基于回归的文本检测
基于回归文本检测方法和目标检测算法的方法相似,文本检测方法只有两个类别,图像中的文本视为待检测的目标,其余部分视为背景。
水平文本检测
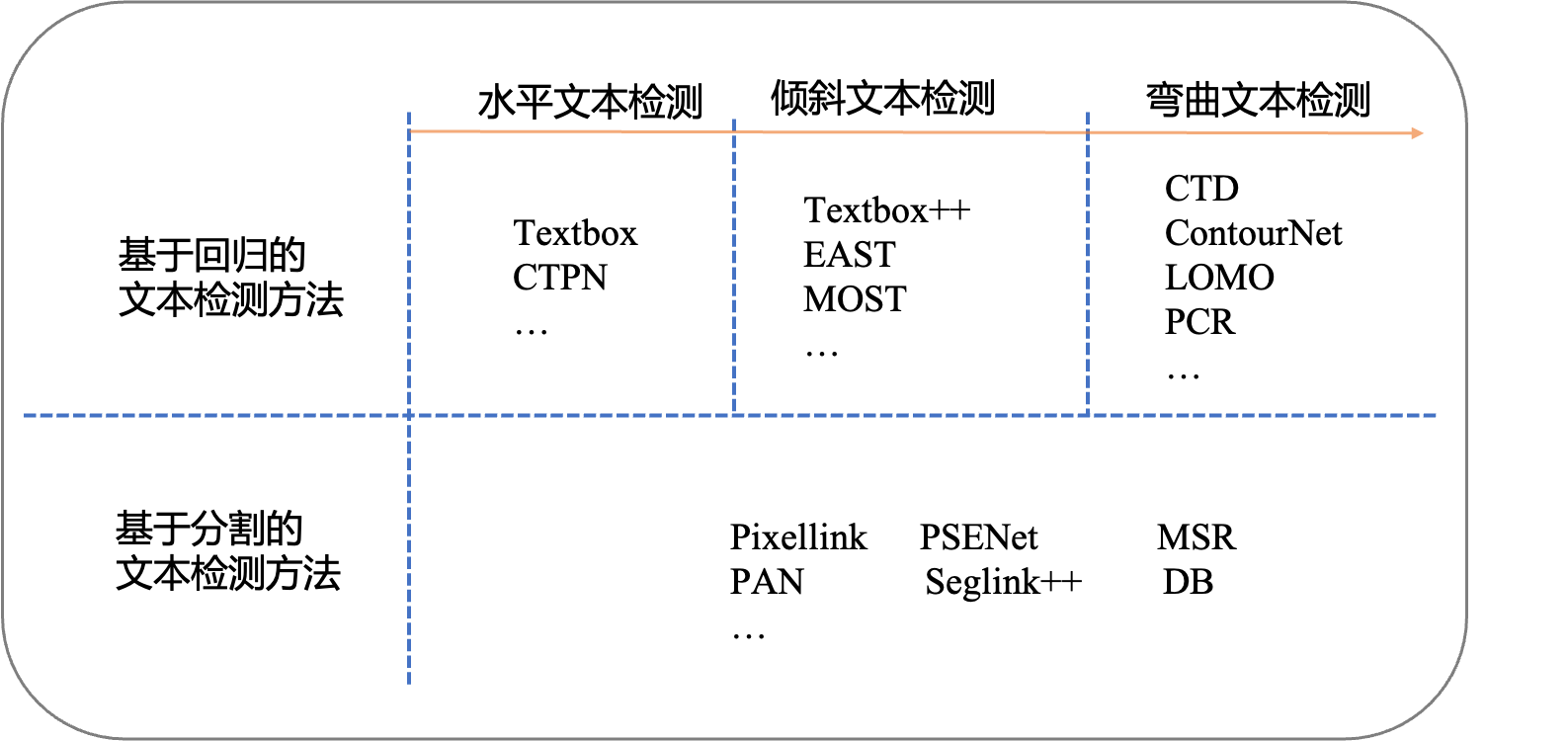
早期基于深度学习的文本检测算法是从目标检测的方法改进而来,支持水平文本检测。比如Textbox算法基于SSD算法改进而来,CTPN根据二阶段目标检测Fast-RCNN算法改进而来。
CTPN基于Fast-RCNN算法,扩展RPN模块并且设计了基于CRNN的模块让整个网络从卷积特征中检测到文本序列,二阶段的方法通过ROI Pooling获得了更准确的特征定位。但是TextBoxes和CTPN只支持检测横向文本。
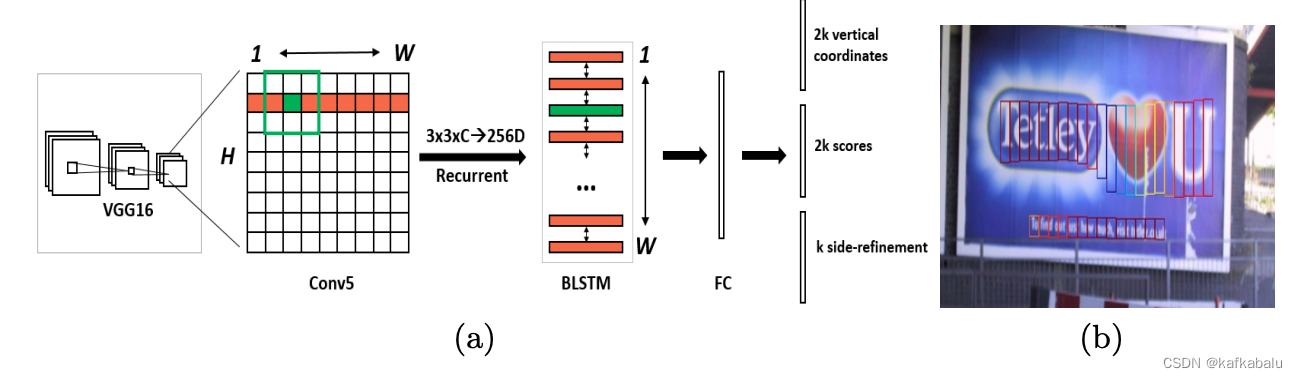
如何实现弯曲文本检测呢?
