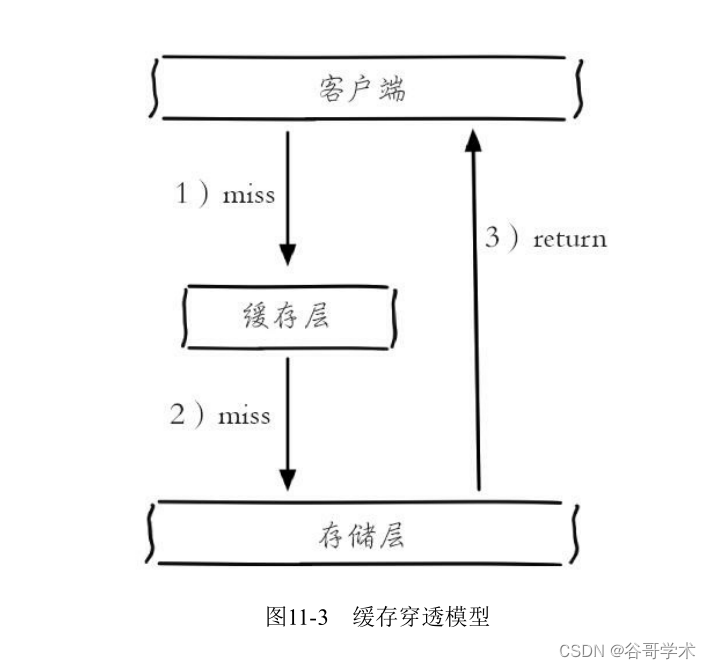
图11-1左侧为客户端直接调用存储层的架构,右侧为比较典型的缓存层
成本如下:
11.2 缓存更新策略
4.最佳实践
例如现在需要将MySQL的用户信息使用Redis缓存,可以执行如下操
缓存粒度问题是一个容易被忽视的问题,如果使用不当,可能会造成很
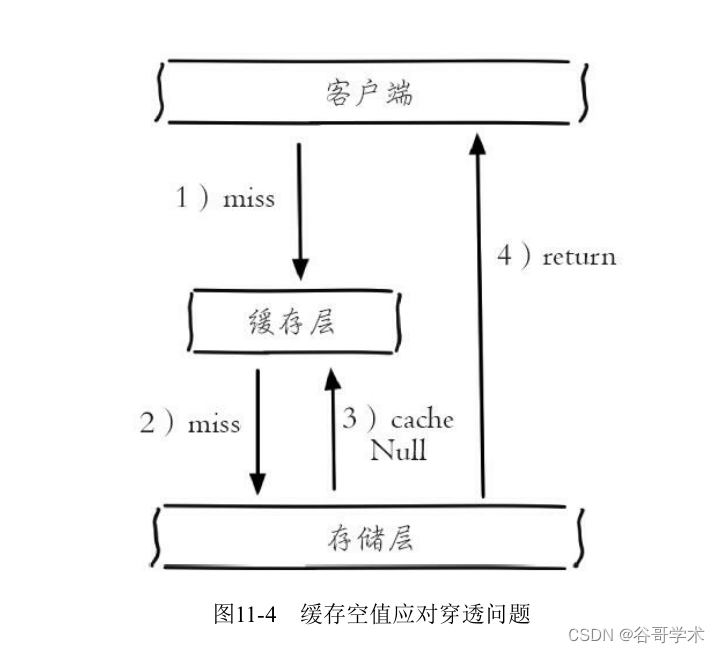
缓存空对象会有两个问题:第一,空值做了缓存,意味着缓存层中存了
String get(String key) {
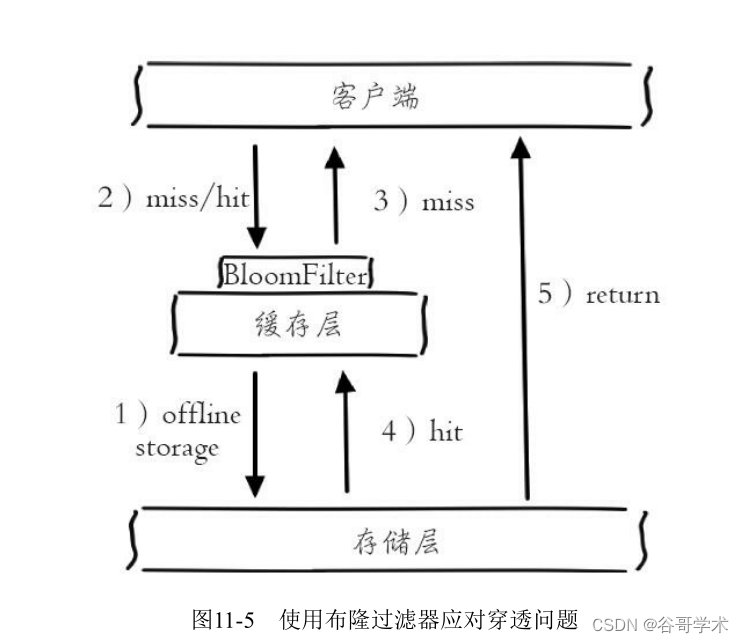
2.布隆过滤器拦截
开发提示
11.5 无底洞优化
·命令本身的优化,例如优化SQL语句等。
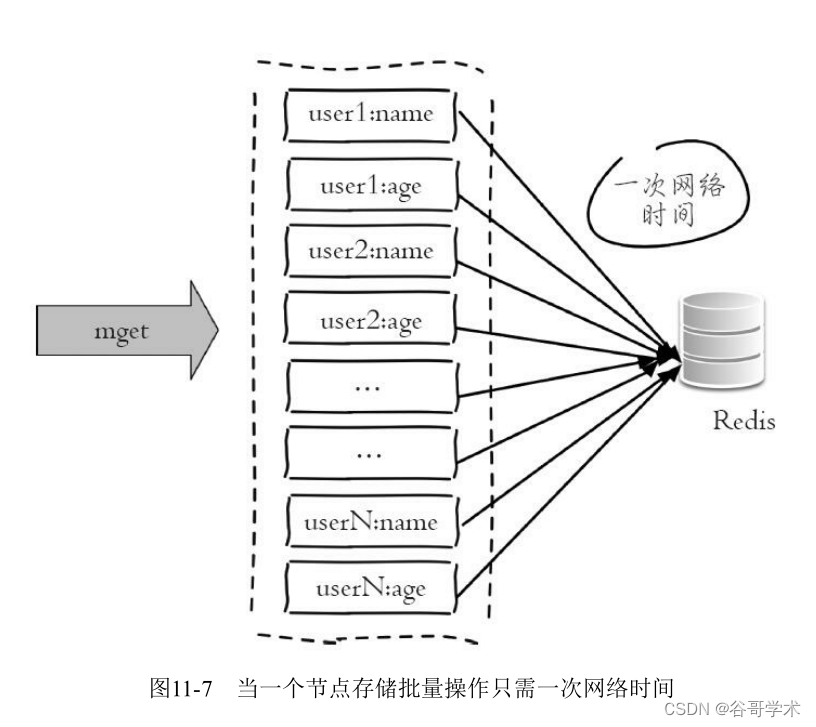
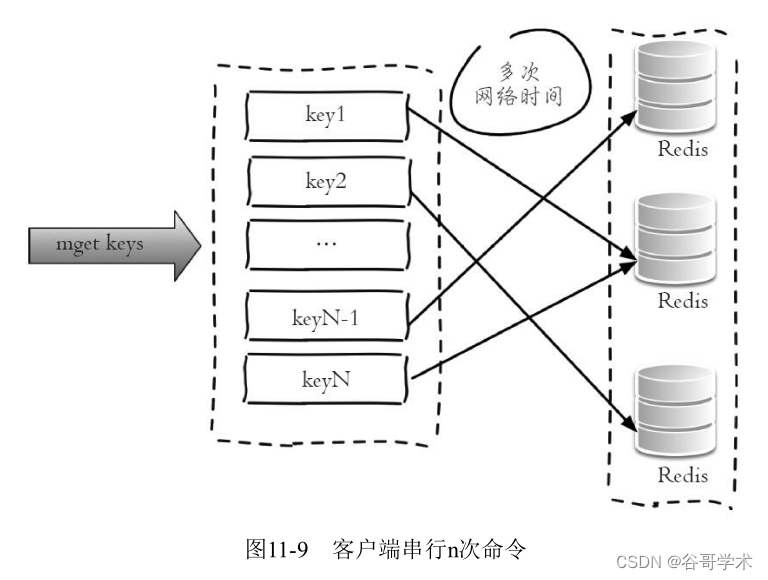
1.串行命令
Jedis客户端示例代码如下:
Jedis客户端示例代码如下:
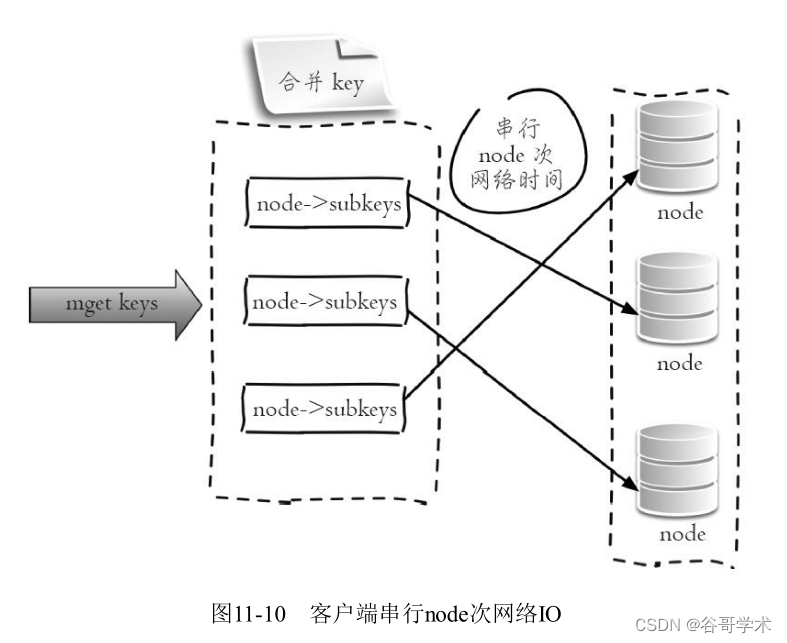
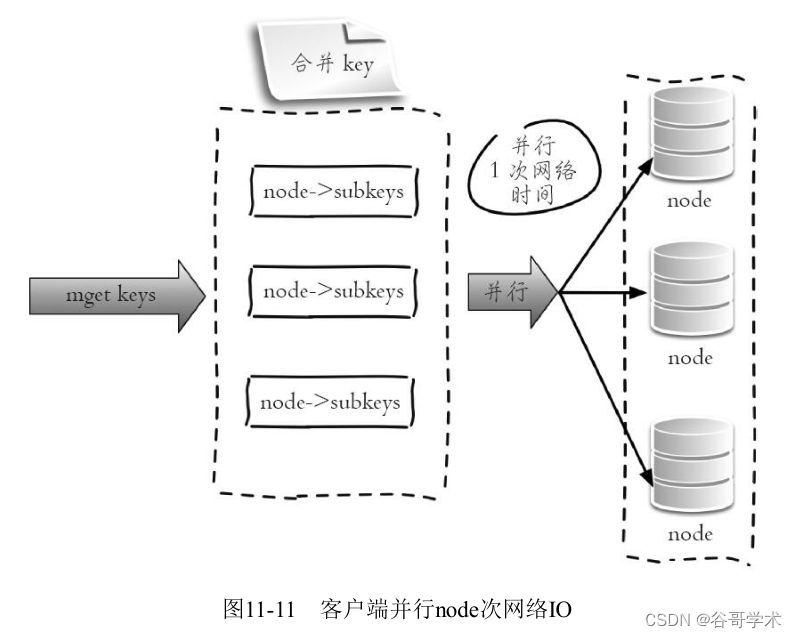
4.hash_tag实现
如图11-13所示,所有key属于node2节点。
图11-13 hashtag只需要1次网络时间
Jedis客户端示例代码如下:
表11-4 四种批量操作解决方案对比
实际开发中可以根据表11-4给出的优缺点进行分析,没有最好的方案只
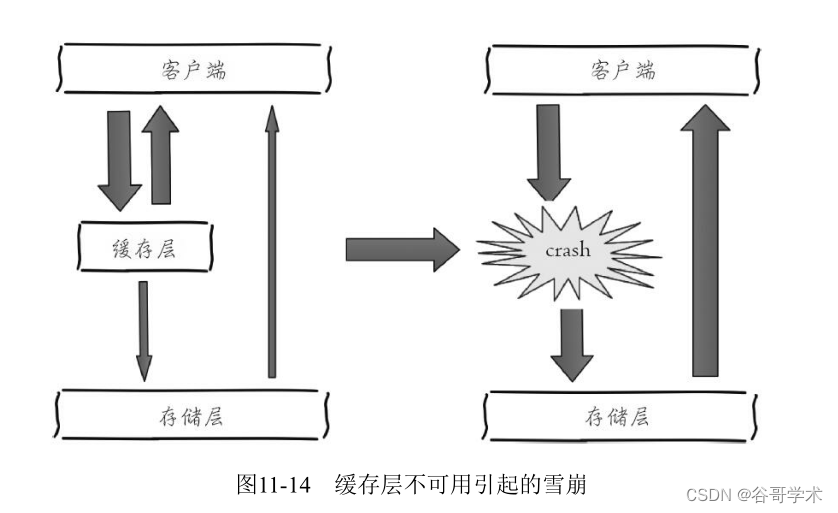
预防和解决缓存雪崩问题,可以从以下三个方面进行着手。
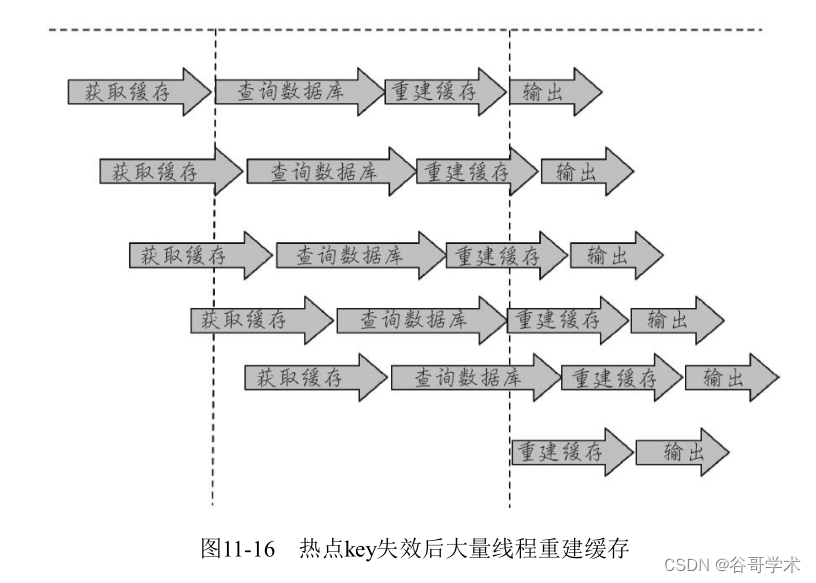
11.7 热点key重建优化
·数据尽可能一致。
下面代码使用Redis的setnx命令实现上述功能:
String get(String key) {
// 从 Redis 中获取数据
String value = redis.get(key);
// 如果 value 为空,则开始重构缓存
