
一、UniProt 数据库介绍
Uniprot (Universal Protein )是包含蛋白质序列,功能信息,研究论文索引的蛋白质数据库,整合了包括EBI( European Bioinformatics Institute),SIB(the Swiss Institute of Bioinformatics),PIR(Protein Information Resource)三大数据库的资源。
- EBI( European Bioinformatics Institute):欧洲生物信息学研究所(EMBL-EBI)是欧洲生命科学旗舰实验室EMBL的一部分。位于英国剑桥欣克斯顿的惠康基因组校园内,是世界上基因组学领域最强的地带之一。
- SIB(the Swiss Institute of Bioinformatics):瑞士日内瓦的SIB维护着ExPASy(专家蛋白质分析系统)服务器,这里包含有蛋白质组学工具和数据库的主要资源。
- PIR(Protein Information Resource):PIR由美国国家生物医学研究基金会(NBRF)于1984年成立,旨在协助研究人员识别和解释蛋白质序列信息。
二、UniProt 数据库构成

目前,UniProt由主要由以下子库构成:
| 数据库名 | 全名 | 用途 |
|---|
| Swiss-Prot | Protein knowledgebas (review) | 高质量的、手工注释的、非冗余的数据库 |
| TrEMBL | Protein knowledgebase (unreview) | 自动翻译蛋白质序列,预测序列,未验证的数据库 |
| UniParc | Sequence | 非冗余蛋白质序列数据库 |
