小数的十进制、二进制转换
十进制 --> 二进制
整数部分除2取余,小数部分乘2取整。
考虑 8.25
整数部分8进行除2取余,
除2商4余0
除2商2余0
除2商1余0
除2商0余1
所以结果是1000【最后一个余数在最前】
小数部分0.25进行乘2取整,
0.25乘2得0.5 整数为0
0.5 乘2得1 整数为1
所以结果是01
十进制表示的8.25其二进制表示即为1000.01
二进制 --> 十进制
这个就简单多了,二进制的各个位乘以其权重即可。
整数部分 1*2^3 + 0*2^2 + 0*2^1 + 0*2^0 = 8
小数部分 0*2^(-1) + 1*2^(-2) = 0.25
小数不能被精确表示的原因
十进制中能够精确表示的小数,都是10的质因子2或5为分母的,比如
1/2=0.5 1/4=0.25 1/8=0.125
1/5=0.2
1/10=0.1
十进制中不能精确表示的小数,有1/3,1/6,1/7,1/9
在二进制中,只有2是质因子,对于1/2,1/4,1/8可以精确表示;
但对于1/10=0.1和1/5=0.2都不能精确表示。【1/3,1/6,1/7,1/9也不能】
比如对于十进制表示的0.1取它的二进制表示,则是
小数部分0.1进行乘2取整,
0.1乘2得0.2 整数为0
0.2乘2得0.4 整数为0
0.4乘2得0.8 整数为0
0.8乘2得1.6 整数为1
0.6乘2得1.2 整数为1
0.2乘2得0.4 整数为0
0.4乘2得0.8 整数为0
0.8乘2得1.6 整数为1
发现已经开始循环了!根本无法取到精确值。
出处:https://0.30000000000000004.com/
计算机中小数的存储
需要先将小数的表示方法进行规格化,即整数部分为1,其余全部是小数部分的科学计数法。
比如
1000.01需要先表示为 1.00001*2^3
之后祭出IEEE 754标准
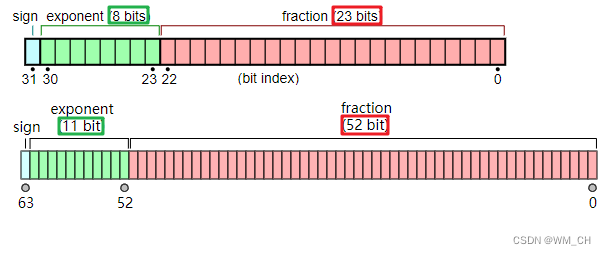
符号位:0 表示正,1 表示负
指数位:指数是负数时,小数点需要左移;指数是正数时,小数点需要右移。
1.00001 * 2^3,里面的幂数+3代表小数点需要右移3位。
指数位的长度越长,数值的表达范围越大;
尾数位:小数部分,
1.00001 * 2^3,尾数部分就是 00001,
尾数的长度决定了这个数的精度,因此如果要表示精度更高的小数,则就要提高尾数位的长度;
double 的尾数部分是 52 位,float 的尾数部分是 23 位,但他们同时都隐含一个整数部分的1,
所以 double 共有 53 个二进制有效位,float 共有 24 个二进制有效位,
所以它们的精度在十进制中分别是 log10(2^53)约等于 15.95 和 log10(2^24)约等于 7.22 位,
因此 double 的有效数字是 15~16 位,float 的有效数字是 7~8 位,有效位包含整数部分和小数部分;
指数位里面的偏移量
在float类型当中
小数点移动范围是 -126~127
偏移量是127(0111 1111)
这样可以保证8位的指数位都是正数。
1000.01 规范化为 1.00001 * 2^3
这里的指数位是 +3+127
0.00101 规范化为 1.01 * 2^(-3)
这里的指数位是 -3+127
在double类型当中
小数点移动范围是 -1022~1023
偏移量是1023(0011 1111 1111)
这样可以保证11位的指数位都是正数。
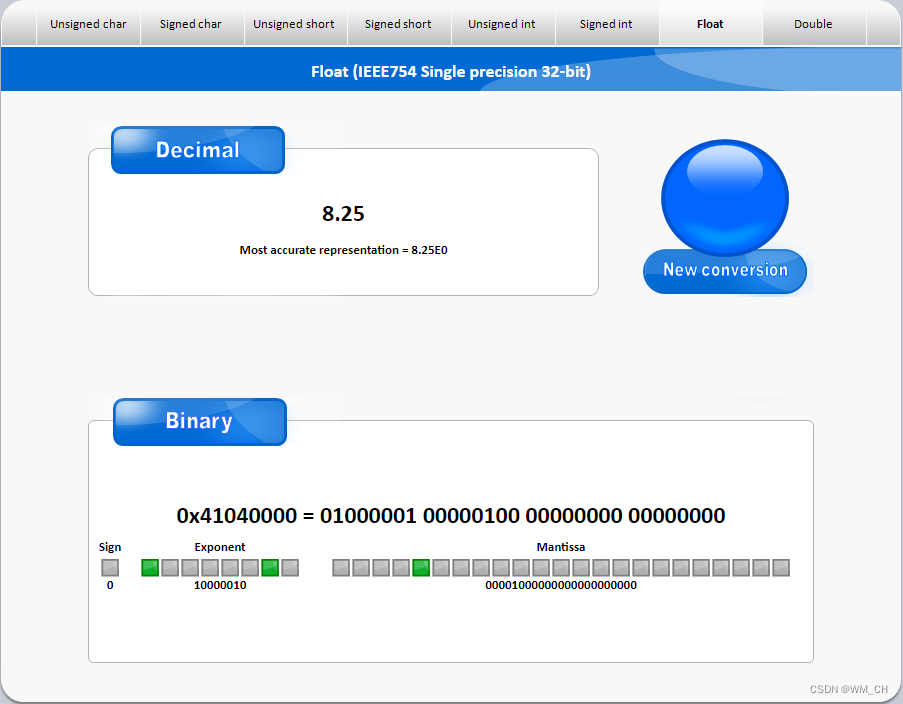
我们来填个空
1.00001 * 2^3
float类型在计算机中表示为
符号01位 0
指数08位 3+127 = 130 = 1000 0010
尾数23位 0000 1000 0000 0000 000
连起来
0 100 0001 0 000 0100 0000 0000 0000 0000
小端存储,低位在低地址,即为 0x41040000
这里有个网站,可以在线查看。
http://www.binaryconvert.com/result_float.html?decimal=056046050053
浮点数在计算机中的精度
