1.HTTP/HTTPS
⑴概述
HTTP协议(HyperText Transfer Protocol,超文本传输协议)是因特网上应用最为广泛的一种网络传输协议
⑵HTTP工作过程
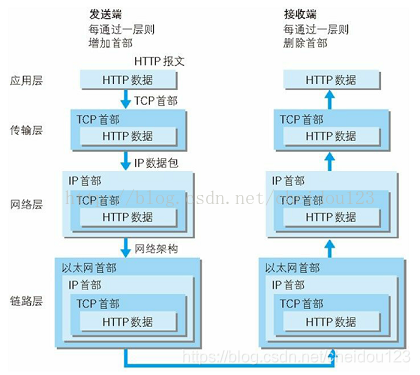
⑶HTTP特点
- 无状态,但是很多业务都需要对通信状态进行保存,于是我们引入了 Cookie 技术
- 使用 Cookie 的状态管理,Cookie 会根据从服务器端发送的响应报文内的一个叫做 Set-Cookie 的首部字段信息,通知客户端保存Cookie。
- 长连接 HTTP/1.1 和部分 HTTP/1.0 想出了持久连接的方法,只要任意一端没有明确提出断开连接,则保持 TCP 连接状态。在 HTTP/1.1 中,所有的连接默认都是持久连接
- 管线化 能做到同时并行发送多个请求
⑷发展过程
①HTTP0.9
- 仅支持GET
- 相应仅支持超文本,响应后马上结束的连接
- 没有 HTTP headers (无法传输其他内容类型的文件), 没有 status/error 代码, 没有 URLs, 没有版本控制
②HTTP1.0
- 支持的方法:GET HESD POST
- 响应:不再只限于超文本 (Content-Type 头部提供了传输 HTML 之外文件的能力 — 如脚本、样式或媒体文件)
- 提供了对请求和响应都包含丰富元数据的 header 域 (HTTP 版本号、status code 和 content type)
- HTTP1.0默认是短连接
③HTTP1.1(当前普遍使用的版本)
- 支持的方法: GET , HEAD , POST , PUT , DELETE , TRACE , OPTIONS
- 默认值长连接
- 进行了重大的性能优化和特性增强,分块传输、压缩/解压等
- 引入更多缓存机制
- 增加了错误状态码
- 在HTTP1.0中认为每台服务器都绑定一个唯一的IP地址,因此,请求消息中的URL并没有传递主机名(hostname)。但随着虚拟主机技术的发展,在一台物理服务器上可以存在多个虚拟主机(Multi-homed Web Servers),并且它们共享一个IP地址。HTTP1.1的请求消息和响应消息都应支持Host头域,且请求消息中如果没有Host头域会报告一个错误(400 Bad Request)
HTTP1.1的缺点:
HTTP 1.1 在应用层以纯文本的形式进行通信。每次通信都要带完整的 HTTP 的头,而且不 考虑 pipeline 模式的话,每次的过程总是像上面描述的那样一去一回。这样在实时性、并 发性上都存在问题。
HTTP1.1的pipeline模式:
桌面浏览器仍然会选择默认关闭HTTP pipelining,只有幂等的请求可以被管线化。
它指定是把多个HTTP请求放到一个TCP连接中一一发送,而在发送过程中不需要等待服务器对前一个请求的响应;只不过,客户端还是要按照发送请求的顺序来接收响应!
