Introduction to financial concepts and data
Optiver波动率预测 概述 评估 时间线
金融概念与数据介绍 订单簿(Order Book) 交易(Trade) 做市与市场效率 订单簿统计数据 买卖差价(Bid/Ask Spread) 加权平均价格(Weighted averaged price) 对数收益率(Log Return) 已实现波动率Realized volatility 竞赛数据Competition data 订单簿数据快照 **交易数据快照** **Realized volatility calculation in python** 让我们绘制该工具在此时间段内的逐笔回报 朴素预测:使用过去的已实现波动率作为目标 提交submission
本篇博客是对Kaggle竞赛Optiver Realized Volatility Prediction中金融概念与数据介绍笔记本的翻译。
概述
波动性(Volatility)**是您在任何交易大厅都会听到的最重要的术语之一——这是有充分理由的。 在金融市场中,波动率反映了价格的波动幅度。 高波动性与市场动荡时期和价格大幅波动有关,而低波动性则描述更平静和安静的市场。 对于像 Optiver 这样的交易公司来说,准确预测波动率对于期权交易至关重要,期权的价格与标的产品的波动率直接相关。
作为全球领先的电子做市商,Optiver 致力于不断改善金融市场,为全球众多交易所的期权、ETF、现金股票、债券和外币创造更好的准入和价格。 Optiver 的团队花费了无数个小时来构建复杂的模型,以预测波动性并不断为最终投资者生成更公平的期权价格。然而,行业领先的定价算法永远不会停止发展,没有比 Kaggle 更好的地方可以帮助 Optiver 将其模型提升到一个新的水平。
在本次比赛的前三个月,您将构建模型来预测不同行业数百只股票的短期波动。您将拥有触手可及的数亿行高度细化的财务数据,您将利用这些数据设计预测 10 分钟内波动率的模型。您的模型将根据训练后三个月评估期内收集的真实市场数据进行评估。
通过本次比赛,您将获得对波动性和金融市场结构的宝贵洞察。您还将更好地了解 Optiver 几十年来面临的数据科学问题。我们期待看到 Kaggle 社区将创造性的方法应用于这个复杂但令人兴奋的交易挑战。
为了让 Kagglers 更好地为这次比赛做好准备,Optiver 的数据科学家创建了一个教程笔记本 汇报本次交易挑战的竞争数据和相关财务概念。 此外,Optiver 的在线课程可以告诉您更多有关金融市场和做市商的信息。
评估
提交将使用百分比均方根误差进行评估,定义如下:
RMSPE
=
1
n
∑
i
=
1
n
(
(
y
i
−
y
^
i
)
/
y
i
)
2
\text{RMSPE} = \sqrt{\frac{1}{n} \sum_{i=1}^{n} ((y_i - \hat{y}_i)/y_i)^2}
RMSPE = n 1 i = 1 ∑ n ( ( y i − y ^ i ) / y i ) 2
row_id,您必须预测目标变量。 该文件应包含标题并具有以下格式:
row_id,target
0-0,0.003
0-1,0.002
0-2,0.001
...
