句向量(Sentence Embeddings)模型在多模态人工智能领域起着至关重要的作用,它通过将句子编码为固定长度的向量表示,将语义信息转化为机器可以处理的形式,在 文本分类、信息检索和相似度计算 等多个方面有着广泛应用。
然而长期以来,句向量模型在训练过程中 一直面临两大挑战:对大量数据和计算资源的依赖。传统的句向量模型,比如 Sentence-BERT 和 Sentence-T5,通常需要数十亿级别的句子对进行训练。这不仅训练成本高,还有点不环保。
为了解决这些问题,本文将深入探讨一种全新的句向量模型—— Jina Embeddings。该模型采用创新性地数据预处理、加权采样和三元组训练策略,大幅减少了训练数据需求,同时达到了与当前顶尖模型相当的性能表现。
与之前的模型相比, Jina AI 新近发布的 Jina Embeddings 在训练数据减少 80% 的情况下,性能表现依然和当前顶尖模型肩并肩。 无论是用于文本检索、排序、语义相似度,还是当下最热门的检索增强生成(Retrieval Augmented Generation,RAG),它的表现都让人印象深刻。
模型: https://huggingface.co/jinaai/jina-embedding-t-en-v1
本文,我们将详细介绍 Jina Embeddings 模型是如何解决这一困扰行业的训练问题的。
数据预处理
传统的大数据思维往往是“越多越好”,使得许多用于训练句向量模型的数据集会包含重复项、非英语样本和语义相似度最小的低质量对。
在 Jina Embeddings 的训练过程中,我们对原始数据集进行了严格地过滤和优化。
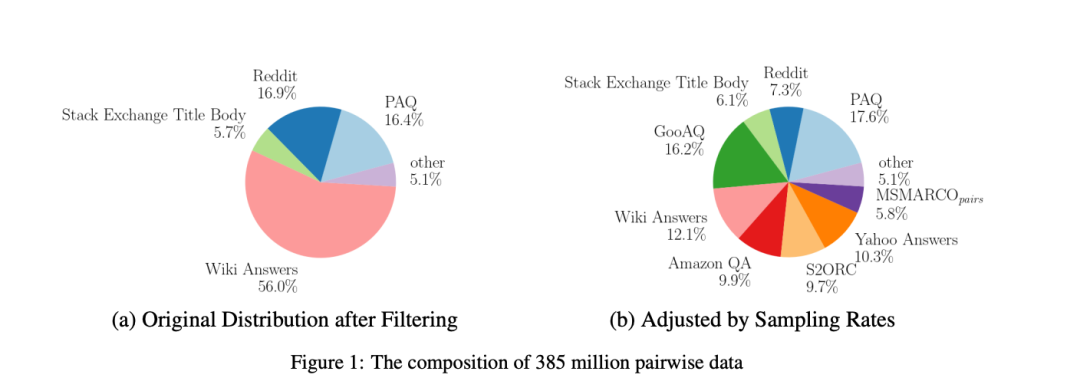
具体来说,我们从原始的 16 亿个句子对中,筛选出了 3.85 亿个高质量样本。 并且实施了一个分阶段的数据清洗流程,包括去重处理、语言过滤和一致性过滤。
语言过滤 :仅保留英语句子对,以便在特定文化和语言环境中达到更高的准确率。
一致性过滤 :利用辅助模型,排除了向量相似度低的句子对,这一步骤排除了 84% 的低质量数据,如 Reddit 的评论数据。
模型预训练
挑选出了好的数据,接着还要巧妙地选择用哪些数据来训练我们的模型。因此,我们 采用了并行化方法在多个数据集上进行训练 ,但设计了一个约束条件:每个训练批次(batch)仅包含来自单一数据集的样本。这样做既可以加速训练,又确保每个数据集都能得到合适的关注。
