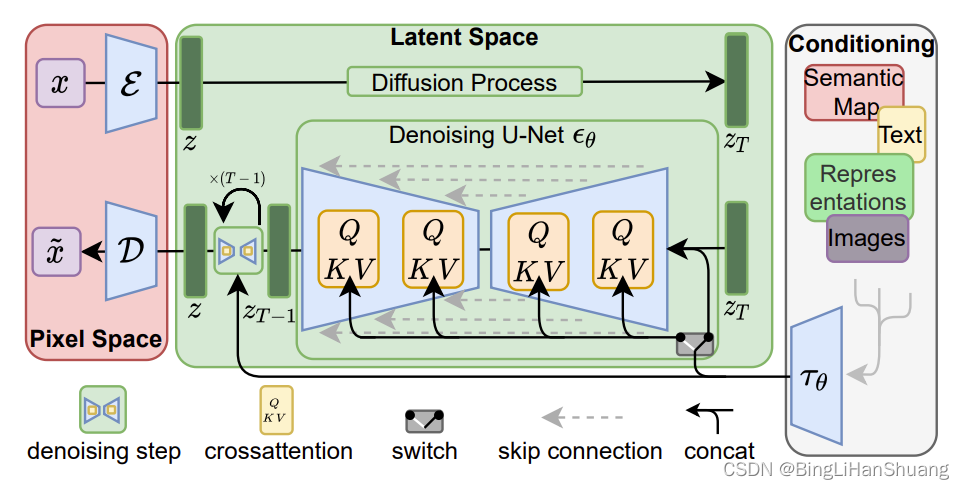
import argparse, os, sys, glob
import cv2
import torch
import numpy as np
from omegaconf import OmegaConf
from PIL import Image
from tqdm import tqdm, trange
from imwatermark import WatermarkEncoder
from itertools import islice
from einops import rearrange
from torchvision.utils import make_grid
import time
from pytorch_lightning import seed_everything
from torch import autocast
from contextlib import contextmanager, nullcontext
from ldm.util import instantiate_from_config
from ldm.models.diffusion.ddim import DDIMSampler
from ldm.models.diffusion.plms import PLMSSampler
from diffusers.pipelines.stable_diffusion.safety_checker import StableDiffusionSafetyChecker
from transformers import AutoFeatureExtractor
parser = argparse.ArgumentParser()
parser.add_argument(
"--prompt",
type=str,
nargs="?",
default="a painting of a virus monster playing guitar",
help="the prompt to render"
)
parser.add_argument(
"--outdir",
type=str,
nargs="?",
help="dir to write results to",
default="outputs/txt2img-samples"
)
parser.add_argument(
"--skip_grid",
action='store_true',
help="do not save a grid, only individual samples. Helpful when evaluating lots of samples",
)
parser.add_argument(
"--skip_save",
action='store_true',
help="do not save individual samples. For speed measurements.",
)
parser.add_argument(
"--ddim_steps",
type=int,
default=50,
help="number of ddim sampling steps",
)
parser.add_argument(
"--plms",
action='store_true',
help="use plms sampling",
)
parser.add_argument(
"--laion400m",
action='store_true',
help="uses the LAION400M model",
)
parser.add_argument(
"--fixed_code",
action='store_true',
help="if enabled, uses the same starting code across samples ",
)
parser.add_argument(
"--ddim_eta",
type=float,
default=0.0,
help="ddim eta (eta=0.0 corresponds to deterministic sampling",
)
parser.add_argument(
"--n_iter",
type=int,
default=2,
help="sample this often",
)
parser.add_argument(
"--H",
type=int,
default=512,
help="image height, in pixel space",
)
parser.add_argument(
"--W",
type=int,
default=512,
help="image width, in pixel space",
)
parser.add_argument(
"--C",
type=int,
default=4,
help="latent channels",
)
parser.add_argument(
"--f",
type=int,
default=8,
help="downsampling factor",
)
parser.add_argument(
"--n_samples",
type=int,
default=3,
help="how many samples to produce for each given prompt. A.k.a. batch size",
)
parser.add_argument(
"--n_rows",
type=int,
default=0,
help="rows in the grid (default: n_samples)",
)
parser.add_argument(
"--scale",
type=float,
default=7.5,
help="unconditional guidance scale: eps = eps(x, empty) + scale * (eps(x, cond) - eps(x, empty))",
)
parser.add_argument(
"--from-file",
type=str,
help="if specified, load prompts from this file",
)
parser.add_argument(
"--config",
type=str,