并且必须通过Notebooks来提交代码,运行时间不能超过九个小时。
禁用互联网访问 允许免费和公开可用的外部数据,包括预先训练的模型 提交文件必须被命名为 submission.csv 时间线
这是一个具有活跃训练阶段和模型将针对真实市场数据运行的第二阶段的预测竞赛。
2021年6月28日,开始 2021年9月20日,报名截止,您必须在此日期之前接受比赛规则才能参加比赛。 2021 年 9 月 20 日, 团队合并截止日期。 这是参与者可以加入或合并团队的最后一天。 2021年9月27日,最终提交的截止日期。 除非另有说明,所有截止日期均为 UTC 相应日期晚上 11:59。 比赛组织者保留在其认为必要时更新比赛时间表的权利。
预测时间线
在最终提交截止日期之后,排行榜将定期更新,以反映将针对选定笔记本运行的市场数据更新。
2022 年 1 月 10 日 - 比赛结束日期
金融概念与数据介绍
为了让 Kagglers 更好地为这场比赛做好准备,Optiver 的数据科学家创建了一个教程笔记本,循环介绍了这一特定交易挑战中涵盖的一些金融概念。 此外,数据结构和示例代码提交也将在此笔记本中呈现。
订单簿(Order Book)
术语订单簿(Order Book)是指按价格水平组织的特定证券或金融工具的买卖订单电子清单。 订单簿列出了在每个价格点上出价或提供的股票数量。
下面是股票(Stock)(我们称之为股票 A)的订单簿的快照,如您所见,所有预期的买单(buy orders)都在书的左侧显示为“出价(bid)”,而所有预期的卖单都在右侧 书的一面显示为“要约(offer)/要价(ask)”
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-NCx7eLa2-1628163728279)(https://www.optiver.com/wp-content/uploads/2021/05/OrderBook3.png)]
交易活跃的金融工具总是有一个密集的订单簿(流动账簿)。 由于订单簿数据是市场需求/供应的连续表示,因此它始终被视为市场研究的第一大数据源。
交易(Trade)
订单簿是市场交易意图的表示,但市场需要以相同价格的买方和卖方才能进行交易。 因此,有时当有人想要进行股票交易时,他们会查看订单簿并找到有相反兴趣的人进行交易。
例如,假设您想购买 20 股 股票A,而您有上一段中的订单簿。 然后,您需要找到一些愿意通过总共卖出 20 股或更多股票来与您进行交易的人。 您从最低价开始检查订单簿的报价方:在 148 的水平上有 221 股的卖出兴趣。您可以以 148 的价格举起 20 股并保证您的执行。 这将是您交易后生成的股票 A 订单簿:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-dBqa8M7l-1628163728280)(https://www.optiver.com/wp-content/uploads/2021/05/OrderBook4.png)]
在这个案例中,出售者卖出了20股股票,买家买入了20股股票,交易所将匹配卖家和买家之间的订单,并向公众广播一条交易消息。
20股A股以148的价格在市场上交易。
与订单簿数据类似,交易数据对Optiver数据科学家同样至关重要,因为它反映了市场的活跃程度。实际上,金融市场的一些常见技术信号是直接从交易数据中得出的,例如高低或总交易量。
做市与市场效率
想象一下,在另一天,股票 A 的订单簿变得低于模型(shape),而您又想从所有有意卖家那里购买 20 股。 正如你所看到的,这本订单簿没有上一本那么密集,可以说,与上一本相比,这本书流动性较差。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-0WB9jxVD-1628163728282)(https://www.optiver.com/wp-content/uploads/2021/05/OrderBook5.png)]
您可以插入一个在 148 买入的订单。但是,目前没有人愿意在 148 向您卖出,所以您的订单将被放置在账簿中,等待有人与它进行交易。 如果运气不好,价格就会上涨,其他人会以 149 开始出价,而您根本就买不到。 或者,您可以插入一个以 155 买入的订单。交易所会将此订单与未完成的 149 股的卖出订单进行匹配,因此您以 149 买入 1 手。同样,您将以 150 的价格买入 12 股 , 以及 7 股 151。与尝试以 148 买入相比,不存在无法获得所需交易的风险,但最终以更高的价格买入。
您可以看到在这样一个低效的市场中很难交易,因为交易会更加昂贵,如果您希望订单的质量执行,您需要应对更高的市场风险。 这就是为什么投资者喜欢流动性,而无论市场条件多么极端,像 Optiver 这样的做市商都会提供它。
做市商是主动对证券的双向市场报价的公司或个人,提供买价和卖价(称为要价)以及每个的市场规模。 由于做市商会同时显示买入和卖出订单,因此有做市商存在的订单簿将更具流动性,因此将为最终投资者提供更有效的市场,可以自由交易而无需担心执行。
订单簿统计数据
