brief描述子

一般Sb=48,Lb为256.brief描述子不具备旋转尺度不变性。
词袋

提取大量图片的描述子,将描述子用k-means聚类成K堆,这是第n层,把每一堆再次聚类形成下一层,总共聚类L次,到0层。这样就有L层,每次分叉为K。最终得到一棵有W个叶子的树,它们就是词库的单词。每一个单词都有一个权重,它表征了该单词在词库的relevance。
bag-of-words vector: 假设我们词库里有总共三个单词,w1, w2, w3. 图片里面包含2个w1, 0个w2,1个w3. 则图片可以表示为2w1+0w2+1*w3。因为词库是固定的,所以可以直接用[2,0,1]表示这张图片。
inverse index Word1: 存储了该单词在哪些图片出现,且它在该图片的权重。(从单词角度)
在查询图库的时候,如果查询图片有这个单词,那么能很快知道也有这个单词的图片。这样我们很方便就知道图库里面哪些图片和查询图片有最多的共同单词。当图库里面有新的图片加入,inverse index就会更新。当开始查询,就会获得inverse index。
<
I
t
,
v
t
i
>
<I_t,v_t^i>
<It,vti>
direct index image 1:存储每张图片的特征点和它对应的节点。(从图片角度)如果候选帧已经被选出,direct index就会让查询帧和候选帧的特征点对应起来变的很方便。当图库里面有新的图片加入,direct index就会更新。当候选帧已经被选出,要开始匹配,就会获得direct index。
这两个index就是查询帧在图库里寻找匹配图片整个过程所需的,比如一张图片取图库里寻找它的相似帧,且输出该相似帧与它匹配的特征点,我们该怎么做呢?首先,我们要找到该相似图片,如何找?肯定是根据单词来,这时候inverse index就发挥了作用,根据inverse index,我们很快就知道了哪张图片和它有最多的公共单词,就是词向量求相似度。但是单词是不知道在图片中特征点的序号的,我们要知道该图片与查询帧的特征点对应关系,就得靠direct index了。
注意 词库和图库 词库是就是word vocabulary,它是固定不变的,即我们工程去读取的brief_k10L6.bin文件,而图库是我们工程读取的图片集合,使我们每个工程自己生成的
- 比较词向量的相似性:
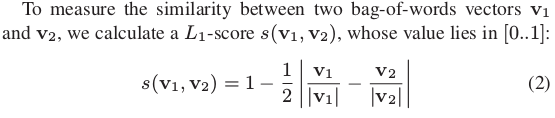
回环检测算法
1.Database query
每一张图片都被转换为词向量v了,直接用s(v1,v2)就可以计算出两张图片的相似度。假设当前帧是
v
t
v_t
vt, 在图库里计算出一组匹配分
<
v
t
,
v
t
1
>
,
<
v
t
,
<
v
t
2
>
.
.
.
<v_t, v_{t1}> , <v_t, <v_{t2}>...
<vt,vt1>,<vt,<vt2>...,我们那当前帧与它上一帧的匹配分
<
v
t
,
v
t
−
T
>
<v_t,v_{t-T}>
<vt,vt−T>作为标准,一般两帧的分数是比较高的(但是在旋转时会变小,要剔除)
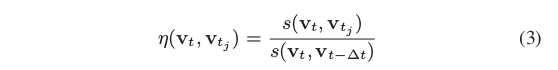
如果这个值大于某个阈值,则认为是候选帧了。
2.Match grouping

这里的意思就是如果某一帧如果是真正的回环帧,那么它前后帧也都应该与当前帧相似,应该把这些看做是一次匹配,把他们都加起来,H越大,说明这个岛越大且分最高,说明越是可能的回环。
3.Temporal consistency

时间校验,这个候选帧(注意是岛的代表)必须跟当前帧的前7帧也是相似的,那么就从岛中选出得分最高的作为候选帧了。
上面都是提取候选帧。
下面是匹配。
4.几何校验
找出当前帧和候选帧的特征点对应关系,用ransac求F矩阵即可。找特征点对应关系就要用到direct index啦,

我们只计算两张图片同在一个叶子节点的特征点描述子的距离,这样就可以大大节省时间。但是如果l=0,导致只有属于同一个单词的特征点参与计算,这样对应关系肯定变少。两者需要权衡。如果l=Lw,那就是暴力匹配了。
tf-idf,
tf是词频(term frequency),表示词在文本中出现的频率

idf逆向文件频率,总文件数目除以包含该单词的文件数目,再将商取对数,即idf。如果idf越大,说明出现该单词的文件越少,则该词越具有区分性。

tf-idf 就是tf * idf。
什么意思呢?我们要区分文本,靠的是单词,有些单词具有很好的区分性,有些单词可能每个文本都出现,这样的单词区分性就比较差。tf表征了单词在所有文本库中出现的频率,如果单用tf来衡量,是很难的,因为tf大,有可能它确实在某几篇文档中反复出现,这种是可以的,但是它也有可能是在大量出现在所有文档中(比如我,的这样的单词)。引入idf就是为了避免这种情况,它表征了该单词在多少个文本中出现,像“我”、“的”这样的单词idf就非常小,就算tf很大,相乘之后tf-idf就很小,说明该词区分性不好。tf-idf越大,说明该单词不仅出现次数多而且它所在的文本数量少,这样的词就具备很好的区分性。
DBOW
dbow1,2,3的区别
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)