create table userbehavior_partitioned2(
user_id string,
item_id string,
category_id string,
behavior_type string
)
partitioned by (time string)
insert into userbehavior_partitioned2 partition(time)
select user_id,item_id,category_id,behavior_type,
from_unixtime(cast(time as bigint),'yyyy-MM-dd HH:mm:ss')time
from userbehavior;
上面的sql是创建分区表userbehavior_partitioned2,并从userbehavior
中select数据插入分区表中
执行代码之前先开启动态分区非严格模式
set hive.exec.dynamic.partition.mode=nonstrict;
再加一条命令
set hive.optimize.sort.dynamic.partition=true;
充分利用动态分区 job数能变少哦
执行上面sql
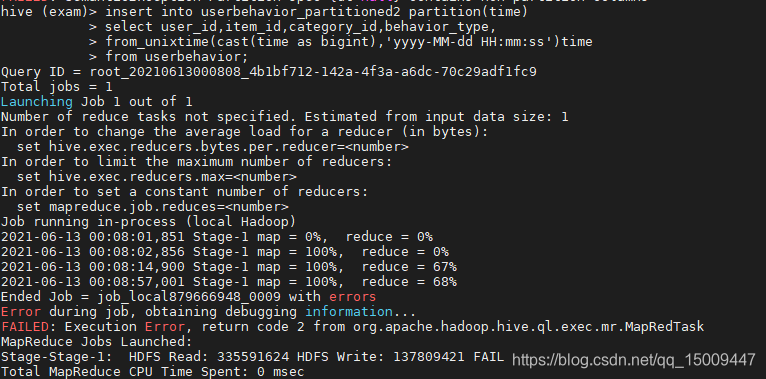
报错…
期间花了很长时间看了网上的很多资料,方法很多,但是治不了我这个报错,
但是后来有提示去看日志,于是去找日志
在hive目录下有logs 进去查看
看到了如下的具体错误信息
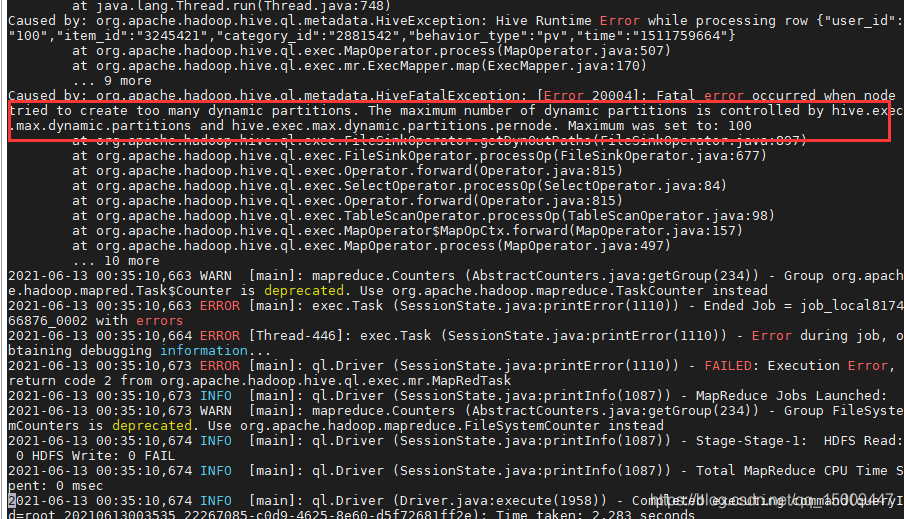
然后果断去hive那边
set hive.exec.max.dynamic.partitions.pernode=20000
set hive.exec.max.dynamic.partitions=20000
以为找到原因了 还是没用。
但是已经能知道点意思了,开始考虑… 意思是允许的最大分区不够,但是设置了那么大了还是不行,再去看看sql,发现分区的字段好像有点问题,from_unixtime(cast(time as bigint),‘yyyy-MM-dd HH:mm:ss’)time
这个分区字段到了时分秒了,那肯定不行了啊,有十万条数据就有十万个分区啊,肯定不行啊 分区是以天为单位,不就一下少了很多吗,改
create table userbehavior_partitioned2(
user_id string,
item_id string,
category_id string,
behavior_type string,
time string
)
partitioned by (dt string)
insert into userbehavior_partitioned2 partition(dt)
select user_id,item_id,category_id,behavior_type,
from_unixtime(cast(time as bigint),'yyyy-MM-dd HH:mm:ss')time,
from_unixtime(cast(time as bigint),'yyyy-MM-dd')dt
from userbehavior;
from_unixtime(cast(time as bigint),‘yyyy-MM-dd’)dt,以这个为分区 就ok了
再次执行 成功
总结:
很多错误表面提示是一样的,但是很多问题是各有各的原因的,最好的解决办法是去找日志,找到根本原因,再去解决。