在企业生产环境中,随着时间的迁移数据会存在磁盘空间不足,或者机器节点故障等情况。OSD又是实际存储数据,所以扩容和缩容OSD就很有必要性
随着我们数据量的增长,后期可能我们需要对osd进行扩容。目前扩容分为两种,一种为横向扩容,另外一种为纵向扩容
- 横向扩容scale out增加节点,添加更多的节点进来,让集群包含更多的节点
- 纵向扩容scale up增加磁盘,添加更多的硬盘进行,来增加存储容量
一、横向扩容
横向扩容实际上就是把ceph osd节点安装一遍,安装步骤我这里一步带过,详细的步骤可以参考下面的文章
新添加机器

执行添加节点初始化步骤
#NTP SERVER (ntp server 与阿里与ntp时间服务器进行同步)#首先我们配置ntp server,我这里在ceph01上面配置yum install -y ntpsystemctl start ntpdsystemctl enable ntpdtimedatectl set-timezone Asia/Shanghai#将当前的 UTC 时间写入硬件时钟timedatectl set-local-rtc 0#重启依赖于系统时间的服务systemctl restart rsyslog systemctl restart crond#这样我们的ntp server自动连接到外网,进行同步 (时间同步完成在IP前面会有一个*号)[root@ceph-01 ~]# ntpq -pnremote refid st t when poll reach delay offset jitter==============================================================================120.25.115.20 10.137.53.7 2 u 8 64 17 40.203 -24.837 0.253*203.107.6.88 100.107.25.114 2 u 8 64 17 14.998 -22.611 0.186#NTP Agent (ntp agent同步ntp server时间)ntp agent需要修改ntp server的地址[root@ceph-02 ~]# vim /etc/ntp.conf server 192.168.31.20 iburst#server 0.centos.pool.ntp.org iburst#server 1.centos.pool.ntp.org iburst#server 2.centos.pool.ntp.org iburst#server 3.centos.pool.ntp.org iburst#注释默认的server,添加一条我们ntp server的地址[root@ceph-02 ~]# systemctl restart ntpd[root@ceph-02 ~]# systemctl enable ntpd#等待几分钟出现*号代表同步完成[root@ceph-02 ~]# ntpq -pnremote refid st t when poll reach delay offset jitter==============================================================================*192.168.31.20 120.25.115.20 3 u 13 64 1 0.125 -19.095 0.095#ceph-03节点操作相同在ntp_agent节点添加定时同步任务$ crontab -e*/5 * * * * /usr/sbin/ntpdate 192.168.31.20ntp时间服务器设置完成后在所有节点修改时区以及写入硬件timedatectl set-timezone Asia/Shanghai#将当前的 UTC 时间写入硬件时钟timedatectl set-local-rtc 0#重启依赖于系统时间的服务systemctl restart rsyslog systemctl restart crond校对时间[root@ceph-01 ~]# dateTue Sep 8 17:35:43 CST 2020[root@ceph-02 ~]# dateTue Sep 8 17:35:46 CST 2020[root@ceph-03 ~]# dateTue Sep 8 17:35:47 CST 2020添加host[root@ceph-01 ceph-deploy]# vim /etc/hosts192.168.31.23 ceph-04#关闭防火墙systemctl stop firewalldsystemctl disable firewalldiptables -F && iptables -X && iptables -F -t nat && iptables -X -t natiptables -P FORWARD ACCEPTsetenforce 0sed -i 's/^SELINUX=.*/SELINUX=disabled/' /etc/selinux/config#ceph yum源配置#配置centos、epeo、ceph源curl -o /etc/yum.repos.d/CentOS-Base.repo https://mirrors.aliyun.com/repo/Centos-7.repowget -O /etc/yum.repos.d/epel.repo http://mirrors.aliyun.com/repo/epel-7.repowget -O /etc/yum.repos.d/ceph.repo http://down.i4t.com/ceph/ceph.repoyum clean allyum makecache#安装cephyum install -y ceph vim wget #进入mon节点,分发配置文件,添加osd节点[root@ceph-01 