题目:Associatively Segmenting Instances and Semantics in Point Clouds
代码:https://github.com/WXinlong/ASIS
文章讨论: Instances Segmentation 和 Semantics Segmentation
实例Instances Segmentation:分辨出每个单独事物,但不知道是否是一类
语义Semantics Segmentation:分辨出不同类事物,但不知道每类事物具体有几个
摘要
3D点云描述真实场景准确直观,在信息丰富的3D场景进行分割各种元素很少。
本文的框架同时分割点云中的实例和语义。作者提出两种方法,使两项任务互相利用,实现双赢。
具体来说,通过学习语义感知的point-level实例嵌入,使实例分割受益于语义分割。同时,将属于同一实例的点的语义特征融合在一起,从而对每个点更准确地进行语义预测。
相关介绍
实例分割和语义分割 相关又冲突。 那么如何联系,如何双赢。
相关:点云可以被解析为点组,其中每个组对应于一类东西或个体实例。
冲突: 实例分割是要是分出同一类物体的不同实例,语义分割是想让同一类物体有同样的标签。
协作点:语义分割识别出不同的类,而不同实例肯定属于不同的类。实例分割将相同的标签赋予一个实例。因为同一个实例必定属于同一个类别。
简单结合
- 简单方法1:给出语义标签,在单独的标签基础上跑实例分割。缺点:实力分割很大程度上取决于语义分割的表现。
- 简单方法2:给出实例标签,将所有实例分类将预测的类标签赋予该实例的每个点。缺点:不准确的实例预测会严重混淆downstream object classifiers。
解决:端到端框架。
首先引入一个简单的基线来同时分割实例和语义。
基线网络有两个并行分支:一个用于每点语义预测; 另一个输出点级的embeddings实例嵌入
🎈属于同一实例的点的嵌入保持接近而不同实例的点的嵌入是分开。
🎈直觉是,在语义分割期间,分配给其中一个类别的点是因为包含该点的实例属于该类别。
结论:本文基线方法已经可以获得比最近最先进的方法SGPN 更好的性能,以及更快的训练和推理。 基于这种灵活的基线,将实例分割和语义分割紧密地联系在一起,称为ASIS(关联分段实例和语义)

不同类的点之间间距更大。如1中桌子椅子,2中窗户和墙,3中椅子柜子。此外,利用同一实例中点的语义特征进行融合,使每点的语义预测更加准确。语义分割期间一个点会被分配成一个类别,因为包含这个点的实例属于该类别。
该方法对不同的主干网络适用,如PointNet和PointNet++。也可以用于全景分割(Panoptic segmentation).
全景分割与实例分割,语义分割的不同:
对比语义分割,全景分割需要区分不同的 object instances;对于 FCN-based 方法具有挑战性.
对比实例分割,全景分割必须是非重叠的(non-overlapping);对于 region-based 方法具有挑战性.
