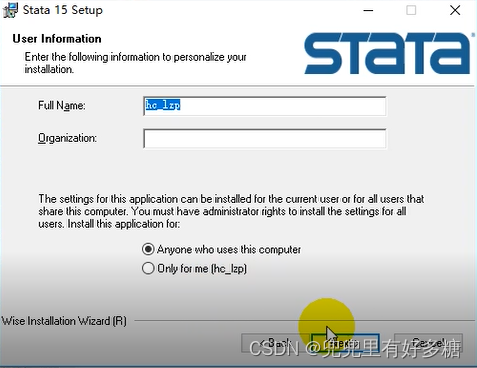
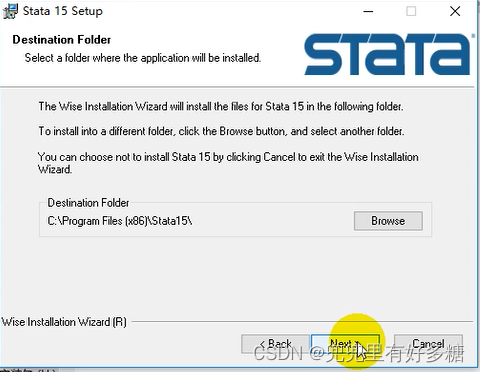
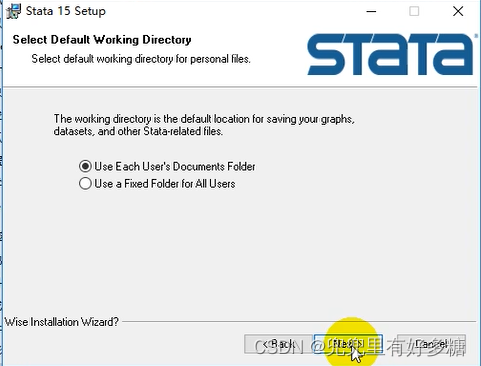
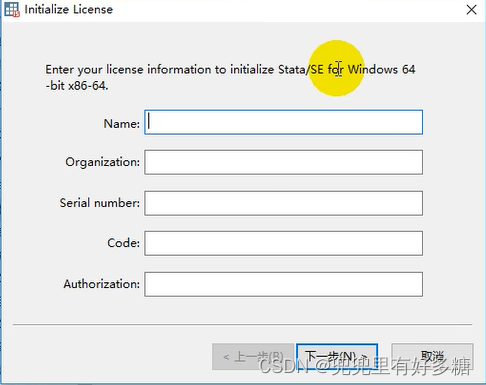
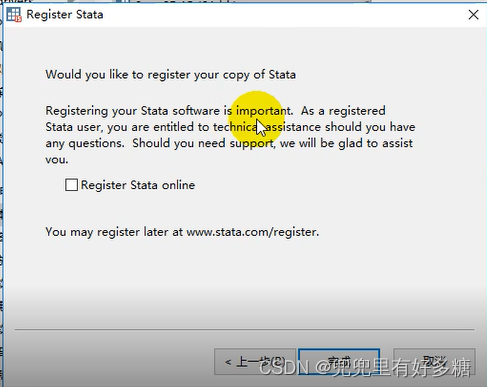
将下载后的资源解压缩之后双击安装软件: 点击”下一步“ 点击”下一步“ 这里选择第二个”SE“这个选项,然后点击”下一步“ 此处尽量不要修改安装路径,尽量使用默认安装路径 然后一直点”下一步“即可 安装完成之后点击”finish“,然后打开已安装的Stata: 打开之后如图让我们填写这些信息。 第一行和第二行都可以随便填,其余的三行按照下面的填写即可:
Serial number: 401506209499 Code: uk4n 5fLi 6wk3 n7q4 kv6h s2ea 719 Authorization: gc83
