一、前言知识
1、基于Region Proposal(候选区域)的深度学习目标检测算法
Region Proposal(候选区域),就是预先找出图中目标可能出现的位置,通过利用图像中的纹理、边缘、颜色等信息,保证在选取较少窗口(几千个甚至几百个)的情况下保持较高的召回率(IoU,Intersection-over-Union)。
2、什么是IoU?
Intersection over Union是一种测量在特定数据集中检测相应物体准确度的一个标准。我们可以在很多物体检测挑战中,例如PASCAL VOC challenge中看多很多使用该标准的做法。
通常我们在 HOG + Linear SVM object detectors 和 Convolutional Neural Network detectors (R-CNN, Faster R-CNN, YOLO, etc.)中使用该方法检测其性能。注意,这个测量方法和你在任务中使用的物体检测算法没有关系。
IoU是一个简单的测量标准,只要是在输出中得出一个预测范围(bounding boxex)的任务都可以用IoU来进行测量。为了可以使IoU用于测量任意大小形状的物体检测,我们需要:
1、 ground-truth bounding boxes(人为在训练集图像中标出要检测物体的大概范围);
2、我们的算法得出的结果范围。
也就是说,这个标准用于测量真实和预测之间的相关度,相关度越高,该值越高。
如下图:
下图展示了ground-truth和predicted的结果,绿色标线是人为标记的正确结果,红色标线是算法预测出来的结果,IoU要做的就是在这两个结果中测量算法的准确度。
Region Proposal方法比传统的滑动窗口方法获取的质量要更高。比较常用的Region Proposal方法有:SelectiveSearch(SS,选择性搜索)、Edge Boxes(EB)。
二、R-CNN、Fast R-CNN、Faster R-CNN三者关系