| UniRef | Sequence clusters | 聚类序列减小数据库,加快搜索的速度 |
| Proteomes | Protein sets from fully sequenced genomes | 为全测序基因组物种提供蛋白质组信息 |
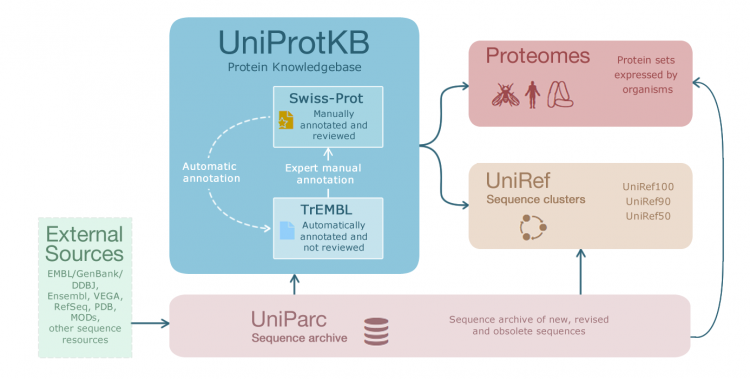
他们的关系如下:
通过EMBL,GenBank,DDBJ等公共数据库得到原始数据,处理后存入UniParc的非冗余蛋白质序列数据库。
UniParc作为数据仓库,再分别给UniProtKB,Proteomes,UniRef提供可靠的数据集。
这里的UniProtKB 由两个子库构成 Swiss-Prot,TrEMBL。
Swiss-Prot 经过人工验证和注释,是高质量的蛋白质注释数据。但人工效率在高速增长的蛋白质数据面前显得极其低效。因此,注释这些数据需要大量时间,为了弥补这一问题。
TrEMBL 被建立用于存储由机器自动翻译和预测的蛋白质序列。显然,这必然导致蛋白质质量下降。
简而言之,在UniProtKB数据库中Swiss-Prot是由TrEMBL经过手动注释后得到的高质量非冗余数据库,也是我们今后常用的蛋白质数据库之一。
三、Swiss-Prot 介绍
高质量的、手工注释的、非冗余的数据集
Swiss-Prot 提供高水平注释(例如,蛋白质功能,其域结构,翻译后修饰,变体等的描述)和蛋白质序列。
Swiss-Prot由Amos Bairoch博士在1986年创建,由瑞士生物信息学研究所开发,随后由欧洲生物信息学研究所的Rolf Apweiler开发。也就是说EBI和SIB共同制作了Swiss-Prot和TrEMBL数据库。
注释主要来自文献中的研究成果和E-value校验过计算分析结果,有质量保证的数据才被加入该数据库 。
