1. 摘要
图像分类,也可以称作图像识别,顾名思义,就是辨别图像中的物体属于什么类别。核心是从给定的分类集合中给图像分配一个标签的任务。实际上,这意味着我们的任务是分析一个输入图像并返回一个将图像分类的标签。在这里,我们将分别自己搭建卷积神经网路、迁移学习分别对图像数据集进行分类。本篇使用的数据集下载地址为:
链接:https://pan.baidu.com/s/1mS4xIf1sr3mhYn-cJNMqjQ
提取码:k57i
Pytorch_datasets文件夹底下包括两个文件夹存放各自的图片数据集。
2.搭建卷积神经网络实现图像分类
卷积神经网络与普通的神经网络的区别在于,卷积神经网络包含了一个卷积层convolutional layer和池化层pooling layer构成的特征提取器。卷积神经网路中每层卷积层由若干卷积单元组成,每个卷积单元的参数都是通过反向传播算法优化得到的。卷积运算的目的是提取输入的不同特征,第一层卷积层可能只能提取一些低级的特征如边缘、线条和角等层级,更多层的网络能从低级特征中迭代提取更复杂的特征。池化层(Pooling layer),通常在卷积层之后会得到维度很大的特征,将特征切成几个区域,取其最大值或平均值,得到新的、维度较小的特征。
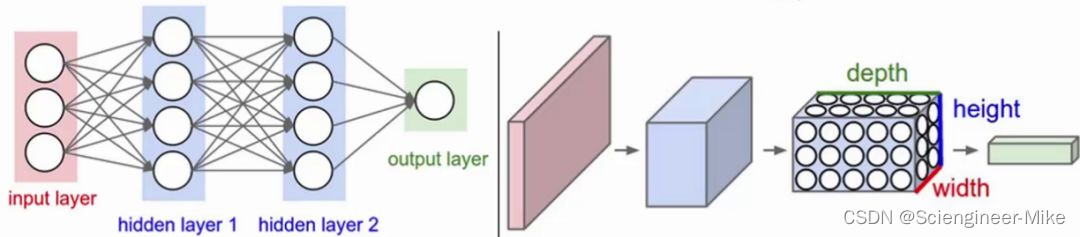
如上图左,全连接神经网络是一个“平面”,包括输入层—激活函数—全连接层,右图的卷积神经网络是一个“立体”,包括输入层—卷积层—激活函数—池化层—全连接层。卷积神经网络提取的数据量更大,因此常用在图像处理上。
接下来,我们自己搭建神经网络对上面同样的数据集进行分类
- 首先,导入相应的包
import os
import torch
from torch import nn,optim
from torch.nn import functional as F
from torch.utils import data
from torchvision import datasets,transforms
- 图像数据预处理
train_path = "./pytorch_datasets/train"
test_path = "./pytorch_datasets/test"
data_transform = transforms.Compose([
transforms.RandomResizedCrop(150),
transforms.ToTensor(),
transforms.Normalize((0.1307,),(0.3081,))
])
datasets_train = datasets.ImageFolder(train_path,data_transform)
datasets_test = datasets.ImageFolder(test_path,data_transform)
train_loader = data.DataLoader(datasets_train,batch_size=32,shuffle=True)
test_loader = data.DataLoader(datasets_test,batch_size=16,shuffle=False)
- pytorch搭建卷积神经网络
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.conv1 = nn.Conv2d(3, 32, 3)
self.max_pool1 = nn.MaxPool2d(2)
self.conv2 = nn.Conv2d(32, 64, 3)
self.max_pool2 = nn.MaxPool2d(2)
self.conv3 = nn.Conv2d(64, 128, 3)
self.max_pool3 = nn.MaxPool2d(2)