Faster R-CNN是基于R-CNN和Fast R-CNN来进行改进的。
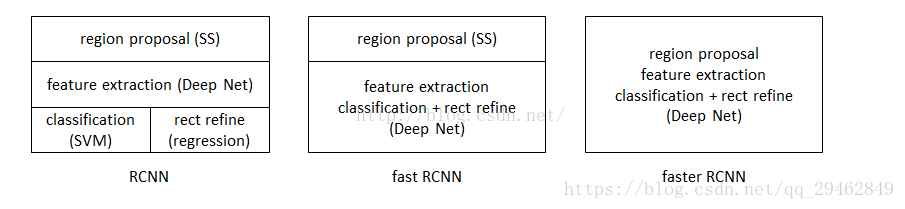
三者关系
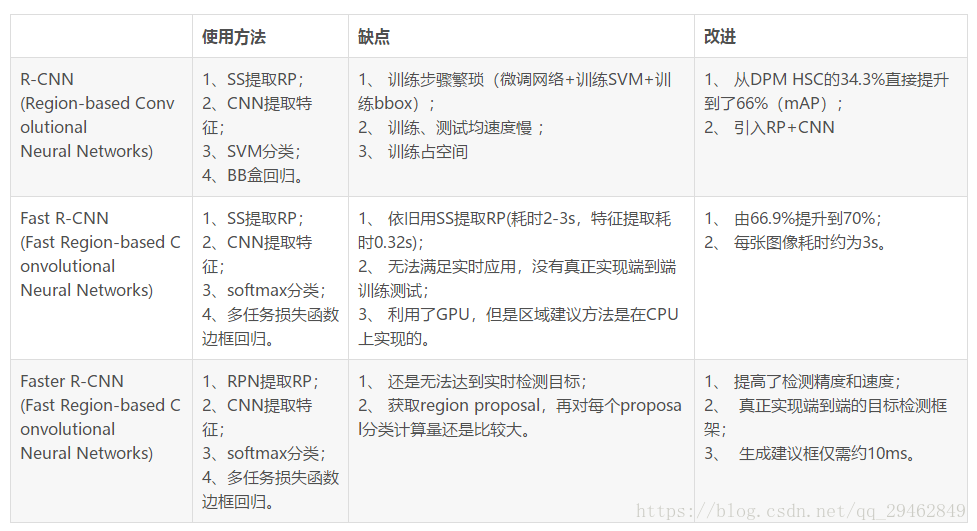
三者比较
关于R-CNN和Fast R-CNN更多细节请看R-CNN和Fast R-CNN
三、Faster R-CNN目标检测
3.1 Faster R-CNN的思想
Faster R-CNN可以简单地看做“区域生成网络RPNs + Fast R-CNN”的系统,用区域生成网络代替FastR-CNN中的Selective Search方法。Faster R-CNN这篇论文着重解决了这个系统中的三个问题:
1. 如何设计区域生成网络;
2. 如何训练区域生成网络;
3. 如何让区域生成网络和Fast RCNN网络共享特征提取网络。
在整个Faster R-CNN算法中,有三种尺度:
1. 原图尺度:原始输入的大小。不受任何限制,不影响性能。
- 归一化尺度:输入特征提取网络的大小,在测试时设置,源码中opts.test_scale=600。anchor在这个尺度上设定。这个参数和anchor的相对大小决定了想要检测的目标范围。
- 网络输入尺度:输入特征检测网络的大小,在训练时设置,源码中为224*224。
3.2 Faster R-CNN框架介绍
Input Image–生成候选区域–特征提取–分类–位置精修
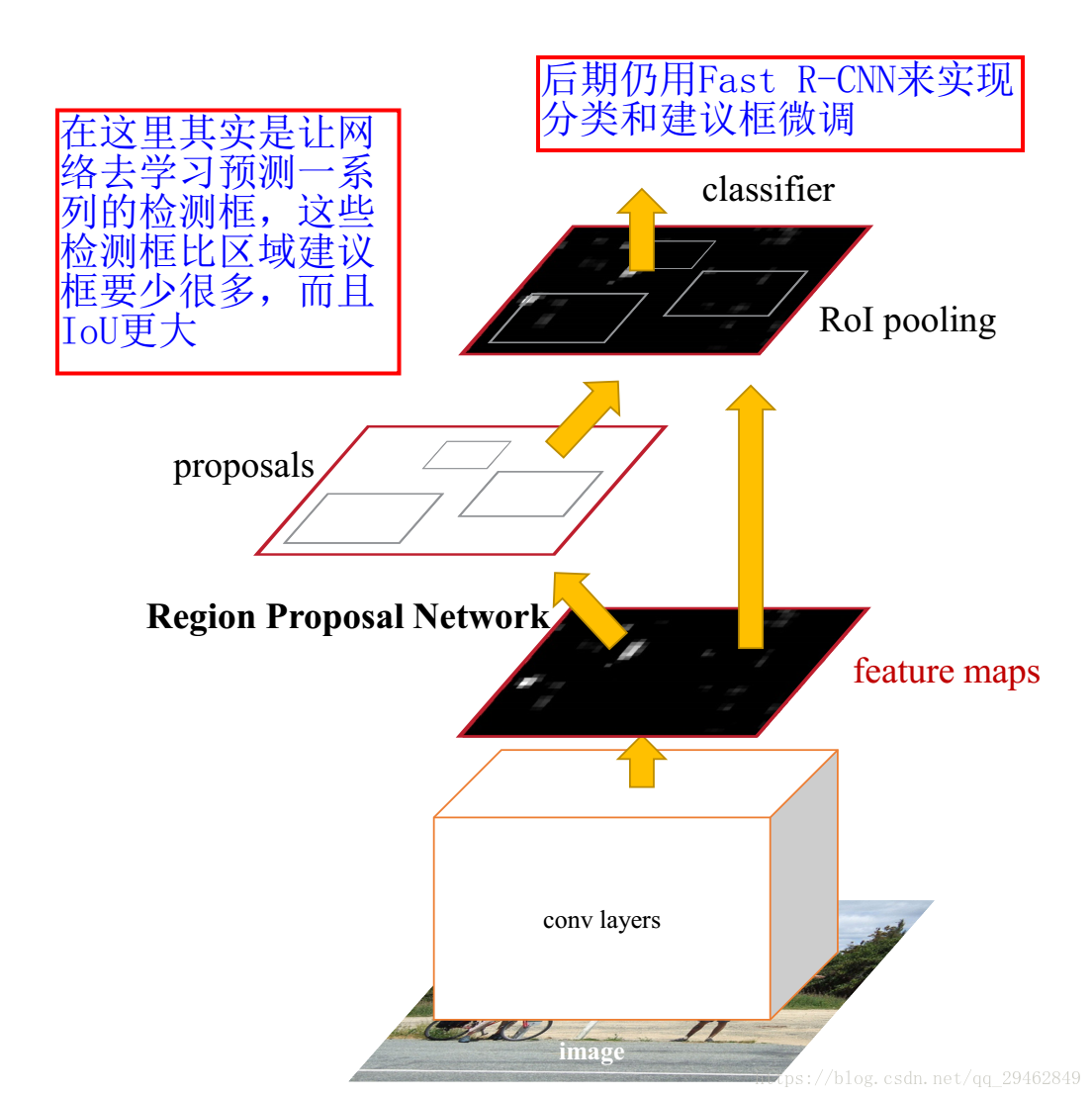
Faster R-CNN模型
Faster R-CNN算法由两大模块组成:
1.PRN候选框提取模块;
2.Fast R-CNN检测模块。
其中,RPN是全卷积神经网络,用于提取候选框;Fast R-CNN基于RPN提取的proposal检测并识别proposal中的目标。
3.3 RPN介绍
3.3.1背景
