ELK 不是一款软件,而是 Elasticsearch、Logstash 和 Kibana 三种软件产品的首字母缩写。这三者都是开源软件,通常配合使用,而且又先后归于 Elastic.co 公司名下,所以被简称为 ELK Stack。根据 Google Trend 的信息显示,ELK Stack 已经成为目前最流行的集中式日志解决方案。
- Elasticsearch:分布式搜索和分析引擎,具有高可伸缩、高可靠和易管理等特点。基于 Apache Lucene 构建,能对大容量的数据进行接近实时的存储、搜索和分析操作。通常被用作某些应用的基础搜索引擎,使其具有复杂的搜索功能;
- Logstash:数据收集引擎。它支持动态的从各种数据源搜集数据,并对数据进行过滤、分析、丰富、统一格式等操作,然后存储到用户指定的位置;
- Kibana:数据分析和可视化平台。通常与 Elasticsearch 配合使用,对其中数据进行搜索、分析和以统计图表的方式展示;
- Filebeat:ELK 协议栈的新成员,一个轻量级开源日志文件数据搜集器,基于 Logstash-Forwarder 源代码开发,是对它的替代。在需要采集日志数据的 server 上安装 Filebeat,并指定日志目录或日志文件后,Filebeat 就能读取数据,迅速发送到 Logstash 进行解析,亦或直接发送到 Elasticsearch 进行集中式存储和分析。
ELK 3个包的下载地址:https://www.elastic.co/cn/downloads/past-releases
一. 下载elasticsearch-7.3.0
cd /Users/sunww/Documents/soft/ELK