self.conv4 = nn.Conv2d(128, 128, 3)
self.max_pool4 = nn.MaxPool2d(2)
self.fc1 = nn.Linear(6272, 512)
self.fc2 = nn.Linear(512, 1)
def forward(self, x):
in_size = x.size(0)
x = self.conv1(x)
x = F.relu(x)
x = self.max_pool1(x)
x = self.conv2(x)
x = F.relu(x)
x = self.max_pool2(x)
x = self.conv3(x)
x = F.relu(x)
x = self.max_pool3(x)
x = self.conv4(x)
x = F.relu(x)
x = self.max_pool4(x)
x = x.view(in_size, -1)
x = self.fc1(x)
x = F.relu(x)
x = self.fc2(x)
x = torch.sigmoid(x)
return x
DEVICE = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(DEVICE)
model = CNN().to(DEVICE)
optimizer = optim.Adam(model.parameters(),lr=0.0001)

- 对图像数据集进行训练30次,打印损失
for epoch in range(30):
model.train()
for i,(image,label) in enumerate(train_loader):
data,target = Variable(image).cuda(),Variable(label.cuda()).unsqueeze(-1)
optimizer.zero_grad()
output = model(data)
output=output.to(torch.float32)
target=target.to(torch.float32)
loss = F.binary_cross_entropy(output,target)
loss.backward()
optimizer.step()
if (i+1)%10==0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, (i+1) * len(data), len(train_loader.dataset),
100. * (i+1) / len(train_loader), loss.item()))

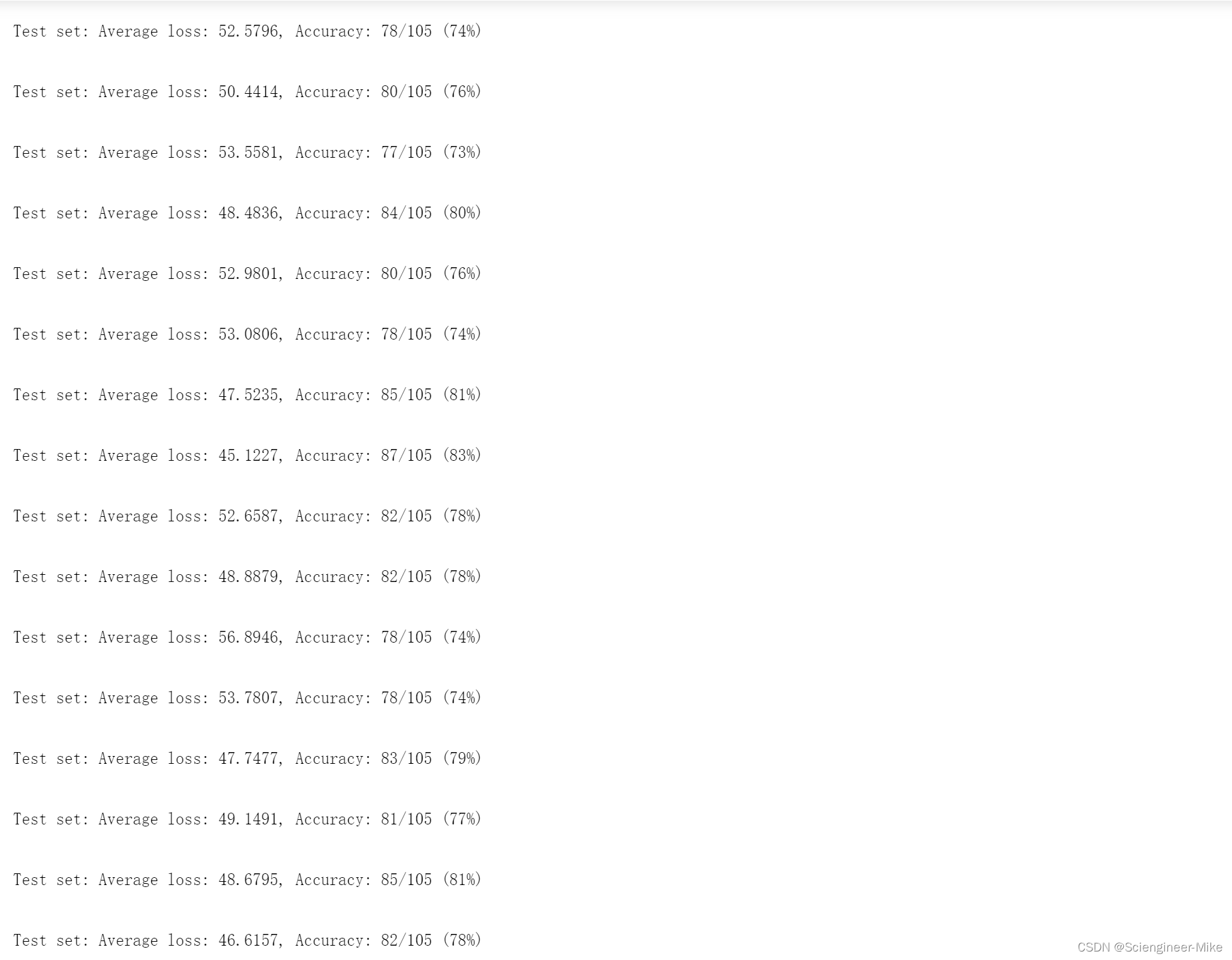
- 对测试集数据进行验证评估,打印精确度
for epoch in range(30):
model.eval()
test_loss = 0
correct = 0
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(DEVICE), target.to(DEVICE).float().unsqueeze(-1)
output = model(data)
test_loss += F.binary_cross_entropy(output, target, reduction='sum').item()
pred = torch.tensor([[1] if num[0] >= 0.5 else [0] for num in output]).to(DEVICE)
correct += pred.eq(target.long()).sum().item()
print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(