Optiver 数据科学家可以从原始订单簿数据中得出很多统计数据,以反映市场流动性和股票估值。 这些统计数据被证明是任何市场预测算法的基本输入。 下面我们想列出一些常见的统计数据,以激励 Kagglers 从订单数据中挖掘更有价值的信号。
买卖差价(Bid/Ask Spread)
由于不同股票在市场上的交易水平不同,我们采用最佳报价和最佳买入价的比率来计算买卖价差。
买卖价差的公式可以写成以下形式:
B
i
d
A
s
k
S
p
r
e
a
d
=
B
e
s
t
O
f
f
e
r
/
B
e
s
t
B
i
d
−
1
BidAskSpread = BestOffer/BestBid -1
B i d A s k S p r e a d = B e s t O f f e r / B e s t B i d − 1
加权平均价格(Weighted averaged price)
订单簿也是股票估值的主要来源之一。 公平的账面估值必须考虑两个因素:订单的水平(level)和规模(size)。 在本次比赛中,我们使用加权平均价格 (WAP) 来计算瞬时股票估值并计算已实现的波动率作为我们的目标。
WAP的公式可以写成如下,它考虑了顶级价格和数量信息:
W
A
P
=
B
i
d
P
r
i
c
e
1
∗
A
s
k
S
i
z
e
1
+
A
s
k
P
r
i
c
e
1
∗
B
i
d
S
i
z
e
1
B
i
d
S
i
z
e
1
+
A
s
k
S
i
z
e
1
WAP = \frac{BidPrice_{1}*AskSize_{1} + AskPrice_{1}*BidSize_{1}}{BidSize_{1} + AskSize_{1}}
W A P = B i d S i z e 1 + A s k S i z e 1 B i d P r i c e 1 ∗ A s k S i z e 1 + A s k P r i c e 1 ∗ B i d S i z e 1
请注意,在大多数情况下,在连续交易时间内,订单簿不应出现买单高于要约(offer)或要价(ask)的情况。 换句话说,最有可能的是,买入价(bid)和卖出价(ask)永远不应该交叉。
在本次比赛中,目标是从 WAP 构建的。 订单簿快照的 WAP 为 147.5317797。
对数收益率(Log Return)
我们如何比较昨天和今天的股票价格?
最简单的方法就是取差额。 这绝对是最直观的方式,但是不同股票的价格差异并不总是具有可比性。 例如,假设我们在股票 A 和股票 B 上都投资了 1000 美元,股票 A 从 100 美元涨到 102 美元,股票 B 从 10 美元涨到 11 美元。我们总共有 10 股 A
(
1000
/
100
=
10
)
( 1000 / 100=10 )
( 1 0 0 0 / 1 0 0 = 1 0 )
10
⋅
(
102
−
100
)
=
20
10⋅(102−100)=20
1 0 ⋅ ( 1 0 2 − 1 0 0 ) = 2 0
我们可以通过将变化量除以股票的起始价格来解决上述问题,有效地计算价格变化的百分比,也称为股票收益(stock return)。 在我们的例子中,股票 A 的回报是 $(102−100)/100=2% $ ,而股票 B 的回报是
(
11
−
10
)
10
=
10
(11−10)10=10%
( 1 1 − 1 0 ) 1 0 = 1 0 股票回报(Return)与我们投资资本的百分比变化一致。
收益率在金融中被广泛使用,但是当需要一些数学建模时,对数回报是首选 。 将 St 称为股票 S 在时间 t 的价格,我们可以将 t1 和 t2 之间的对数收益定义为:
r
t
1
,
t
2
=
log
(
S
t
2
S
t
1
)
r_{t_1, t_2} = \log \left( \frac{S_{t_2}}{S_{t_1}} \right)
r t 1 , t 2 = log ( S t 1 S t 2 )
r
t
=
r
t
−
10
m
i
n
,
t
r_t=r_{t-10min,t}
r t = r t − 1 0 m i n , t
它们随着时间的推移是可加的
r
t
1
,
t
2
+
r
t
2
,
t
3
=
r
t
1
,
t
3
r_{t_1, t_2} + r_{t_2, t_3} = r_{t_1, t_3}
r t 1 , t 2 + r t 2 , t 3 = r t 1 , t 3
常规收益率不能低于 -100%,而对数收益率不受限制
已实现波动率Realized volatility
当我们交易期权options时,我们模型的一个有价值的输入是股票对数收益率的标准差 。 在更长或更短的时间间隔内计算的对数收益率的标准差会有所不同,因此它通常被标准化为 1 年期,年化标准差称为波动率 。
在本次比赛中,您将获得 10 分钟的账面数据,我们要求您预测接下来 10 分钟的波动性。 波动率将按如下方式测量:
我们将计算所有连续账簿更新的对数收益率 ,并将实现的波动率 σ 定义为对数收益率平方和的平方根 。
σ
=
∑
t
r
t
−
1
,
t
2
\sigma = \sqrt{\sum_{t}r_{t-1, t}^2}
