使用Python,OpenCV应用EAST文本检测器检测自然场景图像中的文本
这篇博客将介绍如何使用Python,OpenCV应用EAST文本检测器检测自然场景图像和视频流中的文本。
OpenCV的EAST文本检测器是一种深度学习模型,基于一种新颖的体系结构和训练模式。它能够(1)在720p图像上以13 FPS的速度近实时运行,(2)获得最先进的文本检测精度。
《EAST:高效准确的场景文本检测》称该算法为“EAST”,是一种高效、准确的场景文本检测管道。
文本检测器不仅准确,而且能够在720p图像上以大约13 FPS的速度近实时运行。
为了提供OpenCV的EAST文本检测器的实现,需要转换OpenCV的C++示例;然而遇到了许多挑战,如:
- 无法使用OpenCV的NMSBox进行非最大值抑制,而必须使用imutils中的实现。
- 由于缺少RotatedRect的Python绑定,无法计算真正的旋转边界框。
- 尽最大可能使实现尽可能接近OpenCV,但注意:该版本与C++版本并非完全相同,随着时间的推移,可能需要解决一到两个小问题。
1. 效果图
成都玩的照片,检测效果图1如下:
可以看到文本被正确识别,EAST很快,每张照片耗时0.15s左右;

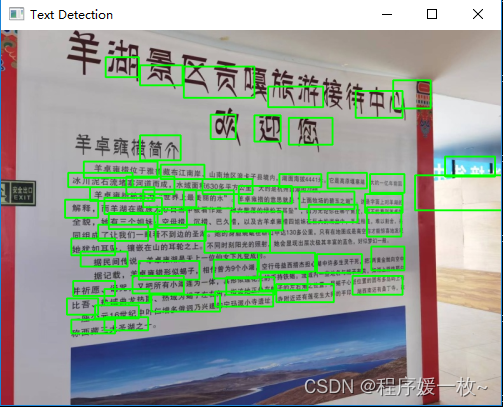
拉萨羊卓雍错湖路上拍的照片,效果图2如下:
可以看到大多数文本被正确识别;
侏罗纪世界电影开头,视频流中检测效果图如下:

2. 原理
opencv >=3.4.2或者4
什么是EAST文本检测器,为什么使用它,以及是什么使该算法如此新颖
在受约束的可控环境中检测文本通常可以通过使用基于启发式的方法来实现,例如利用梯度信息或文本通常分组为段落并且字符出现在直线上的事实。这种基于启发式的文本检测器的示例可以关于检测护照图像中的机器可读区域中看到。
自然场景文本检测是不同的,但更具挑战性。
2.1 为什么自然场景文本检测如此具有挑战性?
- 图像/传感器噪声:手持式相机的传感器噪声通常高于传统扫描仪的噪声。此外,低价相机通常会对原始传感器的像素进行插值,以产生真实的颜色。
- 视角:自然场景文本可以自然地具有与文本不平行的视角,从而使文本更难识别。
- 模糊:不受控制的环境往往会产生模糊。
- 照明条件:不能对自然场景图像中的照明条件做出任何假设。它可能接近黑暗,相机上的闪光灯可能亮着,或者太阳可能明亮地照耀着,使整个图像饱和。
- 分辨率:并非所有相机分辨率一致,可能正在处理分辨率低于标准的相机。
- 非纸张对象:大多数(但不是全部)纸张都不反射(至少在尝试扫描的纸张的上下文中)。自然场景中的文字可能是反射性的,包括徽标、标志等。
非平面物体:考虑瓶子表面上的文字可能是扭曲和变形的。尽管人仍然能够轻松地“检测”和阅读文本,但算法很难处理。
未知布局:不能使用任何先验信息为算法提供文本所在位置的“线索”。
OpenCV的EAST文本检测器实现非常健壮,即使文本模糊、反射或部分模糊,也能够定位文本
2.2 替代EAST文本检测实现
这里使用的EAST文本检测模型是与OpenCV兼容的TensorFlow实现,即可以使用TensorFlow或OpenCV使用该模型进行文本检测预测。也可以使用PyTorch实现。
Tesseract和EasyOCR都具有文本检测(检测文本在输入图像中的位置)和文本识别(OCR文本本身)
使用Python,OpenCV进行Tesseract-OCR绑定及文本检测识别
使用EasyOCR执行文本检测
这两个都使用基于深度学习的模型来执行文本检测和定位。
然而根据项目,可以使用基本的图像处理和计算机视觉技术来执行文本检测。
如使用Python,OpenCV+OCR检测护照图像中的机器可读区域(MRZ Machine-Readable Zones)
使用OpenCV和Python识别数字
https://blog.csdn.net/qq_40985985/article/details/113944141
使用Python,OpenCV进行卡类型及16位卡号数字的OCR
使用Python,OpenCV进行银行支票数字和符号的OCR
虽然传统的计算机视觉和图像处理技术可能没有基于深度学习的文本检测技术那么普遍,但它们在某些情况下可以工作得出奇地好。
3. 源码
3.1 text_detection.py
# text_detection.py 对图像进行文本检测
# text_detection_video 对视频流(实时视频/视频文件)进行文本检测
# frozen_east_text_detection.pb EAST自然场景文本检测序列化的模型
# USAGE
# python text_detection.py --image images/yh.jpg --east frozen_east_text_detection.pb
import argparse
import time
import cv2
import imutils
import numpy as np
# 导入必要的包
from imutils.object_detection import non_max_suppression # 从IMUTIL中导入了NumPy、OpenCV的非最大单位抑制实现
# 构建命令行参数及解析
# --image 输入图像路径
# --east east场景文本检测器模型路径
# --min-confidence 可选 过滤弱检测的置信度值
# --width 可选 缩放图像宽度,必须是32的倍数
# --height 可选 缩放图像高度,必须是32的倍数
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", type=str,
help="path to input image")
ap.add_argument("-east", "--east", type=str,
help="path to input EAST text detector")
ap.add_argument("-c", "--min-confidence", type=float, default=0.5,