手动注释
注释会用相关出版物通过搜索数据库(例如PubMed)进行识别。阅读每篇论文的全文,然后提取信息并将其添加到条目中。科学文献中的注释包括但不限于:
- 蛋白质和基因名称
- 功能
- 特定于酶的信息,例如催化活性,辅因子和催化残基
- 亚细胞定位
- 蛋白质相互作用
- 表达方式
- 重要域和站点的位置和角色
- 离子,底物和辅因子结合位点
- 通过自然遗传变异,RNA编辑,替代剪接,蛋白水解加工和翻译后修饰产生的蛋白质变异形式
计算机预测
Swiss-Prot条目的注释中使用了一系列序列分析工具,包括手动检测和评估,计算机预测。
这些预测包括翻译后修饰,跨膜结构域和拓扑,信号肽,结构域识别和蛋白质家族分类。
也包括序列之间的差异:可变剪接,自然变异,错误的起始位点,错误的外显子边界,移码,未识别的冲突。
这里包含了很多第三方算法和软件
3.1、查询蛋白质基础操作
1、进入官网:https://www.uniprot.org/

1、切换数据库,也就是上面介绍的
2、输入基因名,uniprot id,物种名等都可以
3、点击进行搜索
4、进入搜索结果页面
https://www.uniprot.org/uniprotkb?query=oct4
新版界面主要由,搜索框,搜索结果表,和左边过滤选项面板构成
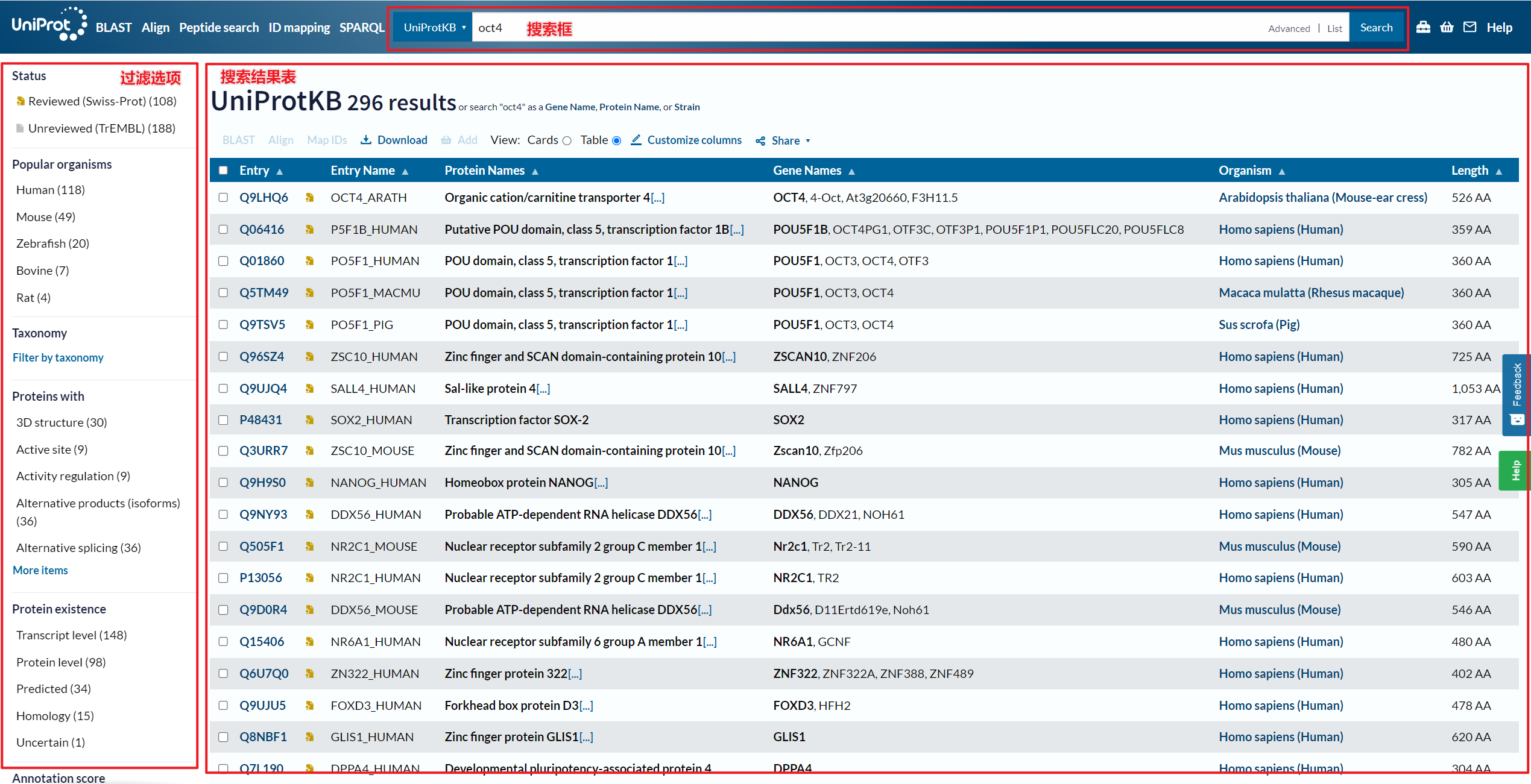
5、过滤选项面板
- 来源库:Reviewed:存储在Swiss-Prot数据库中经过验证的蛋白数据,Unreviewed:存储在TrEMBL数据库中没有经过验证的蛋白数据
- 物种,点击
