目录
1.词袋模型(Bag of words,简称 BoW )
2.词频向量化
3.TF-IDF处理
3.1 TF
3.2 IDF
4 CountVectorizer与TfidfVectorizer的异同:
5.sklearn中TfidfTransformer和TfidfVectorizer对tf-idf的计算方式
6.实战
文本数据预处理的第一步通常是进行分词,分词后会进行向量化的操作。在介绍向量化之前,我们先来了解下词袋模型。
1.词袋模型(Bag of words,简称 BoW )
词袋模型假设我们不考虑文本中词与词之间的上下文关系,仅仅只考虑所有词的权重。而权重与词在文本中出现的频率有关。
词袋模型首先会进行分词,在分词之后,通过统计每个词在文本中出现的次数,我们就可以得到该文本基于词的特征,如果将各个文本样本的这些词与对应的词频放在一起,就是我们常说的向量化。向量化完毕后一般也会使用 TF-IDF 进行特征的权重修正,再将特征进行标准化。 再进行一些其他的特征工程后,就可以将数据带入机器学习模型中计算。
词袋模型的三部曲:分词(tokenizing),统计修订词特征值(counting)与标准化(normalizing)。
词袋模型有很大的局限性,因为它仅仅考虑了词频,没有考虑上下文的关系,因此会丢失一部分文本的语义。
在词袋模型统计词频的时候,可以使用 sklearn 中的 CountVectorizer 来完成。
2.词频向量化
CountVectorizer 类会将文本中的词语转换为词频矩阵,例如矩阵中包含一个元素a[i][j],它表示j词在i类文本下的词频。它通过 fit_transform 函数计算各个词语出现的次数,通过get_feature_names()可获取词袋中所有文本的关键字,通过 toarray()可看到词频矩阵的结果。
3.TF-IDF处理
然而有些词在文本中尽管词频高,但是并不重要,这个时候就可以用TF-IDF技术。
TF-IDF(Term Frequency–Inverse Document Frequency)是一种用于资讯检索与文本挖掘的常用加权技术。TF-IDF是一种统计方法,用以评估一个字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。TF-IDF加权的各种形式常被搜索引擎应用,作为文件与用户查询之间相关程度的度量或评级。
TF-IDF的主要思想是:如果某个词或短语在一篇文章中出现的频率TF高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。TF-IDF实际上是:TF * IDF。
3.1 TF
TF:Term Frequency,即词频。它表示一个词在内容(如某文章)中出现的次数。为了消除文档本身大小的影响,通常,它的定义是:
TF = 某个词在文档中出现的次数 / 文档的总词数
某个词出现越多,表示它约重要。比如某篇新闻中,“剑术”出现了5次,“电视”出现了1次,很可能这是一个剑术赛事报道。
如果这篇新闻中,“中国”和“剑术”出现的次数一样多,是不是表示两者同等重要呢?答案是否定的,因为中国这个词很常见,它难以表达文档的特性。而剑术很少见,更能表达文章的特性。
3.2 IDF
IDF(Inverse Document Frequency),即逆文档频率,它是一个表达词语重要性的指标。通常,它的计算方法是:
IDF=log(语料库中的文档数/(包含该词的文档数+1))
如果所有文章都包涵某个词,那个词的IDF=log(1)=0, 即重要性为零。停用词的IDF约等于0。
如果某个词只在很少的文章中出现,则IDF很大,其重要性也越高。
为了避免分母为0,所以+1.