本文贡献
- 提出了一种快速有效的简单基线,用于在3D点云上同时进行实例分割和语义分割。
- 提出了一个新的框架,称为ASIS,将实例分割和语义分割紧密地联系在一起。 具体而言,提出了两种类型的伙伴关系 - 语义意识,例如用于语义分割的分段和实例融合 - 以使这两个任务彼此协作。
- 通过所提出的ASIS,包含语义感知实例分割和实例融合语义分割的模型被端到端地训练,其优于S3DIS数据集上的最先进的3D实例分割方法及三维语义分割任务的重大改进。 此外,在ShapeNet
利用提出的ASIS方法,网络可以学习语义感知的实例嵌套,其中属于不同语义类的点的嵌入通过特征融合进一步自动分离。
实现方法
一个简单基线网络
框架:由共享编码器和两个并行解码器组成。
解码器1:点级语义预测
解码器2:处理实例分段问题
流程:
 大小的点云经过特征编码器变成特征矩阵:首先提取大小为的点云,并通过特征编码器(例如,堆叠的PointNet层)将其编码成特征矩阵。{此共享特征矩阵指的是PointNet体系结构中的局部特征和全局特征的串联,或PointNet ++体系结构的最后一组抽象模块的输出。}
大小的点云经过特征编码器变成特征矩阵:首先提取大小为的点云,并通过特征编码器(例如,堆叠的PointNet层)将其编码成特征矩阵。{此共享特征矩阵指的是PointNet体系结构中的局部特征和全局特征的串联,或PointNet ++体系结构的最后一组抽象模块的输出。}
- semantic 解码器 将 特征矩阵 解码成 ×
 大小的Semantic语义特征矩阵Fsem,输出语义预测结果Psem:两个并行分支获取特征矩阵,并分别继续进行以下预测。{语义分割分支将共享特征矩阵解码为×形语义特征矩阵,然后输出具有×形状的语义预测,其中
大小的Semantic语义特征矩阵Fsem,输出语义预测结果Psem:两个并行分支获取特征矩阵,并分别继续进行以下预测。{语义分割分支将共享特征矩阵解码为×形语义特征矩阵,然后输出具有×形状的语义预测,其中 是语义类别的数量。}
是语义类别的数量。}
- instance解码器 将 特征矩阵 解码成 × 的instance特征矩阵FINS,并输出大小为Np * NE 的instance预测结果 EINS{Fins用来预测逐点的实例嵌套EINS} ,其中NE表示有多少embedding{除最后一个输出层外,实例分段分支具有相同的体系结构。}
- 训练:
语义分段:交叉熵损失
实例分割:采用前人的成果中的2D图像判别损失函数来监督实例嵌入学习,修改它并使其适用于点云
以前:以前使用的损失是特定于类的:不同语义类的实例嵌入是分开学习的,这意味着应该首先给出语义类。 这种逐步范式高度依赖于语义预测的质量,因为不正确的语义预测将不可避免地导致不正确的实例识别。
本文:采用类不可知实例嵌入学习策略,其中嵌入负责区分不同的实例并且对其类别视而不见。
其中Lvar是让instance的embedding区于平均,Ldist让instance间互相区分,α在实验中设为0.001


在测试期间,使用平均移位聚类在实例嵌入上获得最终实例标签。 我们将同一实例中的点的语义标签的模式分配为其最终类别。 点云实例分割和语义分割基本框架如图3所示。
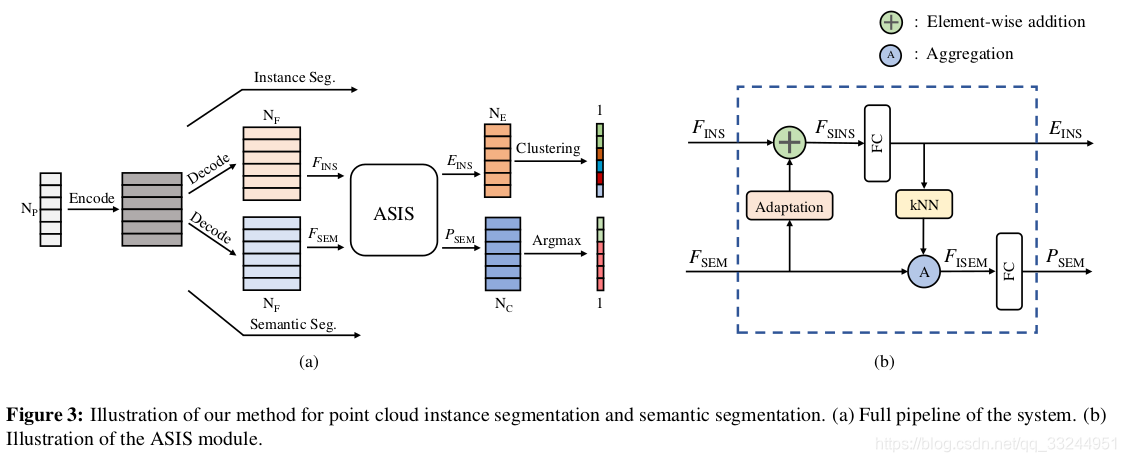
ASIS部分
本文从以上基础框架基础上构建新的ASIS模块,实现语义感知实例分割和实例融合语义分割。
- 语义感知-实例分割
- 这一步让属于不同类instance的三维点更加疏远,但不影响属于同一类instance的三维点。