Popular organisms切换到该物种,或者在 Taxonomy通过 taxid 来筛选。什么是 Taxonomy?https://blog.csdn.net/u011262253/article/details/95304930/ - 蛋白质相关注释内容:直接点击对应管关键字
- 注释分数:分数越高,注释内容质量越高
- 蛋白质长度:单位是氨基酸,AA
6、搜索结果表
依次是Unprot ID,蛋白质Uniprot名称,蛋白质名称,基因名,物种名,序列长
7、比对操作
- 序列与蛋白库比对:如果需要Blast来查看某个蛋白有哪些序列相似的蛋白序列,先选中感兴趣蛋白前的方框,点击Blast
- 多序列比对:先选中感兴趣蛋白前的方框,点击Align
8、数据下载
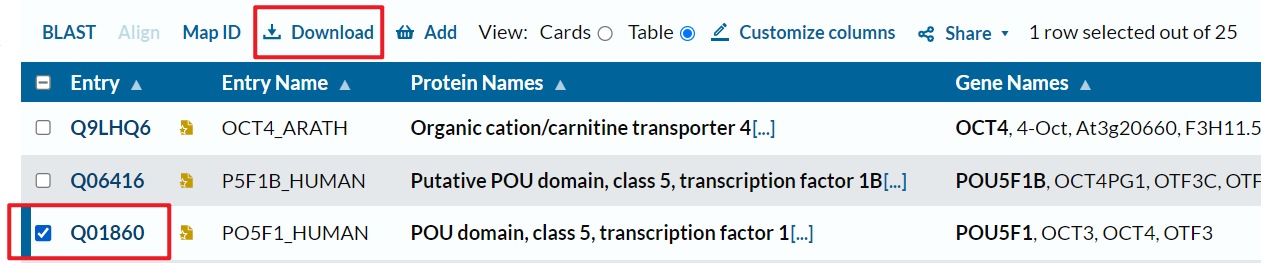
下面以 PO5F1_HUMAN 为例。
先选中感兴趣蛋白前的方框,点击Download下载。
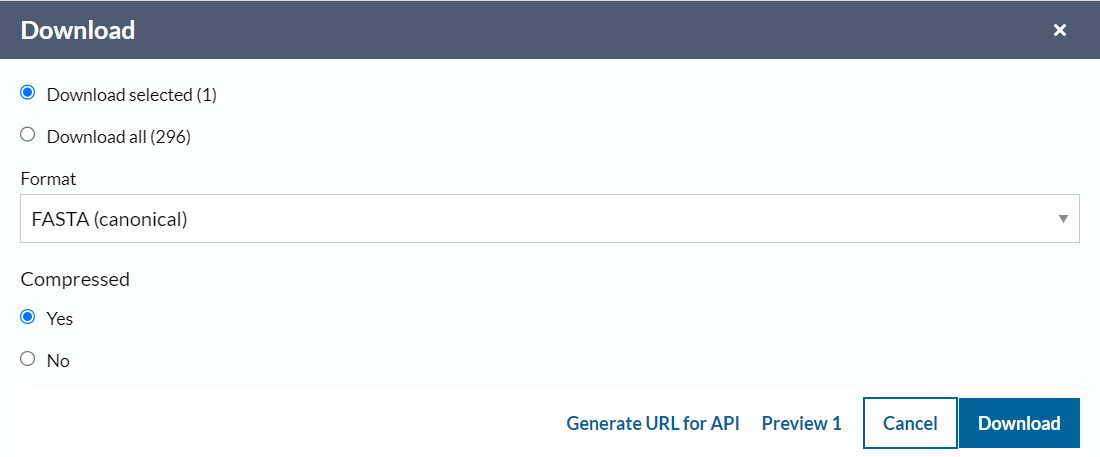
下载对应的fasta序列来看看:
3.2、UniProt Fasta 文件介绍
>sp|Q01860|PO5F1_HUMAN POU domain, class 5, transcription factor 1 OS=Homo sapiens OX=9606 GN=POU5F1 PE=1 SV=1
MAGHLASDFAFSPPPGGGGDGPGGPEPGWVDPRTWLSFQGPPGGPGIGPGVGPGSEVWGI
PPCPPPYEFCGGMAYCGPQVGVGLVPQGGLETSQPEGEAGVGVESNSDGASPEPCTVTPG
AVKLEKEKLEQNPEESQDIKALQKELEQFAKLLKQKRITLGYTQADVGLTLGVLFGKVFS