一个简单的思路是用多点坐标描述弯曲文本的边界多边形,然后直接预测多边形的顶点坐标。
基于分割的文本检测
基于回归的方法虽然在文本检测上取得了很好的效果,但是对解决弯曲文本往往难以得到平滑的文本包围曲线,并且模型较为复杂不具备性能优势。
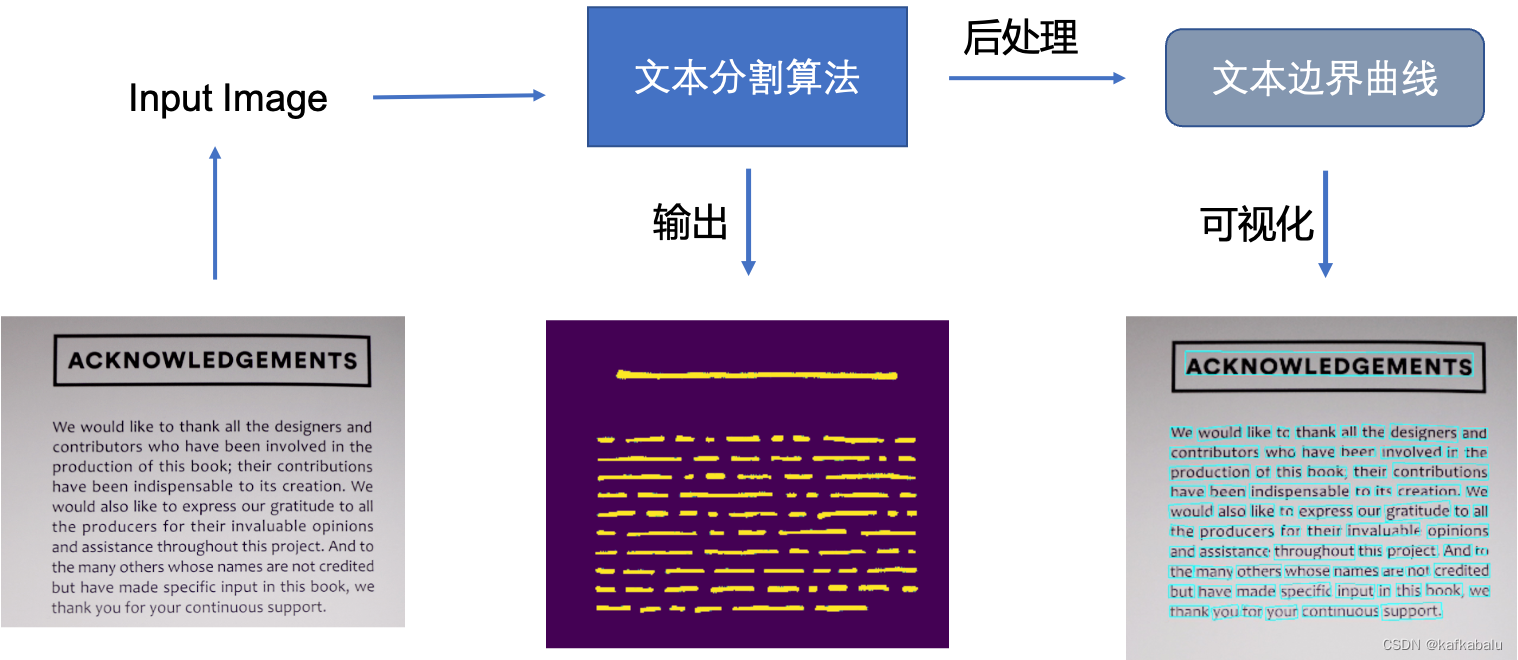
于是研究者们提出了基于图像分割的文本分割方法,先从像素层面做分类,判别每一个像素点是否属于一个文本目标,得到文本区域的概率图,通过后处理方式得到文本分割区域的包围曲线。
1 DB文本检测算法详细实现
1.1 DB文本检测算法原理
DB是一个基于分割的文本检测算法,其提出可微分阈值Differenttiable Binarization module(DB module)采用动态的阈值区分文本区域与背景。
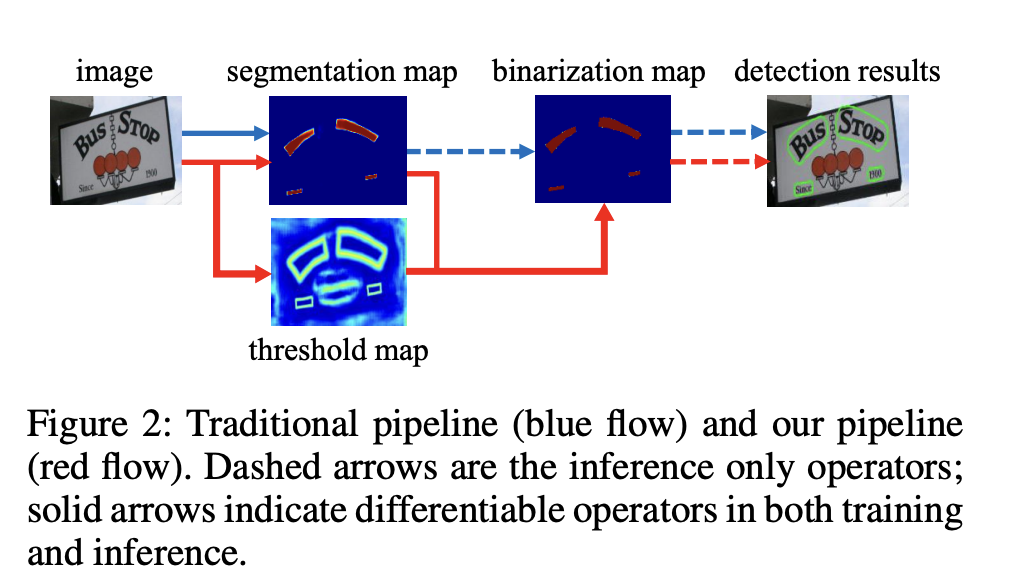
图1 DB模型与其他方法的区别
基于分割的普通文本检测算法其流程如上图中的蓝色箭头所示,此类方法得到分割结果之后采用一个固定的阈值得到二值化的分割图,之后采用诸如像素聚类的启发式算法得到文本区域。
DB算法的流程如图中红色箭头所示,最大的不同在于DB有一个阈值图,通过网络去预测图片每个位置处的阈值,而不是采用一个固定的值,更好的分离文本背景与前景。
DB算法有以下几个优势:
- 算法结构简单,无需繁琐的后处理
- 在开源数据上拥有良好的精度和性能
在传统的图像分割算法中,获取概率图后,会使用标准二值化(Standard Binarize)方法进行处理,将低于阈值的像素点置0,高于阈值的像素点置1,公式如下:
B
i
,
j
=
{
1
,
i
f
P
i
,
j
>
=
t
,
0
,
o
t
h
e
r
w
i
s
e
.