σ = t ∑ r t − 1 , t 2
我们希望定义尽可能简单明了,这样没有金融知识的 Kagglers 就不会受到惩罚。 所以我们没有对波动率进行年化,我们假设对数回报的平均值为 0。
竞赛数据Competition data
在本次比赛中,Kagglers 面临的挑战是从固定 10 分钟窗口的账面和交易数据中生成一系列短期信号,以预测下一个 10 分钟窗口的已实现波动率。 在 train/test.csv 中给出的目标可以通过相同的 time_id 和 stock_id 与原始订单簿/交易数据链接。 特征和目标窗口之间没有重叠。
请注意,比赛数据将附带分区的账面和交易数据文件。 您可以在此 notebook 中找到有关账面和交易数据文件处理的教程。
In[1]:
import pandas as pd
import numpy as np
import plotly. express as px
train = pd. read_csv( '../input/optiver-realized-volatility-prediction/train.csv' )
train. head( )
Out[1]:
stock_id time_id target 0 0 5 0.004136 1 0 11 0.001445 2 0 16 0.002168 3 0 31 0.002195 4 0 62 0.001747
取第一行数据,表示time_id 5、stock_id 0的目标bucket的实现vol为0.004136。 特征桶中的账簿和交易数据如何构建信号?
In[2]:
book_example = pd. read_parquet( '../input/optiver-realized-volatility-prediction/book_train.parquet/stock_id=0' )
trade_example = pd. read_parquet( '../input/optiver-realized-volatility-prediction/trade_train.parquet/stock_id=0' )
stock_id = '0'
book_example = book_example[ book_example[ 'time_id' ] == 5 ]
book_example. loc[ : , 'stock_id' ] = stock_id
trade_example = trade_example[ trade_example[ 'time_id' ] == 5 ]
trade_example. loc[ : , 'stock_id' ] = stock_id
订单簿数据快照
In[3]:
book_example. head( )
Out[3]:
time_id seconds_in_bucket bid_price1 ask_price1 bid_price2 ask_price2 bid_size1 ask_size1 bid_size2 ask_size2 stock_id 0 5 0 1.001422 1.002301 1.00137 1.002353 3 226 2 100 0 1 5 1 1.001422 1.002301 1.00137 1.002353 3 100 2 100 0 2 5 5 1.001422 1.002301 1.00137 1.002405 3 100 2 100 0 3 5 6 1.001422 1.002301 1.00137 1.002405 3 126 2 100 0 4 5 7 1.001422 1.002301 1.00137 1.002405 3 126 2 100 0
交易数据快照 In[4]:
trade_example. head( )
Out[4]:
time_id seconds_in_bucket price size order_count stock_id 0 5 21 1.002301 326 12 0 1 5 46 1.002778 128 4 0 2 5 50 1.002818 55 1 0 3 5 57 1.003155 121 5 0 4 5 68 1.003646 4 1 0
Realized volatility calculation in python 在这场比赛中,我们的目标是预测短期的已实现波动率。 虽然无法共享目标的订单簿和交易数据,但我们仍然可以使用我们提供的特征数据呈现已实现的波动率计算。
由于已实现波动率是给定股票价格变化的统计量度,为了计算价格变化,我们首先需要在固定时间间隔(1 秒)进行股票估值。 我们将使用我们提供的订单簿数据的加权平均价格或 WAP。
book_example[ 'wap' ] = ( book_example[ 'bid_price1' ] * book_example[ 'ask_size1' ] +
book_example[ 'ask_price1' ] * book_example[ 'bid_size1' ] ) / (
book_example[ 'bid_size1' ] + book_example[ 'ask_size1' ] )