QTTICRFEALQLSFKNMCKLRPLLQKWVEEADNNENLQEICKAETLVQARKRKRTSIENR
VRGNLENLFLQCPKPTLQQISHIAQQLGLEKDVVRVWFCNRRQKGKRSSSDYAQREDFEA
AGSPFSGGPVSFPLAPGPHFGTPGYGSPHFTALYSSVPFPEGEAFPPVSVTTLGSPMHSN
首先看 > 后的注释信息
-
sp:Swiss-Prot数据库的简称,也就是上面说的验证后的蛋白数据库
-
Q01860:UniProt ID号
-
PO5F1_HUMAN:是UniProt 的登录名
-
POU domain, class 5, transcription factor 1:蛋白质名称
-
OS=Homo sapiens:OS是Organism简称,Homo sapiens为人的拉丁文分类命名,也就是这是人的蛋白质
-
OX=9606:Organism Taxonomy,也就是物种分类数据库Taxonomy ID
-
GN=POU5F1:Gene name,基因名为POU5F1
-
PE=1:Protein Existence,蛋白质可靠性,对应5个数字,数字越小越可靠:
-
- 1:Experimental evidence at protein level
- 2:Experimental evidence at tranlevel
- 3:Protein inferred from homology
- 4:Protein predicted
- 5:Protein uncertain
-
SV=1:Sequence Version,序列版本号
3.3、查询蛋白质高级搜索
1、点击 Advanced展开左侧菜单
2、点击蓝色按钮选择搜索字段,在对应右侧输入框填写内容