ceph-deploy]# cd /root/ceph-deploy/[root@ceph-01 ceph-deploy]# ceph-deploy --overwrite-conf config push ceph-04[root@ceph-01 ceph-deploy]# ceph-deploy osd create --data /dev/sdb ceph-04#这时候可以看到节点已经添加进来了,并且ceph状态已经是OK[root@ceph-01 ceph-deploy]# ceph osd treeID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF-1 0.22449 root default-3 0.07809 host ceph-010 hdd 0.04880 osd.0 up 1.00000 1.000003 hdd 0.02930 osd.3 up 1.00000 1.00000-5 0.04880 host ceph-021 hdd 0.04880 osd.1 up 1.00000 1.00000-7 0.04880 host ceph-032 hdd 0.04880 osd.2 up 1.00000 1.00000-9 0.04880 host ceph-044 hdd 0.04880 osd.4 up 1.00000 1.00000[root@ceph-01 ceph-deploy]#[root@ceph-01 ceph-deploy]# ceph -scluster:id: c8ae7537-8693-40df-8943-733f82049642health: HEALTH_OKservices:mon: 3 daemons, quorum ceph-01,ceph-02,ceph-03 (age 11m)mgr: ceph-03(active, since 8d), standbys: ceph-02, ceph-01mds: cephfs-abcdocker:1 {0=ceph-02=up:active} 2 up:standbyosd: 5 osds: 5 up (since 7m), 5 in (since 7m)rgw: 1 daemon active (ceph-01)task status:data:pools: 9 pools, 384 pgsobjects: 320 objects, 141 MiBusage: 5.5 GiB used, 224 GiB / 230 GiB availpgs: 384 active+clean
二、纵向扩容
纵向扩容即添加一块新硬盘即可 (我这里只添加ceph-01服务器一块30G盘)
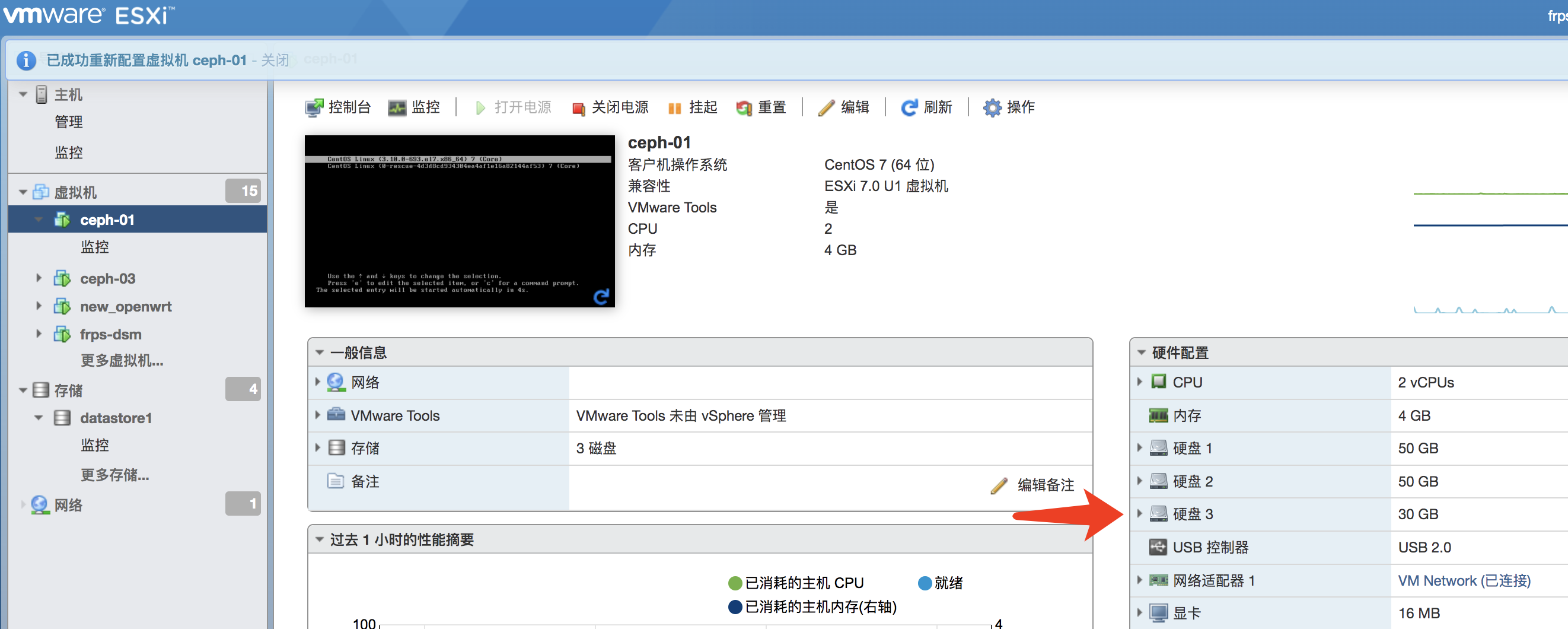
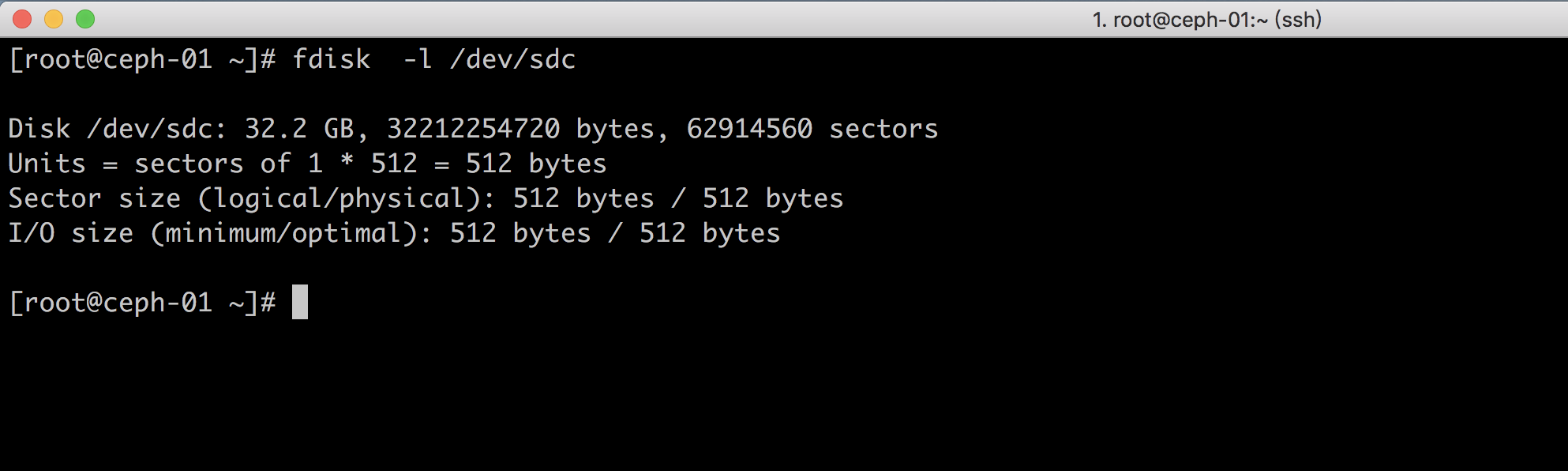
如果我们新增的硬盘有数据和分区需要初始化,可以通过下面的命令进行处理
[root@ceph-01 ~]# fdisk -l /dev/sdc #查看目前的硬盘空间Disk /dev/sdc: 32.2 GB, 32212254720 bytes, 62914560 sectorsUnits = sectors of 1 * 512 = 512 bytesSector size (logical/physical): 512 bytes / 512 bytesI/O size (minimum/optimal): 512 bytes / 512 bytes[root@ceph-01 ~]# cd ceph-deploy #需要进入到我们的ceph.conf目录,否则执行命令会报错[root@ceph-01 ceph-deploy]# ceph-deploy disk zap ceph-01 /dev/sdc #执行初始化命令,ceph-01为需要初始化的节点,/dev/sdc初始化硬盘[ceph_deploy.conf][DEBUG ] found configuration file at: /root/.cephdeploy.conf[ceph_deploy.cli][INFO ] Invoked (2.0.1): /bin/ceph-deploy disk zap ceph-01 /dev/sdc[ceph_deploy.cli][INFO ] ceph-deploy options:[ceph_deploy.cli][INFO ] username : None[ceph_deploy.cli][INFO ] verbose : False[ceph_deploy.cli][INFO ] debug : False[ceph_deploy.cli][INFO ] overwrite_conf : False[ceph_deploy.cli][INFO ] subcommand : zap[ceph_deploy.cli][INFO ] quiet : False[ceph_deploy.cli][INFO ] cd_conf : <ceph_deploy.conf.cephdeploy.Conf instance at 0x283f290>[ceph_deploy.cli][INFO ] cluster : ceph[ceph_deploy.cli][INFO ] host : ceph-01[ceph_deploy.cli][INFO ] func : <function disk at 0x282c7d0>[ceph_deploy.cli][INFO ] ceph_conf : None[ceph_deploy.cli][INFO ] default_release : False[ceph_deploy.cli][INFO ] disk : ['/dev/sdc'][ceph_deploy.osd][DEBUG ] zapping /dev/sdc on ceph-01[ceph-01][DEBUG ] connected to host: ceph-01[ceph-01][DEBUG ] detect platform information from remote host[ceph-01][DEBUG ] detect machine type[ceph-01][DEBUG ] find the location of an executable[ceph_deploy.osd][INFO ] Distro info: CentOS Linux 7.4.1708 Core[ceph-01][DEBUG ] zeroing last few blocks of device[ceph-01][DEBUG ] find the location of an executable[ceph-01][INFO ] Running command: /usr/sbin/ceph-volume lvm zap /dev/sdc[ceph-01][WARNIN] --> Zapping: /dev/sdc[ceph-01][WARNIN] --> --destroy was not specified, but zapping a whole device will remove the partition table[ceph-01][WARNIN] Running command: /bin/dd if=/dev/zero of=/dev/sdc bs=1M count=10 conv=fsync[ceph-01][WARNIN] stderr: 10+0 records in[ceph-01][WARNIN] 10+0 records out[ceph-01][WARNIN] 10485760 bytes (10 MB) copied[ceph-01][WARNIN] stderr: , 0.378842 s, 27.7 MB/s[ceph-01][WARNIN] --> Zapping successful for: <Raw Device: /dev/sdc>
实际上上面的命令只是执行了一个dd命令,将我们服务器的数据表内容清除
接下来我们执行扩容命令
#ceph-01为扩容节点名称,--data为扩容节点硬盘
[root@ceph-01 ceph-deploy]# ceph-deploy osd create ceph-01 --data /dev/sdc[ceph_deploy.conf][DEBUG ] found configuration file at: /root/.cephdeploy.conf[ceph_deploy.cli][INFO ] Invoked (2.0.1): /bin/ceph-deploy osd create ceph-01 --data /dev/sdc[ceph_deploy.cli][INFO ] ceph-deploy options:[ceph_deploy.cli][INFO ] verbose : False[ceph_deploy.cli][INFO ] bluestore : None[ceph_deploy.cli][INFO ] cd_conf : <ceph_deploy.conf.cephdeploy.Conf instance at 0x20e33b0>[ceph_deploy.cli][INFO ] cluster : ceph[ceph_deploy.cli][INFO ] fs_type : xfs[ceph_deploy.cli][INFO ] block_wal : None[ceph_deploy.cli][INFO ] default_release : False[ceph_deploy.cli][INFO ] username : None[ceph_deploy.cli][INFO ] journal : None[ceph_deploy.cli][INFO ] subcommand : create[ceph_deploy.cli][INFO ] host : ceph-01[ceph_deploy.cli][INFO ] filestore : None[ceph_deploy.cli][INFO ] func : <function osd at 0x20cf758>[ceph_deploy.cli][INFO ] ceph_conf : None[ceph_deploy.cli][INFO ] zap_disk : False[ceph_deploy.cli][INFO ] data : /dev/sdc[ceph_deploy.cli][INFO ] block_db : None[ceph_deploy.cli][INFO ] dmcrypt : False[ceph_deploy.cli][INFO ] overwrite_conf : False[ceph_deploy.cli][INFO ] dmcrypt_key_dir : /etc/ceph/dmcrypt-keys[ceph_deploy.cli][INFO ] quiet : False[ceph_deploy.cli][INFO ] debug : False[ceph_deploy.osd][DEBUG ] Creating OSD on cluster ceph with data device /dev/sdc[ceph-01][DEBUG ] connected to host: ceph-01[ceph-01][DEBUG ] detect platform information from remote host[ceph-01][DEBUG ] detect machine type[ceph-01][DEBUG ] find the