help="minimum probability required to inspect a region")
ap.add_argument("-w", "--width", type=int, default=320,
help="resized image width (should be multiple of 32)")
ap.add_argument("-e", "--height", type=int, default=320,
help="resized image height (should be multiple of 32)")
args = vars(ap.parse_args())
# 加载图像获取维度
image = cv2.imread(args["image"])
orig = image.copy()
(H, W) = image.shape[:2]
# 计算宽度,高度及分别的比率值
(newW, newH) = (args["width"], args["height"])
rW = W / float(newW)
rH = H / float(newH)
# 缩放图像获取新维度
image = cv2.resize(image, (newW, newH))
(H, W) = image.shape[:2]
# 为了使用OpenCV和EAST深度学习模型执行文本检测,需要提取两层的输出特征图:
# 定义EAST探测器模型的两个输出层名称,感兴趣的是——第一层输出可能性,第二层用于提取文本边界框坐标
# 第一层是输出sigmoid激活,提供了一个区域是否包含文本的概率。
# 第二层是表示图像“几何体”的输出特征映射-将能够使用该几何体来推导输入图像中文本的边界框坐标
layerNames = [
"feature_fusion/Conv_7/Sigmoid",
"feature_fusion/concat_3"]
# cv2.dnn.readNet加载预训练的EAST text detector
print("[INFO] loading EAST text detector...")
net = cv2.dnn.readNet(args["east"])
# 从图像构建一个blob,然后执行预测以获取俩层输出结果
# 将图像转换为blob来准备图像
blob = cv2.dnn.blobFromImage(image, 1.0, (W, H),
(123.68, 116.78, 103.94), swapRB=True, crop=False)
start = time.time()
# 通过将层名称作为参数提供给网络以指示OpenCV返回感兴趣的两个特征图:
# 分数图,包含给定区域包含文本的概率
# 几何图:输入图像中文本的边界框坐标的输出几何图
net.setInput(blob)
(scores, geometry) = net.forward(layerNames)
end = time.time()
# 展示文本预测耗时信息
print("[INFO] text detection took {:.6f} seconds".format(end - start))
# 从分数卷中获取行数和列数,然后初始化边界框矩形集和对应的信心分数
(numRows, numCols) = scores.shape[2:4]
rects = []
confidences = []
# 两个嵌套for循环用于在分数和几何体体积上循环,这将是一个很好的例子,说明可以利用Cython显著加快管道操作。
# 我已经用OpenCV和Python演示了Cython在快速、优化的“for”像素循环中的强大功能。
# 遍历预测结果
for y in range(0, numRows):
# 提取分数(概率),然后是环绕文字的几何(用于推导潜在边界框坐标的数据)
scoresData = scores[0, 0, y]
xData0 = geometry[0, 0, y]
xData1 = geometry[0, 1, y]
xData2 = geometry[0, 2, y]
xData3 = geometry[0, 3, y]
anglesData = geometry[0, 4, y]
# 遍历列
for x in range(0, numCols):
# 过滤弱检测
if scoresData[x] < args["min_confidence"]:
continue
# 计算偏移因子,因为得到的特征图将比输入图像小4倍
(offsetX, offsetY) = (x * 4.0, y * 4.0)
# 提取用于预测的旋转角度,然后计算正弦和余弦
angle = anglesData[x]
cos = np.cos(angle)
sin = np.sin(angle)
# 使用几何体体积导出边界框
h = xData0[x] + xData2[x]
w = xData1[x] + xData3[x]
# 计算文本边界框的开始,结束x,y坐标
endX = int(offsetX + (cos * xData1[x]) + (sin * xData2[x]))
endY = int(offsetY - (sin * xData1[x]) + (cos * xData2[x]))
startX = int(endX - w)
startY = int(endY - h)
# 将边界框坐标和概率分数添加到各自的列表
rects.append((startX, startY, endX, endY))
confidences.append(scoresData[x])
# 对边界框应用非最大值抑制(non-maxima suppression),以抑制弱重叠边界框,然后显示结果文本预测
# apply overlapping to suppress weak, overlapping bounding boxes
boxes = non_max_suppression(np.array(rects), probs=confidences)