tar -xzvf elasticsearch-7.3.0-darwin-x86_64.tar.gz
cd elasticsearch-7.3.0/
bin/elasticsearch // 启动elasticsearch
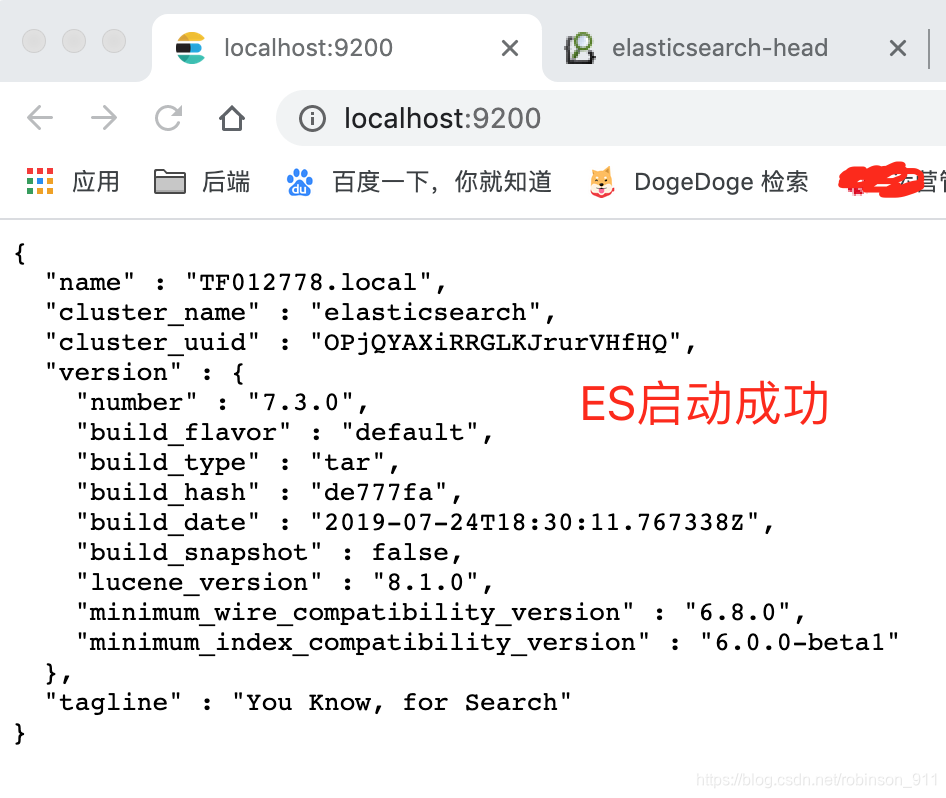
在浏览器中输入 http://localhost:9200/ 可以看到如下内容,则代表ES启动成功:
二. MAC下安装ElasticSearch Head插件
参考我之前的文章 https://blog.csdn.net/robinson_911/article/details/94558309
三. 下载并配置logstash7.3.0
logstash-7.3.0的下载如ElasticSearch的下载
cd /Users/sunww/Documents/soft/ELK
tar -xzvf logstash-7.3.0.tar.gz
cd logstash-7.3.0
bin/logstash -e 'input{stdin{}} output{ stdout {}}' // 等待控制台输入日志,并打印出来
测试下:hello world
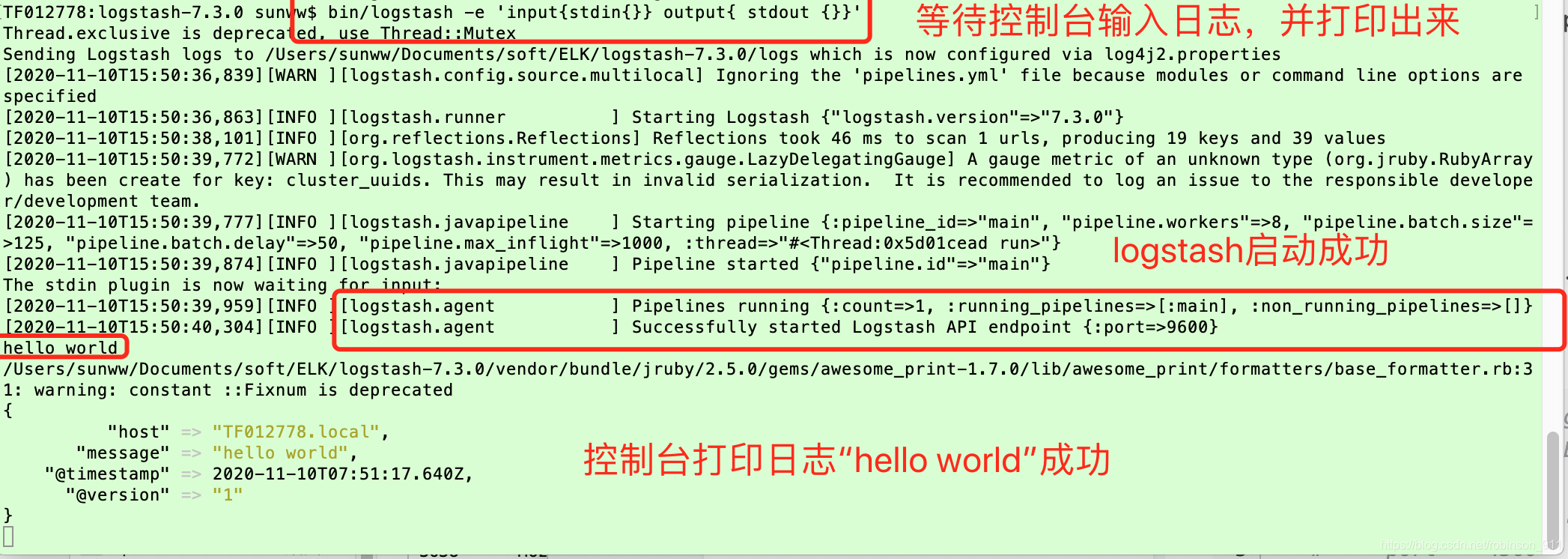
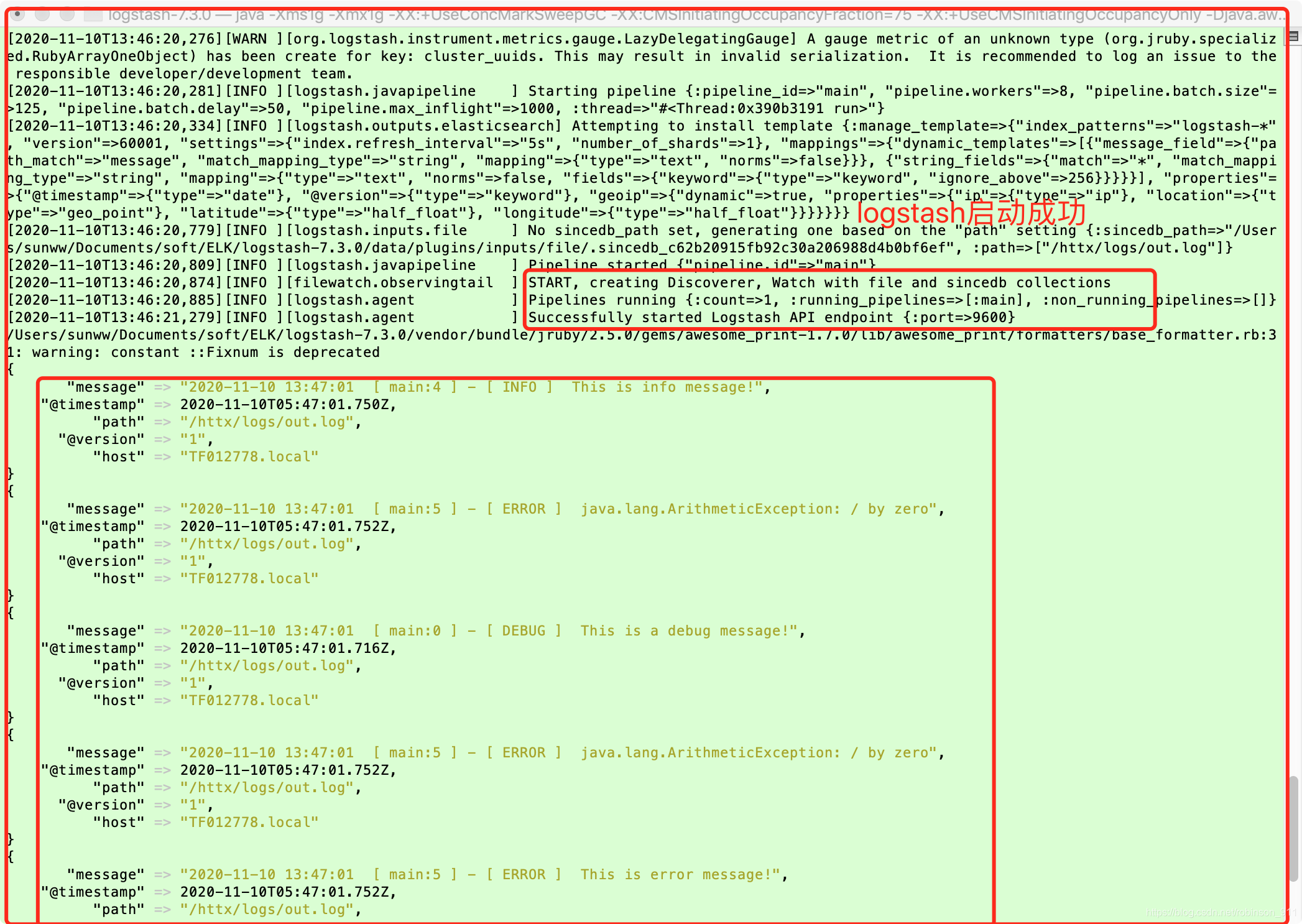
出现上面截图界面的内容的话,代表logstash安装配置成功。
配置输入日志文件地址和ES地址等,如下:
根据配置文件启动logstash
./bin/logstash -f ./config/logstash.conf
logstash.conf 文件内容如下:
# Sample Logstash configuration for creating a simple
# Beats -> Logstash -> Elasticsearch pipeline.
#log4j {
# host => "127.0.0.1"
# port => 4560
# }
input {
file {
# path=>"/Users/sunww/Documents/soft/ELK/logstash-7.3.0/logstash-tutorial.log"
path=>"/httx/logs/out.log" # 日志输入的位置
}
}
output {
# 控制台打印log
stdout{
codec => rubydebug
}
# logstash中的数据分发到ES中去
elasticsearch {
hosts => ["http://localhost:9200"]
#index => "logstashdata"
index => "log4j-%{+YYYY.MM.dd}"
document_type => "log4j_type" #文档类型,便于ES去做查询
}
}
四. 通过logstash将日志分发到ES中,便于日志查询和检索测试
log4j.properties 内容(将上面单元测试的日志文件存储到/httx/logs/out.log)
#Output pattern : date [thread] priority category - message
#log4j.rootLogger=DEBUG, Console, RollingFile
#
##Console
#log4j.appender.Console=org.apache.log4j.ConsoleAppender
#log4j.appender.Console.layout=org.apache.log4j.PatternLayout
#log4j.appender.Console.layout.ConversionPattern=%d [%t] %-5p [%c] - %m%n
#
##RollingFile
#log4j.appender.RollingFile=org.apache.log4j.FileAppender
#log4j.appender.RollingFile.File=/httx/logs/out.log
#log4j.appender.RollingFile.layout=org.apache.log4j.PatternLayout
#log4j.appender.RollingFile.layout.ConversionPattern=%d{yyyy-MM-dd HH:mm:ss,SSS} [%t] %-5p [%c] - %m%n
### 设置###
log4j.rootLogger = debug,stdout,D,E,logstash
### 输出信息到控制抬 ###
log4j.appender.stdout = org.apache.log4j.ConsoleAppender
log4j.appender.stdout.Target = System.out
log4j.appender.stdout.layout = org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern = [%-5p] %d{yyyy-MM-dd HH:mm:ss,SSS} method:%l%n%m%n
