NEON 技术是 ARM Cortex™-A 系列处理器的 128 位 SIMD(单指令,多数据)架构扩展,旨在为消费性多媒体应用程序提供灵活、强大的加速功能,从而显著改善用户体验。它具有 32 个寄存器,64 位宽(双倍视图为 16 个寄存器,128 位宽。)
目前主流的iPhone手机和大部分android手机都支持ARM NEON加速,因此在编写移动端算法时,可利用NEON技术进行算法加速,以长度为4的寄存器大小为例,相应的提速倍数约是原始的4倍。
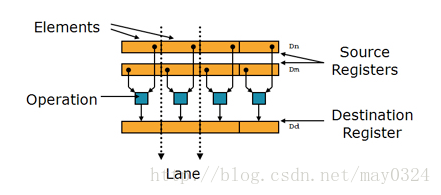
NEON 指令可执行“打包的 SIMD”处理:
寄存器被视为同一数据类型的元素的矢量
数据类型可为:签名/未签名的 8 位、16 位、32 位、64 位单精度浮点
指令在所有通道中执行同一操作
如下图所示:
本文主要介绍float32x4_t相关的结构及函数,
float32x4_t 可以理解为vector<float32> (4),同理typexN_t即为vector<type>(N)。
在NEON编程中,对单个数据的操作可以扩展为对寄存器,也即同一类型元素矢量的操作,因此大大减少了操作次数。
这里以一个小例子来解释如何利用NEON内置函数来加速实现统计一个数组内的元素之和。
以C++代码为例:
原始算法代码如下:
#include <iostream>
using namespace std;
float sum_array(float *arr, int len)
{
if(NULL == arr || len < 1)
{
cout<<"input error\n";
return 0;
}
float sum(0.0);
for(int i=0; i<len; ++i)
{
sum += *arr++;
}
return sum;
}
对于长度为N的数组,上述算法的时间复杂度时O(N)。
采用NEON函数进行加速:
#include <iostream>
#include <arm_neon.h>
using namespace std;
float sum_array(float *arr, int len)
{
if(NULL == arr || len < 1)
{
cout<<"input error\n";
return 0;
}
int dim4 = len >> 2;
int left4 = len & 3;
float32x4_t sum_vec = vdupq_n_f32(0.0);
for (; dim4>0; dim4--, arr+=4)
{
float32x4_t data_vec = vld1q_f32(arr);
sum_vec = vaddq_f32(sum_vec, data_vec);
}
float sum = vgetq_lane_f32(sum_vec, 0)+vgetq_lane_f32(sum_vec, 1)+vgetq_lane_f32(sum_vec, 2)+vgetq_lane_f32(sum_vec, 3);
for (; left4>0; left4--, arr++)
sum += (*arr) ;
return sum;
}
上述算法的时间复杂度时O(N/4)
从上面的例子看出,使用NEON函数很简单,只需要将依次处理,变为批处理(如上面的每次处理4个)。
上面用到的函数有:
float32x4_t vdupq_n_f32 (float32_t value)
将value复制4分存到返回的寄存器中
float32x4_t vld1q_f32 (float32_t const * ptr)
从数组中依次Load4个元素存到寄存器中
相应的 有void vst1q_f32 (float32_t * ptr, float32x4_t val)
将寄存器中的值写入数组中
float32x4_t vaddq_f32 (float32x4_t a, float32x4_t b)
返回两个寄存器对应元素之和 r = a+b
相应的 有float32x4_t vsubq_f32 (float32x4_t a, float32x4_t b)
返回两个寄存器对应元素之差 r = a-b
float32_t vgetq_lane_f32 (float32x4_t v, const int lane)
返回寄存器某一lane的值
其他常用的函数还有:
float32x4_t vmulq_f32 (float32x4_t a, float32x4_t b)
返回两个寄存器对应元素之积 r = a*b
float32x4_t vmlaq_f32 (float32x4_t a, float32x4_t b, float32x4_t c)
r = a +b*c
float32x4_t vextq_f32 (float32x4_t a, float32x4_t b, const int n)
拼接两个寄存器并返回从第n位开始的大小为4的寄存器 0<=n<=3
例如
a: 1 2 3 4
b: 5 6 7 8
vextq_f32(a,b,1) -> r: 2 3 4 5
vextq_f32(a,b,2) -> r: 3 4 5 6
vextq_f32(a,b,3) -> r: 4 5 6 7
float32x4_t sum = vdupq_n_f32(0);
float _a[] = {1,2,3,4}, _b[] = {5,6,7,8} ;
float32x4_t a = vld1q_f32(_a), b = vld1q_f32(_b) ;
float32x4_t sum1 = vfmaq_laneq_f32(sum, a, b, 0);
sum + a**b[0]
(0,0,0,0) + (1*5, 2*5, 3*5, 4*5) = (5, 10 ,15 ,20)
float32x4_t sum2 = vfmaq_laneq_f32(sum1, a, b, 1);
float32x4_t sum3 = vfmaq_laneq_f32(sum2, a, b, 2);
其他常用的函数可以参考开发网站
https://developer.arm.com/technologies/neon/intrinsics
总之,NEON学习入门很快,但如果想要更精深,就需要多花些时间和功夫在上面。
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)