目前最先进的目标检测网络需要先用区域建议算法推测目标位置,像SPPnet和Fast R-CNN这些网络虽然已经减少了检测网络运行的时间,但是计算区域建议依然耗时较大。所以,在这样的瓶颈下,RBG和Kaiming He一帮人将Region Proposal也交给CNN来做,这才提出了RPN(Region Proposal Network)区域建议网络用来提取检测区域,它能和整个检测网络共享全图的卷积特征,使得区域建议几乎不花时间。
RCNN解决的是,“为什么不用CNN做classification呢?”
Fast R-CNN解决的是,“为什么不一起输出bounding box和label呢?”
Faster R-CNN解决的是,“为什么还要用selective search呢?”
3.3.2 RPN核心思想
RPN的核心思想是使用CNN卷积神经网络直接产生Region Proposal,使用的方法本质上就是滑动窗口(只需在最后的卷积层上滑动一遍),因为anchor机制和边框回归可以得到多尺度多长宽比的Region Proposal。
RPN网络也是全卷积网络(FCN,fully-convolutional network),可以针对生成检测建议框的任务端到端地训练,能够同时预测出object的边界和分数。只是在CNN上额外增加了2个卷积层(全卷积层cls和reg)。
①将每个特征图的位置编码成一个特征向量(256dfor ZF and 512d for VGG)。
②对每一个位置输出一个objectness score和regressedbounds for k个region proposal,即在每个卷积映射位置输出这个位置上多种尺度(3种)和长宽比(3种)的k个(3*3=9)区域建议的物体得分和回归边界。
RPN网络的输入可以是任意大小(但还是有最小分辨率要求的,例如VGG是228*228)的图片。如果用VGG16进行特征提取,那么RPN网络的组成形式可以表示为VGG16+RPN。
VGG16:参考