以下绘制股票的WAP
fig = px. line( book_example, x= "seconds_in_bucket" , y= "wap" , title= 'WAP of stock_id_0, time_id_5' )
fig. show( )
为了计算对数回报,我们可以简单地取两个连续 WAP 之间的比率的对数。 第一行将有一个空的回报,因为之前的书籍更新是未知的,因此空的回报数据点将被删除。
def log_return ( list_stock_prices) :
return np. log( list_stock_prices) . diff( )
book_example. loc[ : , 'log_return' ] = log_return( book_example[ 'wap' ] )
book_example = book_example[ ~ book_example[ 'log_return' ] . isnull( ) ]
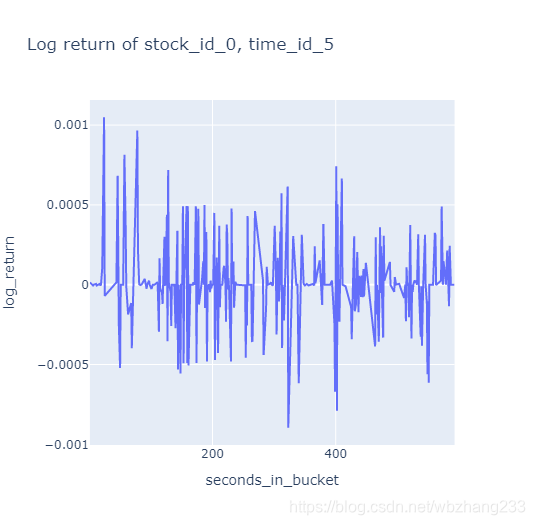
让我们绘制该工具在此时间段内的逐笔回报
fig = px. line( book_example, x= "seconds_in_bucket" , y= "log_return" , title= 'Log return of stock_id_0, time_id_5' )
fig. show( )
此特征桶中股票 0 的已实现成交量将是:
In[10]:
def realized_volatility ( series_log_return) :
return np. sqrt( np. sum ( series_log_return** 2 ) )
realized_vol = realized_volatility( book_example[ 'log_return' ] )
print ( f'Realized volatility for stock_id 0 on time_id 5 is { realized_vol} ' )
Realized volatility for stock_id 0 on time_id 5 is 0.004499364172786558
朴素预测:使用过去的已实现波动率作为目标
关于波动率的一个众所周知的事实是它往往是自相关的。 我们可以使用此属性来实现一个简单的模型,该模型仅通过使用最初 10 分钟内已实现的波动率来“预测”已实现的波动率。
让我们计算整个训练集过去实现的波动率,看看单个原始信号的预测能力如何。
import os
from sklearn. metrics import r2_score
import glob
list_order_book_file_train = glob. glob( '/kaggle/input/optiver-realized-volatility-prediction/book_train.parquet/*' )
由于本次比赛中数据通过stock_id进行分区,以便Kagglers更好地管理内存,因此我们尝试逐个计算已实现的波动率股票并将它们合并为一个提交文件。 请注意,如果我们加载单个文件,作为分区列的股票 ID 不存在,因此我们将手动修复。 我们将重用上一课中定义的对数返回和已实现的波动率函数。
def realized_volatility_per_time_id ( file_path, prediction_column_name) :
df_book_data = pd. read_parquet( file_path)
df_book_data[ 'wap' ] = ( df_book_data[ 'bid_price1' ] * df_book_data[ 'ask_size1' ] + df_book_data[ 'ask_price1' ] * df_book_data[ 'bid_size1' ] ) / (
df_book_data[ 'bid_size1' ] + df_book_data[
'ask_size1' ] )
df_book_data[ 'log_return' ] = df_book_data. groupby( [ 'time_id' ] ) [ 'wap' ] . apply ( log_return)
df_book_data = df_book_data[ ~ df_book_data[ 'log_return' ] . isnull( ) ]
df_realized_vol_per_stock = pd. DataFrame( df_book_data. groupby( [ 'time_id' ] ) [ 'log_return' ] . agg( realized_volatility) ) . reset_index( )
df_realized_vol_per_stock = df_realized_vol_per_stock. rename( columns = { 'log_return' : prediction_column_name} )