default="configs/stable-diffusion/v1-inference.yaml",
help="path to config which constructs model",
)
parser.add_argument(
"--ckpt",
type=str,
default="models/ldm/stable-diffusion-v1/model.ckpt",
help="path to checkpoint of model",
)
parser.add_argument(
"--seed",
type=int,
default=42,
help="the seed (for reproducible sampling)",
)
parser.add_argument(
"--precision",
type=str,
help="evaluate at this precision",
choices=["full", "autocast"],
default="autocast"
)
opt = parser.parse_args()
这一块对应Readme中的:
usage: txt2img.py [-h] [--prompt [PROMPT]] [--outdir [OUTDIR]] [--skip_grid] [--skip_save] [--ddim_steps DDIM_STEPS] [--plms] [--laion400m] [--fixed_code] [--ddim_eta DDIM_ETA]
[--n_iter N_ITER] [--H H] [--W W] [--C C] [--f F] [--n_samples N_SAMPLES] [--n_rows N_ROWS] [--scale SCALE] [--from-file FROM_FILE] [--config CONFIG] [--ckpt CKPT]
[--seed SEED] [--precision {full,autocast}]
optional arguments:
-h, --help show this help message and exit
--prompt [PROMPT] the prompt to render
--outdir [OUTDIR] dir to write results to
--skip_grid do not save a grid, only individual samples. Helpful when evaluating lots of samples
--skip_save do not save individual samples. For speed measurements.
--ddim_steps DDIM_STEPS
number of ddim sampling steps
--plms use plms sampling
--laion400m uses the LAION400M model
--fixed_code if enabled, uses the same starting code across samples
--ddim_eta DDIM_ETA ddim eta (eta=0.0 corresponds to deterministic sampling
--n_iter N_ITER sample this often
--H H image height, in pixel space
--W W image width, in pixel space
--C C latent channels
--f F downsampling factor
--n_samples N_SAMPLES
how many samples to produce for each given prompt. A.k.a. batch size
--n_rows N_ROWS rows in the grid (default: n_samples)
--scale SCALE unconditional guidance scale: eps = eps(x, empty) + scale * (eps(x, cond) - eps(x, empty))
--from-file FROM_FILE
if specified, load prompts from this file
--config CONFIG path to config which constructs model
--ckpt CKPT path to checkpoint of model
--seed SEED the seed (for reproducible sampling)
--precision {full,autocast}
evaluate at this precision
即使用txt2img.py脚本的方法,例如官方调用示例:
python scripts/txt2img.py --prompt "a photograph of an astronaut riding a horse" --plms
4、内部参数设置
if opt.laion400m:
print("Falling back to LAION 400M model...")
opt.config = "configs/latent-diffusion/txt2img-1p4B-eval.yaml"
opt.ckpt = "models/ldm/text2img-large/model.ckpt"
opt.outdir = "outputs/txt2img-samples-laion400m"
seed_everything(opt.seed)
config = OmegaConf.load(f"{opt.config}")
model = load_model_from_config(config, f"{opt.ckpt}")
device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
model = model.to(device)
if opt.plms:
sampler = PLMSSampler(model)
else:
sampler = DDIMSampler(model)
os.makedirs(opt.outdir, exist_ok=True)
outpath = opt.outdir