概述
GITHUB路径:
https://github.com/tensorflow/models/tree/master/research/deeplab
论文:
https://arxiv.org/abs/1802.02611
相对于DEEPLAB V3,有如下的修改:
1.网络层使用XCEPTION替换RESNET,性能更好
2.加入ENCODE-DECODE模块。
训练建议的参数:
python deeplab/train.py \
--logtostderr \
--training_number_of_steps=30000 \
--train_split="train" \
--model_variant="xception_65" \
--atrous_rates=6 \
--atrous_rates=12 \
--atrous_rates=18 \
--output_stride=16 \
--decoder_output_stride=4 \
--train_crop_size=513 \
--train_crop_size=513 \
--train_batch_size=1 \
--dataset="pascal_voc_seg" \
--tf_initial_checkpoint=${PATH_TO_INITIAL_CHECKPOINT} \
--train_logdir=${PATH_TO_TRAIN_DIR} \
--dataset_dir=${PATH_TO_DATASET}
网络
网络整体框架:

说实话,封装的过于完美,导致很难看懂。。。
调用链:
train.py:
_build_deeplab->model.multi_scale_logits
model.py:
multi_scale_logits->_get_logits->extract_features->feature_extractor.extract_features
feature_extractor.py:
extract_features->get_network
基础网络
基础网络层在CORE目录里实现。
这里主要看一下XCEPTION-65的实现和XCEPTION的区别。
先上图:
这是XCEPTION模型:

这是DEEPLAB使用的XCEPTION模型:
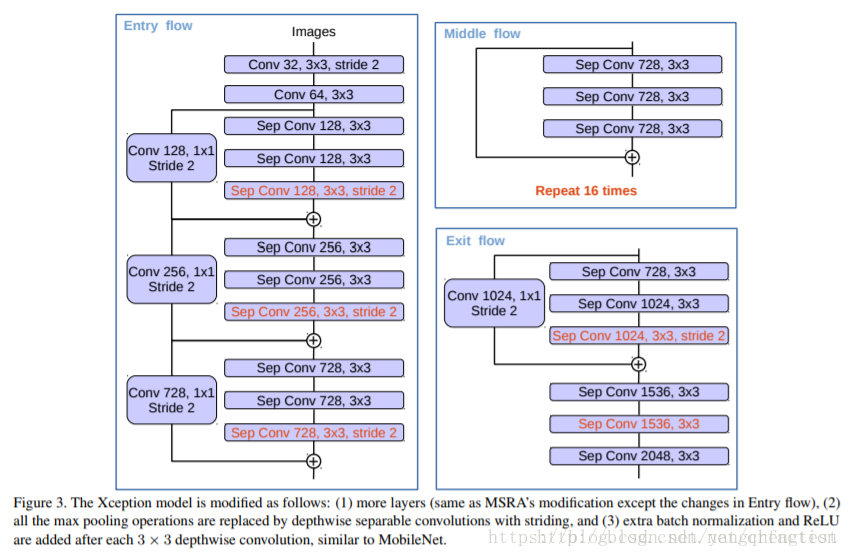
模型基础配置在:
xception.py的函数xception_65中实现。
但是有很多的细节。
除了基础模型上的改动,DEEPLAB在V2之后的核心思想是空洞卷积和ASPP。
空洞卷积以及网络的STRIDE是在:
xception.py的stack_blocks_dense函数中实现
current_stride = 1
rate = 1
for block in blocks:
with tf.variable_scope(block.scope, 'block', [net]) as sc:
for i, unit in enumerate(block.args):
if output_stride is not None and current_stride > output_stride:
raise ValueError('The target output_stride cannot be reached.')