### 输出DEBUG 级别以上的日志到=/Users/bee/Documents/elk/log4j/debug.log###
log4j.appender.D = org.apache.log4j.DailyRollingFileAppender
log4j.appender.D.File = /httx/logs/out.log
log4j.appender.D.Append = true
log4j.appender.D.Threshold = DEBUG
log4j.appender.D.layout = org.apache.log4j.PatternLayout
log4j.appender.D.layout.ConversionPattern = %-d{yyyy-MM-dd HH:mm:ss} [ %t:%r ] - [ %p ] %m%n
### 输出ERROR 级别以上的日志到=/Users/bee/Documents/elk/log4j/error.log ###
log4j.appender.E = org.apache.log4j.DailyRollingFileAppender
log4j.appender.E.File =/httx/logs/out.log
log4j.appender.E.Append = true
log4j.appender.E.Threshold = ERROR
log4j.appender.E.layout = org.apache.log4j.PatternLayout
log4j.appender.E.layout.ConversionPattern = %-d{yyyy-MM-dd HH:mm:ss} [ %t:%r ] - [ %p ] %m%n
#输出日志到logstash
log4j.appender.logstash=org.apache.log4j.net.SocketAppender
log4j.appender.logstash.RemoteHost=127.0.0.1
log4j.appender.logstash.port=4560
log4j.appender.logstash.ReconnectionDelay=60000
log4j.appender.logstash.LocationInfo=true
启动单元测试,产生日志,存储到/httx/logs/out.log
package com.robinboot.facade;
import org.apache.log4j.Logger;
/**
* @auther: TF12778
* @date: 2020/11/10 11:08
* @description:
*/
public class Log4jTest {
public static final Logger logger=Logger.getLogger(Log4jTest.class);
public static void main(String[] args) {
logger.debug("This is a debug message!");
logger.info("This is info message!");
logger.warn("This is a warn message!");
logger.error("This is error message!");
try{
System.out.println(5/0);
}catch(Exception e){