如果建立多个TCP连接,会导致资源耗费和性能损失,而且也新建不了多少。
所以HTTP1.1仍旧存在线头阻塞(Head of line blocking)问题。
④SPDY(了解)

2012年由google提出,主要解决:
- 降低延迟,针对HTTP高延迟的问题,SPDY优雅的采取了多路复用(multiplexing)
- 请求优先级(request prioritization)。多路复用带来一个新的问题是,在连接共享的基础之上有可能会导 致关键请求被阻塞。SPDY允许给每个request设置优先级,这样重要的请求就会优先得到响应。比如浏览器加载首页,首页的html内容应该优先展示,之后才是各种静态资源文件,脚本文件等加载,这样可以保证用户能第一时间看到网页内容。
- header压缩。前面提到HTTP1.x的header很多时候都是重复多余的。选择合适的压缩算法可以减小包的大小和数量。
- 基于HTTPS的加密协议传输,大大提高了传输数据的可靠性。
- 服务端推送(server push),采用了SPDY的网页,例如我的网页有一个style.css的请求,在客户端收到style.css数据的同时,服务端会将style.js的文件推送给客户端,当客户端再次尝试获取style.js时就可以直接从缓存中获取到,不用再发请求了。
⑤HTTP2.0
基于SPDY,解决了HTTP1.1的队首阻塞的问题。
二进制分帧层:
应用层和传输层之间加了一层:二进制分帧层。它会将所有传输的信息分割为更小的消息和帧(frame),并对它们采用二进制格式的编码。比起像HTTP/1.x这样的文本协议,二进制协议解析起来更高效,“线上”更紧凑,错误更少。
HTTP2.0 通信在一个连接上完成,这个连接可以承载任意数量的双向数据流。先完成的请求可以先响应。
这样我们可以将N个请求变成N个流,乱序发送到一个TCP连接中。
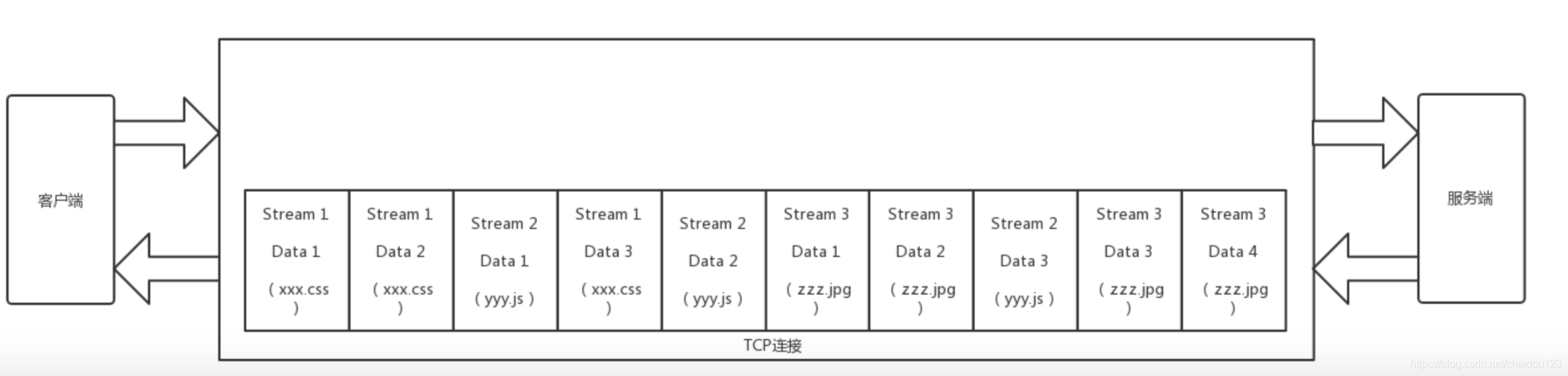
头部压缩
HPACK头部压缩算法,将原来每次都要携带的大量 key value 在两端建立一个索引表,对相同的头只发送索引表中的索引
服务端推送
服务端可以主动将一些资源推送给浏览器的缓存,浏览器需要时就可以直接在缓存中读取了
流优先级
用来告诉对方哪个流更重要
HTTP2.0的缺点
HTTP2.0如果有数据包丢失,就会出现队首阻塞的问题
当其中一个数据包遇到问题,TCP 连接需要等待这个包完成重传之后才能继续进行。
虽然 HTTP 2.0 通过多个 stream,使得逻辑上一个 TCP 连接上的并行内容,进行多路数据的传 输,然而这中间并没有关联的数据。一前一后,前面 stream 2 的帧没有收到,后面 stream 1 的帧也会因此阻塞。
⑤QUIC(了解)
QUIC 协议通过基于 UDP 自定义的类似 TCP 的连接、重试、多路复用、流量控制技术, 进一步提升性能。
⑥HTTPS
概述
HTTP是明文传输的,HTTPS在HTTP的基础上添加了SSL(安全套接字层)层来保证传输数据的安全问题

CA证书
CA证书是由一个权威的CA证书中心颁发的,我们首先来看一个简化的加密流程,对于每个访问XX的用户,生成的对称密钥B理论上来说都是不一样的。比如小明、小王、小光,可能生成的就是B1、B2、B3.