3、如果不需要字段置空,或者点击 Remove移除
4、填写如下内容,即可搜索得到还有蛋白质三维结构的蛋白质列表
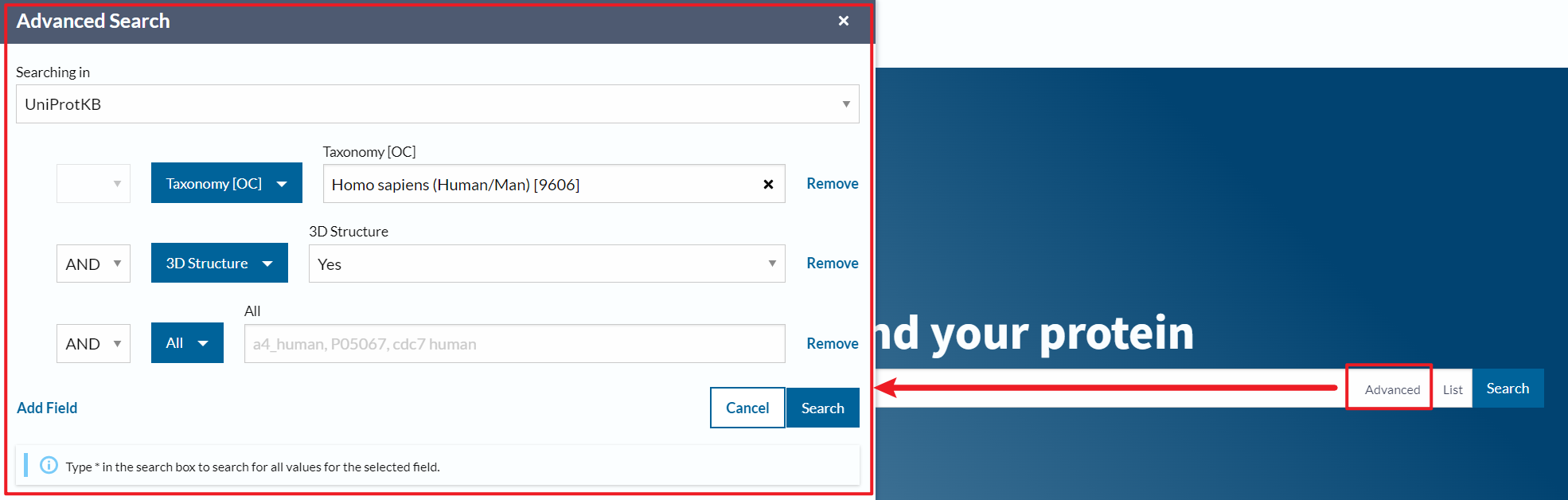
5、进入搜索结果
[https://www.uniprot.org/uniprotkb?query=(taxonomy_id:9606)%20AND%20(structure_3d:true)](https://www.uniprot.org/uniprotkb?query=(taxonomy_id:9606) AND (structure_3d:true))
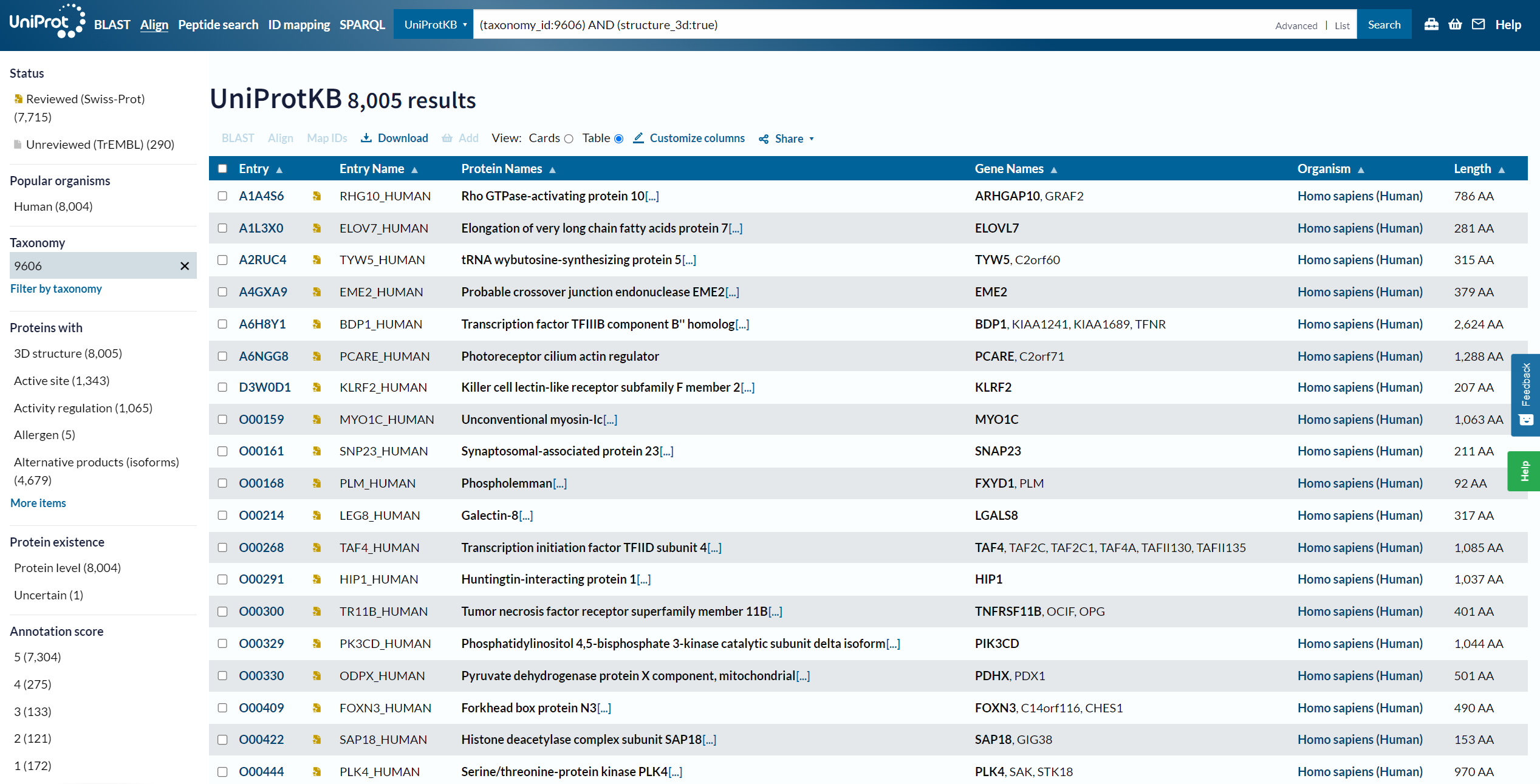
3.4、蛋白质 ID 转换
1、进入官网https://www.uniprot.org/
可以在两个入口,点击后进入

2、工作页面
这里以下列蛋白质 ID 作为输入,搜索这些蛋白质三维结构的 PDB ID 为例
A1A4S6
A1L3X0
A2RUC4
A4GXA9
A6H8Y1
A6NGG8
D3W0D1
O00159
O00161
O00168
O00214
O00268
O00291
O00300
O00329
O00330
O00409
O00422
O00444
O00478
O00487
O00506
O00560
O00622
O00746
在 From database中选择我们的输入数据格式是 UniprotKB AC/ID
在 To database中选择我们需要转换的 PDB
点击 Map进入工作流程
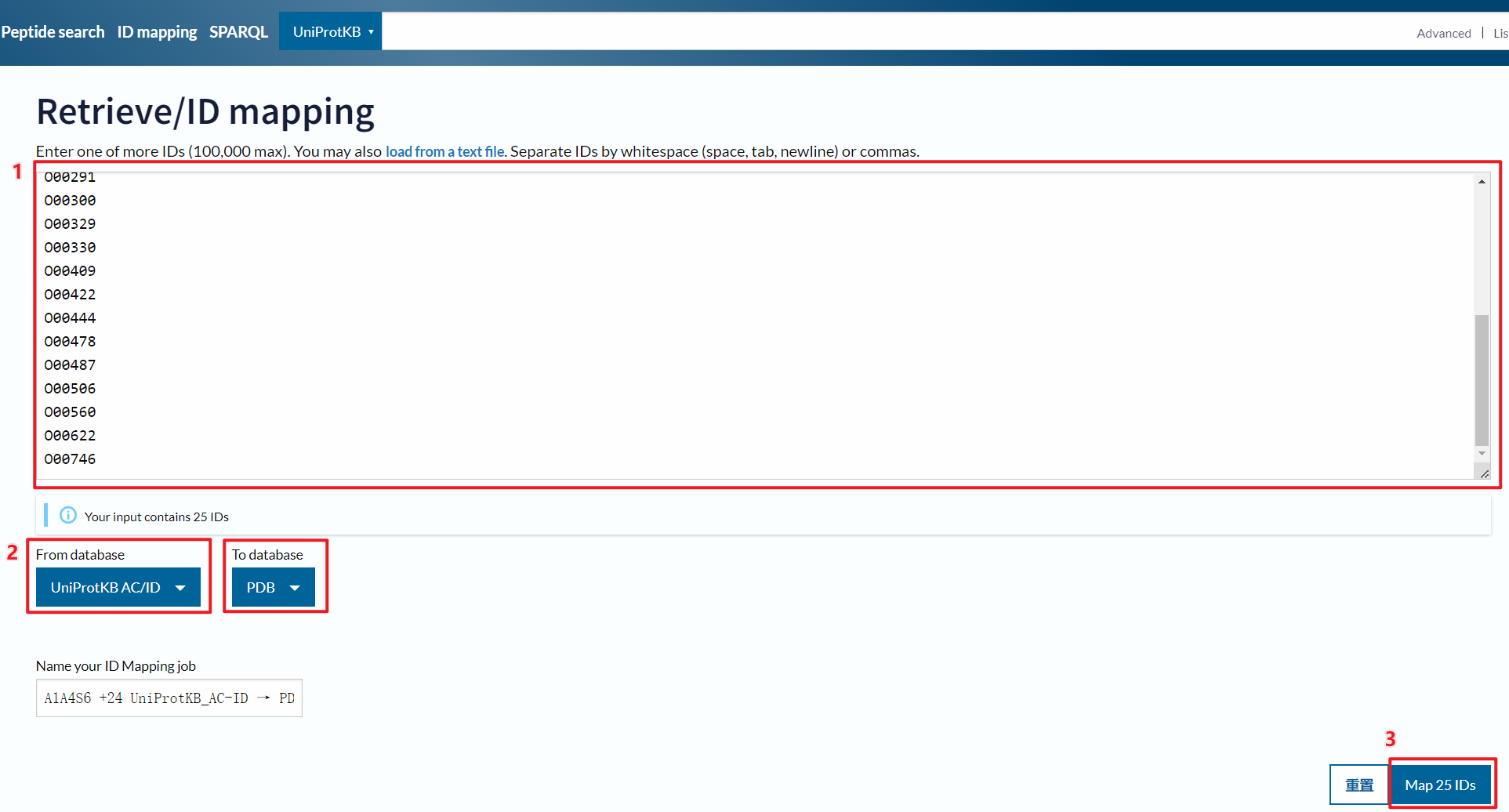
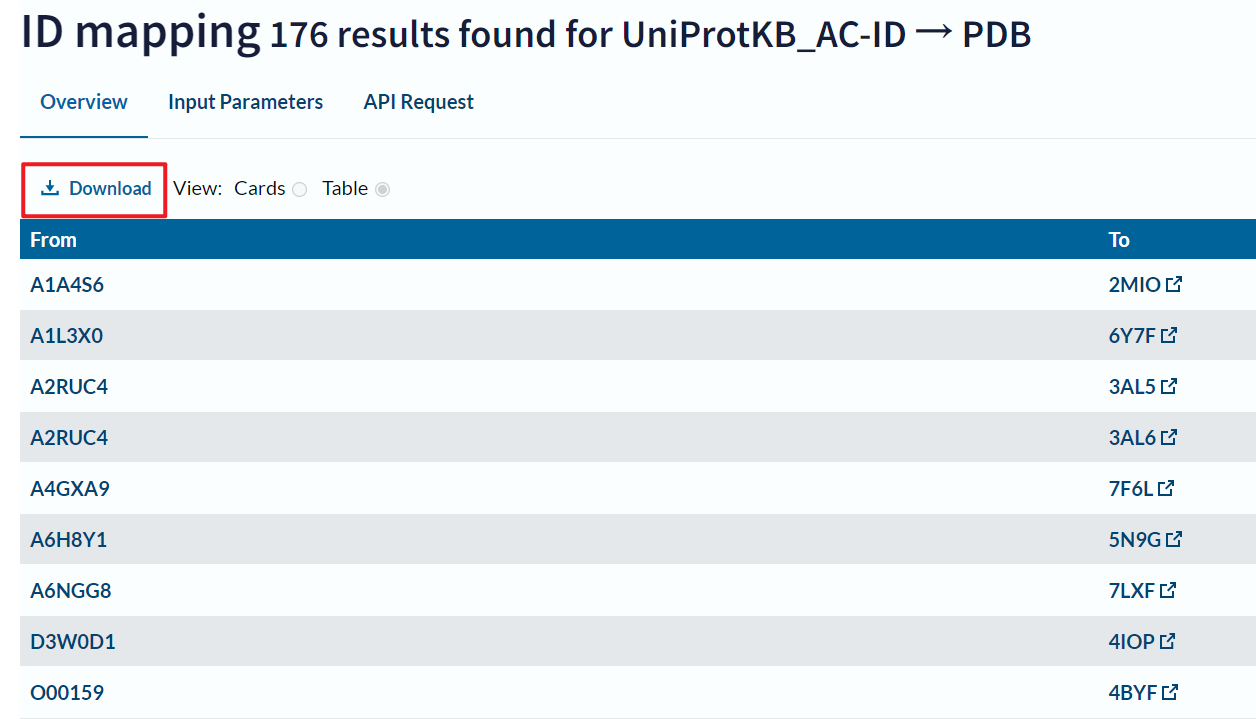