with tf.variable_scope('unit_%d' % (i + 1), values=[net]):
if output_stride is not None and current_stride == output_stride:
net = block.unit_fn(net, rate=rate, **dict(unit, stride=1))
rate *= unit.get('stride', 1)
else:
net = block.unit_fn(net, rate=1, **unit)
current_stride *= unit.get('stride', 1)
net = slim.utils.collect_named_outputs(outputs_collections, sc.name, net)
ASPP
DEEPLAB V3+的ASPP代码在:
model.py的extract_features函数中实现。
从网络整体框架可以看到:
需要对基础的网络的FEATURE做相应的处理整合。
ASPP默认也是使用separable_conv做ASPP。
# Merge branch logits.
concat_logits = tf.concat(branch_logits, 3)
concat_logits = slim.conv2d(
concat_logits, depth, 1, scope=CONCAT_PROJECTION_SCOPE)
concat_logits = slim.dropout(
concat_logits,
keep_prob=0.9,
is_training=is_training,
scope=CONCAT_PROJECTION_SCOPE + '_dropout')
最后做一层1*1卷积加一层DROPOUT,ASPP所有网络的深度都是depth = 256。
DECODER
回到model.py的_get_logits函数
if model_options.decoder_output_stride is not None:
if model_options.crop_size is None:
height = tf.shape(images)[1]
width = tf.shape(images)[2]
else:
height, width = model_options.crop_size
decoder_height = scale_dimension(height,
1.0 / model_options.decoder_output_stride)
decoder_width = scale_dimension(width,
1.0 / model_options.decoder_output_stride)
features = refine_by_decoder(
features,
end_points,
decoder_height=decoder_height,
decoder_width=decoder_width,
decoder_use_separable_conv=model_options.decoder_use_separable_conv,
model_variant=model_options.model_variant,
weight_decay=weight_decay,
reuse=reuse,
is_training=is_training,
fine_tune_batch_norm=fine_tune_batch_norm)
看一下
decoder的节点定义
'xception_65': {
DECODER_END_POINTS: [
'entry_flow/block2/unit_1/xception_module/'
'separable_conv2_pointwise',
],
entry_flow/block2/unit_1/xception_module/separable_conv2_pointwise
对应的结构:
xception_block(‘entry_flow/block2’,
depth_list=[256, 256, 256],
skip_connection_type=’conv’,
activation_fn_in_separable_conv=False,
regularize_depthwise=regularize_depthwise,
num_units=1,
stride=2),
LOW-LEVEL FEATURES使用的是entry_flow的第二层特征。
使用如下的代码,做低层特征的1*1卷积
for i, name in enumerate(feature_list):
decoder_features_list = [decoder_features]
if 'mobilenet' in model_variant:
feature_name = name
else:
feature_name = '{}/{}'.format(
feature_extractor.name_scope[model_variant], name)
decoder_features_list.append(
slim.conv2d(
end_points[feature_name],
48,
1,
scope='feature_projection' + str(i)))
使用下面的代码做基础网络的4*UNSAMPLE
for j, feature in enumerate(decoder_features_list):
decoder_features_list[j] = tf.image.resize_bilinear(
feature, [decoder_height, decoder_width], align_corners=True)
h = (None if isinstance(decoder_height, tf.Tensor)
else decoder_height)
w = (None if isinstance(decoder_width, tf.Tensor)
else decoder_width)
decoder_features_list[j].set_shape([None, h, w, None])
最后与论文中的图稍有不同的是默认decoder_use_separable_conv=TRUE,没有使用3*3的卷积,而是二层的split_separable_conv2d
This operation differs from tf.layers.separable_conv2d as this operation
applies activation function between depthwise and pointwise conv2d.
decoder_depth = 256
if decoder_use_separable_conv:
decoder_features = split_separable_conv2d(
tf.concat(decoder_features_list, 3),
filters=decoder_depth,
rate=1,
weight_decay=weight_decay,
scope='decoder_conv0')
decoder_features = split_separable_conv2d(
decoder_features,
filters=decoder_depth,
rate=1,
weight_decay=weight_decay,
scope='decoder_conv1')
else:
num_convs = 2
decoder_features = slim.repeat(
tf.concat(decoder_features_list, 3),
num_convs,
slim.conv2d,
decoder_depth,
3,
scope='decoder_conv' + str(i))
最后回到
model.py的multi_scale_logits函数
for output in sorted(outputs_to_logits):
outputs_to_logits[output] = tf.image.resize_bilinear(
outputs_to_logits[output], [logits_height, logits_width],
align_corners=True)
返回4*的UNSAMPLE结果。
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)