前言:
从上个世纪卡尔曼滤波理论被提出,卡尔曼滤波在控制论与信息论的连接上做出了卓越的贡献。为了得出准确的下一时刻状态真值,我们常常使用卡尔曼滤波、扩展卡尔曼滤波、无迹卡尔曼滤波、粒子滤波等等方法,这些方法在姿态解算、轨迹规划等方面有着很多用途。卡尔曼滤波的本质是参数化的贝叶斯模型,通过对下一时刻系统的初步状态估计(即状态的先验估计)以及测量得出的反馈相结合,最终得到改时刻较为准确的的状态估计(即状态的后验估计),其核心思想即为预测+测量反馈,而这两者是通过一个变化的权值相联系使得最后的状态后验估计无限逼近系统准确的状态真值,这个权值即为大名鼎鼎的卡尔曼增益。可以说,卡尔曼滤波并不与传统的在频域的滤波相似,而是一种在时域的状态预测器,这就省去了时域频域的变换的步骤,而这种状态预测器不仅仅在工程上有很广的应用,在金融方面例如股票的走势等等方面也可以有很多的应用。
一直以来,卡尔曼滤波相关的资料较少,很多人觉得很难,因此写下这篇博客来帮助大家更好的理解卡尔曼滤波的运作原理。
2017年2月11日 by 回忆不能已 转载请声明出处 谢谢合作
————————————————————————————————————————————————————————————————————————————————————
一、卡尔曼滤波的定义
卡尔曼滤波的定义:
一种利用线性系统状态方程,通过系统输入输出观测数据,对系统状态进行最优估计的算法。由于观测数据中包括系统中的噪声和干扰的影响,所以最优估计也可看作是滤波过程。
1.1 线性系统状态方程
首先我们来看什么是线性系统状态方程,这个名词包含线性系统、状态这两个特征。
线性系统
状态空间描述(内部描述):基于系统内部结构,是对系统的一种完整的描述。
状态方程
描述系统状态变量间或状态变量与系统输入变量间关系的一个一阶微分方程组(连续系统)或一阶差分方程组(离散系统),称为状态方程。
1.2 观测数据
观测数据代表传感器采集的实际数据,可能存在着或多或少的误差,例如陀螺仪的积分误差等。
1.3 最优估计
最优估计指的是使经过KF算法解算的数据无限接近于真实值的估计,用数学表述即为后验概率估计无限接近于真实值。
二、卡尔曼滤波算法流程
卡尔曼滤波算法核心思想在于预测+测量反馈,它由两部分组成,第一部分是 线性系统状态预测方程,第二部分是 线性系统观测方程。
2.1 线性系统状态预测方程
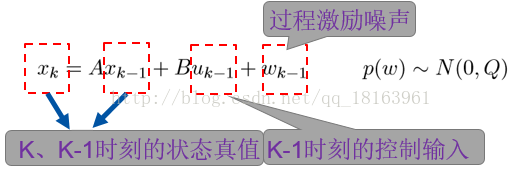
A :表示状态转移系数矩阵,n×n 阶
B :表示可选的控制输入的增益矩阵
Q :表示过程激励噪声的协方差矩阵
上图为线性系统状态预测方程的表达式,假设过程激励噪声满足高斯分布。
2.2 线性系统观测方程