因为不是所有数据集都一样重要或者一样大。所以,我们 根据数据集的大小和质量来进行了加权 ,以决定从中抽取多少数据用于训练。这避免了在小的数据集上过拟合,同时也确保了重要的、高质量的数据集能得到足够的关注。
通过这种精打细算的训练策略,我们 实际上只用了 3.8 亿对数据就达到了不错的训练效果 ,用相对低的计算成本下实现了非常高效的模型训练。
三元组训练
在句子对数据进行预训练后,我们进一步采用了一个三元组训练阶段。在这一阶段里,每个样本包括一个查询、一个正样本和一个负样本。
模型在这一阶段会学习:如何让查询语句在向量空间里更加靠近正样本,而远离负样本。此外,我们还引入了难负样本(Hard Negatives),来增强模型的判别能力。
同时,我们也观察到 很多句向量模型难以准确处理否定词 。比如 “一对情侣手牵手地走在街上。”,“一对情侣正在一起走。” 和 “一对情侣没有一起走。” 前两个应该关系紧密,而第二个和第三个句子,由于含义相反,应该距离较远。
然而,使用 MiniLM-L6-v2 模型时, 前两个句子的余弦相似度 0.7,而后两个句子的相似度为 0.86,这是不应发生的现象。
因此,我们决定 构建自己的反义数据集 ,就像上面的例子那样,每组数据都有三个部分:一个“锚点”(主句子)、一个“隐含”(和主句子意思相似的句子)和一个“否定”(和主句子意思相反的句子),并将其纳入训练数据中,帮助模型识别和区分语义不一致的表达。
在三元组训练后,我们的 jina-large-v1 模型在 处理复杂否定语句的准确率从 16.6% 提高到了 65.4%。
性能评估
我们在 MTEB 和 BEIR 等权威的数据集上,将我们的 Jina Embeddings 与 Sentence-T5 等模型市面流行句向量模型进行了基准测试, Jina Embeddings 在不同任务和模型规模下都展示了强劲的竞争力。
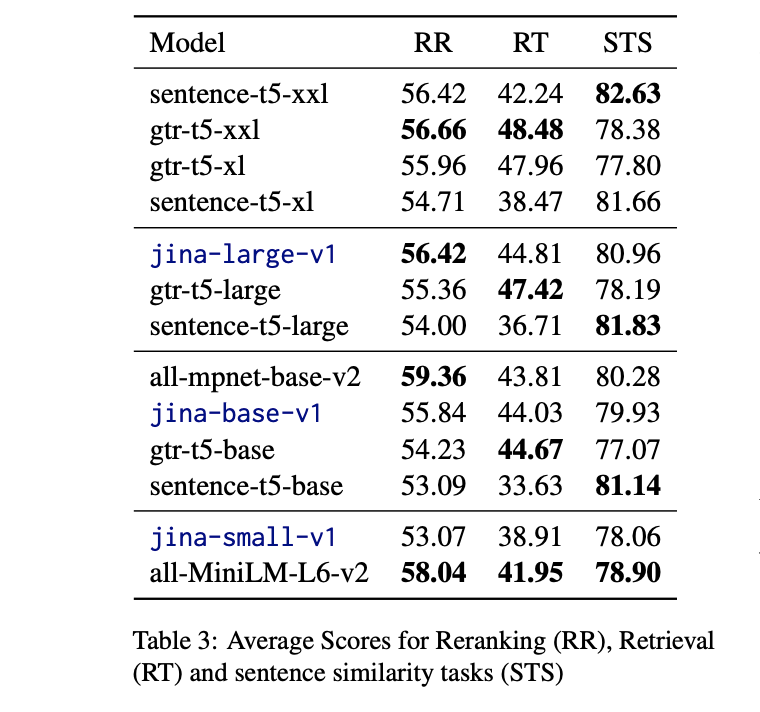
在重新排序任务上, Jina Embeddings 系列模型,特别是“jina-large-v1”和“jina-base-v1”模型,表现出了抢眼的竞争力,超越或等于“gtr-t5-large”和“sentence-t5-xxl”等当前顶尖模型。
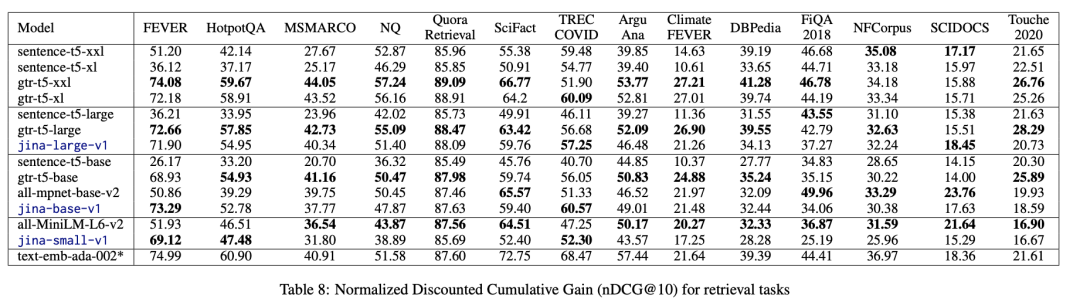
在检索任务表现上,专门为检索任务训练的 gtr-t5 模型成绩最好,但 Jina Embeddings 系列模型也很接近。
在文本相似度任务上,Jina-large-v1 的分数为 80.96,略低于专门用于句子相似度任务的 Sentence-t5-xxl 的 82.63。