点击 Completed进入工作结果页面
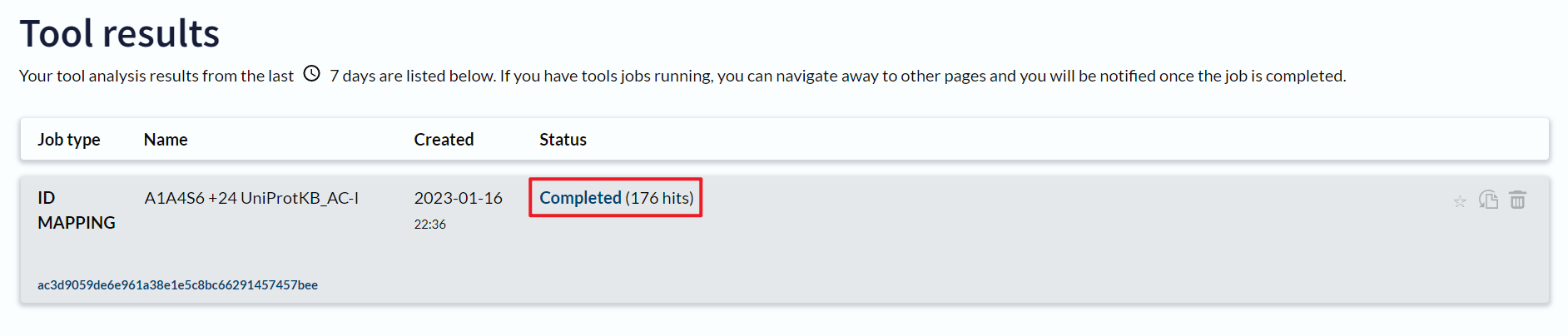
这里显示了匹配的 PDB id,因为一个 蛋白质ID 可能对应多个PDB ID,因此转换结果较多。
点击 Download进行下载
四、UniProtKB/TrEMBL 介绍
在认识到序列数据的生成速度超过了Swiss-Prot的注释能力时,为了给不在Swiss-Prot中的那些蛋白质提供自动注释,UniProt创建了TrEMBL(翻译的EMBL核苷酸序列数据库)。
在三大核酸数据库(EMBL-Bank/GenBank/DDBJ)中注释的编码序列都会被自动翻译并加入该数据库中。它也有来自PDB数据库的序列,以及Ensembl、Refeq和CCDS基因预测的序列。之前提到的PIR组织制作了蛋白质序列数据库(PIR-PSD)也包含在其中。
五、UniParc 介绍
UniProt Archive(UniParc)包含来自主要公共可用蛋白质序列数据库的所有蛋白质序列的非冗余数据集。蛋白质可能存在于几个不同的来源数据库中,并且在同一数据库中存在多个副本。 为了避免冗余,UniParc仅将每个唯一序列存储一次。 相同序列被合并,无论它们来自相同还是不同物种。 每个序列都有一个稳定且唯一的标识符(UPI),从而可以从不同的来源数据库中识别相同的蛋白质。
UniParc仅包含蛋白质序列,没有注释。 UniParc条目中的数据库交叉引用允许从源数据库检索有关该蛋白质的更多信息。 当源数据库中的序列发生更改时,UniParc将跟踪这些更改,并记录所有更改的历史记录。
六、UniRef 介绍
UniProt Reference Clusters(UniRef):聚类序列可显著减小数据库大小,从而加快序列搜索的速度。用于计算的蛋白质序列来自UniProtKB和部分UniParc记录的序列。