逆向文件频率(Inverse Document Frequency,IDF)是一个词语普遍重要性的度量。某一特定词语的IDF,可以由总文件数目除以包含该词语之文件的数目,再将得到的商取对数得到。即文档总数n与词w所出现文件数docs(w, D)比值的对数。
idf = log(n / docs(w, D))
TF-IDF根据 tf 和 idf 为每一个文档d和由关键词w[1]…w[k]组成的查询串q计算一个权值,用于表示查询串q与文档d的匹配度:
tf-idf(q, d) = sum { i = 1..k | tf-idf(w[i], d) } = sum { i = 1..k | tf(w[i], d) * idf(w[i]) }
某一特定文件内的高词语频率,以及该词语在整个文件集合中的低文件频率,可以产生出高权重的TF-IDF。因此,TF-IDF倾向于过滤掉常见的词语,保留重要的词语
TF-IDF值
TF-IDF = TF X IDF
其中:

如果一个词越常见,那么分母就越大,逆文档频率就越小越接近0。分母之所以要加1,是为了避免分母为0(即所有文档都不包含该词)。log表示对得到的值取对数。
假定某训练文本长度为1000个词,”中国”、”蜜蜂”、”养殖”各出现20次,则这三个词的”词频”(TF)都为0.02。然后,搜索Google发现,包含”的”字的网页共有250亿张,假定这就是中文网页总数(即总样本数)。包含”中国”的网页共有62.3亿张,包含”蜜蜂”的网页为0.484亿张,包含”养殖”的网页为0.973亿张。则它们的逆文档频率(IDF)和TF-IDF如下:
| NULL |
包含该词的文档数(亿) |
TF |
IDF |
TF-IDF |
| 中国 |
62.3 |
0.2 |
0.603 |
0.0121 |
| 蜜蜂 |
0.484 |
0.2 |
2.713 |
0.0543 |
| 养殖 |
0.973 |
0.2 |
2.410 |
0.0482 |
如:
0.2∗log(250000000006230000000+1)=0.2∗0.603=0.01210.2∗log(250000000006230000000+1)=0.2∗0.603=0.0121
从上表可见,”蜜蜂”的TF-IDF值最高,”养殖”其次,”中国”最低。所以,如果只选择一个词,”蜜蜂”就是这篇文章的关键词。
相关参考:TF-IDF模型的概率解释:https://www.cnblogs.com/weidagang2046/archive/2012/10/22/tf-idf-from-probabilistic-view.html
4 CountVectorizer与TfidfVectorizer的异同:
对于每一个训练文本,CountVectorizer只考虑每种词汇在该训练文本中出现的频率,而TfidfVectorizer除了考量某一词汇在当前训练文本中出现的频率之外,同时关注包含这个词汇的其它训练文本数目的倒数。
相比之下,训练文本的数量越多,TfidfVectorizer这种特征量化方式就更有优势。
smooth_idf=True时
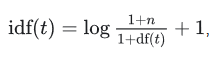
smooth_idf=False时
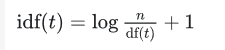
标准公式
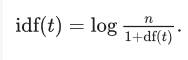
6.实战
实战1
from sklearn.feature_extraction.text import CountVectorizer
X_test = ['I sed about sed the lack',
'of any Actually']
count_vec=CountVectorizer(stop_words=None)
print (count_vec.fit_transform(X_test).toarray())
print ('\nvocabulary list:\n\n',count_vec.vocabulary_)
>>
>>
[[1 0 0 1 1 0 2 1]
[0 1 1 0 0 1 0 0]]
(0, 4) 1
(0, 7) 1
(0, 0) 1
(0, 6) 2
(0, 3) 1
(1, 1) 1
(1, 2) 1
(1, 5) 1
vocabulary list:
{u'about': 0, u'i': 3, u'of': 5, u'lack': 4, u'actually': 1, u'sed': 6, u'the': 7, u'any': 2}
关于上面的代码,有几点说明:
(1)第6行代码中,stop_words=None表示不去掉停用词,若改为stop_words=’english’则去掉停用词(**
**);
(2)第12,13行,分别是X_test中,两段文本的词频统计结果;
(3)第15-22行,是稀疏矩阵的表示方式;
(4)CountVectorizer同样适用于中文
# -*- coding: utf-8 -*-
from sklearn.feature_extraction.text import CountVectorizer
X_test = [u'没有 你 的 地方 都是 他乡',u'没有 你 的 旅行 都是 流浪']
count_vec=CountVectorizer(token_pattern=r"(?u)\b\w\w+\b")