test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))
3.迁移学习实现图像分类
问题来了?什么是迁移学习?迁移学习(Transfer learning) 顾名思义就是把已训练好的模型(预训练模型)参数迁移到新的模型来帮助新模型训练。考虑到大部分数据或任务都是存在相关性的,所以通过迁移学习我们可以将已经学到的模型参数(也可理解为模型学到的知识)通过某种方式来分享给新模型从而加快并优化模型的学习效率不用像大多数网络那样从零学习。其中,实现迁移学习有以下三种手段:
1.Transfer Learning:冻结预训练模型的全部卷积层,只训练自己定制的全连接层。
2.Extract Feature Vector:先计算出预训练模型的卷积层对所有训练和测试数据的特征向量,然后抛开预训练模型,只训练自己定制的简配版全连接网络。
3.Fine-tuning:冻结预训练模型的部分卷积层(通常是靠近输入的多数卷积层,因为这些层保留了大量底层信息)甚至不冻结任何网络层,训练剩下的卷积层(通常是靠近输出的部分卷积层)和全连接层。
预训练模型有很多,本文选用InceptionV3预训练模型,它是由谷歌团队从ImageNet的1000个类别的超大数据集训练而来的,表现优异,经常用来做计算机视觉方面的迁移学习研究和应用。
- 同样,首先导入所需要的包
from sklearn.model_selection import train_test_split
import numpy as np
import os
from tqdm import tqdm
from PIL import Image
import torch
import torchvision.datasets
import torchvision.transforms as transforms
import torchvision.models as models
- 图片数据预处理
trainpath = "./pytorch_datasets/train"
testpath = "./pytorch_datasets/test"
batch_size = 16
traintransform = transforms.Compose([transforms.RandomRotation(20),
transforms.ColorJitter(brightness=0.1),
transforms.Resize([224,224]),
transforms.ToTensor()])
valtransform = transforms.Compose([transforms.Resize([224,224]),
transforms.ToTensor()])
trainData = torchvision.datasets.ImageFolder(trainpath,transform=traintransform)
testData = torchvision.datasets.ImageFolder(testpath,transform=valtransform)
trainLoader = torch.utils.data.DataLoader(dataset=trainData,batch_size=batch_size,shuffle=True)
testLoader = torch.utils.data.DataLoader(dataset=testData,batch_size=batch_size,shuffle=False)
- 微调模型进行训练
model = models.resnet34(pretrained=True)
model.fc = torch.nn.Linear(512,2)