- 小明访问XX,XX将自己的证书给到小明(其实是给到浏览器,小明不会有感知)
- 浏览器从证书中拿到XX的公钥A
- 浏览器生成一个只有自己自己的对称密钥B,用公钥A加密,并传给XX(其实是有协商的过程,这里为了便于理解先简化)
- XX通过私钥解密,拿到对称密钥B
- 浏览器、XX 之后的数据通信,都用密钥B进行加密
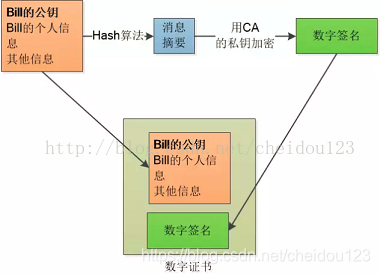
注:这里的Bill是服务器端
如何保证证书不被篡改呢?
数字签名是用来验证数据完整性的,首先将公钥与个人信息用一个Hash算法生成一个消息摘要,Hash算法是不可逆的,且只要内容发生变化,那生成的消息摘要将会截然不同.然后CA再用它的私钥对消息摘要加密,最终形成数字签名.这还不算, 还把原始信息和数据签名合并, 形成一个全新的东西,叫做“数字证书”
当客户端接收到证书时:
- 用同样的Hash算法再次生成一个消息摘要
- 然后用CA的公钥对证书进行解密
- 对比两个消息摘要就能知道数据有没有被篡改过了.
那么CA的公钥又要从哪里来呢?这似乎陷入了一个鸡生蛋,蛋生鸡的悖论,其实CA也有证书来证明自己,而且CA证书的信用体系就像一棵树的结构,上层节点是信用高的CA同时它也会对底层的CA做信用背书,操作系统中已经内置了一些根证书,所以相当于你已经自动信任了它们(需要注意误安装一些非法或不安全的证书).
⑸HTTP报文信息
①报文结构
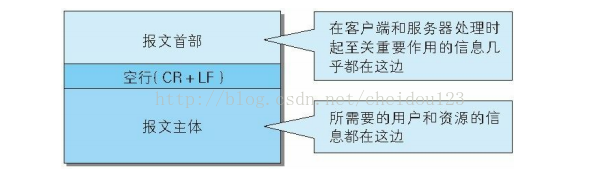
②请求报文
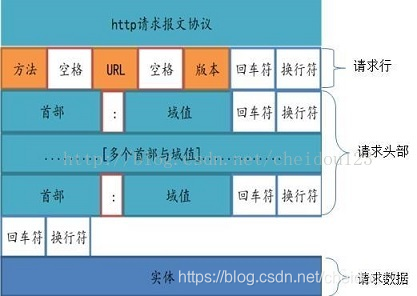
这里只关注几个重要的:
- Cookie: 客户机通过这个头可以向服务器带数据
