鸡蛋该从大的一端剥开还是小的一端剥开?
Fabless半导体公司在面试软件工程师时经常会问:什么是大端序和小端序?
01
—
字节序
字节序,又名端序(endianness),狭义来看,是指多字节变量的字节在内存中的存储顺序。
负责任地说,我们接触到的大部分机器,包括手机,平板,电脑和各种物联网硬件,它们内部的多字节对象的存储方式都是连续的字节序列。
那么问题来了,既然有顺序,那是正序还是倒序呢?这个就是字节序描述的问题。
02
—
大端序,小端序
在32位机器上,假设类型为unsigned int的四字节变量的值是0xA0B0C0D0,变量起始地址是0x00,那么该值的各位在四字节上连续存储的方式有两种:
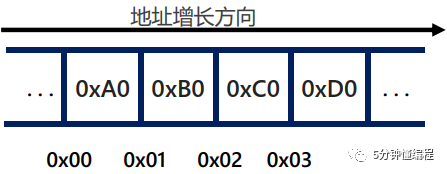
图 1. 大端序
图 1为大端序,字节最高位0xA0存储在内存最低位0x00。
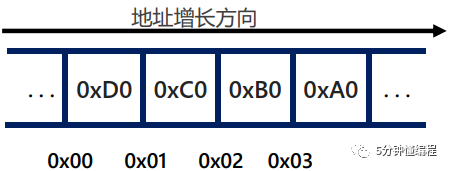
图 2. 小端序
图 2为大端序,字节最低位0xD0存储在内存最低位0x00。
实例代码如下所示:
#include
typedef unsigned int uint32;
typedef unsigned char uint8;
int main(void)
{
uint32 Data = 0xA0B0C0D0;
uint8* byte_ptr_1 = (uint8*)(&Data);
uint8 i = 0;while( i < 4 )
{
printf("Data at addr %p, value: %X\n",
byte_ptr_1 + i, *(byte_ptr_1 + i++));
} return 0;
}
运行结果如下(x86机器),显然x86 CPU采用的是小端序。
Data at addr 0x7fffb9590915, value: D0
Data at addr 0x7fffb9590916, value: C0
Data at addr 0x7fffb9590917, value: B0
Data at addr 0x7fffb9590918, value: A0
03
—
孰优孰劣?
大端序有利于快速判断变量数值的正负或者大小,因为CPU从内存低位读取存储的内容,优先得到变量数值的高位。
小端序有利于强制转换数据类型,因为由长字节类型转换成短字节类型时只需要扔掉多余的高地址存储字节,符合转换逻辑。
当然,我们还可以从很多个角度对二者进行对比分析。总而言之,各有优劣,各有侧重,工业界尚未有统一标准。
04
—
大家是怎么选的?
前面一通分析有纸上谈兵的嫌疑,那么计算机各个领域是如何选择端序的呢?
做个小总结:
x86处理器是小端序,ARM处理器字节序可配置。
TCP/IP协议规定使用大端序作为网络字节序。
串行数据传输协议USB,RS-232/422/485等均采用小端序,而I2C和SPI协议则采用大端序。
有时候,选择大小端作为字节序就像吃鸡蛋的时候选择从大的一端开始剥开还是从小的一端开始剥开一样有意思。
参考&引用
白皮书:http://3bc.bertrand-blanc.com/endianness05.pdf
本文仅作学习交流使用,所有涉及他人发表的图文的引用均在文末以参考文献方式标注,若有纰漏,欢迎指正交流。