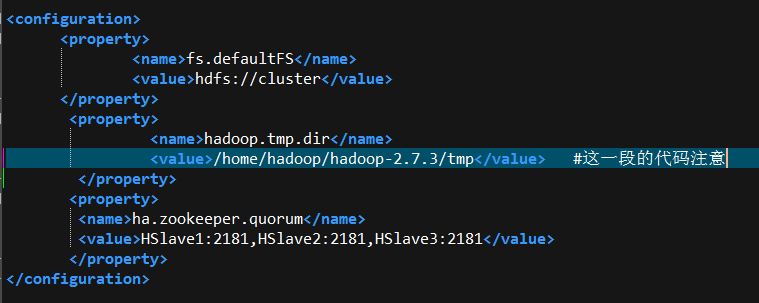
在执行name node格式化(hdfs namenode -format)的时候,出现了以下无法启动NameNode的错误,研究了很久,请教了本班的大神后,终于知道原因是core-site的文件配置中 tmp 的目录路径写错了
17/07/19 01:32:48 ERROR namenode.NameNode: Failed to start namenode.
java.lang.IllegalArgumentException: URI has an authority component
at java.io.File.<init>(File.java:423)
at org.apache.hadoop.hdfs.server.namenode.NNStorage.getStorageDirectory(NNStorage.java:329)
at org.apache.hadoop.hdfs.server.namenode.FSEditLog.initJournals(FSEditLog.java:276)
at org.apache.hadoop.hdfs.server.namenode.FSEditLog.initJournalsForWrite(FSEditLog.java:247)
at org.apache.hadoop.hdfs.server.namenode.NameNode.format(NameNode.java:986)
at org.apache.hadoop.hdfs.server.namenode.NameNode.createNameNode(NameNode.java:1434)
at org.apache.hadoop.hdfs.server.namenode.NameNode.main(NameNode.java:1559)
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)