- Accept: 用于高速服务器,客户机支持的数据类型
- Content-Type: 请求正文的格式
- Cache-control: 可以使用客户端缓存
- If-Modified-Since: 在发送HTTP请求时,把浏览器端缓存页面的最后修改时间一起发到服务器去,服务器会把这个时间与服务器上实际文件的最后修改时间进行比较。
- 如果时间一致,那么返回HTTP状态码304(不返回文件内容),客户端接到之后,就直接把本地缓存文件显示到浏览器中
- 如果时间不一致,就返回HTTP状态码200和新的文件内容,客户端接到之后,会丢弃旧文件,把新文件缓存起来,并显示到浏览器中
⑹响应报文
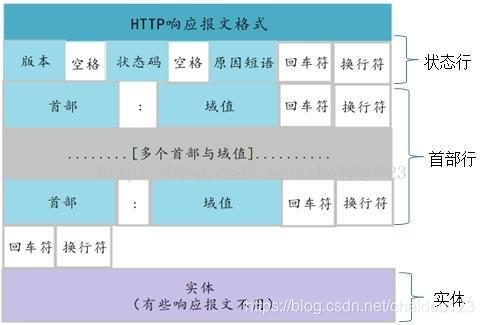
这里只关注几个重要的:
- content-type:服务器通过这个头告诉浏览器回送数据的类型。
- set-cookie: 设置HTTP cookie
⑺状态码
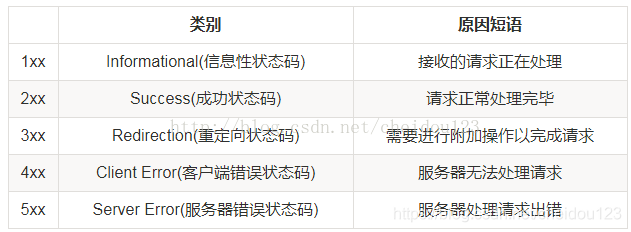
常用的状态码:
- 200 表示从客户端发来的请求在服务器端被正常处理了
- 400 表示请求报文中存在语法错误
- 404 服务器上无法找到请求的资源
- 500 表明服务器端在执行请求时发生了错误。也可能是 Web 应用存在的 bug 或某些临时的故障
2.FTP协议
(File Transfer Protocol)即文件传输协议
当我们下载电影的时候,最简单的方式就是采用HTTP协议,但是这种下载速度太慢。
FTP协议采用两个TCP连接来传输一个文件。
3.P2P协议
HTTP协议和FTP协议都无法克服服务器的带宽问题,所有有个P2P协议。
在P2P协议中,我们即使服务下载者,也是提供者。常见的P2P软件例如BitTorrent,往往我们看到既有下载流量,又有上传流量。