logger.error(e);
}
}
}
单元测试启动后,可以看到logstash控制台输出了单元测试中的日志,如下截图:
此时通过ElasticSearch Head插件可以访问到localhost:9100地址,可以看到logstash分发到Elasticsearch的数据,如下:
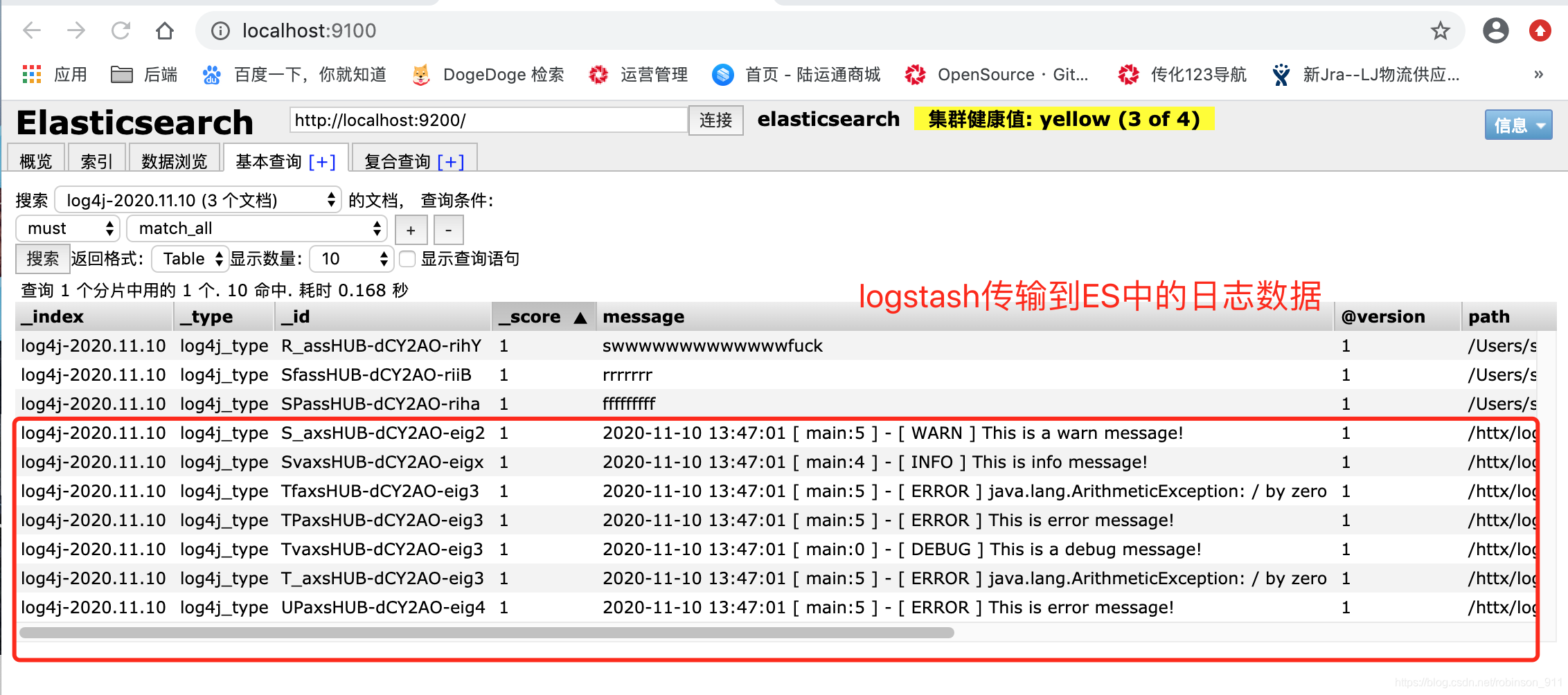
上面为什么会产生_index为log4j-2020.11.10,_type为log4j_type的数据,主要是因为我们在logstash.conf中配置了如下的规则:
# logstash中的数据分发到ES中去
elasticsearch {
hosts => ["http://localhost:9200"] # elasticsearch服务器地址
index => "log4j-%{+YYYY.MM.dd}" # log4j-2020.11.10
document_type => "log4j_type" # 文档类型,便于ES去做查询
}
五. 下载和配置Kibana
cd /Users/sunww/Documents/soft/ELK
cd kibana-7.3.0-darwin-x86_64/bin
配置下kibana.yml文件,如下:
server.port: 5601
server.host: "localhost"
elasticsearch.hosts: ["http://localhost:9200"] #连接到ES服务器
./kibana // 启动kibana
启动成功界面如下:
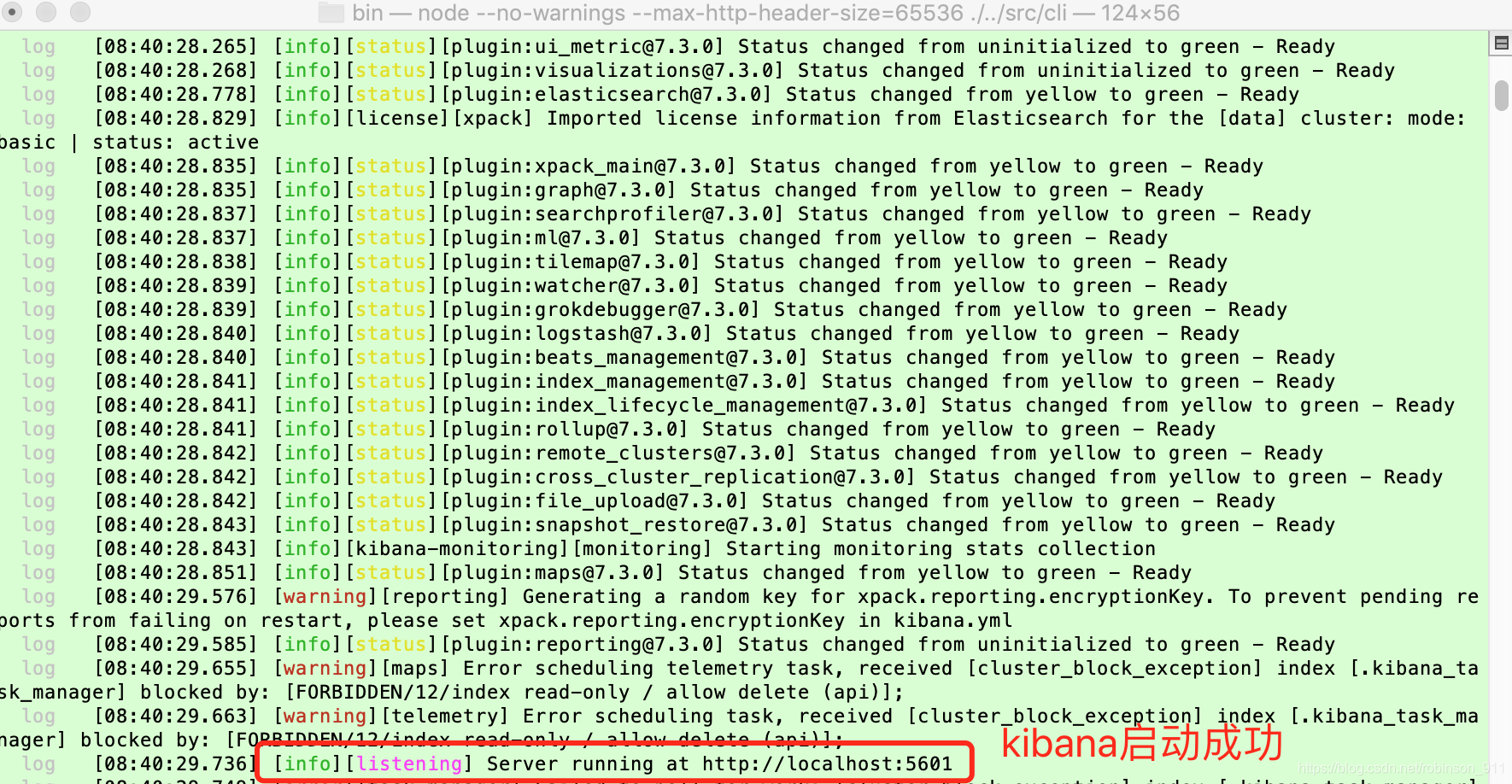