这进一步证实了 Jina Embeddings 系列模型在多任务性能上的优越性 ,也突出了专门用于训练特定任务的模型,如 sentence-t5 和 gtr-t5 的局限性。
需要强调的是,Jina Embedding 系列模型在训练时对数据和计算资源的需求相对低许多,但仍能达到与顶级模型相当的性能。这一点对于那些资源有限,但又希望得到高性能模型的用户来说,是一个巨大的优势。
其中最值得一提的是,参数量仅有 1.1 亿的 jina-base-v1 模型,在许多检索和排序任务中,性能甚至超越了拥有 3.3 亿参数的 Sentence-t5-large 模型,与 10 亿参数规模的模型旗鼓相当。 同时,即便只有 3500 万参数的 jina-small-v1 模型,也有非常出色的表现。这也印证了我们训练策略:高效的数据利用与训练方法能挖掘出更为精巧却强大的模型潜能。
展望未来
本文介绍了 Jina Embeddings 系列模型的训练过程,并通过 MTEB 基准的广泛评估证明了其在多任务性能上的优越性。即使只使用了两成数据,仍然达到满血的模型性能。 这一发现挑战了现有的范式,证明了用更少的数据就能有效地训练大型语言模型。
我们的研究也揭示了高效数据使用的多方面好处:
资源节约 :更少的数据需求,从而降低了训练所需的计算基础设施和资源压力。
提高可访问性 :更少的计算需求,使得资源受限的组织也能训练高性能模型。
负责任 AI :更小但同样可靠的模型,意味着我们正在朝着更可持续、更负责任的 AI 发展。
目前,我们已经发布了多个预训练好的 Jina Embeddings 模型,包括 jina-embedding-t/s/b/l-en-v1 等。这些模型参数规模范围从 1400 万到 3.3 亿不等,大家可根据实际需求进行选择。其中 Tiny 的参数量是 1400 万,是目前全世界最小的向量模型 。经实验评估,Jina Embedding 开源模型在关键的 9 个指标上超越了 OpenAI 的 text-embedding-ada-002,在 CPU 上的推理速度比之前最快的模型提高了一倍,每秒可以编码 1700 个句子,适合部署在边缘设备。
模型 : https://huggingface.co/jinaai/jina-embedding-t-en-v1
技术报告 : https://arxiv.org/abs/2307.11224
未来,我们还将推出 Jina Embeddings V2,把向量模型的序列长度拓展到 8 千,并进一步改善向量质量。在 v2 的基础上我们也会将模型拓展到多语言,包括但不限于中文、德文、西班牙文等。