【论文阅读】Ultrafast Local Outlier Detection from a Data Stream with Stationary Region Skipping
论文来源:SIGKDD 2020
原文地址:https://dl.acm.org/doi/abs/10.1145/3394486.3403171
ABSTRACT
ABSTRACT
从数据流中实时检测异常值是一个越来越重要的问题,尤其是由于物联网的普及和数字孪生的出现,传感器生成的数据流在许多应用程序中比比皆是。已经提出了几种基于密度的方法来解决这个问题,但可以说它们都不够快,无法满足实际应用程序的性能需求。本文基于一项新颖的观察,即在数据空间的许多区域中,数据分布几乎不会跨窗口滑动发生变化。我们提出了一种新算法,STARE,它识别数据分布几乎没有变化的局部区域,然后跳过更新这些区域中的密度——这个概念称为静止区域跳跃。两种技术,数据分布近似和基于累积净变化的跳过(cumulative net-change-based skip),被用来高效和有效地实现这个概念。使用合成和真实数据流的大量实验以及案例研究表明,STARE比现有算法快几个数量级,同时实现相当或更高的精度。
Main Idea
这项工作利用了真实数据流中的一个重要特性,它可以潜在地为异常值检测节省大量工作:数据点被倾斜到数据空间中的多个局部区域,并且数据分布在这些区域中几乎是静止的(即变化不显着)特定时间段内的区域。这种观察在窗口流处理中更为明显,因为窗口通常以窗口大小的一小部分滑动,因此,窗口滑动中的过期或新数据点对整个窗口中的数据分布的影响有限(参见图 1) ).
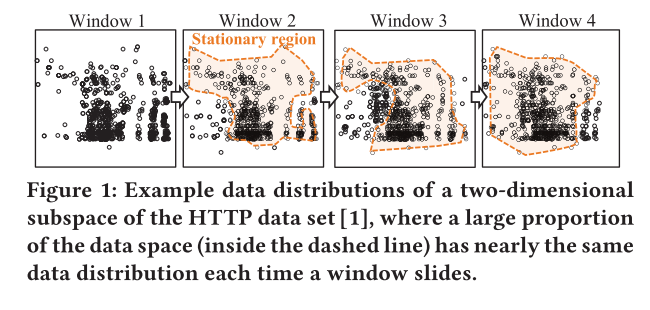
从图中可以看出,随着窗口的滑动,数据的分布有一定的变化,但是整体分布变化不大。利用这一点,本文采取了基于局部密度的方法,找出与其他数据点存在显著不同的数据点标记为异常值。如果点的密度低于其邻居,基于密度的方法能够通过标记数据来有效地找到此类局部异常值,则该点作为异常点,其中数据点的密度由其局部区域的数据分布决定
目前,已经提出了几种基于密度的算法来检测数据流中的局部异常值 [13-16],它们需要估计数据点的密度。现有算法忽略了密度平稳性,每次窗口滑动时都会重复更新窗口中所有数据点的密度;整个数据空间中的这种密度估计会导致二次时间复杂度 [2, 6],这会由于延迟过大而影响及时的异常值检测。我们解决这个问题的关键思想是跳过数据点密度几乎没有变化的局部区域的密度更新,即静止区域。

如上图所示,在前一个窗口(图2a)中有两个离群值
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)