stock_id = file_path. split( '=' ) [ 1 ]
df_realized_vol_per_stock[ 'row_id' ] = df_realized_vol_per_stock[ 'time_id' ] . apply ( lambda x: f' { stock_id} - { x} ' )
return df_realized_vol_per_stock[ [ 'row_id' , prediction_column_name] ]
遍历每只个股,我们可以得到过去实现的波动率作为对每只个股的预测。
def past_realized_volatility_per_stock ( list_file, prediction_column_name) :
df_past_realized = pd. DataFrame( )
for file in list_file:
df_past_realized = pd. concat( [ df_past_realized,
realized_volatility_per_time_id( file , prediction_column_name) ] )
return df_past_realized
df_past_realized_train = past_realized_volatility_per_stock( list_file= list_order_book_file_train,
prediction_column_name= 'pred' )
让我们将输出数据帧与 train.csv连接起来,看看在训练集上的朴素预测的性能。
train[ 'row_id' ] = train[ 'stock_id' ] . astype( str ) + '-' + train[ 'time_id' ] . astype( str )
train = train[ [ 'row_id' , 'target' ] ]
df_joined = train. merge( df_past_realized_train[ [ 'row_id' , 'pred' ] ] , on = [ 'row_id' ] , how = 'left' )
我们将通过两个指标评估朴素预测结果:RMSPE 和 R 平方。
from sklearn. metrics import r2_score
def rmspe ( y_true, y_pred) :
return ( np. sqrt( np. mean( np. square( ( y_true - y_pred) / y_true) ) ) )
R2 = round ( r2_score( y_true = df_joined[ 'target' ] , y_pred = df_joined[ 'pred' ] ) , 3 )
RMSPE = round ( rmspe( y_true = df_joined[ 'target' ] , y_pred = df_joined[ 'pred' ] ) , 3 )
print ( f'Performance of the naive prediction: R2 score: { R2} , RMSPE: { RMSPE} ' )
Performance of the naive prediction: R2 score: 0.628 , RMSPE: 0.341
naive 模型的性能并不惊人,但作为基准,它是一个合理的开始。
提交submission
作为最后一步,我们将通过教程笔记本进行提交——通过写入输出文件夹的文件。朴素方法的提交在公共LB上获得了RMSE 0.327,改进空间肯定很大!
list_order_book_file_test = glob. glob( '/kaggle/input/optiver-realized-volatility-prediction/book_test.parquet/*' )
df_naive_pred_test = past_realized_volatility_per_stock( list_file= list_order_book_file_test,
prediction_column_name= 'target' )
df_naive_pred_test. to_csv( 'submission.csv' , index = False )
请注意,在本次比赛中,可以下载的测试数据只有几行。 在您提交笔记本并手动提交输出后,实际的评估程序将在后台运行。 请检查代码要求以获取更多解释。
私人排行榜将根据训练期后收集的真实市场数据构建,因此公共和私人排行榜数据将零重叠。 让您的模型在实时市场上进行测试将是令人兴奋的! 由于本次比赛将提供一个非常丰富的数据集,代表市场微观结构,因此可以提出无限量的信号。 一切都在你身上,祝你好运! 我们 Optiver 非常期待向才华横溢的 Kaggle 社区学习!
如果您对此笔记本或其背后的财务概念有任何疑问,请随时在评论部分提问,我们将确保您的问题得到解答。
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)