location of an executable[ceph_deploy.osd][INFO ] Distro info: CentOS Linux 7.4.1708 Core[ceph_deploy.osd][DEBUG ] Deploying osd to ceph-01[ceph-01][DEBUG ] write cluster configuration to /etc/ceph/{cluster}.conf[ceph-01][DEBUG ] find the location of an executable[ceph-01][INFO ] Running command: /usr/sbin/ceph-volume --cluster ceph lvm create --bluestore --data /dev/sdc[ceph-01][WARNIN] Running command: /bin/ceph-authtool --gen-print-key[ceph-01][WARNIN] Running command: /bin/ceph --cluster ceph --name client.bootstrap-osd --keyring /var/lib/ceph/bootstrap-osd/ceph.keyring -i - osd new 40cc4038-1d7b-4ec8-a78b-6dc939b9dd01[ceph-01][WARNIN] Running command: /sbin/vgcreate --force --yes ceph-6adf3ba2-9b6f-4f62-b9c9-0e6414bd1c96 /dev/sdc[ceph-01][WARNIN] stdout: Physical volume "/dev/sdc" successfully created.[ceph-01][WARNIN] stdout: Volume group "ceph-6adf3ba2-9b6f-4f62-b9c9-0e6414bd1c96" successfully created[ceph-01][WARNIN] Running command: /sbin/lvcreate --yes -l 7679 -n osd-block-40cc4038-1d7b-4ec8-a78b-6dc939b9dd01 ceph-6adf3ba2-9b6f-4f62-b9c9-0e6414bd1c96[ceph-01][WARNIN] stdout: Logical volume "osd-block-40cc4038-1d7b-4ec8-a78b-6dc939b9dd01" created.[ceph-01][WARNIN] Running command: /bin/ceph-authtool --gen-print-key[ceph-01][WARNIN] Running command: /bin/mount -t tmpfs tmpfs /var/lib/ceph/osd/ceph-3[ceph-01][WARNIN] Running command: /bin/chown -h ceph:ceph /dev/ceph-6adf3ba2-9b6f-4f62-b9c9-0e6414bd1c96/osd-block-40cc4038-1d7b-4ec8-a78b-6dc939b9dd01[ceph-01][WARNIN] Running command: /bin/chown -R ceph:ceph /dev/dm-1[ceph-01][WARNIN] Running command: /bin/ln -s /dev/ceph-6adf3ba2-9b6f-4f62-b9c9-0e6414bd1c96/osd-block-40cc4038-1d7b-4ec8-a78b-6dc939b9dd01 /var/lib/ceph/osd/ceph-3/block[ceph-01][WARNIN] Running command: /bin/ceph --cluster ceph --name client.bootstrap-osd --keyring /var/lib/ceph/bootstrap-osd/ceph.keyring mon getmap -o /var/lib/ceph/osd/ceph-3/activate.monmap[ceph-01][WARNIN] stderr: 2022-02-15 15:32:34.732 7f433f903700 -1 auth: unable to find a keyring on /etc/ceph/ceph.client.bootstrap-osd.keyring,/etc/ceph/ceph.keyring,/etc/ceph/keyring,/etc/ceph/keyring.bin,: (2) No such file or directory[ceph-01][WARNIN] 2022-02-15 15:32:34.732 7f433f903700 -1 AuthRegistry(0x7f4338066aa8) no keyring found at /etc/ceph/ceph.client.bootstrap-osd.keyring,/etc/ceph/ceph.keyring,/etc/ceph/keyring,/etc/ceph/keyring.bin,, disabling cephx[ceph-01][WARNIN] stderr: got monmap epoch 3[ceph-01][WARNIN] Running command: /bin/ceph-authtool /var/lib/ceph/osd/ceph-3/keyring --create-keyring --name osd.3 --add-key