print (count_vec.fit_transform(X_test).toarray())
print (count_vec.fit_transform(X_test))
print ('\nvocabulary list:\n')
for key,value in count_vec.vocabulary_.items():
print (key,value)
>>
>>
[[1 1 0 1 0 1]
[0 0 1 1 1 1]]
(0, 0) 1
(0, 5) 1
(0, 1) 1
(0, 3) 1
(1, 4) 1
(1, 2) 1
(1, 5) 1
(1, 3) 1
vocabulary list:
他乡 0
地方 1
旅行 2
没有 3
都是 5
流浪 4
实战2(.sklearn.feature_extraction.text.TfidfVectorizer )
TfidfVectorizer
| 参数表 |
作用 |
| stop_words |
停用词表;自定义停用词表 |
| token_pattern |
过滤规则; |
| 属性表 |
作用 |
| vocabulary_ |
词汇表;字典型 |
| idf_ |
返回idf值 |
| stop_words_ |
返回停用词表 |
| 方法表 |
作用 |
| fit_transform(X) |
拟合模型,并返回文本矩阵 |
# -*- coding: utf-8 -*-
from sklearn.feature_extraction.text import TfidfVectorizer
X_test = ['没有 你 的 地方 都是 他乡','没有 你 的 旅行 都是 流浪']
stopword = [u'都是'] #自定义一个停用词表,如果不指定停用词表,则默认将所有单个汉字视为停用词;但可以设token_pattern=r"(?u)\b\w+\b",即不考虑停用词
tfidf=TfidfVectorizer(token_pattern=r"(?u)\b\w\w+\b",stop_words=stopword)
weight=tfidf.fit_transform(X_test).toarray()
word=tfidf.get_feature_names()
print ('vocabulary list:\n')
for key,value in tfidf.vocabulary_.items():
print (key,value)
print ('IFIDF词频矩阵:\n')
print (weight)
for i in range(len(weight)): # 打印每类文本的tf-idf词语权重,第一个for遍历所有文本,第二个for便利某一类文本下的词语权重
print (u"-------这里输出第", i, u"类文本的词语tf-idf权重------")
for j in range(len(word)):
print (word[j], weight[i][j]#第i个文本中,第j个次的tfidf值)
>>
>>
vocabulary list:
没有 3
他乡 0
地方 1
旅行 2
流浪 4
IFIDF词频矩阵:
[[ 0.6316672 0.6316672 0. 0.44943642 0. ]
[ 0. 0. 0.6316672 0.44943642 0.6316672 ]]
-------第 0 类文本的词语tf-idf权重------
他乡 0.631667201738
地方 0.631667201738
旅行 0.0
没有 0.449436416524
流浪 0.0
-------第 1 类文本的词语tf-idf权重------
他乡 0.0
地方 0.0
旅行 0.631667201738
没有 0.449436416524
流浪 0.631667201738
参考:
- http://www.ruanyifeng.com/blog/2013/03/tf-idf.htm
- https://blog.csdn.net/the_lastest/article/details/79093407
- Python机器学习即实践
-
http://scikit-learn.org/stable/modules/feature_extraction.html#common-vectorizer-usage
-
http://www.cnblogs.com/weidagang2046/archive/2012/10/22/tf-idf-from-probabilistic-view.html#top
-
https://zhangzirui.github.io/posts/Document-14%20(sklearn-feature).md
====================
n-gram的理解,未完待续
一、N-gram统计语言模型的原理
N-gram模型:参数越多,可区别性越好,但同时单个参数的实例变少从而降低了可靠性,一般取2-3gram即可。
二、使用sklearn CountVectorizer 实战n-gram
通过如下实验可知:
12 + 11 =23
结论:
相同语料库的情况下, ngram_range=(1,2)单词量的大小等于ngram_range=(1,1)与ngram_range=(2,2)单词量大小之和。

注意如下复制的代码中df.head的显示中,第一列为行号。
1.ngram_range=(1,1)-->ngram1