H :表示量测系数矩阵,m×n 阶矩阵
R :表示测量噪声协方差矩阵
上图为线性系统观测方程表达式,假设测量噪声矩阵满足高斯分布
随机信号 wk和vk分别表示过程激励噪声和观测噪声。Kf算法中假设它们为相互独立,正态分布的白色噪声。
预测+测量反馈进行后续的估计,那kf算法到底是如何利用预测状态与测量的反馈进行最优估计的呢?这部分我们将在后续的模型及数学推导来详细讲解
2.3 扩展卡尔曼滤波EKF流程
EKF的基本思想是将非线性系统线性化,然后进行卡尔曼滤波,因此EKF是一种伪非线性的卡尔曼滤波。实际中一阶EKF应用广泛。
但EKF存在一定的局限性:
其一是当强非线性时EKF违背局部线性假设,Taylor展开式中被忽略的高阶项带来大的误差时,EKF算法可能会使滤波发散;
另外,由于EKF在线性化处理时需要用雅克比(Jacobian)矩阵,其繁琐的计算过程导致该方法实现相对困难。所以,在满足线性系统、高斯白噪声、所有随机变量服从高斯(Gaussian)分布这3个假设条件时,EKF是最小方差准则下的次优滤波器,其性能依赖于局部非线性度。
以PIXHAWK飞控代码为例说明:
1、非线性系统线性化
EKF对非线性函数的Taylor展开式进行一阶线性化截断,忽略其余高阶项,从而将非线性问题转化为线性,可以将卡尔曼线性滤波算法应用于非线性系统中多种二阶广义卡尔曼滤波方法的提出及应用进一步提高了卡尔曼滤波对非线性系统的估计性能
2、二阶滤波方法考虑了Taylor级数展开的二次项,因此减少了由于线性化所引起的估计误差,但大大增加了运算量
3、pixhawk开源项目使用的是一阶EKF滤波,因为二到三阶滤波计算量较大如果飞行器的处理速度能跟上,可以考虑2-3阶滤波。
扩展卡尔曼滤波的状态预测方程以及观测方程与一般的卡尔曼滤波略有不同:


KF与EKF的联系如下图所示:

三、卡尔曼滤波算法模型
3.1 卡尔曼滤波算法应用前提
(1)系统是可观测的
(2)系统为线性系统,能够写出下一时刻的状态预测方程
(3)假设系统的噪声统计特性可观测
应用中大多数情况下并不知道建模噪声和观测噪声的统计特性,一般假定为零均值,方差的值通过测试或是经验丰富的开发人员设置得到,噪声一般直接简化假设为高斯白噪声
3.2 预先的一些数学知识准备
先验估计:先验状态估计是根据系统过程原理或者经验得到的估计值,实际应用中可以通过传感器数据去预测下一时刻的数据
后验估计:后验状态估计是结合之前的先验状态估计值,再加权测量值得到一个理论上最接近真实值的结果
协方差:协方差用于衡量两个变量的总体误差。而方差是协方差的一种特殊情况,即当两个变量是相同的情况
均方差:它是“误差”的平方的期望值
矩阵的迹:矩阵主对角线上的所有元素之和称之为矩阵的迹
协方差矩阵的主对角线元素分别为两个变量的方差
最小均方差估计就是指估计参数时要使得估计出来的模型和真实值之间的误差平方期望值最小。
3.3 模型讲解
实际的状态模型如下所示:
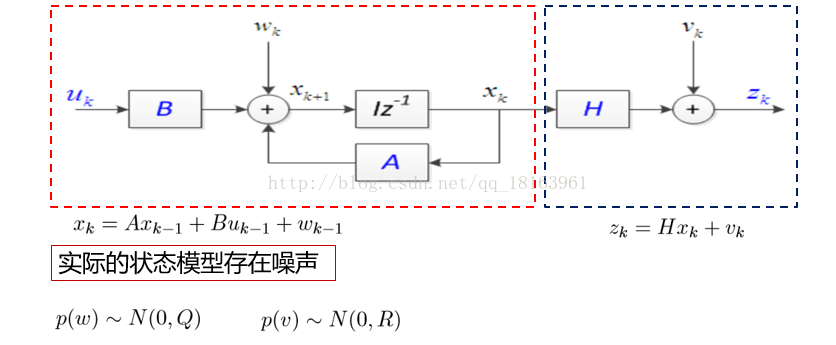
随机信号w和v分别表示过程激励噪声和观测噪声。
假设它们为相互独立,正态分布的白色噪声
图片中蓝色标记的为已知的矩阵和信息,卡尔曼滤波的目的就是利用这些已知的信息估计离散时间过程的状态变量。为什么是估计呢?因为有噪声、 存在。而信息就这么多,我们要做的就是利用这手头的信息尽量准确的估计出离散过程的状态变量,从而随时掌握系统的运行状态和变化。
举个日常生活的例子:
假设你有两个传感器,测的是同一个信号。可是它们每次的读数都不太一样,怎么办?取平均。
再假设你知道其中贵的那个传感器应该准一些,便宜的那个应该差一些。那有比取平均更好的办法吗?加权平均。
怎么加权?假设两个传感器的误差都符合正态分布,假设你知道这两个正态分布的方差,用这两个方差值,(此处省略若干数学公式),你可以得到一个“最优”的权重。