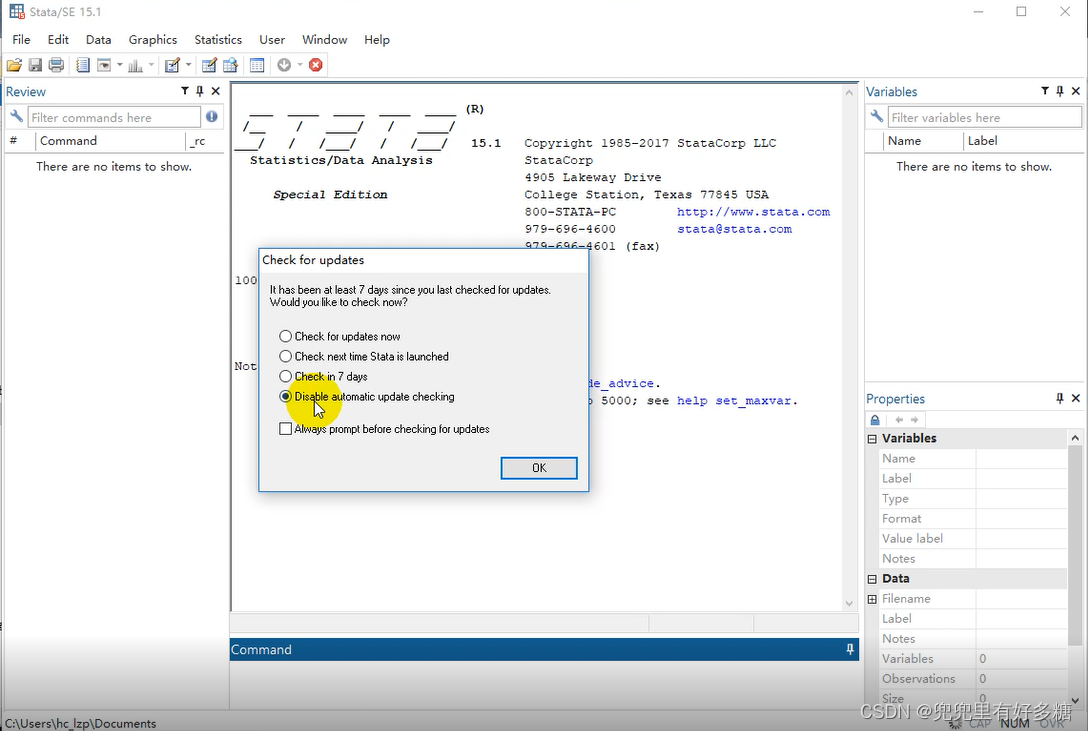
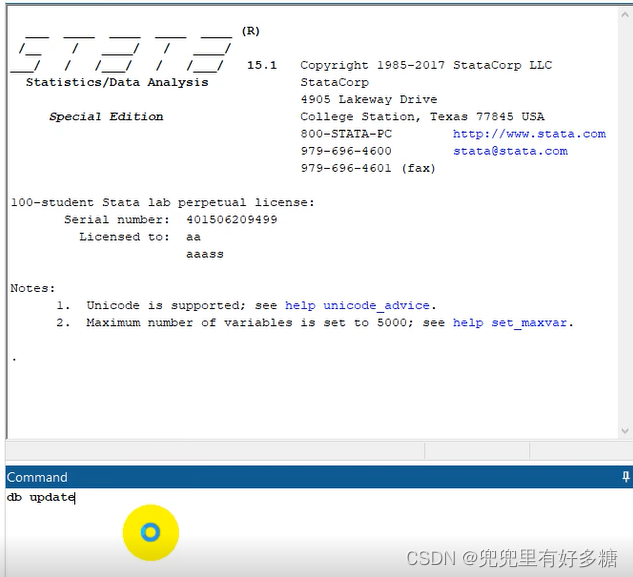
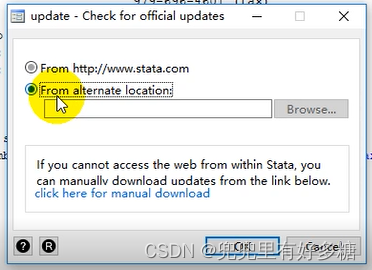
填写好之后点击”下一步“ 这里建议不要勾画这个选项,然后点击”下一步“。 然后我们就进入了软件界面。 之后按照如图勾选: 之后是升级操作,是必须完成的重要操作,不要跳过不做! 看我们的文件中,下面这个文件就是离线的软件更新文件。 我们在Stata下面的命令窗口输入db update 命令。 之后会弹出的窗口中,我们选择”从本地“,然后后点击浏览 选择到如图这个文件: 然后点击确定即可。 等待他更新完成之后就可以正常使用了。
db update
附:
离线更新包下载: 执行命令 db update 选择解压后的更新文件,根目录是stata.upd Windows (64-bit and 32-bit):https://www.stata.com/support/updates/stata15/stata15update_win.zip