# n-gram
from sklearn.feature_extraction.text import CountVectorizer
import pandas as pd
import jieba
data = ["为了祖国,为了胜利,向我开炮!向我开炮!",
"记者:你怎么会说出那番话",
"我只是觉得,对准我自己打"]
data = [" ".join(jieba.lcut(e)) for e in data] # 分词,并用" "连接+
print(type(data))
print(data)
vec = CountVectorizer(min_df=1, ngram_range=(1,1))
X = vec.fit_transform(data) # transform text to metrix
print(vec)
vec.get_feature_names() # get features
<class 'list'>
['为了 祖国 , 为了 胜利 , 向 我 开炮 ! 向 我 开炮 !', '记者 : 你 怎么 会 说出 那 番话', '我 只是 觉得 , 对准 我 自己 打']
CountVectorizer(analyzer='word', binary=False, decode_error='strict',
dtype=<class 'numpy.int64'>, encoding='utf-8', input='content',
lowercase=True, max_df=1.0, max_features=None, min_df=1,
ngram_range=(1, 1), preprocessor=None, stop_words=None,
strip_accents=None, token_pattern='(?u)\\b\\w\\w+\\b',
tokenizer=None, vocabulary=None)
['为了', '只是', '对准', '开炮', '怎么', '番话', '祖国', '胜利', '自己', '觉得', '记者', '说出']
print (vec.vocabulary_)
len(vec.vocabulary_)
//如下单词的数字与vec.get_feature_names()对应的序号对应。
{'为了': 0, '祖国': 6, '胜利': 7, '开炮': 3, '记者': 10, '怎么': 4, '说出': 11, '番话': 5, '只是': 1, '觉得': 9, '对准': 2, '自己': 8}
12
X
<3x12 sparse matrix of type '<class 'numpy.int64'>'
with 12 stored elements in Compressed Sparse Row format>
//X为稀疏矩阵,所以打印出来如下形式
print(X)
(0, 3) 2
(0, 7) 1
(0, 6) 1
(0, 0) 2
(1, 5) 1
(1, 11) 1
(1, 4) 1
(1, 10) 1
(2, 8) 1
(2, 2) 1
(2, 9) 1
(2, 1) 1
X.toarray()
array([[2, 0, 0, 2, 0, 0, 1, 1, 0, 0, 0, 0],
[0, 0, 0, 0, 1, 1, 0, 0, 0, 0, 1, 1],
[0, 1, 1, 0, 0, 0, 0, 0, 1, 1, 0, 0]], dtype=int64)
df = pd.DataFrame(X.toarray(), columns=vec.get_feature_names()) # to DataFrame
df.head()
为了 只是 对准 开炮 怎么 番话 祖国 胜利 自己 觉得 记者 说出
0 2 0 0 2 0 0 1 1 0 0 0 0
1 0 0 0 0 1 1 0 0 0 0 1 1
2 0 1 1 0 0 0 0 0 1 1 0 0
df.shape
(3, 12)
词典包含为12个单词
2.ngram_range=(2,2)-->-->ngram2
# n-gram
from sklearn.feature_extraction.text import CountVectorizer
import pandas as pd
import jieba
data = ["为了祖国,为了胜利,向我开炮!向我开炮!",
"记者:你怎么会说出那番话",
"我只是觉得,对准我自己打"]
# n-gram
from sklearn.feature_extraction.text import CountVectorizer
import pandas as pd
import jieba
data = ["为了祖国,为了胜利,向我开炮!向我开炮!",
"记者:你怎么会说出那番话",
"我只是觉得,对准我自己打"]
data = [" ".join(jieba.lcut(e)) for e in data] # 分词,并用" "连接
vec1 = CountVectorizer(min_df=1, ngram_range=(2,2))
X1 = vec1.fit_transform(data) # transform text to metrix
vec1.get_feature_names() # get features
['为了 祖国',
'为了 胜利',
'只是 觉得',
'对准 自己',
'开炮 开炮',
'怎么 说出',
'祖国 为了',