P2P 也是有两种,一种是依赖于 tracker 的,也即元数据集中,文件数据分散;另一种是 基于分布式的哈希算法,元数据和文件数据全部分散。
⑴依赖tracker的协议
.torrent 文件(又叫做种子),里面包括announce(tracker URL)和文件信息。
下载的时候可以根据tracker URL去tracker 服务器拿到其它下载者(包括发布者)的IP,下载者根据种子的文件信息和对方交换没有的数据。而且通过下载块的hash验证码来验证准确性,不准确则重新下载。
一旦 tracker 服务器出现故障或者线路遭到屏蔽,BT 工具就无法正常工作了。
⑵DHT
Distributed Hash Table,有一种著名的 DHT 协议,叫Kademlia 协议:
它相当于一个朋友圈,假如我想买点吃的,我可以在我的朋友圈询问好友,好友然后通过他的朋友圈然后再询问,最终知道哪里有卖。
在一个DHT网络中每个节点都保存了一定的联系方式,但是肯定没有所有的联系方式。
任何一个BitTorrent 启动之后,在.torrent 文件可以找到一个node的列表,这些节点列表里肯定有我们可以联系上的,然后我们通过这个节点接入了一个DHT网络,然后我们计算这个文件的hash值来找到我们下载节点(这个下载节点不是唯一的,因而任意节点加入和离开都不影响整体网络),然后通过可以联系上的不断寻找,找到可以下载的节点。下载完之后我们这里也有了那个文件,最后告诉下载节点我们也有了,以后可以从我们这下载。
4.流媒体协议
⑴帧
每一张图片,我们成为一帧,如果每秒帧够多(FPS),就形成了视频
⑵直播的过程
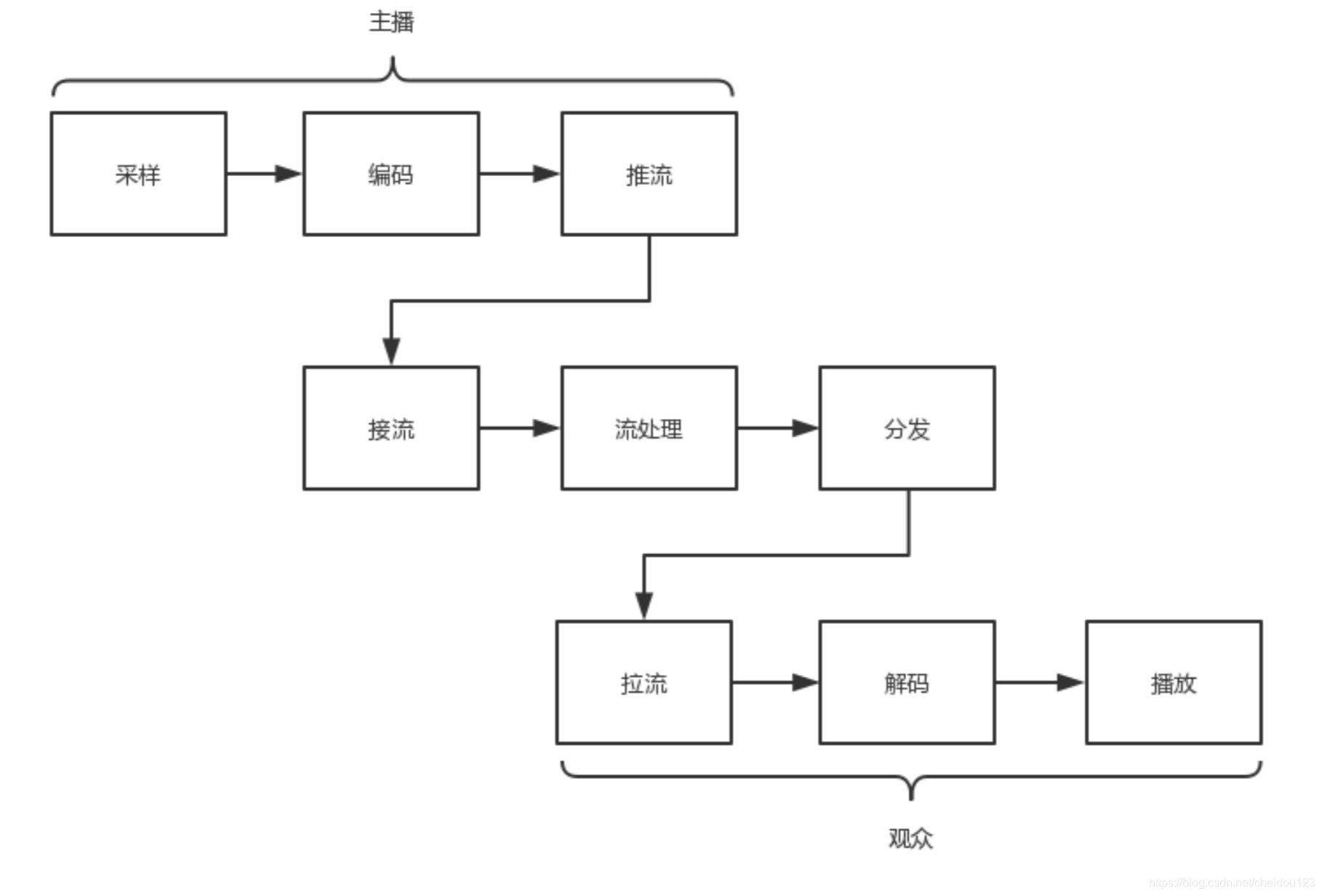