在浏览器中输入 localhost:5601 就可以看到视图界面了(可以看到我们上面创建的2个index)

六. Kibana创建查询日志的index pattern步骤以及日志查询
这里出现个错误,Kibana 创建索引 POST 403 (forbidden) on create index ,解决办法:https://blog.csdn.net/robinson_911/article/details/109603296
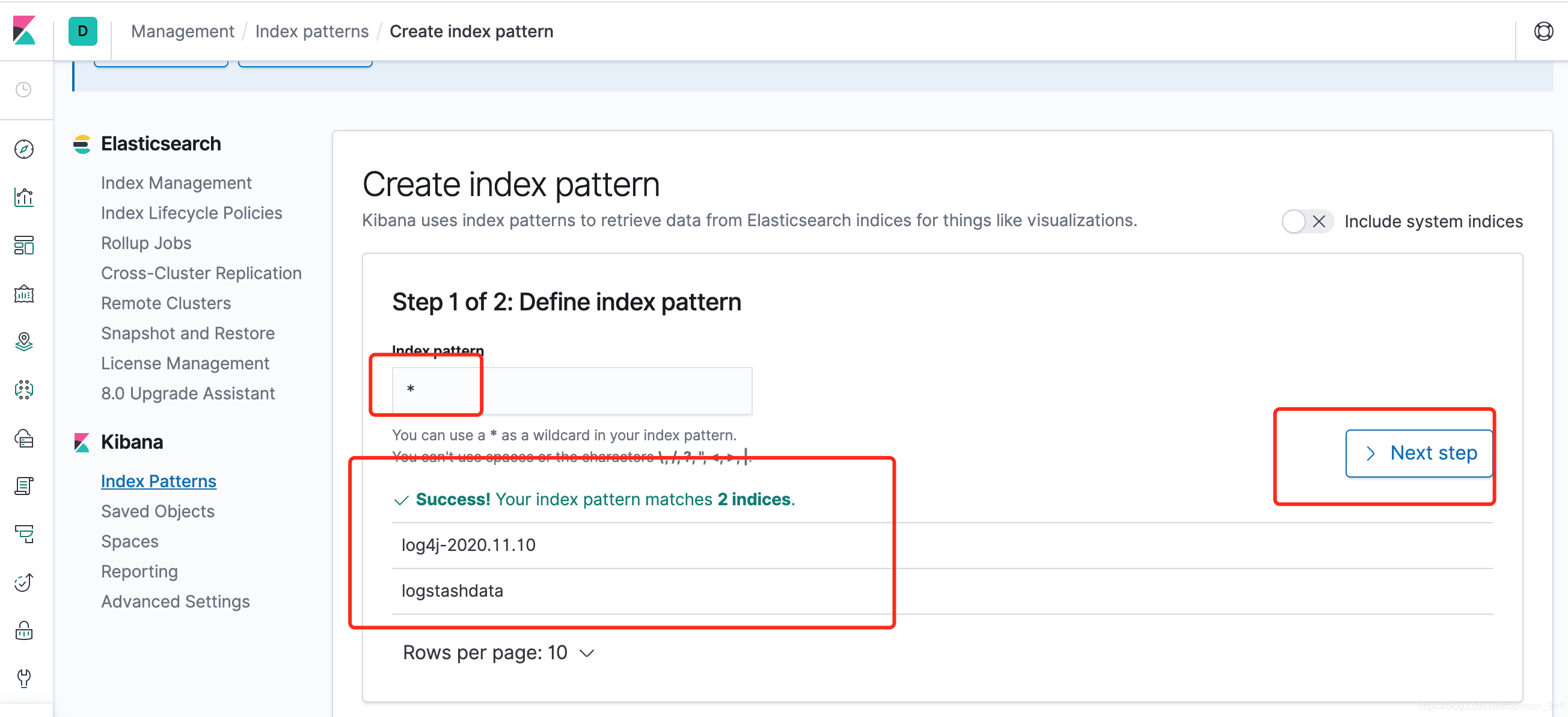
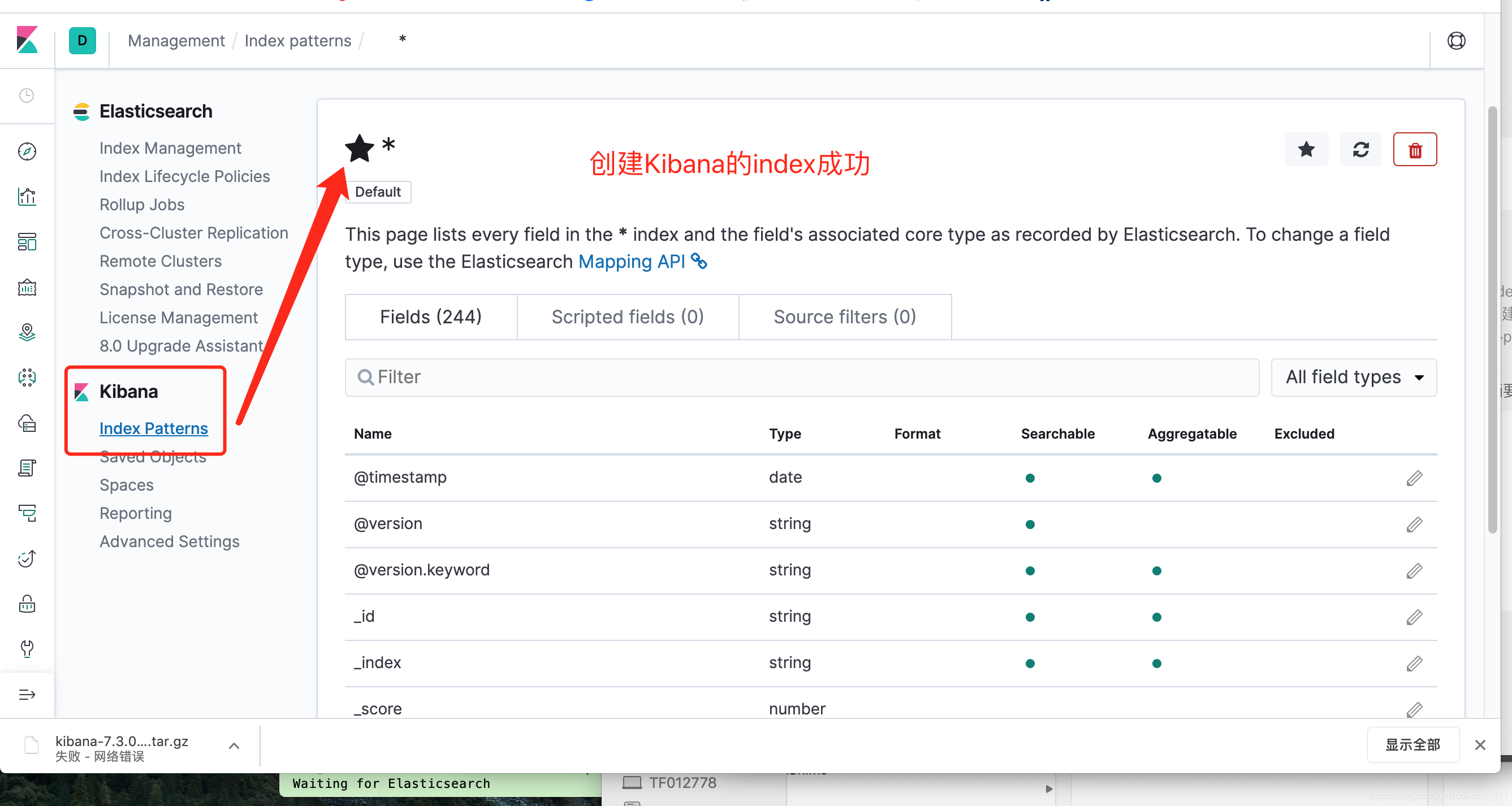
1. 创建index pattern
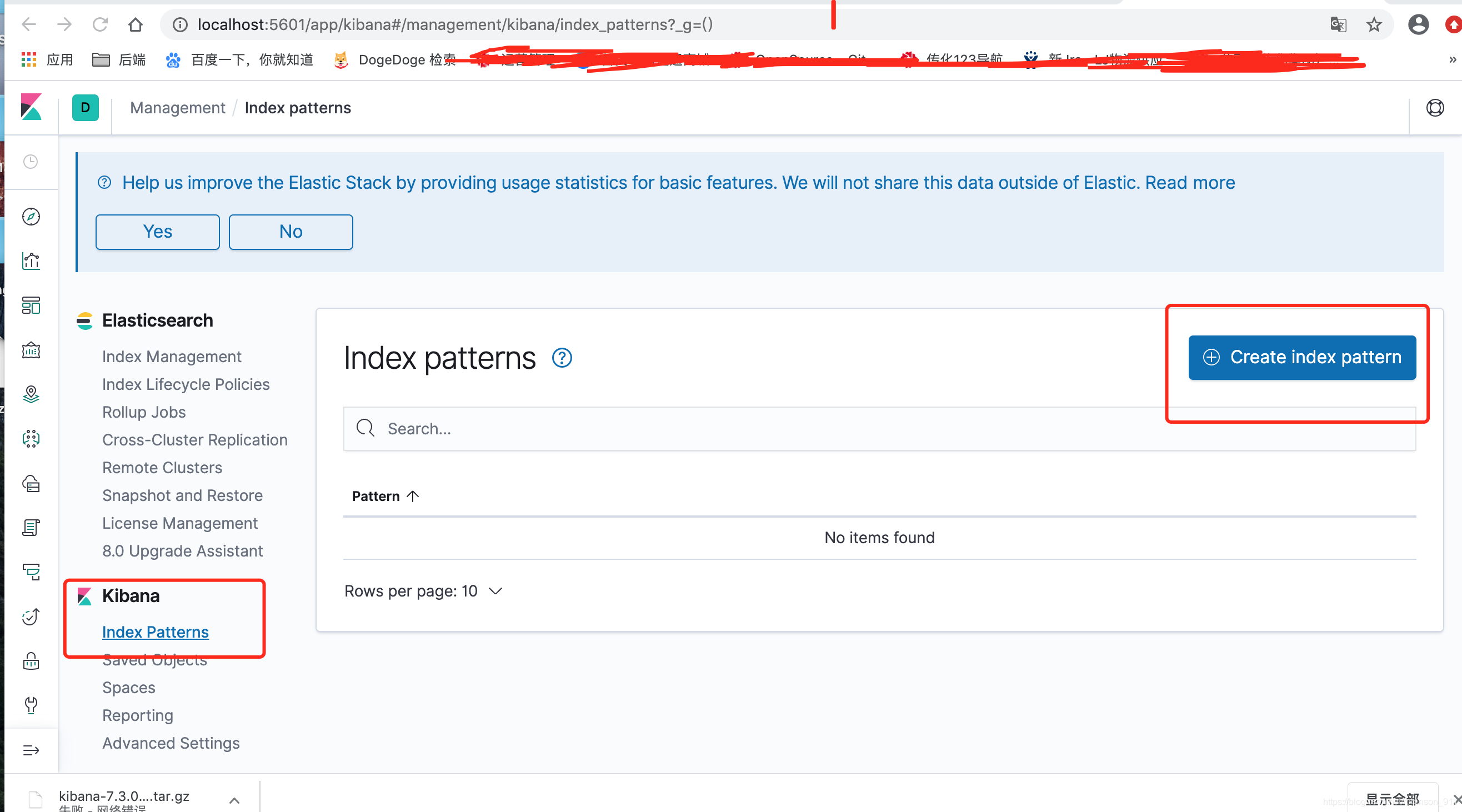

2. 日志查询
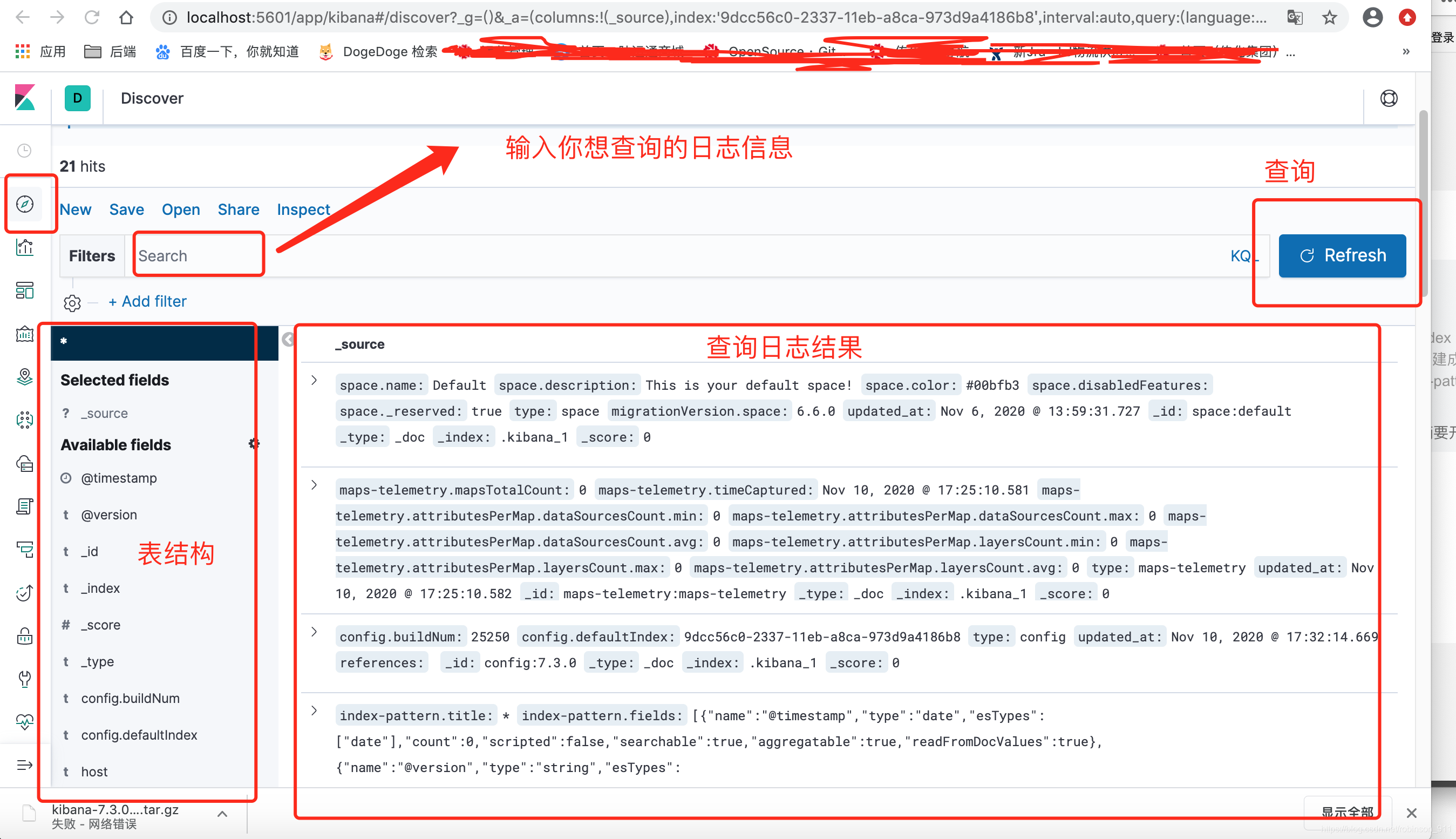
参考:
https://blog.csdn.net/gebitan505/article/details/70256827?utm_medium=distribute.pc_relevant.none-task-blog-title-6&spm=1001.2101.3001.4242
https://blog.csdn.net/mrxiky/article/details/86089280?utm_medium=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-3.pc_relevant_is_cache&depth_1-utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-3.pc_relevant_is_cache