AQARVwtiym1ZMRAAVHbevWt3Mr3VfpnOkCQnEg==[ceph-01][WARNIN] stdout: creating /var/lib/ceph/osd/ceph-3/keyring[ceph-01][WARNIN] added entity osd.3 auth(key=AQARVwtiym1ZMRAAVHbevWt3Mr3VfpnOkCQnEg==)[ceph-01][WARNIN] Running command: /bin/chown -R ceph:ceph /var/lib/ceph/osd/ceph-3/keyring[ceph-01][WARNIN] Running command: /bin/chown -R ceph:ceph /var/lib/ceph/osd/ceph-3/[ceph-01][WARNIN] Running command: /bin/ceph-osd --cluster ceph --osd-objectstore bluestore --mkfs -i 3 --monmap /var/lib/ceph/osd/ceph-3/activate.monmap --keyfile - --osd-data /var/lib/ceph/osd/ceph-3/ --osd-uuid 40cc4038-1d7b-4ec8-a78b-6dc939b9dd01 --setuser ceph --setgroup ceph[ceph-01][WARNIN] stderr: 2022-02-15 15:32:35.229 7fa862665a80 -1 bluestore(/var/lib/ceph/osd/ceph-3/) _read_fsid unparsable uuid[ceph-01][WARNIN] --> ceph-volume lvm prepare successful for: /dev/sdc[ceph-01][WARNIN] Running command: /bin/chown -R ceph:ceph /var/lib/ceph/osd/ceph-3[ceph-01][WARNIN] Running command: /bin/ceph-bluestore-tool --cluster=ceph prime-osd-dir --dev /dev/ceph-6adf3ba2-9b6f-4f62-b9c9-0e6414bd1c96/osd-block-40cc4038-1d7b-4ec8-a78b-6dc939b9dd01 --path /var/lib/ceph/osd/ceph-3 --no-mon-config[ceph-01][WARNIN] Running command: /bin/ln -snf /dev/ceph-6adf3ba2-9b6f-4f62-b9c9-0e6414bd1c96/osd-block-40cc4038-1d7b-4ec8-a78b-6dc939b9dd01 /var/lib/ceph/osd/ceph-3/block[ceph-01][WARNIN] Running command: /bin/chown -h ceph:ceph /var/lib/ceph/osd/ceph-3/block[ceph-01][WARNIN] Running command: /bin/chown -R ceph:ceph /dev/dm-1[ceph-01][WARNIN] Running command: /bin/chown -R ceph:ceph /var/lib/ceph/osd/ceph-3[ceph-01][WARNIN] Running command: /bin/systemctl enable ceph-volume@lvm-3-40cc4038-1d7b-4ec8-a78b-6dc939b9dd01[ceph-01][WARNIN] stderr: Created symlink from /etc/systemd/system/multi-user.target.wants/ceph-volume@lvm-3-40cc4038-1d7b-4ec8-a78b-6dc939b9dd01.service to /usr/lib/systemd/system/ceph-volume@.service.[ceph-01][WARNIN] Running command: /bin/systemctl enable --runtime ceph-osd@3[ceph-01][WARNIN] stderr: Created symlink from /run/systemd/system/ceph-osd.target.wants/ceph-osd@3.service to /usr/lib/systemd/system/ceph-osd@.service.[ceph-01][WARNIN] Running command: /bin/systemctl start ceph-osd@3[ceph-01][WARNIN] --> ceph-volume lvm activate successful for osd ID: 3[ceph-01][WARNIN] --> ceph-volume lvm create successful for: /dev/sdc[ceph-01][INFO ] checking OSD status...[ceph-01][DEBUG ] find the location of an executable[ceph-01][INFO ] Running command: /bin/ceph --cluster=ceph osd stat --format=json[ceph_deploy.osd][DEBUG ] Host ceph-01 is now ready for osd use.