UniRef100序列将相同的序列和序列片段(来自任何生物)合并到一个UniRef条目中,用于显示代表性蛋白质的序列。 使用CD-HIT算法对UniRef100序列进行聚类,并构建UniRef90和UniRef50。UniRef90和UniRef50分别代表每个簇由与最长序列分别具有至少90%或50%序列同一性的序列组成。
七、蛋白质结构和序列预测的更新
最新版的 UniProt 整合了深度学习模型预测的结果,包括:
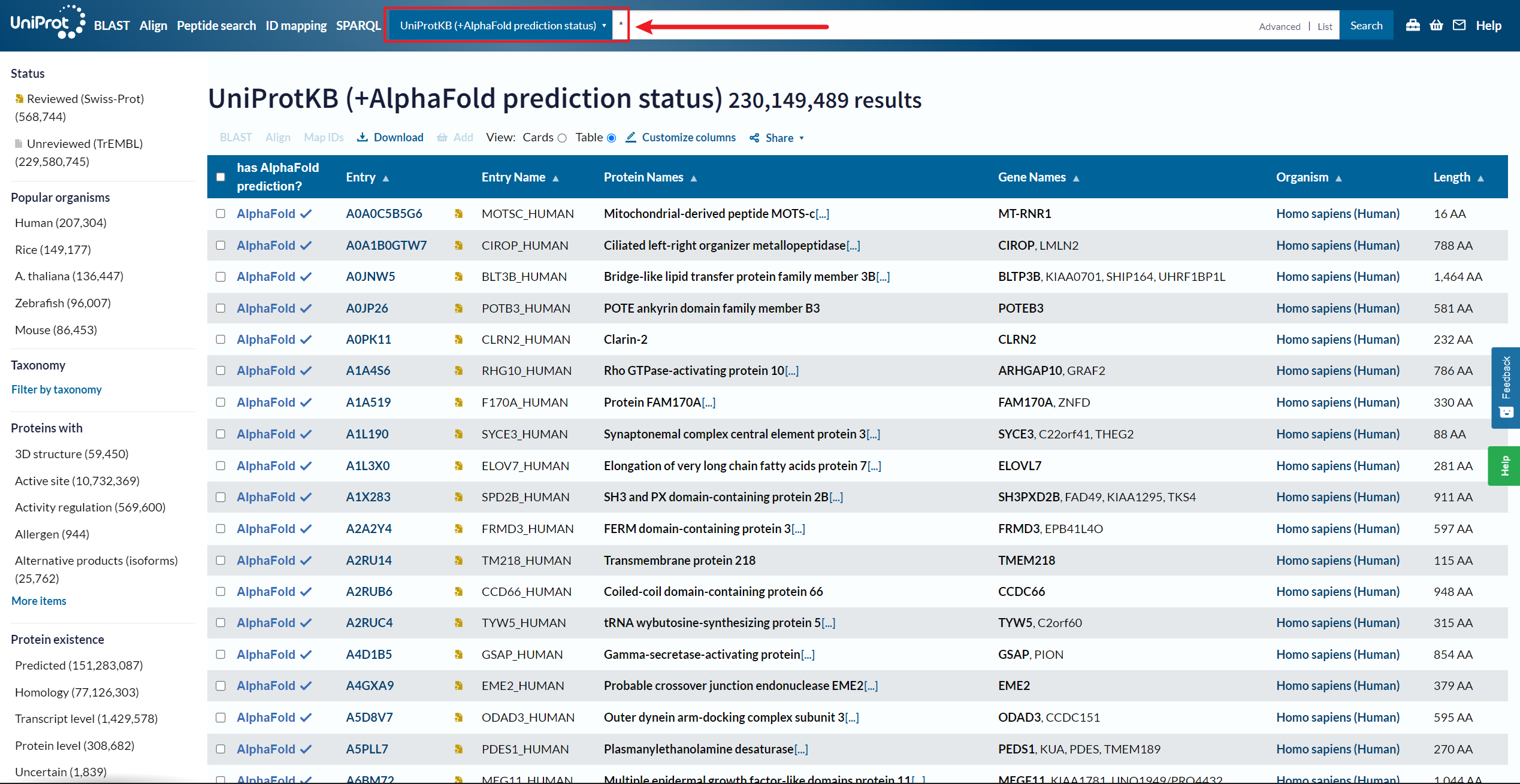
1、由 DeepMind 团队构建 AlphaFold2 预测的蛋白质三维结构
官网:https://alphafold.ebi.ac.uk/
Uniprot 资源:https://www.uniprot.org/alphafold?query=*
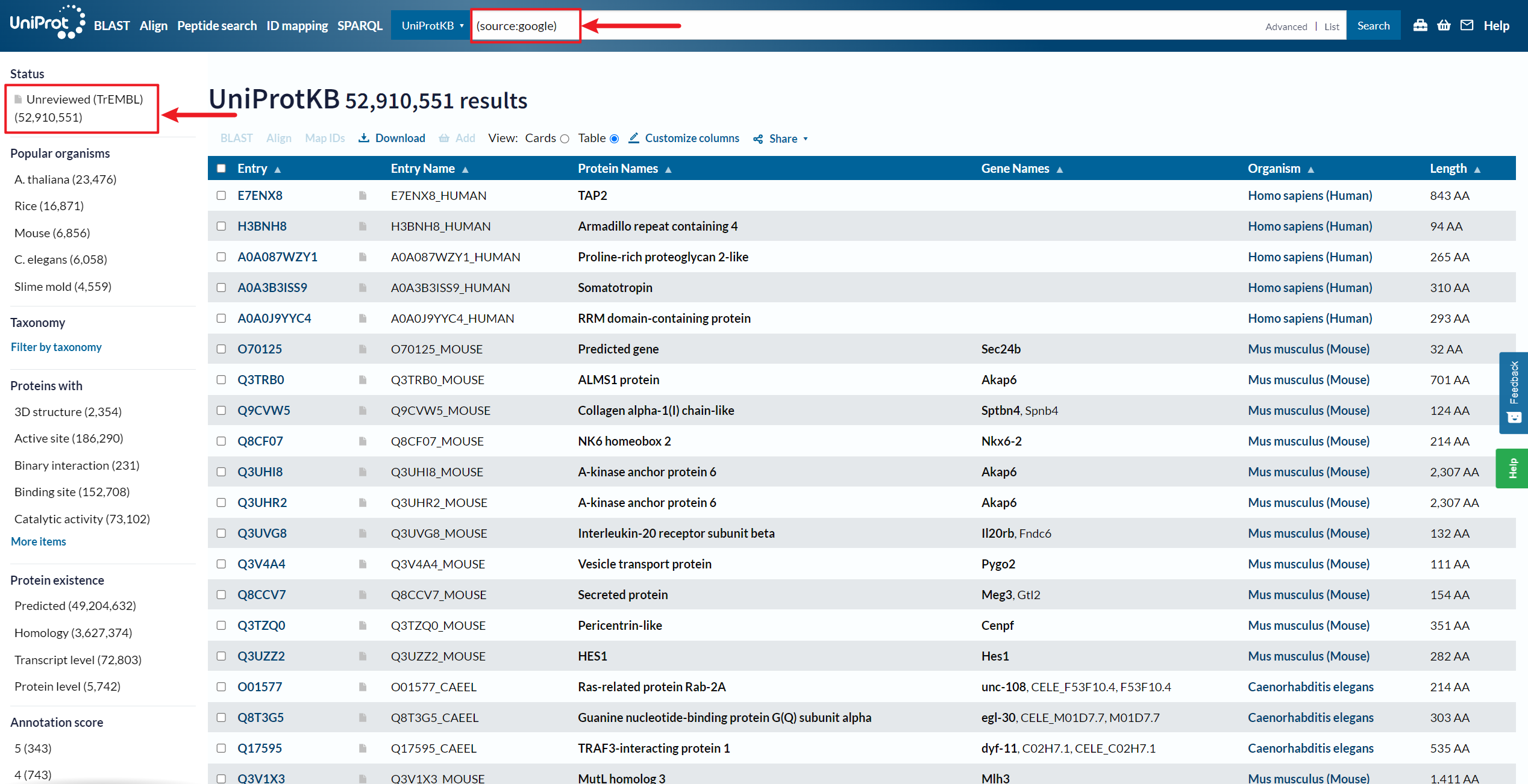
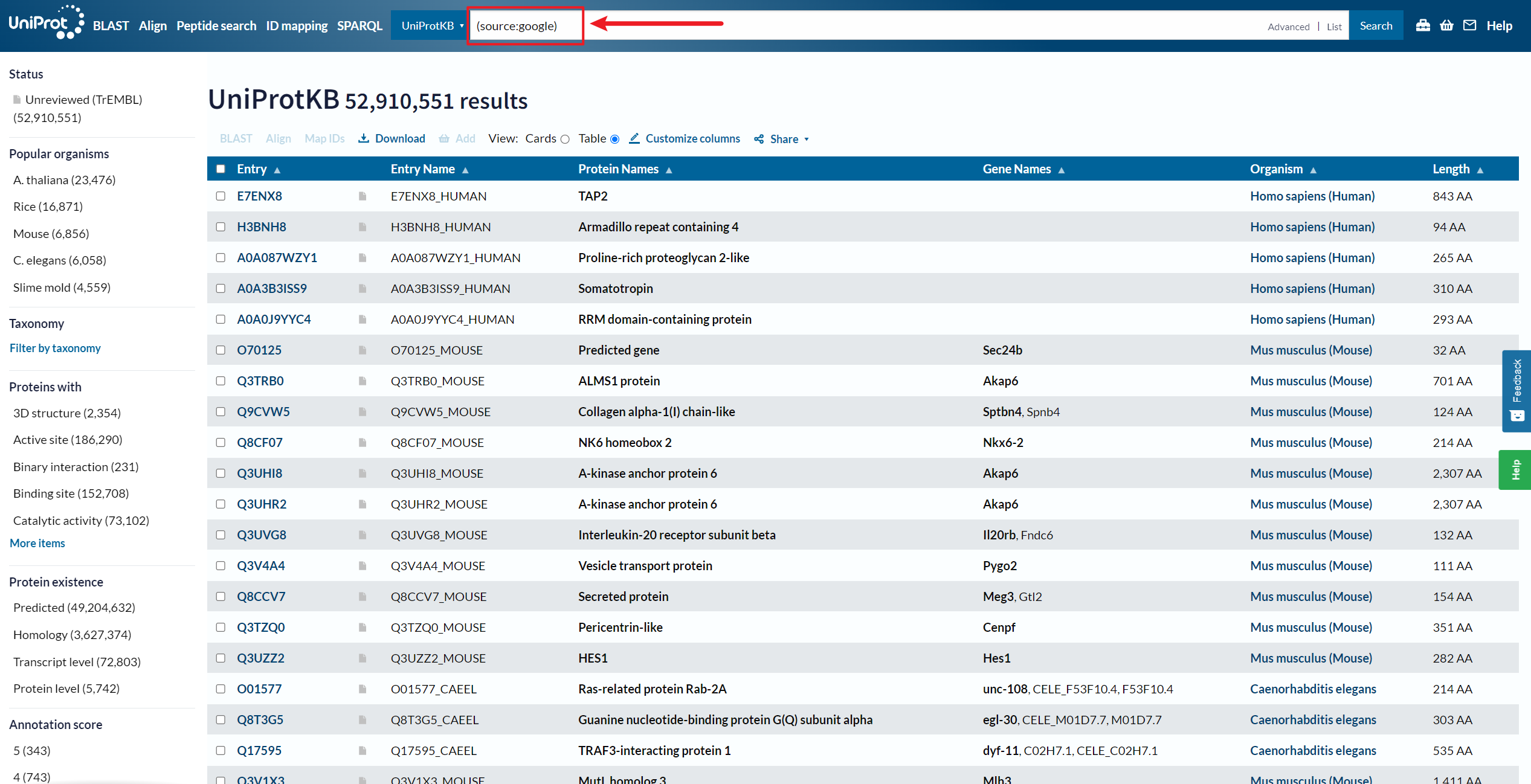
2、由 Google Brain 团队构建ProtNLM 预测的蛋白质序列注释,
预印本:https://proceedings.neurips.cc/paper/2017/file/3f5ee243547dee91fbd053c1c4a845aa-Paper.pdf
UniProt 资源:https://www.uniprot.org/uniprotkb?query=(source:google)
不得不说,现在生信是越来越卷了。。。
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)