https://github.com/rbgirshick/py-faster-rcnn/blob/master/models/pascal_voc/VGG16/faster_rcnn_end2end/train.prototxt,可以看出VGG16中用于特征提取的部分是13个卷积层(conv1_1—->conv5.3),不包括pool5及pool5后的网络层次结构。
因为我们的最终目标是和Fast R-CNN目标检测网络共享计算,所以假设这两个网络共享一系列卷积层。在论文的实验中,ZF有5个可共享的卷积层, VGG有13个可共享的卷积层。
RPN的具体流程如下:使用一个小网络在最后卷积得到的特征图上进行滑动扫描,这个滑动网络每次与特征图上n*n(论文中n=3)的窗口全连接(图像的有效感受野很大,ZF是171像素,VGG是228像素),然后映射到一个低维向量(256d for ZF / 512d for VGG),最后将这个低维向量送入到两个全连接层,即bbox回归层(reg)和box分类层(cls)。sliding window的处理方式保证reg-layer和cls-layer关联了conv5-3的全部特征空间。
reg层:预测proposal的anchor对应的proposal的(x,y,w,h)
cls层:判断该proposal是前景(object)还是背景(non-object)。
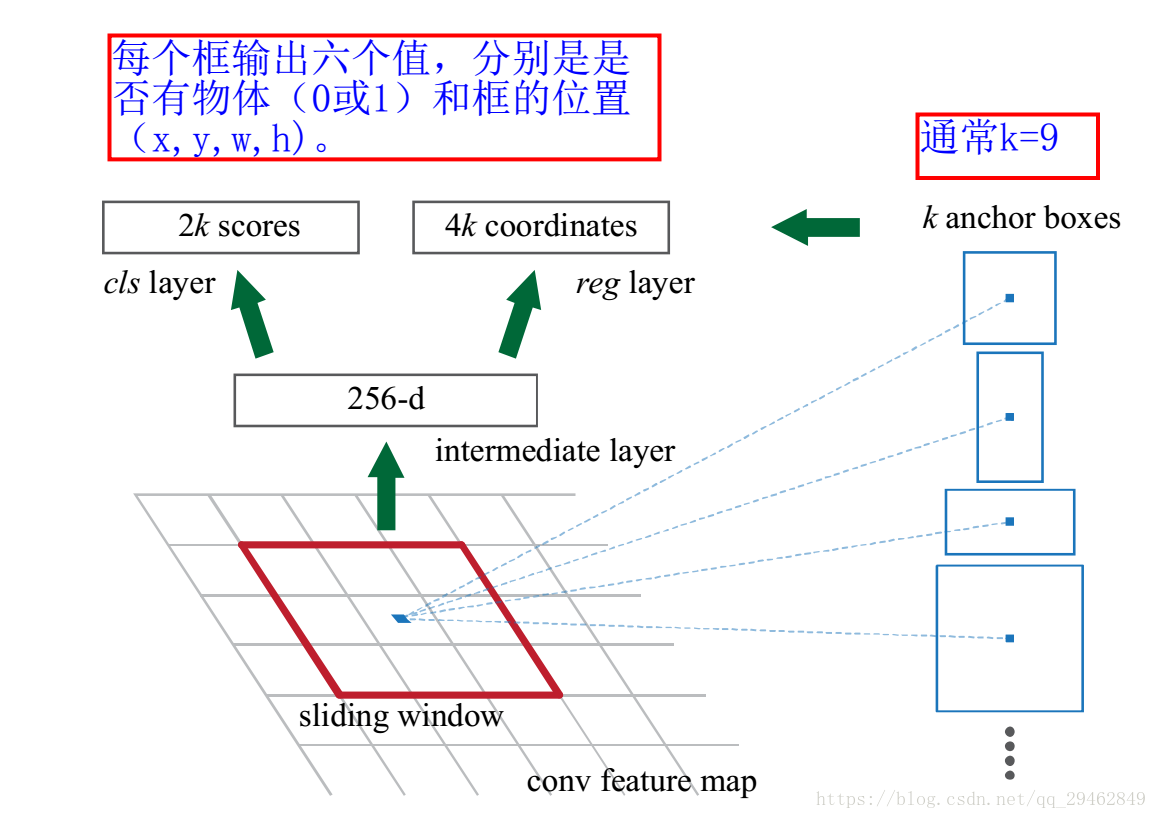
RPN框架
在上图中,要注意,3*3卷积核的中心点对应原图(re-scale,源代码设置re-scale为600*1000)上的位置(点),将该点作为anchor的中心点,在原图中框出多尺度、多种长宽比的anchors。所以,anchor不在conv特征图上,而在原图上。对于一个大小为H*W的特征层,它上面每一个像素点对应9个anchor,这里有一个重要的参数feat_stride = 16, 它表示特征层上移动一个点,对应原图移动16个像素点(看一看网络中的stride就明白16的来历了)。