接下来,重点来了:
假设你只有一个传感器,但是你还有一个数学模型。模型可以帮你算出一个值,但也不是那么准。怎么办?把模型算出来的值,和传感器测出的值,(就像两个传感器那样),取加权平均。OK,最后一点说明:你的模型其实只是一个步长的,也就是说,知道x(k),我可以求x(k+1)。问题是x(k)是多少呢?答案:x(k)就是你上一步卡尔曼滤波得到的、所谓加权平均之后的那个、对x在k时刻的最佳估计值。于是迭代也有了。
卡尔曼滤波的模型:
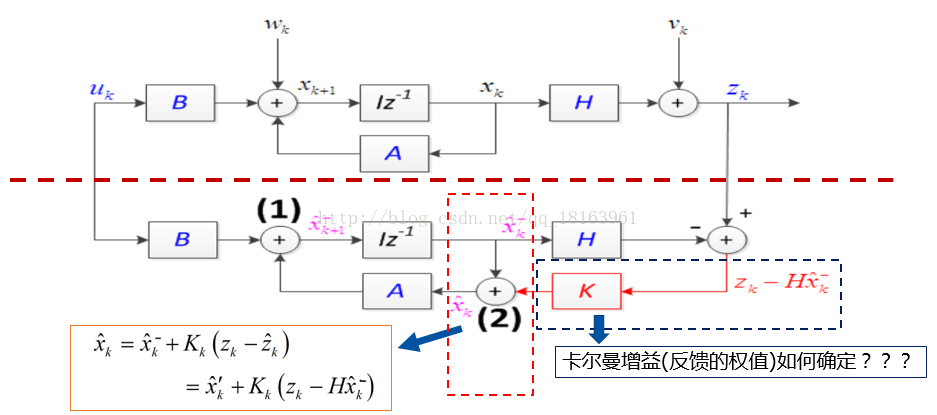
带卡尔曼滤波器的系统方框图,图中的上半部分是实际的离散时间过程(有噪声的存在),下面部分是卡尔曼滤波器。卡尔曼滤波器通过利用蓝色标记的可用信息对系统的状态变量进行估计,得出粉色标记的方框,而这个得以实现的关键就是红色标记出的反馈信息的利用,即设置怎样的反馈增益矩阵K使状态变量在某种意义下最准确,最接近真实系统状态。
我们认定是预测(先验)值,是估计值,为测量值的预测,在下面的推导中,请注意估计和预测两者的区别,不混为一谈。由一般的反馈思想我们得到估计值:
其中括号里面的公式称之为残差,也就是预测的和你实际测量值之间的差距。如果这项等于0,说明预测和测量出的完全吻合。
关键就是求取这个K。这时最小均方差就起到了作用。
顺便在这里回答为什么噪声必须服从高斯分布,在进行参数估计的时候,估计的一种标准叫最大似然估计,它的核心思想就是你手里的这些相互间独立的样本既然出现了,那就说明这些样本概率的乘积应该最大(概率大才出现嘛)。如果样本服从概率高斯分布,对他们的概率乘积取对数ln后,你会发现函数形式将会变成一个常数加上样本最小均方差的形式。因此,看似直观上很容易理解的最小均方差理论上来源就出于那里。
我们想得到最优的估计,那么必须知道k时刻的后验估计协方差与k时刻的先验估计协方差。
k时刻的后验估计协方差表达式为