double 的有效数字是 15~16 位,float 的有效数字是 7~8 位,有效位包含整数部分和小数部分;
如果整数部分越长,就会直接导致小数部分减少。精度变低!
如果小数部分最前边又添了几个0,就会直接导致尾数变长,变得更精确。
说明浮点表示仅仅是一种近似的表示方法,不能精确的表示数值,所以有时候大家在编程的过程中明明向float类型变量赋值了一个准确的数据,仿真一看数据成了一个近似值。
因此浮点数作比较不能使用==直接进行比较!
而是使用下面的宏
#define FLOAT_EPS (0.000001)
#define Float_Equ(a, b) ((fabs((a)-(b)))<(FLOAT_EPS))
再来一个例子证明精度问题,
#include <stdio.h>
#include <stdlib.h>
#define FACTOR (1UL<<28)
int main(int argc, char *argv[]) {
float a = 1.7 * FACTOR;
float b = 0.2 * FACTOR;
float c = a + b;
float d = 1.9 * FACTOR;
printf("%f\n", c);
printf("%f\n", d);
printf("%f\n",c - d);
return 0;
}
打印结果为
510027392.000000
510027360.000000
32.000000
浮点数编程案例
#include <stdio.h>
#include <stdlib.h>
typedef union _tag_FloatConvert
{
unsigned char byte[4];
float Result;
}uFloatConvert;
int main(int argc, char *argv[]) {
uFloatConvert unFloatConvert;
float fVal = 4.25;
int iVal = 0x40880000;
float *pfVal = NULL;
int *pIVal = NULL;
fVal = (float)iVal;
printf("fVal = %.3f\n",fVal);
printf("iVal = %d\n",iVal);
pfVal = (float*)(&iVal);
printf("*pfVal = %.3f\n",*pfVal);
unFloatConvert.byte[0] = 0x00;
unFloatConvert.byte[1] = 0x00;
unFloatConvert.byte[2] = 0x88;
unFloatConvert.byte[3] = 0x40;
printf("unFloatConvert.Result = %.3f\n",unFloatConvert.Result);
printf("公众号:最后一个bug\n");
return 0;
}
运行结果
fVal = 1082654720.000
iVal = 1082654720
*pfVal = 4.250
unFloatConvert.Result = 4.250
公众号:最后一个bug
可见直接强制转换的做法是错误的!
本文内容大量参考下边的文章,如果有侵权问题,请联系我删除。
浮点数运算不满足交换律
(3.14 + 1e10) - 1e10 求值得到 0.0 因为尾数被丢掉了。
3.14 + (1e10 - 1e10) 会得到 3.14。
编译器、CPU不一定使用的是IEEE 754
x86 CPU 是在 x87 FPU的内部以80b计算得到结果后,再 truncate 为 IEEE 754 的 float(32b) 或者 double(64b),这中间会有微小的差异。
另一方面,ARM VFP 指令(IEEE 754 相容) 与 NEON指令(非完全 IEEE 754 相容)也可能会有不同的输出结果。
另外还有 gcc 的 -mfpmath=sse2 参数。
参考:
为什么 0.1 + 0.2 不等于 0.3 ?
【典藏】别怪"浮点数"太坑(C语言版本)
同事用"两个浮点数相等" 被说了一顿
浮点数的美丽与哀愁
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)