if (value == null) {
// 只允许一个线程重构缓存,使用 nx ,并设置过期时间 ex
String mutexKey = "mutext:key:" + key;
if (redis.set(mutexKey, "1", "ex 180", "nx")) {
// 从数据源获取数据
value = db.get(key);
// 回写 Redis ,并设置过期时间
redis.setex(key, timeout, value);
// 删除 key_mutex
redis.delete(mutexKey);
}
// 其他线程休息 50 毫秒后重试
else {
Thread.sleep(50);
get(key);
}
}
return value;
}
1)从Redis获取数据,如果值不为空,则直接返回值;否则执行下面的
String get(final String key) {
V v = redis.get(key);
String value = v.getValue();
// 逻辑过期时间
long logicTimeout = v.getLogicTimeout();
// 如果逻辑过期时间小于当前时间,开始后台构建
if (v.logicTimeout <= System.currentTimeMillis()) {
String mutexKey = "mutex:key:" + key;
if (redis.set(mutexKey, "1", "ex 180", "nx")) {
// 重构缓存
threadPool.execute(new Runnable() {
public void run() {
String dbValue = db.get(key);
redis.set(key, (dbvalue,newLogicTimeout));
redis.delete(mutexKey);
}
});
}
}
return value;
} 作为一个并发量较大的应用,在使用缓存时有三个目标:第一,加快用
11.8 本章重点回顾
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)