B_{i,j}=\left\{ \begin{aligned} 1 , if P_{i,j} >= t ,\\ 0 , otherwise. \end{aligned} \right.
Bi,j={1,ifPi,j>=t,0,otherwise.
但是标准的二值化方法是不可微的,导致网络无法端对端训练。为了解决这个问题,DB算法提出了可微二值化(Differentiable Binarization,DB)。可微二值化将标准二值化中的阶跃函数进行了近似,使用如下公式进行代替:
B
^
=
1
1
+
e
−
k
(
P
i
,
j
−
T
i
,
j
)
\hat{B} = \frac{1}{1 + e^{-k(P_{i,j}-T_{i,j})}}
B^=1+e−k(Pi,j−Ti,j)1
其中,P是上文中获取的概率图,T是上文中获取的阈值图,k是增益因子,在实验中,根据经验选取为50。标准二值化和可微二值化的对比图如 下图3(a) 所示。
当使用交叉熵损失时,正负样本的loss分别为
l
+
l_+
l+ 和
l
−
l_-
l− :
l
+
=
−
l
o
g
(
1
1
+
e
−
k
(
P
i
,
j
−
T
i
,
j
)
)
l_+ = -log(\frac{1}{1 + e^{-k(P_{i,j}-T_{i,j})}})
l+=−log(1+e−k(Pi,j−Ti,j)1)
l
−
=
−
l
o
g
(
1
−
1
1
+
e
−
k
(
P
i
,
j
−
T
i
,
j
)
)
l_- = -log(1-\frac{1}{1 + e^{-k(P_{i,j}-T_{i,j})}})
l−=−log(1−1+e−k(Pi,j−Ti,j)1)
对输入
x
x
x 求偏导则会得到:
δ
l
+
δ
x
=
−
k
f
(
x
)
e
−
k
x
\frac{\delta{l_+}}{\delta{x}} = -kf(x)e^{-kx}
δxδl+=−kf(x)e−kx
δ
l
−
δ
x
=
−
k
f
(
x
)
\frac{\delta{l_-}}{\delta{x}} = -kf(x)
δxδl−=−kf(x)
可以发现,增强因子会放大错误预测的梯度,从而优化模型得到更好的结果。图3(b) 中,
x
<
0
x<0
x<0 的部分为正样本预测为负样本的情况,可以看到,增益因子k将梯度进行了放大;而 图3(c) 中
x
>
0
x>0
x>0 的部分为负样本预测为正样本时,梯度同样也被放大了。

图3:DB算法示意图
DB算法整体结构如下图所示:
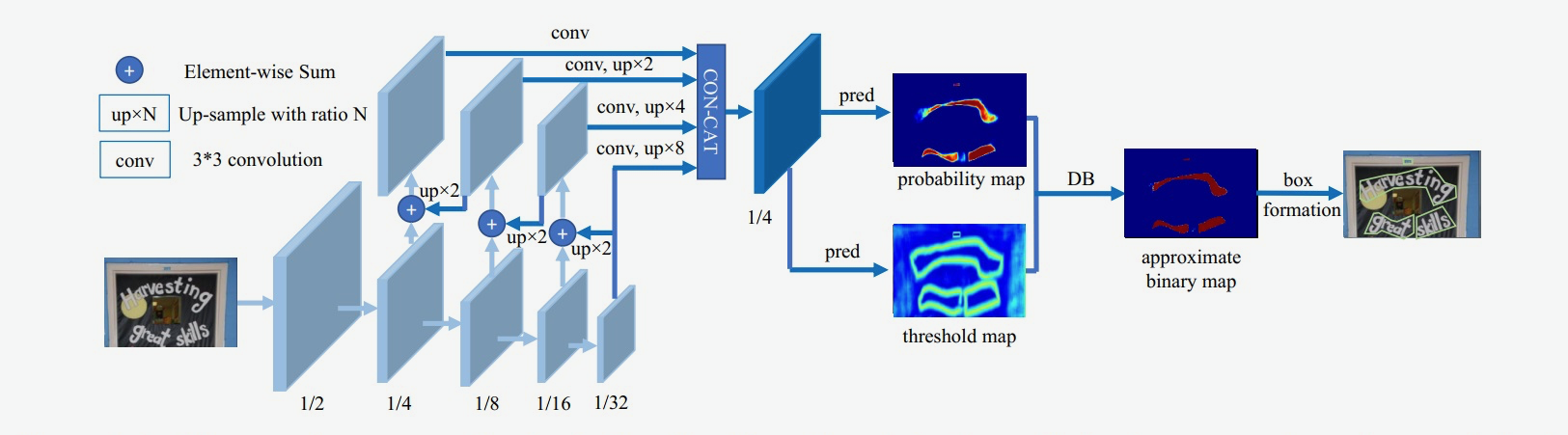
图2 DB模型网络结构示意图
输入的图像经过网络Backbone和FPN提取特征,提取后的特征级联在一起,得到原图四分之一大小的特征,然后利用卷积层分别得到文本区域预测概率图和阈值图,进而通过DB的后处理得到文本包围曲线。
1.2 DB文本检测模型构建
DB文本检测模型可以分为三个部分:
- Backbone网络,负责提取图像的特征
- FPN网络,特征金字塔结构增强特征
- Head网络,计算文本区域概率图
本节使用PaddlePaddle分别实现上述三个网络模块,并完成完整的网络构建。
backbone网络
DB文本检测网络的Backbone部分采用的是图像分类网络,论文中使用了ResNet,本节实验中,为了加快训练速度,采用MobileNetV3 large结构作为backbone。