红色方框里面表达式在前面提过,即
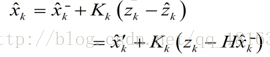
k时刻的先验估计协方差表达式为
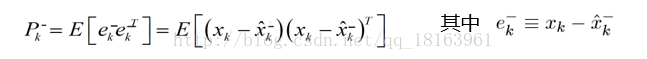
我们把k时刻的后验估计协方差矩阵的迹即为T[Pk]

Pk对角线元素的和即为均方差。
x^k¯:表示k时刻先验状态估计值,这是算法根据前次迭代结果(就是上一次循环的后验估计值)做出的不可靠估计。x^k、x^k−1:分别表示k时刻、k-1时刻后验状态估计值,也就是要输出的该时刻最优估计值,这个值是卡尔曼滤波的结果。 A :表示状态转移矩阵,是n×n阶方阵,它是算法对状态变量进行预测的依据,状态转移矩阵如果不符合目标模型有可能导致滤波发散,它的确定请参看第二节中的举例。
B :表示可选的控制输入u∈Rl的增益,在大多数实际情况下并没有控制增益。
uk−1:表示k-1时刻的控制增益,一般没有这个变量,可以设为0。
P^k¯ :表示k时刻的先验估计协方差,这个协方差矩阵只要确定了一开始的P^0,后面都可以递推出来,而且初始协方差矩阵P^0只要不是为0,它的取值对滤波效果影响很小,都能很快收敛。
P^k 、P^k−1 :分别表示k时刻、k-1时刻的后验估计协方差,是滤波结果之一。
Q:表示过程激励噪声的协方差,它是状态转移矩阵与实际过程之间的误差。这个矩阵是卡尔曼滤波中比较难确定的一个量,一般有两种思路:一是在某些稳定的过程可以假定它是固定的矩阵,通过寻找最优的Q值使滤波器获得更好的性能,这是调整滤波器参数的主要手段,Q一般是对角阵,且对角线上的值很小,便于快速收敛;二是在自适应卡尔曼滤波(AKF)中Q矩阵是随时间变化的。
Kk :表示卡尔曼增益,是滤波的中间结果。
zk :表示测量值,是m阶向量。
H:表示量测矩阵,是m×n阶矩阵,它把m维测量值转换到n维与状态变量相对应。
R:表示测量噪声协方差,它是一个数值,这是和仪器相关的一个特性,作为已知条件输入滤波器。需要注意的是这个值过大过小都会使滤波效果变差,且R取值越小收敛越快,所以可以通过实验手段寻找合适的R值再利用它进行真实的滤波。
最小均方差求解
均方差对未知量K求导,令导函数等于0,就能确定卡尔曼增益K的值,完成模型的最小均方差估计,从而使后验估计的误差很小,更加逼近状态的真值
求最小均方差确定卡尔曼增益的表达式
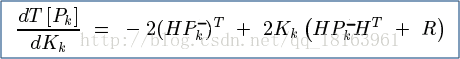

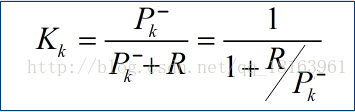
H:表示量测矩阵
R:表示测量噪声协方差,和仪器相关
3.4 卡尔曼增益的分析
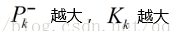
先验估计误差较大,我们需要更加信任测量反馈,模型自动加大卡尔曼增益来进行更准确的估计