点云的语义特征构建了一个新的高级特征空间,其中点根据其类别自然定位。 在该空间中,相同语义类的点位于一起,而不同的类被分开。 本文从语义特征中抽象出语义感知(SA)并将其集成到实例特征中,从而产生语义感知实例特征。 首先,语义特征矩阵 适用于通过具有批量归一化和ReLU激活函数的点独立完全连接层(FC)作为F SEM的实例特征空间。 具有与
适用于通过具有批量归一化和ReLU激活函数的点独立完全连接层(FC)作为F SEM的实例特征空间。 具有与 相同的形状。 然后,我们将自适应语义特征矩阵添加到实例特征矩阵
相同的形状。 然后,我们将自适应语义特征矩阵添加到实例特征矩阵 元素,生成语义感知实例特征矩阵
元素,生成语义感知实例特征矩阵 。 该过程可以表述为:
。 该过程可以表述为:

在这种简易且可学习的方式中,属于不同类别实例的点在实例特征空间中被进一步排斥,而相同类别实例很少受到影响。 特征矩阵用于生成最终实例嵌入。
- 实例融合-语义分割
- 这一部分将同一类的Instance融合成Semantic
给定实例嵌入,本文使用K最近邻(kNN)搜索来为实例嵌入空间中的每个点(包括其自身)找到固定数量的相邻点。为了确保属于同一实例的K个采样点,作者根据公式2中使用的边界过滤异常值。如前一节所述,铰接损失项 通过绘制每个点嵌入来监控实例嵌入学习接近δv距离内的平均嵌入。 kNN搜索的输出是形状为
通过绘制每个点嵌入来监控实例嵌入学习接近δv距离内的平均嵌入。 kNN搜索的输出是形状为 的索引矩阵。根据索引矩阵,这些点的语义特征()被分组为
的索引矩阵。根据索引矩阵,这些点的语义特征()被分组为 形特征张量,其是语义特征矩阵,其中每个组对应于与其质心点相邻的实例嵌入空间中的局部区域。受基于通道的最大聚合的有效性的启发,每个组的语义特征通过通道方式的最大聚合操作融合在一起,作为质心点的精确语义特征。实例融合(IF)可以如下公式化。对于
形特征张量,其是语义特征矩阵,其中每个组对应于与其质心点相邻的实例嵌入空间中的局部区域。受基于通道的最大聚合的有效性的启发,每个组的语义特征通过通道方式的最大聚合操作融合在一起,作为质心点的精确语义特征。实例融合(IF)可以如下公式化。对于 形语义特征矩阵
形语义特征矩阵![F_{SEM}=[x_{1},,,x-{NP}]\subseteq R^{NF}](https://private.codecogs.com/gif.latex?F_%7BSEM%7D%3D%5Bx_%7B1%7D%2C%2C%2Cx-%7BNP%7D%5D%5Csubseteq%20R%5E%7BNF%7D) ,实例融合语义特征计算如下:
,实例融合语义特征计算如下:
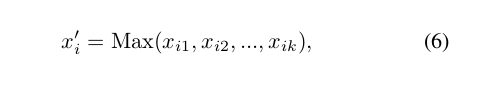
其中![[x_{i1},,,,x_{ik}]](https://private.codecogs.com/gif.latex?%5Bx_%7Bi1%7D%2C%2C%2C%2Cx_%7Bik%7D%5D) 表示实例嵌入空间中K个相邻点居中点i的语义特征,而Max是以K个向量作为输入并输出新向量的逐元素最大值算子。 在实例融合之后,输出是特征矩阵
表示实例嵌入空间中K个相邻点居中点i的语义特征,而Max是以K个向量作为输入并输出新向量的逐元素最大值算子。 在实例融合之后,输出是特征矩阵 ,最终语义特征将被馈送到最后的语义分类器中。
,最终语义特征将被馈送到最后的语义分类器中。
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)