把这9个anchor的坐标进行平移操作,获得在原图上的坐标。之后根据ground truth label和这些anchor之间的关系生成rpn_lables,具体的方法论文中有提到,根据overlap来计算,这里就不详细说明了,生成的rpn_labels中,positive的位置被置为1,negative的位置被置为0,其他的为-1。box_target通过_compute_targets()函数生成,这个函数实际上是寻找每一个anchor最匹配的ground truth box, 然后进行论文中提到的box坐标的转化。
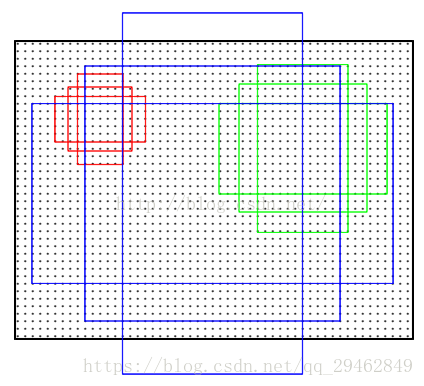
九种anchor(三种尺度[128x128;256x256;512x512],三种比例[1:1;1:2;2:1])
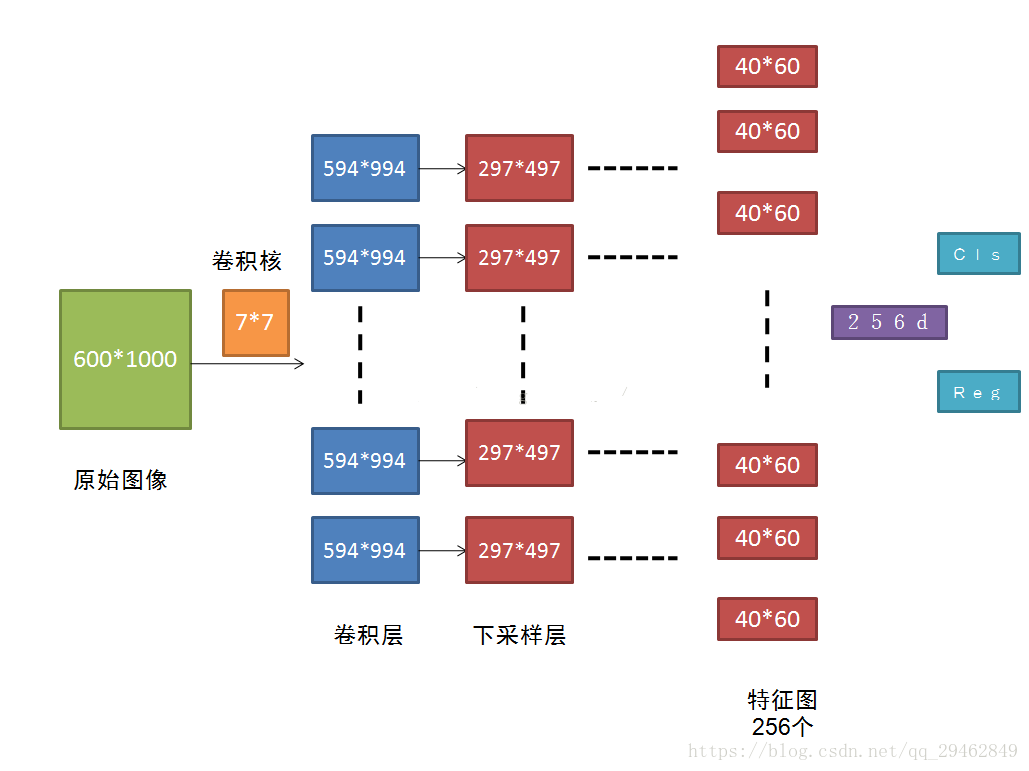
Faster R-CNN卷积流程图
原图600*1000经CNN卷积后,在CNN最后一层(conv5)得出的是40*60大小的特征图,对应文中说的典型值为2400。若特征图大小为W*H,则需要W*H*K个anchor,本文中需要40*60*9≈2k个。
在RPN网络中,我们需要重点理解其中的anchors概念,Loss fucntions计算方式和RPN层训练数据生成的具体细节。
3.4 RPN的平移不变性
在计算机视觉中的一个挑战就是平移不变性:比如人脸识别任务中,小的人脸(24*24的分辨率)和大的人脸(1080*720)如何在同一个训练好权值的网络中都能正确识别。若是平移了图像中的目标,则建议框也应该平移,也应该能用同样的函数预测建议框。
传统有两种主流的解决方式:
第一、对图像或feature map层进行尺度\宽高的采样;
第二、对滤波器进行尺度\宽高的采样(或可以认为是滑动窗口).