先验估计没有任何误差,我们只需要通过预测就能够得到准确的后验估计,无需测量的反馈,模型自动将测量反馈的权值设为0
3.5模型的迭代过程

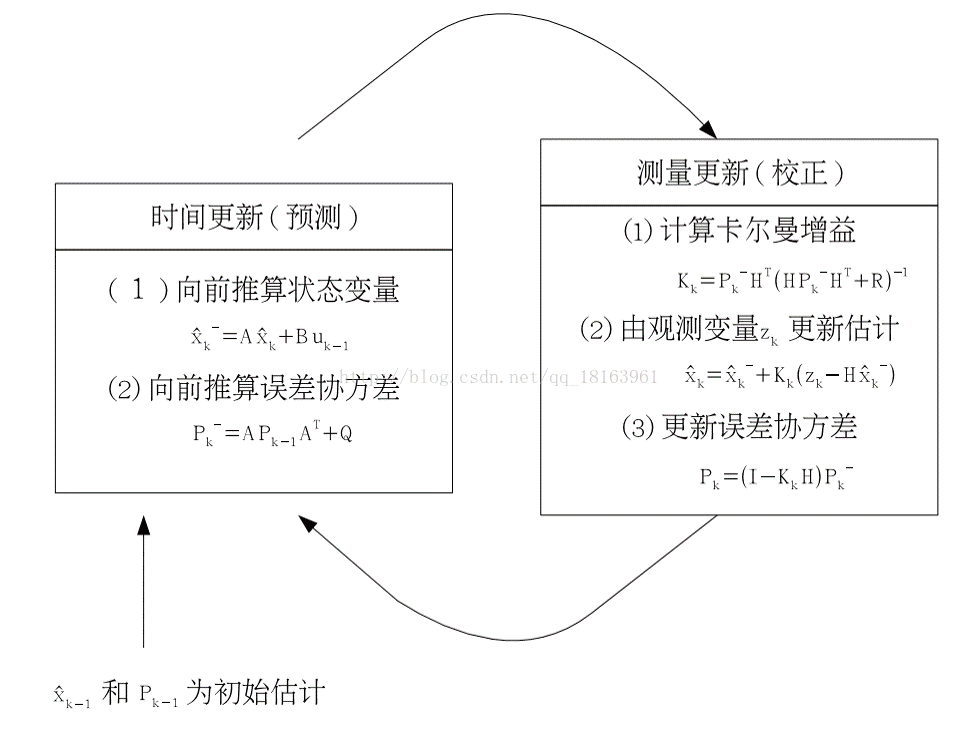
3.5.1时间更新方程
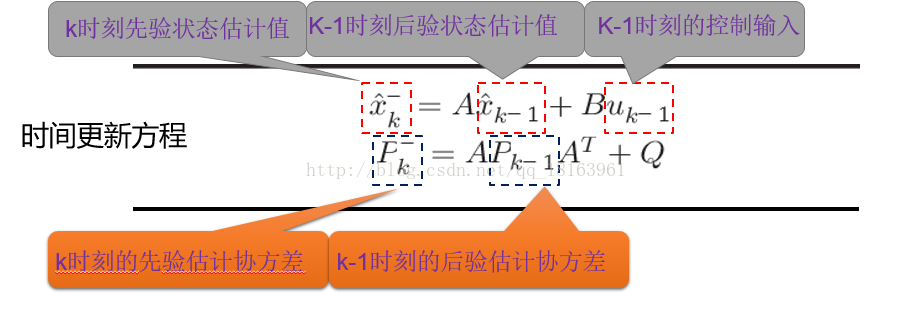
A :表示状态转移矩阵,n×n 阶
B :表示可选的控制输入的增益矩阵
Q :表示过程激励噪声的协方差矩阵
3.5.2 状态更新方程

H :表示量测矩阵,m×n 阶矩阵
R :表示测量噪声协方差矩阵
3.5.3 迭代示意图
下篇博客会详细分析EKF的模型,对其非线性系统的建模进行讲解,欢迎大家指出博客中的错误!
--------------------- 本文来自 回忆不能已 的CSDN 博客 ,全文地址请点击:https://blog.csdn.net/qq_18163961/article/details/52505591?utm_source=copy
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)