- 定义损失函数和优化器
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(),lr=0.0001)
- 进行训练数据集
from torch.autograd import Variable
import time
train_loss = []
valid_loss = []
accuracy = []
for epoch in range(100):
epoch_start_time = time.time()
model.train()
total_loss = 0
train_corrects = 0
for i,(image,label) in enumerate(trainLoader):
image = Variable(image.cuda())
label = Variable(label.cuda())
model.cuda()
target = model(image)
loss = criterion(target,label)
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_loss += loss.item()
max_value,max_index = torch.max(target,1)
pred_label = max_index.cpu().numpy()
true_label = label.cpu().numpy()
train_corrects += np.sum(pred_label==true_label)
loss = total_loss/float(len(trainLoader))
train_acc = train_corrects/100
train_loss.append(loss)
for epoch in range(100):
model.eval()
corrects = eval_loss = 0
with torch.no_grad():
for image,label in testLoader:
image = Variable(image.cuda())
label = Variable(label.cuda())
model.cuda()
pred = model(image)
loss = criterion(pred,label)
eval_loss += loss.item()
max_value,max_index = torch.max(pred,1)
pred_label = max_index.cpu().numpy()
true_label = label.cpu().numpy()
corrects += np.sum(pred_label==true_label)
loss = eval_loss/float(len(testLoader))
acc = corrects/100
valid_loss.append(loss)
accuracy.append(acc)
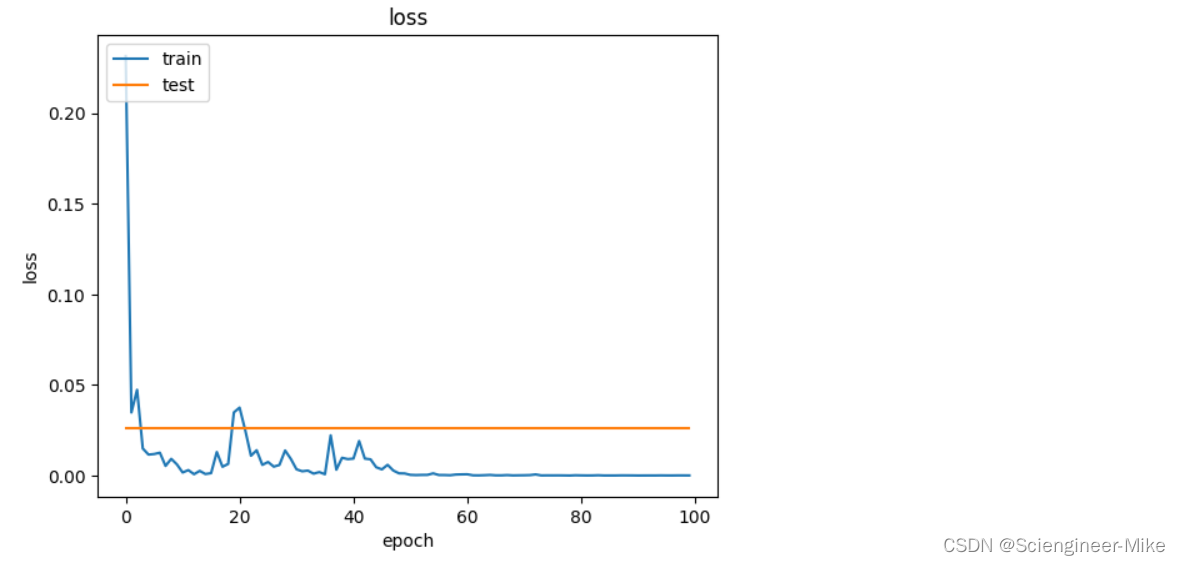
import matplotlib.pyplot as plt
print("**********ending*********")
plt.plot(train_loss)
plt.plot(valid_loss)
plt.title('loss')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.legend(['train', 'test'], loc='upper left')
plt.show()
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)