# 扩容完成我们可以看到ceph的状态,此时我们的osd已经发生变化
[root@ceph-01 ceph-deploy]# ceph -s
cluster:id: c8ae7537-8693-40df-8943-733f82049642health: HEALTH_OKservices:mon: 3 daemons, quorum ceph-01,ceph-02,ceph-03 (age 19m)mgr: ceph-03(active, since 7d), standbys: ceph-02, ceph-01mds: cephfs-abcdocker:1 {0=ceph-02=up:active} 2 up:standbyosd: 4 osds: 4 up (since 2m), 4 in (since 2m) #osd已经变更为4个,状态为uprgw: 1 daemon active (ceph-01)task status:data:pools: 9 pools, 384 pgsobjects: 320 objects, 141 MiBusage: 4.5 GiB used, 176 GiB / 180 GiB avail #空间大小已经由原来的150扩容为180pgs: 384 active+clean
# 通过ceph osd tree可以看到我们三台节点,一共有4个osd,其中ceph-01节点有2台osd节点
[root@ceph-01 ceph-deploy]# ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF-1 0.17569 root default-3 0.07809 host ceph-010 hdd 0.04880 osd.0 up 1.00000 1.000003 hdd 0.02930 osd.3 up 1.00000 1.00000-5 0.04880 host ceph-021 hdd 0.04880 osd.1 up 1.00000 1.00000-7 0.04880 host ceph-032 hdd 0.04880 osd.2 up 1.00000 1.00000
三、数据重分步 rebalancing
数据重分布原理
当Ceph OSD添加到Ceph存储集群时,集群映射会使用新的 OSD 进行更新。回到计算 PG ID中,这会更改集群映射。因此,它改变了对象的放置,因为它改变了计算的输入。下图描述了重新平衡过程(尽管相当粗略,因为它对大型集群的影响要小得多),其中一些但不是所有 PG 从现有 OSD(OSD 1 和 OSD 2)迁移到新 OSD(OSD 3) )。即使在再平衡时,许多归置组保持原来的配置,每个OSD都获得了一些额外的容量,因此在重新平衡完成后新 OSD 上没有负载峰值。
PG中存储的是subject,因为subject计算比较复杂,所以ceph会直接迁移pg保证集群平衡

#DD一个10G的文件
[root@ceph-01 abcdocker]# dd if=/dev/zero of=abcdocker.img bs=1M count=10240
我们将文件复制到CEPHFS文件存储中,通过ceph健康检查,就可以看到下面的PG同步的状态
ceph osd重分布不会马上进行数据同步,而是大概有10分钟的等待时间。在异常时可以看到有多少个object受到影响,并不会马上同步
[root@ceph-02 ~]# ceph -s
cluster:id: c8ae7537-8693-40df-8943-733f82049642health: HEALTH_WARNDegraded data redundancy: 8/8640 objects degraded (0.093%), 2 pgs degradedservices:mon: 3 daemons, quorum ceph-01,ceph-02,ceph-03 (age 71s)mgr: ceph-03(active, since 8d), standbys: ceph-02, ceph-01mds: cephfs-abcdocker:1 {0=ceph-03=up:active} 2 up:standbyosd: 5 osds: 5 up (since 15s), 5 in (since 3h)rgw: 1 daemon active (ceph-01)task status:data:pools: 9 pools, 384 pgsobjects: 2.88k objects, 10 GiBusage: 36 GiB used, 194 GiB / 230 GiB availpgs: 8/8640 objects degraded (0.093%)382 active+clean1 active+recovery_wait+degraded1 active+recovering+degradedio:recovery: 0 B/s, 1 objects/sclient: 32 KiB/s rd, 0 B/s wr, 31 op/s rd, 21 op/s wr
当PG数据同步完成后,ceph集群health状态就变更为OK
温馨提示,当ceph osd执行重分配时,会影响ceph集群正常写入的操作。所以当更新升级osd节点时建议一台一台进行更新,或者临时关闭rebalance
ceph osd 重分布以及写入数据是可以指定2块网卡,生产环境建议ceph配置双网段。cluster_network为osd数据扩容同步重分配网卡,public_network为ceph客户端连接的网络。设置双网段可以减少重分布造成的影响
如果我们已经在数据重分配了,已经影响到线上ceph正常读写了,可以通过下面的方式临时暂停rebalance
[root@ceph-01 ceph-deploy]# ceph osd set norebalance
