1 引言
在机器学习领域中,对不均衡数据集进行建模是我们训练模型时经常遇到的挑战.比如在分类问题上,训练集上类别的平衡对模型建模起着重要作用.
如果直接对类间不平衡的数据进行建模,即数据集中存在少数类,这样训练好的模型试图只学习多数类,会导致模型出现有偏预测。
因此,在训练模型之前,需要处理数据集的不平衡问题。业界为了解决类间不平衡问题采用了多种技术,包括过采样, 欠采样以及二者的组合.
本文主要研究6种过采样技术,包括:
- 随机采样
- Smote采样
- BorderLine Smote采样
- KMeans Smote采样
- SVM Smote采样
- ADASYN
闲话少说,我们直接开始吧 😃
2 举个栗子
为了讲解过采样的相关方法,本文以客户流失预测数据集进行讲解.
读取数据:
data = pd.read_csv("./Churn_Modelling.csv")
data.header()
结果如下:

该数据集共包括10000行客户信息数据,其中每行有13列,每1列的含义为序号,客户ID,客户的姓,信用得分,国家,性别,年龄,信用等级,收入,购买产品次数,是否有信用卡,是否为活跃用户,预估收入,是否为流失客户.
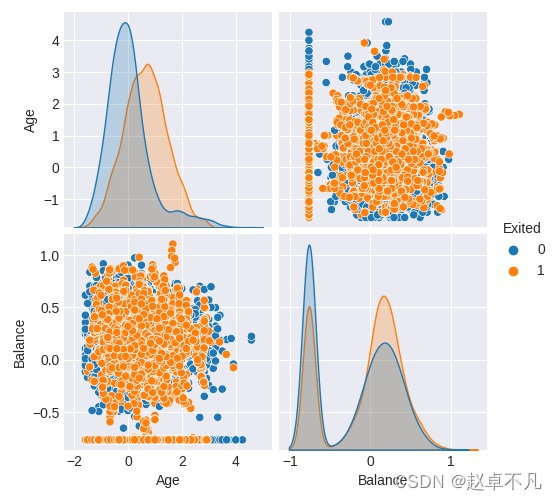
这里为了简单期间,我们假设影响用户是否流失的因素主要包括年龄和收入两项.我们首先来分析数据的分布.
col_n = ['Age','Balance','Exited']
data1 = pd.DataFrame(data,columns=col_n)
sns.pairplot(data1, hue='Exited')
plt.show()
运行结果如下:

接下来我们来统计流失人数的数据分布,
fig,ax = plt.subplots(figsize=(6,6),dpi=80)
ax.set_title("Customer Exited or not")
sns.countplot(data=data1,x='Exited')
for p in ax.patches:
ax.annotate(f'\n{p.get_height()}', (p.get_x(), p.get_height()+50), color='black', size=10)
plt.show()
结果如下:
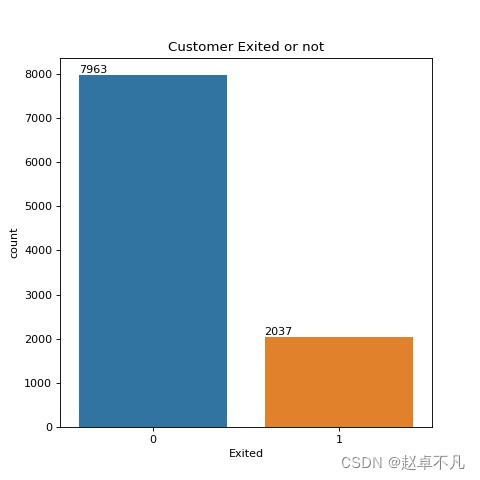
可以看出,数据集中流失的人数占20.4%,留下来的客户占比79.6%. 比例大概为1:4, 所以训练数据是严重不均衡的.
3 数据预处理
问题抽象: 我们的目的在客户是否流失数据集是建立一个模型,用来根据用户的年龄和收入来预测该客户是非为潜在流失客户.将该任务抽象为二分类任务,输入为年龄和收入,输出为1或者0, 其中1表示为流失客户,0表示为非流失客户.
为了完成上述模型,我们首先按照1-9 比例来将数据集划分为训练集和测试集,代码如下:
from sklearn.model_selection import StratifiedShuffleSplit
data2 = pd.get_dummies(data1,drop_first=True)
x = data2.drop("Exited",axis=1)
y = data2["Exited"]
sss = StratifiedShuffleSplit(test_size=0.1,n_splits=2)
for train_ind,test_ind in sss.split(x,y):
xtrain,xtest = x.iloc[train_ind,:],x.iloc[test_ind,:]
ytrain,ytest = y[train_ind],y[test_ind]
我们观察年龄和收入数据,发现二者量纲并不一致,所以我们还需要对数据进行归一化,代码如下:
from sklearn.preprocessing import StandardScaler,RobustScaler
scaler = RobustScaler()
xtrain = pd.DataFrame(scaler.fit_transform(xtrain), columns=x.columns)
xtest = pd.DataFrame(scaler.fit_transform(xtest), columns=x.columns)
4 训练分类器
为了说明采用不同采样器对数据集分布和模型结果的影响,这里首先使用原始数据集进行模型的训练和预测,代码如下:
print("origin result as below:")
get_result_report(xtrain, ytrain, xtest, ytest)
show_data(xtrain,ytrain,out_file="0_org.jpg")
运行结果如下:
origin result as below:
train set report:
precision recall f1-score support
0 0.80 0.96 0.87 7167
1 0.29 0.06 0.10 1833
accuracy 0.78 9000
macro avg 0.54 0.51 0.49 9000
weighted avg 0.70 0.78 0.72 9000
test set report:
precision recall f1-score support
0 0.80 0.97 0.88 796
1 0.36 0.06 0.11 204
accuracy 0.79 1000
macro avg 0.58 0.52 0.49 1000
weighted avg 0.71 0.79 0.72 1000
AUC曲线图如下:

观察上图,我们发现对于缺失样本即Exited=1的样本训练集中仅有1833个,而Exited=0的训练样本有7167个.
所以训练的分类器在测试集上预测Exited=0的样本的准确率为80%,而预测Exited=1的准确率为36%,此时整个模型的AUC=73.38%.
5 随机采样
既然我们知道模型在不均衡数据集上模型训练效果不佳,那么接下来我们来对样本数目少的数据进行重采样,以提升缺失样本的比例.
随机重采样是最简单的采样策略用来使得数据集中的数据趋于平衡.该策略主要通过重复复制样本数目少的数据来使不同类间数据趋于平衡.这种策略的缺点在于模型有可能会对复制的样本产生过拟合.
随机采样代码如下:
from imblearn.over_sampling import RandomOverSampler
ros = RandomOverSampler(random_state=0)
x_resample,y_resample = ros.fit_resample(xtrain,ytrain)
show_data(x_resample, y_resample,out_file="1_random.jpg")
print("Random sample result as below:")
get_result_report(x_resample, y_resample, xtest, ytest,out_file="1_report.jpg")
采样后的数据分布如下:

训练的模型性能如下:
Random sample result as below:
train set report:
precision recall f1-score support
0 0.68 0.72 0.70 7167
1 0.70 0.66 0.68 7167
accuracy 0.69 14334
macro avg 0.69 0.69 0.69 14334
weighted avg 0.69 0.69 0.69 14334
test set report:
precision recall f1-score support
0 0.89 0.72 0.80 796
1 0.38 0.66 0.48 204
accuracy 0.71 1000
macro avg 0.63 0.69 0.64 1000
weighted avg 0.79 0.71 0.73 1000
AUC曲线如下:

观察上图,我们发现对于缺失样本即Exited=1的样本进行随机采样后数目扩展为7167,和Exited=0的训练样本数目保持一致.
此时训练的分类器在测试集上预测Exited=0的样本的准确率为89%,而预测Exited=1的准确率提升为38%; 同时整个模型的AUC=73.64%.
6 SMOTE采样
在上述随机过采样的案例中,由于少数类别的重复复制导致模型容易过拟合复制的样本,为了改善这种情况,引入了SMOTE策略. SMOTE为 Synthetic Minority Oversampling Technique的简称,它通过合成新的样本来使得训练数据趋于平衡.
SMOTE主要利用K近邻算法来合成样本数据,以下为其详细步骤:
- 采样最邻近算法,计算出每个少数类样本的K个近邻;
- 从K个近邻中随机挑选N个样本进行随机线性插值;
- 构造新的少数类样本;
- 将新样本与原数据合成,产生新的训练集;
采用SMOTE算法进行数据采样的代码如下:
from imblearn.over_sampling import SMOTE
smo = SMOTE()
x_resample,y_resample = smo.fit_resample(xtrain,ytrain)
show_data(x_resample, y_resample, out_file="2_smote.jpg")
print("SMOTE sample result as below:")
get_result_report(x_resample, y_resample, xtest, ytest,out_file="2_report.jpg")
采样后的数据分布如下:
训练的模型性能如下:
SMOTE sample result as below:
train set report:
precision recall f1-score support
0 0.68 0.72 0.70 7167
1 0.70 0.66 0.68 7167
accuracy 0.69 14334
macro avg 0.69 0.69 0.69 14334
weighted avg 0.69 0.69 0.69 14334
test set report:
precision recall f1-score support
0 0.89 0.72 0.79 796
1 0.38 0.67 0.48 204
accuracy 0.71 1000
macro avg 0.63 0.69 0.64 1000
weighted avg 0.79 0.71 0.73 1000
AUC曲线如下:

观察上图,我们发现对于缺失样本即Exited=1的样本进行SMOTE采样后数目扩展为7167,和Exited=0的训练样本数目保持一致.
此时训练的分类器在测试集上预测Exited=0的样本的准确率为89%,而预测Exited=1的准确率提升为38%; 同时整个模型的AUC=73.68%.
7 BorderLine SMOTE采样
由于多数类分布的区域往往存在一些少数类的点或异常值,此时利用SMOTE创建的新样本有时候往往不够准确,此时可以使用BorderLine Smote采样算法进行解决。
Borderline SMOTE采样过程是将少数类样本分为3类,分别为Safe、Danger和Noise,具体说明如下。

- Safe,样本周围一半以上均为少数类样本,如图中点A
- Danger:样本周围一半以上均为多数类样本,视为在边界上的样本,如图中点B
- Noise:样本周围均为多数类样本,视为噪音,如图中点C
最后,Borderline SMOTE算法仅对上述Danger的少数类样本进行过采样。
采用BorderLine SMOTE算法进行数据采样的代码如下:
from imblearn.over_sampling import BorderlineSMOTE
smo2 = BorderlineSMOTE()
x_resample, y_resample = smo2.fit_resample(xtrain, ytrain)
show_data(x_resample, y_resample, out_file="3_board_smote.jpg")
print("BorderLine SMOTE sample result as below:")
get_result_report(x_resample, y_resample, xtest, ytest,out_file="3_report.jpg")
采样后的数据分布如下:
 BorderLine
BorderLine
训练的模型性能如下:
BorderLine SMOTE sample result as below:
train set report:
precision recall f1-score support
0 0.68 0.70 0.69 7167
1 0.69 0.67 0.68 7167
accuracy 0.69 14334
macro avg 0.69 0.69 0.69 14334
weighted avg 0.69 0.69 0.69 14334
test set report:
precision recall f1-score support
0 0.89 0.71 0.79 796
1 0.37 0.67 0.48 204
accuracy 0.70 1000
macro avg 0.63 0.69 0.64 1000
weighted avg 0.79 0.70 0.73 1000
AUC曲线如下:

观察上图,我们发现对于缺失样本即Exited=1的样本进行BorderLine SMOTE采样后数目扩展为7167,和Exited=0的训练样本数目保持一致.
此时训练的分类器在测试集上预测Exited=0的样本的准确率为89%,而预测Exited=1的准确率提升为37%; 同时整个模型的AUC=73.51%.
8 KMeans SMOTE采样
K-means SMOTE由三个步骤组成:聚类、滤波和过采样。
- 在聚类步骤中,使用k-均值聚类将输入空间聚类成k个组。
- 滤波步骤选择用于过采样的聚类,保留少数类样本比例高的聚类。
- 然后,它分配要生成的合成样本的数量,将更多的样本分配给少数样本稀疏分布的集群。
- 最后,在过采样步骤中,在每个选定的聚类中应用SMOTE,以实现少数和多数实例的目标比率.
采用K-means SMOTE算法进行数据采样的代码如下:
from imblearn.over_sampling import KMeansSMOTE
smo3 = KMeansSMOTE(k_neighbors=2)
x_resample, y_resample = smo3.fit_resample(xtrain, ytrain)
show_data(x_resample, y_resample, out_file="4_kmeans_smote.jpg")
print("Kmeans SMOTE sample result as below:")
get_result_report(x_resample, y_resample, xtest, ytest,out_file="4_report.jpg")
采样后的数据分布如下:

训练的模型性能如下:
Kmeans SMOTE sample result as below:
train set report:
precision recall f1-score support
0 0.87 0.85 0.86 7167
1 0.86 0.87 0.86 7167
accuracy 0.86 14334
macro avg 0.86 0.86 0.86 14334
weighted avg 0.86 0.86 0.86 14334
test set report:
precision recall f1-score support
0 0.87 0.85 0.86 796
1 0.46 0.49 0.47 204
accuracy 0.78 1000
macro avg 0.66 0.67 0.67 1000
weighted avg 0.78 0.78 0.78 1000
AUC曲线如下:

观察上图,我们发现对于缺失样本即Exited=1的样本进行KMeans SMOTE采样后数目扩展为7167,和Exited=0的训练样本数目保持一致.
此时训练的分类器在测试集上预测Exited=0的样本的准确率为87%,而预测Exited=1的准确率提升为46%; 同时整个模型的AUC=73.87%.
9 SVM SMOTE采样
BorderLine SMOTE的另一个变体是SMOTE SVM,或者我们可以称之为SVM-SMOTE。该技术结合了SVM算法来识别误分类点。
在SVM-SMOTE中,在原始训练集上训练SVM分类器后,用支持向量逼近边界区域。然后沿着将每个少数类支持向量与其若干最近邻连接起来的直线随机创建合成数据。
采用SVM SMOTE算法进行数据采样的代码如下:
from imblearn.over_sampling import SVMSMOTE
smo4 = SVMSMOTE()
x_resample, y_resample = smo4.fit_resample(xtrain, ytrain)
show_data(x_resample, y_resample, out_file="5_svm_smote.jpg")
print("SVM SMOTE sample result as below:")
get_result_report(x_resample, y_resample, xtest, ytest,out_file="5_report.jpg")
采样后的数据分布如下:

训练的模型性能如下:
SVM SMOTE sample result as below:
train set report:
precision recall f1-score support
0 0.78 0.78 0.78 7167
1 0.78 0.78 0.78 7167
accuracy 0.78 14334
macro avg 0.78 0.78 0.78 14334
weighted avg 0.78 0.78 0.78 14334
test set report:
precision recall f1-score support
0 0.89 0.78 0.83 796
1 0.41 0.61 0.49 204
accuracy 0.74 1000
macro avg 0.65 0.69 0.66 1000
weighted avg 0.79 0.74 0.76 1000
AUC曲线如下:

观察上图,我们发现对于缺失样本即Exited=1的样本进行SVM SMOTE采样后数目扩展为7167,和Exited=0的训练样本数目保持一致.
此时训练的分类器在测试集上预测Exited=0的样本的准确率为89%,而预测Exited=1的准确率提升为41%; 同时整个模型的AUC=73.79%.
10 ADASYN采样
BorderLine Smote采样算法更加关注作为边界点附近的样本来生成新的样本,忽略了其他少数类样本. 这个问题由ADASYN算法解决,因为它根据数据密度来创建合成数据。
合成数据的生成与少数类的密度成反比。在少数类密度较低的区域创建的合成数据数量相对较多,而在少数类密度较高的区域创建的合成数据数量相对较少。
采用ADASYN算法进行数据采样的代码如下:
from imblearn.over_sampling import ADASYN
ada = ADASYN()
x_resample, y_resample = ada.fit_resample(xtrain, ytrain)
show_data(x_resample, y_resample, out_file="6_SDASYN.jpg")
print("ADASYN sample result as below:")
get_result_report(x_resample, y_resample, xtest, ytest,out_file="6_report.jpg")
采样后的数据分布如下:

训练的模型性能如下:
ADASYN sample result as below:
train set report:
precision recall f1-score support
0 0.65 0.70 0.68 7167
1 0.67 0.62 0.64 7034
accuracy 0.66 14201
macro avg 0.66 0.66 0.66 14201
weighted avg 0.66 0.66 0.66 14201
test set report:
precision recall f1-score support
0 0.90 0.71 0.79 796
1 0.37 0.68 0.48 204
accuracy 0.70 1000
macro avg 0.63 0.69 0.64 1000
weighted avg 0.79 0.70 0.73 1000
AUC曲线如下:

观察上图,我们发现对于缺失样本即Exited=1的样本进行SVM SMOTE采样后数目扩展为7034,和Exited=0的训练样本数目基本保持一致.
此时训练的分类器在测试集上预测Exited=0的样本的准确率为90%,而预测Exited=1的准确率提升为37%; 同时整个模型的AUC=73.64%.
11 结论
上述五种不同重采样策略下,所得模型的预测结果汇总如下:
| train_precision | train_recall | train_F1 | test_pricison | test_recall | test_F1 | AUC |
|---|
| original | 0.7 | 0.78 | 0.72 | 0.71 | 0.79 | 0.72 | 73.38% |
| Random | 0.69 | 0.69 | 0.69 | 0.79 | 0.71 | 0.73 | 73.64% |
| SMOTE | 0.69 | 0.69 | 0.69 | 0.79 | 0.71 | 0.73 | 73.68% |
| BorderLine Smote | 0.69 | 0.69 | 0.69 | 0.79 | 0.7 | 0.73 | 73.51% |
| Kmenas Smote | 0.86 | 0.86 | 0.86 | 0.78 | 0.78 | 0.78 | 73.87% |
| SVM Smote | 0.78 | 0.78 | 0.78 | 0.79 | 0.74 | 0.76 | 73.79% |
| ADASYN | 0.66 | 0.66 | 0.66 | 0.79 | 0.7 | 0.73 | 73.64% |
可见针对该数据集,使用KMeans-SMOTE 为不错的数据采样策略.
12 总结
本文重点介绍了针对数据不均衡问题,五种不同的数据过采样策略的原理和相关代码实现.
您学废了吗?

关注公众号《AI算法之道》,获取更多AI算法资讯。
关注公众号,后台回复 oversample,即可获取源代码。
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)