Backbone用于提取图像的多尺度特征,如下代码所示,假设输入的形状为[640, 640],backbone网络的输出有四个特征,其形状分别是 [1, 16, 160, 160],[1, 24, 80, 80], [1, 56, 40, 40],[1, 480, 20, 20]。 这些特征将输入给特征金字塔FPN网络进一步的增强特征。
FPN网络
特征金字塔结构FPN是一种卷积网络来高效提取图片中各维度特征的常用方法。
FPN网络的输入为Backbone部分的输出,输出特征图的高度和宽度为原图的四分之一。假设输入图像的形状为[1, 3, 640, 640],FPN输出特征的高度和宽度为[160, 160]
Head网络
计算文本区域概率图,文本区域阈值图以及文本区域二值图。
DB Head网络会在FPN特征的基础上作上采样,将FPN特征由原图的四分之一大小映射到原图大小。
2 训练DB文字检测模型
PaddleOCR提供DB文本检测算法,支持MobileNetV3、ResNet50_vd两种骨干网络,可以根据需要选择相应的配置文件,启动训练。
本节以icdar15数据集、MobileNetV3作为骨干网络的DB检测模型(即超轻量模型使用的配置)为例,介绍如何完成PaddleOCR中文字检测模型的训练、评估与测试。
2.1 数据准备
本次实验选取了场景文本检测和识别(Scene Text Detection and Recognition)任务最知名和常用的数据集ICDAR2015。icdar2015数据集的示意图如下图所示:

图 icdar2015数据集示意图
该项目中已经下载了icdar2015数据集,存放在 /home/aistudio/data/data96799 中,可以运行如下指令完成数据集解压,或者从链接中自行下载。
~/train_data/icdar2015/text_localization 有两个文件夹和两个文件,分别是:
~/train_data/icdar2015/text_localization
└─ icdar_c4_train_imgs/ icdar数据集的训练数据
└─ ch4_test_images/ icdar数据集的测试数据
└─ train_icdar2015_label.txt icdar数据集的训练标注
└─ test_icdar2015_label.txt icdar数据集的测试标注
提供的标注文件格式为:
" 图像文件名 json.dumps编码的图像标注信息"
ch4_test_images/img_61.jpg [{"transcription": "MASA", "points": [[310, 104], [416, 141], [418, 216], [312, 179]], ...}]
json.dumps编码前的图像标注信息是包含多个字典的list,字典中的points表示文本框的四个点的坐标(x, y),从左上角的点开始顺时针排列。 transcription中的字段表示当前文本框的文字,在文本检测任务中并不需要这个信息。 如果您想在其他数据集上训练PaddleOCR,可以按照上述形式构建标注文件。
如果"transcription"字段的文字为’*‘或者’###‘,表示对应的标注可以被忽略掉,因此,如果没有文字标签,可以将transcription字段设置为空字符串。
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)