norebalance is set[root@ceph-01 ceph-deploy]# ceph osd set nobackfillnobackfill is set#当我们设置了norebalance nobackfill ,ceph会将重分布给暂停掉。ceph业务就可以访问正常[root@ceph-01 ceph-deploy]# ceph -scluster:id: c8ae7537-8693-40df-8943-733f82049642health: HEALTH_WARNnobackfill,norebalance flag(s) setservices:mon: 3 daemons, quorum ceph-01,ceph-02,ceph-03 (age 38m)mgr: ceph-03(active, since 8d), standbys: ceph-02, ceph-01mds: cephfs-abcdocker:1 {0=ceph-03=up:active} 2 up:standbyosd: 5 osds: 5 up (since 37m), 5 in (since 3h)flags nobackfill,norebalancergw: 1 daemon active (ceph-01)task status:data:pools: 9 pools, 384 pgsobjects: 2.88k objects, 10 GiBusage: 36 GiB used, 194 GiB / 230 GiB availpgs: 384 active+clean
# 解除rebalance命令如下
[root@ceph-01 ceph-deploy]# ceph osd unset nobackfill
nobackfill is unset[root@ceph-01 ceph-deploy]# ceph osd unset norebalancenorebalance is unset[root@ceph-01 ceph-deploy]# ceph -scluster:id: c8ae7537-8693-40df-8943-733f82049642health: HEALTH_OKservices:mon: 3 daemons, quorum ceph-01,ceph-02,ceph-03 (age 40m)mgr: ceph-03(active, since 8d), standbys: ceph-02, ceph-01mds: cephfs-abcdocker:1 {0=ceph-03=up:active} 2 up:standbyosd: 5 osds: 5 up (since 39m), 5 in (since 3h)rgw: 1 daemon active (ceph-01)task status:data:pools: 9 pools, 384 pgsobjects: 2.88k objects, 10 GiBusage: 36 GiB used, 194 GiB / 230 GiB availpgs: 384 active+clean
四、OSD 缩容
当某个时间段我们OSD服务器受到外部因素影响,硬盘更换,或者是节点DOWN机需要手动剔除OSD节点。
目前ceph osd状态
[root@ceph-01 ~]# ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF-1 0.22449 root default-3 0.07809 host ceph-010 hdd 0.04880 osd.0 up 1.00000 1.000003 hdd 0.02930 osd.3 up 1.00000 1.00000-5 0.04880 host ceph-021 hdd 0.04880 osd.1 up 1.00000 1.00000-7 0.04880 host ceph-032 hdd 0.04880 osd.2 up 1.00000 1.00000-9 0.04880 host ceph-044 hdd 0.04880 osd.4 up 1.00000 1.00000
目前我们ceph节点一共有4台,其中ceph-01有2个osd节点。 假设我们ceph-04节点出现故障,软件或者硬件故障,需要将ceph-04从ceph集群中剔除
ceph osd perf 可以看到ceph中osd的延迟,如果生产中遇到哪块盘延迟较大,可以进行手动剔除
故障发生后,如果一定时间后重新上线故障 OSD,那么 PG 会进行以下流程:
- 故障OSD上线,通知Monitor并注册,该OSD在上线前会读取存在持久化的设备的PGLog
2.Monitor 得知该OSD的旧id,因此会继续使用以前的PG分配,之前该OSD下线造成的Degraded PG会被通知该OSD已经中心加入
3.这时候分为两种情况,以下两种情况PG会标记自己为Peering状态并暂时停止处理请求
-
第一种情况
故障OSD是拥有Primary PG,它作为这部分数据权责主题,需要发送查询PG元数据请求给所有属于该PG的Replicate角色节点。该PG的Replicate角色节点实际上在故障OSD下线时期成为了Primary角色并维护了权威的PGLog,该PG在得到OSD的Primary PG的查询请求后会发送回应。Primary PG通过对比Replicate PG发送的元数据和PG版本信息后发现处于落后状态,因此会合并到PGLog并建立权威PGLog,同时会建立missing列表来标记过时数据
-
第二种情况
故障OSD是拥有Replicate PG,这时上线后故障OSD的Replicate PG会得到Primary PG的查询请求,发送自己这份过时的元数据和PGLog。Primary PG对比数据后发现该PG落后时,通过PGLog建立missing列表。
- PG开始接受IO请求,但是PG所属的故障节点仍存在过时数据,故障节点的Primary PG会发起Pull请求从Replicate节点获得最新数据,Replicate PG会得到其它OSD节点的Primary PG的Push请求来恢复数据
5.恢复完成后标记自己Clean
第三步是PG唯一不处理请求的阶段,它通常会在1s内完成来减少不可用时间。但是这里仍然有其他问题,比如恢复期间故障OSD会维护missing列表,如果IO正好是处于missing列表的数据,那么PG会进行恢复数据的插队操作,主动将该IO涉及的数据从Replicate PG拉过来,提前恢复该部分数据。这个情况延迟大概几十毫秒
首先我们模拟ceph04节点异常,异常的情况有很多,我直接down掉ceph-04节点
第一步: shutdown ceph-04
第二步: 检查ceph状态