- 编码
编码是一个压缩的过程,取出冗余,降低图像质量等等。
- 推流
从主播端推送到服务器
- 接流
在服务器上有个运行了同样协议的服 务端来接收这些网络包,从而得到里面的视频流,这个过程称为接流
- 流处理
服务端接到视频流之后,可以对视频流进行一定的处理,因为观众使用的客户端千差万别,要保证他们都能看到直播
- 分发
如果有非常多的观众,同时看一个视频直播,那都从一个服务器上拉流,压力太大了,因而 需要一个视频的分发网络,将视频预先加载到就近的边缘节点
- 拉流
观众的客户端请求
- 解码
将二进制变成一帧帧图片
6.ssh协议
Secure Shell,为远程登录会话和其他网络服务提供安全性的协议。SSH使用最多的是远程登录和传输文件,实现此功能的传统协议都不安全(ftp,telnet等),因为它们使用明文传输数据。而SSH在传输过程中的数据是加密的,安全性更高。
7.DNS
⑴概述
DNS服务器是通过域名去查询对应的IP的设备,要设计成分布式高可用的。
⑵DNS服务器分类

- 根 DNS 服务器 :返回顶级域 DNS 服务器的 IP 地址
- 顶级域 DNS 服务器:返回权威 DNS 服务器的 IP 地址
- 权威 DNS 服务器 :返回相应主机的 IP 地址
根DNS服务器和顶级域DNS服务器,不会告诉本地DNS具体IP。而是指向它下级的服务器地址。权威DNS服务器会告诉本地DNS具体的IP地址。什么叫本地DNS呢?一般就是网络服务商的某个机房。
⑶DNS解析流程
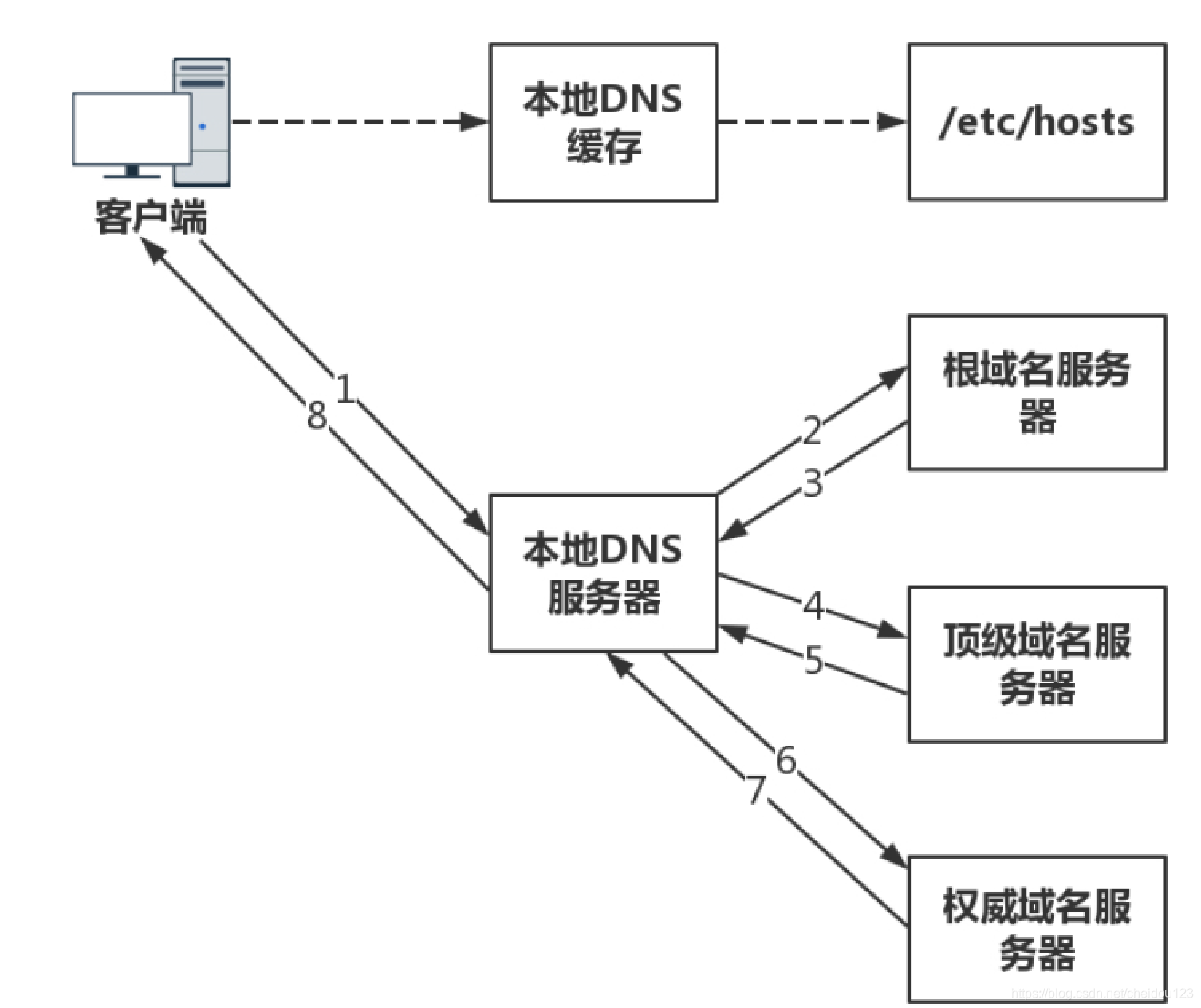
- 客户端先去本地DNS查询
- 本地DNS查询不到就去根域名服务器
- 根域名服务器指向对应的顶级域名服务器