# 遍历边界框
for i, (startX, startY, endX, endY) in enumerate(boxes):
# 根据相对比率缩放边界框坐标
startX = int(startX * rW)
startY = int(startY * rH)
endX = int(endX * rW)
endY = int(endY * rH)
# cv2.putText(orig, str(confidences[i]), (startX, startY - 10),
# cv2.FONT_HERSHEY_SIMPLEX, 0.45, (0, 0, 255), 2)
# 在图像上绘制边界框
cv2.rectangle(orig, (startX, startY), (endX, endY), (0, 255, 0), 2)
# 展示输出图像
cv2.imshow("Text Detection", imutils.resize(orig,width=500))
cv2.waitKey(0)
3.2 text_detection_video.py
# text_detection.py 对图像进行文本检测
# text_detection_video 对视频流(实时视频/视频文件)进行文本检测
# frozen_east_text_detection.pb EAST自然场景文本检测序列化的模型
# USAGE
# python text_detection_video.py --east frozen_east_text_detection.pb
# python text_detection_video.py --east frozen_east_text_detection.pb --video images/jurassic_park_trailer.mp4
import argparse
import time
import cv2
import imutils
import numpy as np
from imutils.object_detection import non_max_suppression # 从IMUTIL中导入了NumPy、OpenCV的非最大单位抑制实现
from imutils.video import FPS
# 导入必要的包
from imutils.video import VideoStream # 使用VideoStream访问网络摄像机和FPS,以对该脚本每秒的帧进行基准测试
# 定义一个新函数来解码预测函数-它将被重新用于每个帧,并使循环代码更简洁
def decode_predictions(scores, geometry):
# 获取分数集中的行列,初始化边界框坐标和分数list
(numRows, numCols) = scores.shape[2:4]
rects = []
confidences = []
# 遍历行
for y in range(0, numRows):
# 提取分数,潜在的包围文本的边界框坐标
scoresData = scores[0, 0, y]
xData0 = geometry[0, 0, y]
xData1 = geometry[0, 1, y]
xData2 = geometry[0, 2, y]
xData3 = geometry[0, 3, y]
anglesData = geometry[0, 4, y]
# 遍历列
for x in range(0, numCols):
# 过滤弱检测
if scoresData[x] < args["min_confidence"]:
continue
# 计算偏移量因子,由于结果特征图比原始图像小4倍
(offsetX, offsetY) = (x * 4.0, y * 4.0)
# 提取预测结果的旋转角度,和正弦余弦函数
angle = anglesData[x]
cos = np.cos(angle)
sin = np.sin(angle)
# 使用几何体计算边界框的宽高
h = xData0[x] + xData2[x]
w = xData1[x] + xData3[x]
# 计算文本边界框的开始,结束坐标
endX = int(offsetX + (cos * xData1[x]) + (sin * xData2[x]))
endY = int(offsetY - (sin * xData1[x]) + (cos * xData2[x]))
startX = int(endX - w)
startY = int(endY - h)
# 添加边界框坐标和相应的分数到list中
rects.append((startX, startY, endX, endY))
confidences.append(scoresData[x])
# 返回一系列边界框坐标和对应的分数
return (rects, confidences)
# 构建命令行参数及解析
# --video 可选的,输入视频文件路径
# --east east场景文本检测器模型路径
# --min-confidence 可选 过滤弱检测的置信度值
# --width 可选 缩放图像宽度,必须是32的倍数
# --height 可选 缩放图像高度,必须是32的倍数
ap = argparse.ArgumentParser()
ap.add_argument("-v", "--video", type=str,
help="path to optinal input video file")
ap.add_argument("-east", "--east", type=str,
help="path to input EAST text detector")
ap.add_argument("-c", "--min-confidence", type=float, default=0.5,
help="minimum probability required to inspect a region")
ap.add_argument("-w", "--width", type=int, default=320,