但Faster R-CNN解决该问题的具体实现是:通过卷积核中心(用来生成推荐窗口的Anchor)进行尺度、宽高比的采样,使用3种尺度和3种比例来产生9种anchor。
3.5 窗口分类和位置精修
分类层(cls_score)输出每一个位置上,9个anchor属于前景和背景的概率。
窗口回归层(bbox_pred)输出每一个位置上,9个anchor对应窗口应该平移缩放的参数(x,y,w,h)。
对于每一个位置来说,分类层从256维特征中输出属于前景和背景的概率;窗口回归层从256维特征中输出4个平移缩放参数。
需要注意的是:并没有显式地提取任何候选窗口,完全使用网络自身完成判断和修正。
3.6 学习区域建议损失函数
3.6.1 标签分类规定
为了训练RPN,需要给每个anchor分配的类标签{目标、非目标}。对于positive label(正标签),论文中给了如下规定(满足以下条件之一即可判为正标签):
1.与GT包围盒最高IoU重叠的anchor
2.与任意GT包围盒的IoU大于0.7的anchor
注意,一个GT包围盒可以对应多个anchor,这样一个GT包围盒就可以有多个正标签。
事实上,采用第②个规则基本上可以找到足够的正样本,但是对于一些极端情况,例如所有的Anchor对应的anchor box与groud truth的IoU不大于0.7,可以采用第一种规则生成。
negative label(负标签):与所有GT包围盒的IoU都小于0.3的anchor。
对于既不是正标签也不是负标签的anchor,以及跨越图像边界的anchor我们给予舍弃,因为其对训练目标是没有任何作用的。
3.6.2 多任务损失(来自Fast R-CNN)
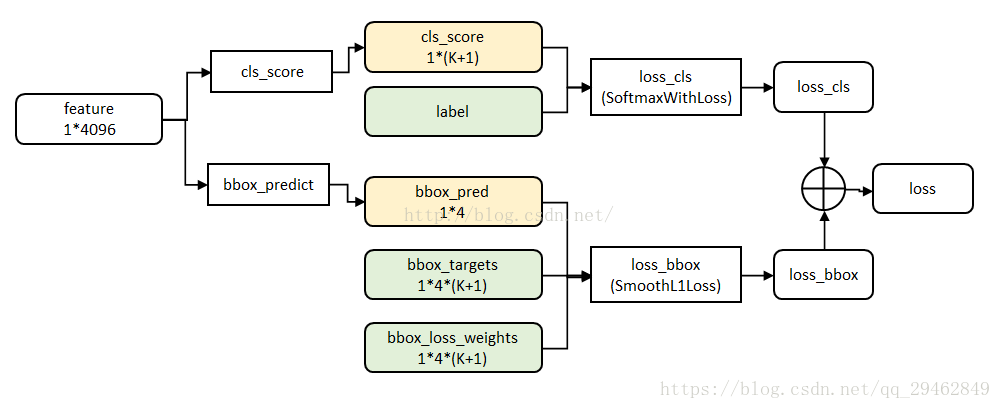
multi-task数据结构
这里一共涉及到两种损失:分类和回归(具体内容可参考论文)
关于回归可以参考R-CNN和Fast R-CNN,在这里不在多述
3.7 非极大值抑制
极大值抑制是用来提出多余的检测框,关于该算法可以参考NMS算法
4.源代码
在这里使用的是谷歌开源的object detection api代码,关于该代码的安装配置谷歌物体检测框架配置教程
在这里已经配置完成,可以直接运行源代码!!!