[root@ceph-01 ~]# ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF-1 0.22449 root default-3 0.07809 host ceph-010 hdd 0.04880 osd.0 up 1.00000 1.000003 hdd 0.02930 osd.3 up 1.00000 1.00000-5 0.04880 host ceph-021 hdd 0.04880 osd.1 up 1.00000 1.00000-7 0.04880 host ceph-032 hdd 0.04880 osd.2 up 1.00000 1.00000-9 0.04880 host ceph-044 hdd 0.04880 osd.4 down 1.00000 1.00000# ceph -04中的osd状态已经是down的状态[root@ceph-01 ~]# ceph -scluster:id: c8ae7537-8693-40df-8943-733f82049642health: HEALTH_WARN1 osds down1 host (1 osds) downDegraded data redundancy: 2154/8640 objects degraded (24.931%), 133 pgs degradedservices:mon: 3 daemons, quorum ceph-01,ceph-02,ceph-03 (age 16h)mgr: ceph-03(active, since 8d), standbys: ceph-02, ceph-01mds: cephfs-abcdocker:1 {0=ceph-03=up:active} 2 up:standbyosd: 5 osds: 4 up (since 23s), 5 in (since 20h)rgw: 1 daemon active (ceph-01)task status:data:pools: 9 pools, 384 pgsobjects: 2.88k objects, 10 GiBusage: 36 GiB used, 194 GiB / 230 GiB availpgs: 2154/8640 objects degraded (24.931%)166 active+undersized133 active+undersized+degraded85 active+clean#可以看到,大概有2154个object受到影响
通过ceph -s可以看到异常的osd在ceph-04上,osd的节点为osd.4。下面执行osd out,可以将权重变小
[root@ceph-01 ~]# ceph osd out osd.4#因为本身没权重,ceph就不会让此节点提供服务
第三步: 删除CRUSHMAP信息,默认情况下ceph osd out不会删除crush中的信息
[root@ceph-01 ~]# ceph osd crush dump|head{"devices": [{"id": 0,"name": "osd.0","class": "hdd"},{"id": 1,"name": "osd.1",
从集群里面删除这个节点的记录
[root@ceph-01 ~]# ceph osd crush rm osd.4removed item id 4 name 'osd.4' from crush map
当前ceph osd里面没有任何数据了,但是ceph集群中还有保留
第四步: 从集群中删除异常节点
#虽然没有提供数据,但是还有存在这个节点[root@ceph-01 ~]# ceph osd rm osd.4removed osd.4[root@ceph-01 ~]# ceph osd treeID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF-1 0.17569 root default-3 0.07809 host ceph-010 hdd 0.04880 osd.0 up 1.00000 1.000003 hdd 0.02930 osd.3 up 1.00000 1.00000-5 0.04880 host ceph-021 hdd 0.04880 osd.1 up 1.00000 1.00000-7 0.04880 host ceph-032 hdd 0.04880 osd.2 up 1.00000 1.00000-9 0 host ceph-04
在通过ceph -s查看时,osd的节点已经更改为4个
[root@ceph-01 ~]# ceph -s|grep osdosd: 4 osds: 4 up (since 10m), 4 in (since 9m); 27 remapped pgs
第五步: 删除auth中的osd key
#此时我们通过ceph -s参数还可以看到有集群状态,是因为auth中osd的key没有删除#通过下面的命令删除auth中的key#查看auth list[root@ceph-01 ~]# ceph auth list|grep osdinstalled auth entries:caps: [osd] allow rwxcaps: [osd] allow rwxcaps: [osd] allow rwxosd.0caps: [mgr] allow profile osdcaps: [mon] allow profile osdcaps: [osd] allow *osd.1caps: [mgr] allow profile osdcaps: [mon] allow profile osdcaps: [osd] allow *osd.2caps: [mgr] allow profile osdcaps: [mon] allow profile osdcaps: [osd] allow *osd.3caps: [mgr] allow profile osdcaps: [mon] allow profile osdcaps: [osd] allow *osd.4caps: [mgr] allow profile osdcaps: [mon] allow profile osdcaps: [osd] allow *caps: [osd] allow *client.bootstrap-osdcaps: [mon] allow profile bootstrap-osdcaps: [osd] allow rwxcaps: [osd] allow *caps: [osd] allow *caps: [osd] allow *#删除osd.4[root@ceph-01 ~]# ceph auth rm osd.4#注意不要删除osd
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)