help="resized image width (should be multiple of 32)")
ap.add_argument("-e", "--height", type=int, default=320,
help="resized image height (should be multiple of 32)")
args = vars(ap.parse_args())
# 初始化原始帧的维度,新维度及比率
(W, H) = (None, None)
(newW, newH) = (args["width"], args["height"])
(rW, rH) = (None, None)
# 为了使用OpenCV和EAST深度学习模型执行文本检测,需要提取两层的输出特征图:
# 定义EAST探测器模型的两个输出层名称,感兴趣的是——第一层输出可能性,第二层用于提取文本边界框坐标
# 第一层是输出sigmoid激活,提供了一个区域是否包含文本的概率。
# 第二层是表示图像“几何体”的输出特征映射-将能够使用该几何体来推导输入图像中文本的边界框坐标
layerNames = [
"feature_fusion/Conv_7/Sigmoid",
"feature_fusion/concat_3"]
# cv2.dnn.readNet加载预训练的EAST text detector
print("[INFO] loading EAST text detector...")
net = cv2.dnn.readNet(args["east"])
# 如果未提供视频文件,则获取摄像头指针
if not args.get("video", False):
print("[INFO] starting video stream...")
vs = VideoStream(src=0).start()
time.sleep(1.0)
# 否则,获取文件指针
else:
vs = cv2.VideoCapture(args["video"])
# 开始帧吞吐量计数器
fps = FPS().start()
num = 0
# 遍历视频流的帧
while True:
# 获取当前帧,兼容 VideoStream or VideoCapture对象
frame = vs.read()
frame = frame[1] if args.get("video", False) else frame
# 检查是否到达文件末尾
if frame is None:
break
# 保持比率的缩放帧
frame = imutils.resize(frame, width=1000)
orig = frame.copy()
# 如果宽度,高度为None,则计算原始帧到新帧的比率
if W is None or H is None:
(H, W) = frame.shape[:2]
rW = W / float(newW)
rH = H / float(newH)
# 缩放帧,忽略比率
frame = cv2.resize(frame, (newW, newH))
# 从帧构建一个blob,执行net.forward获取俩层输出结果
blob = cv2.dnn.blobFromImage(frame, 1.0, (newW, newH),
(123.68, 116.78, 103.94), swapRB=True, crop=False)
net.setInput(blob)
# 通过将层名称作为参数提供给网络以指示OpenCV返回感兴趣的两个特征图:
# 分数图,包含给定区域包含文本的概率
# 几何图:输入图像中文本的边界框坐标的输出几何图
(scores, geometry) = net.forward(layerNames)
# 解码预测结果,然后应用非最大值抑制以抑制重叠边界框
# 解码预测并应用NMS(non-maxima suppression)
(rects, confidences) = decode_predictions(scores, geometry)
boxes = non_max_suppression(np.array(rects), probs=confidences)
# 遍历边界框
for (startX, startY, endX, endY) in boxes:
# 按相对比率缩放边界框
startX = int(startX * rW)
startY = int(startY * rH)
endX = int(endX * rW)
endY = int(endY * rH)
# cv2.putText(orig, str(confidences[i]), (startX, startY - 10),
# cv2.FONT_HERSHEY_SIMPLEX, 0.45, (0, 0, 255), 2)
# 在帧上绘制边界框
cv2.rectangle(orig, (startX, startY), (endX, endY), (0, 255, 0), 2)
# 更新fps计数器
fps.update()
num = num + 1
cv2.imwrite("imgs/" + str(num) + ".jpg", imutils.resize(orig, width=500))
# 展示输出帧
cv2.imshow("Text Detection", orig)
key = cv2.waitKey(1) & 0xFF
# 按下‘q’键,退出循环
if key == ord("q"):
break
# 停止计数器,展示fps信息
fps.stop()
print("[INFO] elasped time: {:.2f}".format(fps.elapsed()))
print("[INFO] approx. FPS: {:.2f}".format(fps.fps()))
# 如果使用的摄像头流,释放指针
if not args.get("video", False):
vs.stop()
# 否则,释放文件指针
else:
vs.release()
# 关闭所有窗口
cv2.destroyAllWindows()
参考