'胜利 开炮',
'觉得 对准',
'记者 怎么',
'说出 番话']
print (vec1.vocabulary_)
len(vec1.vocabulary_)
{'为了 祖国': 0, '祖国 为了': 6, '为了 胜利': 1, '胜利 开炮': 7, '开炮 开炮': 4, '记者 怎么': 9, '怎么 说出': 5, '说出 番话': 10, '只是 觉得': 2, '觉得 对准': 8, '对准 自己': 3}
11
df1 = pd.DataFrame(X1.toarray(), columns=vec1.get_feature_names()) # to DataFrame
df1.head()
为了 祖国 为了 胜利 只是 觉得 对准 自己 开炮 开炮 怎么 说出 祖国 为了 胜利 开炮 觉得 对准 记者 怎么 说出 番话
0 1 1 0 0 1 0 1 1 0 0 0
1 0 0 0 0 0 1 0 0 0 1 1
2 0 0 1 1 0 0 0 0 1 0 0
df1.shape
df1.shape
(3, 11)
词典包含11个单词
3.ngram_range=(1,2)--->同时包含-->ngram1和-->ngram2
# n-gram
from sklearn.feature_extraction.text import CountVectorizer
import pandas as pd
import jieba
data = ["为了祖国,为了胜利,向我开炮!向我开炮!",
"记者:你怎么会说出那番话",
"我只是觉得,对准我自己打"]
data = [" ".join(jieba.lcut(e)) for e in data] # 分词,并用" "连接
vec2 = CountVectorizer(min_df=1, ngram_range=(1,2))
X2 = vec2.fit_transform(data) # transform text to metrix
vec2.get_feature_names() # get features
['为了',
'为了 祖国',
'为了 胜利',
'只是',
'只是 觉得',
'对准',
'对准 自己',
'开炮',
'开炮 开炮',
'怎么',
'怎么 说出',
'番话',
'祖国',
'祖国 为了',
'胜利',
'胜利 开炮',
'自己',
'觉得',
'觉得 对准',
'记者',
'记者 怎么',
'说出',
'说出 番话']
print (vec2.vocabulary_)
len(vec2.vocabulary_)
{'为了': 0, '祖国': 12, '胜利': 14, '开炮': 7, '为了 祖国': 1, '祖国 为了': 13, '为了 胜利': 2, '胜利 开炮': 15, '开炮 开炮': 8, '记者': 19, '怎么': 9, '说出': 21, '番话': 11, '记者 怎么': 20, '怎么 说出': 10, '说出 番话': 22, '只是': 3, '觉得': 17, '对准': 5, '自己': 16, '只是 觉得': 4, '觉得 对准': 18, '对准 自己': 6}
23
df2 = pd.DataFrame(X2.toarray(), columns=vec2.get_feature_names()) # to DataFrame
df2.head()
为了 为了 祖国 为了 胜利 只是 只是 觉得 对准 对准 自己 开炮 开炮 开炮 怎么 ... 祖国 为了 胜利 胜利 开炮 自己 觉得 觉得 对准 记者 记者 怎么 说出 说出 番话
0 2 1 1 0 0 0 0 2 1 0 ... 1 1 1 0 0 0 0 0 0 0
1 0 0 0 0 0 0 0 0 0 1 ... 0 0 0 0 0 0 1 1 1 1
2 0 0 0 1 1 1 1 0 0 0 ... 0 0 0 1 1 1 0 0 0 0
3 rows × 23 columns
df2.shape
(3, 23)
词典包含23个单词。
------------
参考阅读:
https://www.cnblogs.com/Lin-Yi/p/8974108.html
机器学习之路:python 文本特征提取 CountVectorizer, TfidfVectorizer
https://blog.csdn.net/sxhlovehmm/article/details/41252125
数据稀疏的解释:假设词表中有20000个词,如果是bigram model(二元模型)那么可能的2-gram就有400000000个,如果是trigram(3元模型),那么可能的3-gram就有8000000000000个!那么对于其中的很多词对的组合,在语料库中都没有出现,根据最大似然估计得到的概率将会是0,这会造成很大的麻烦,在算句子的概率时一旦其中的某项为0,那么整个句子的概率就会为0,最后的结果是,我们的模型只能算可怜兮兮的几个句子,而大部分的句子算得的概率是0. 因此,我们要进行数据平滑(data Smoothing),数据平滑的目的有两个:一个是使所有的N-gram概率之和为1,使所有的N-gram概率都不为0,有关数据平滑处理的方法可以参考《数学之美》第33页的内容。
注意:2-gram中,(a,b)(b,a)算两个
40000 0000 = 20000 ×19999
80000 0000 0000 = 20000 × 19999 ×19998