- 顶级域名服务器指向权威DNS服务器
- 权威DNS服务器给本地DNS对应的IP
- 本地DNS将IP返回给客户端,客户端和目标建立连接
⑷负载均衡
- 内部负载均衡
通过域名查询IP地址,IP地址可以配置多个做简单的轮询。
- 全局负载均衡
轮询访问不同地域的多个数据中心,也可以配置就近或者分运营商访问
⑸常用工具
①可以查询DNS解析过程dig。
8.HTTPDNS
⑴DNS存在的问题
- 给A运营商发请求,A外包给了B,DNS服务器以为我们是B的用户,给我的IP是B的,跨运营商访问很慢
- 本地DNS缓存并非最新的,也可能不再是最合适的
- NAT网关会修改IP地址,DNS服务器无法判断运营商
- DNS解析要根DNS到权威DNS,比较慢
⑵HTTPDNS
自己搭建基于HTTP协议的DNS服务,分布多个地点和运营商,使用HTTPDNS的一般是手机用户。
在客户端的缓存是手机应用自己做的,可以在配置如何更新,合适更新,可以直接请求HTTPDNS服务器。不需要本地DNS缓存(本地DNS缓存一般是运营商统一做的)。
⑶HTTPDNS缓存设计
- 同步进行
发现过期直接调用 HTTPDNS 的接口,返回最新的记录,更新缓存,实时性好,但是当多个请求同时发现,浪费资源
- 异步进行
可以将多个请求都发现过期的情况,合并为一个对于 HTTPDNS 的请求任务,只执行一次,减少 HTTPDNS 的压力。同时可以在即将过期的时候,就创建一个任务进行预加载,防止过期之后再刷新,称为预加载。缺点是客户可能请求到过期的数据
⑷HTTPDNS
因为客户端嵌入了SDK,不使用本地DNS缓存,转发等等,不会让权威DNS服务器误会客户端位置和运营商,权威服务器可以通过分析更加精准的提供IP地址
同时客户端可以分析网络请求来查看不同IP的服务质量