下面是利用训练好的模型直接检测物体,除了检测单幅图像,代码中还包括检测视频中的物体。
import numpy as np
import os
import six.moves.urllib as urllib
import sys
import tarfile
import tensorflow as tf
import zipfile
from collections import defaultdict
from io import StringIO
from matplotlib import pyplot as plt
from PIL import Image
import cv2
sys.path.append("..")
from utils import label_map_util
from utils import visualization_utils as vis_util
MODEL_NAME = 'faster_rcnn_resnet101_coco_11_06_2017'
MODEL_FILE = MODEL_NAME + '.tar.gz'
DOWNLOAD_BASE = 'http://download.tensorflow.org/models/object_detection/'
PATH_TO_CKPT = MODEL_NAME + '/frozen_inference_graph.pb'
PATH_TO_LABELS = os.path.join('data', 'mscoco_label_map.pbtxt')
NUM_CLASSES = 90
opener = urllib.request.URLopener()
tar_file = tarfile.open(MODEL_FILE)
for file in tar_file.getmembers():
file_name = os.path.basename(file.name)
if 'frozen_inference_graph.pb' in file_name:
tar_file.extract(file, os.getcwd())
detection_graph = tf.Graph()
with detection_graph.as_default():
od_graph_def = tf.GraphDef()
with tf.gfile.GFile(PATH_TO_CKPT, 'rb') as fid:
serialized_graph = fid.read()
od_graph_def.ParseFromString(serialized_graph)
tf.import_graph_def(od_graph_def, name='')
label_map = label_map_util.load_labelmap(PATH_TO_LABELS)
categories = label_map_util.convert_label_map_to_categories(label_map, max_num_classes=NUM_CLASSES, use_display_name=True)
category_index = label_map_util.create_category_index(categories)
def load_image_into_numpy_array(image):
(im_width, im_height) = image.size
return np.array(image.getdata()).reshape(
(im_height, im_width, 3)).astype(np.uint8)
PATH_TO_TEST_IMAGES_DIR = 'test_images'
TEST_IMAGE_PATHS = [ os.path.join(PATH_TO_TEST_IMAGES_DIR, 'image{}.jpg'.format(i)) for i in range(1, 4) ]
IMAGE_SIZE = (12, 8)
with detection_graph.as_default():
with tf.Session(graph=detection_graph) as sess:
for image_path in TEST_IMAGE_PATHS:
image = Image.open(image_path)
image_np = load_image_into_numpy_array(image)
image_np_expanded = np.expand_dims(image_np, axis=0)
image_tensor = detection_graph.get_tensor_by_name('image_tensor:0')
boxes = detection_graph.get_tensor_by_name('detection_boxes:0')
scores = detection_graph.get_tensor_by_name('detection_scores:0')
classes = detection_graph.get_tensor_by_name('detection_classes:0')
num_detections = detection_graph.get_tensor_by_name('num_detections:0')
(boxes, scores, classes, num_detections) = sess.run(
[boxes, scores, classes, num_detections],
feed_dict={image_tensor: image_np_expanded})
vis_util.visualize_boxes_and_labels_on_image_array(
image_np,
np.squeeze(boxes),
np.squeeze(classes).astype(np.int32),
np.squeeze(scores),
category_index,
use_normalized_coordinates=True,
line_thickness=8)
plt.figure(figsize=IMAGE_SIZE)
plt.imshow(image_np)
实验结果
源代码链接:Faster R-CNN源代码
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)