本文中,我们共同学习下Postgresql的WAL日志。WAL,是Write Ahead Log的简称,翻译过来就是预写日志,或者叫做重做日志。相信大家对数据库事务的四大特性ACID(原子性、一致性、隔离性和持久性)已经非常熟悉了,今天我们先从数据库数据的持久性说起。数据的持久性是指,数据库中的事务中的数据一旦提交,便可以做到持久化,只要你不删除,那么数据将会永远存在数据库中。
一、有关CheckPoint
现在我们就来讨论下这个提交的过程。我们直到数据库中数据的存放位置最终是在磁盘上,但是磁盘IO是一个很耗时的操作,当我们查询数据时,如果每次查询都从磁盘直接查询,那么大量的IO,尤其是随机IO,会吃掉大量的时间。所以数据库中提出了共享内存的概念,将一部分数据先读到内存中,查询时直接从内存查询,这就大大提高了查询效率。另一方面,如果修改,也只是在内存中进行修改,那么,这就随之而带来了新的问题:如何保证在内存中的数据和磁盘一致?显然需要一定的时机将内存中的数据重新持久化到磁盘。内存中和磁盘中不一致的数据块,我们称作脏块,而脏块同步到磁盘的过程,就是一个Checkpoint的过程。
Postgresql的checkpoint的上可以分为两种,自动checkpoint和手动执行checkpoint命令,两个过程的结果都是将脏块写入到了磁盘。自动的checnpoint是按照一定的时间间隔执行checkpoint命令,时间间隔是在postgresql.conf文件中可配的,默认是5分钟。可以通过show命令查看配置的这个参数:
stock_analysis_data=# show checkpoint_timeout;
checkpoint_timeout
--------------------
5min
(1 row)
但是,这个参数是无法用set命令修改的,如果修改,会提示下面的错误:‘
stock_analysis_data=# set checkpoint_timeout='10min';
ERROR: parameter "checkpoint_timeout" cannot be changed now
因为它是属于数据库全局的配置,不属于某个会话,只能通过修改postgresql.conf文件,然后重启服务。
除了上述自动checkpoint之外,我们也可以手动执行checkpoint命令,这样也最终使内存中的脏块刷新到了磁盘上,完成了数据的持久化。
stock_analysis_data=# checkpoint;
CHECKPOINT
在checkpoint之后,通过查看控制文件可以看到哪个 WAL文件的内容已经被持久化:
[root@VM-115-39-centos bin]# ./pg_controldata -D /var/lib/pgsql/11/data/
pg_control version number: 1100
Catalog version number: 201809051
Database system identifier: 6853342000172018996
Database cluster state: in production
pg_control last modified: Fri 09 Jul 2021 09:56:48 AM CST
Latest checkpoint location: 2/E8C05538
Latest checkpoint's REDO location: 2/E8C05500
Latest checkpoint's REDO WAL file: 0000000100000002000000E8
Latest checkpoint's TimeLineID: 1
Latest checkpoint's PrevTimeLineID: 1
Latest checkpoint's full_page_writes: on
Latest checkpoint's NextXID: 0:353416
Latest checkpoint's NextOID: 36156
Latest checkpoint's NextMultiXactId: 1
Latest checkpoint's NextMultiOffset: 0
Latest checkpoint's oldestXID: 561
Latest checkpoint's oldestXID's DB: 1
Latest checkpoint's oldestActiveXID: 353416
Latest checkpoint's oldestMultiXid: 1
Latest checkpoint's oldestMulti's DB: 1
Latest checkpoint's oldestCommitTsXid:0
Latest checkpoint's newestCommitTsXid:0
Time of latest checkpoint: Fri 09 Jul 2021 09:56:48 AM CST
Fake LSN counter for unlogged rels: 0/1
Minimum recovery ending location: 0/0
Min recovery ending loc's timeline: 0
Backup start location: 0/0
Backup end location: 0/0
End-of-backup record required: no
wal_level setting: replica
wal_log_hints setting: off
max_connections setting: 100
max_worker_processes setting: 8
max_prepared_xacts setting: 10
max_locks_per_xact setting: 64
track_commit_timestamp setting: off
Maximum data alignment: 8
Database block size: 8192
Blocks per segment of large relation: 131072
WAL block size: 8192
Bytes per WAL segment: 16777216
Maximum length of identifiers: 64
Maximum columns in an index: 32
Maximum size of a TOAST chunk: 1996
Size of a large-object chunk: 2048
Date/time type storage: 64-bit integers
Float4 argument passing: by value
Float8 argument passing: by value
Data page checksum version: 0
Mock authentication nonce: e6868f1dca4d434a9fb50334b182677fd3a9881e0ca2cd9560c3baa41c3c3622
[root@VM-115-39-centos bin]#
我们看第8行Latest checkpoint's REDO location这个参数,它表示在进行checkpoint时,当前持久化的点记录在了哪个WAL文件,也就是说在这个点之前的所有数据都已经刷到磁盘,我们可以执行下面的命令查看这个文件,参数就是Latest checkpoint's REDO location的值:
stock_analysis_data=# select pg_walfile_name('2/E8C05538');
pg_walfile_name
--------------------------
0000000100000002000000E8
(1 row)
二、WAL日志的作用
我们在上文中说过,Postgresql默认每5分钟自动进行一次checkpoint,把内存中的脏块同步到磁盘上,这就又会引起另外一个问题:假设数据库在早上8:00钟自动进行了一次checkpoint,那么下一次执行checkpoint的时间会是在8:05,如果8:00~8:05这段时间内又有新的数据写入,而且写入后数据库发生了宕机重启,那这部分新的数据岂不是就丢失了?于是,为了解决这个问题,WAL日志就登场了。Postgresql的WAL日志、Oracle中的Redo日志、以及Mysql的binlog都是这个作用。
2.1 WAL日志的目录
Postgresql中redo日志在数据库的数据目录的pg_wal(Postgresql9.X之前叫pg_xlog)目录下,查看所有日志文件如下:
[root@VM-115-39-centos pg_wal]# pwd
/var/lib/pgsql/11/data/pg_wal
[root@VM-115-39-centos pg_wal]# ls
000000010000000000000057 0000000100000000000000DB 00000001000000010000005F 0000000100000001000000E3 000000010000000200000067
000000010000000000000058 0000000100000000000000DC 000000010000000100000060 0000000100000001000000E4 000000010000000200000068
......
我们看到,所谓的WAL日志其实就是这些由24位16进制数字命名的文件。那么WAL日志是怎么解决在自动checkpoint间隔内数据库宕机而数据不会丢失呢?实际上原理很简单,在更新内存中的数据同时,Postgresql会将数据同步保存到WAL日志上,一旦数据库发生了宕机再重启,它会根据前次checkpoint的时间点作为起始点,根据WAL日志更新起始点之后的数据,这就是所谓的’前滚‘过程。
可能有的朋友会有疑问:同样是写磁盘,为什么Postgresql在用户提交数据时,没有将数据直接写入到数据表磁盘上,而是写入到了WAL日志中?这就涉及到了重做日志写入算法效率的问题。
2.2 重做日志算法
我们直到磁盘IO一直时操作数据效率的一大瓶颈,而写WAL日志时,数据库采用了一种叫做重做日志算法的一种磁盘写入算法,在相同的数据量下,采用这种算法写入磁盘文件比普通的文件写入效率要提高一倍以上,所以Postresql或者其它数据库都是采用的这种,先更新内存数据和重写日志,最终将脏块同步到磁盘的方式,保证数据的安全性和持久性。
2.3 WAL文件的文件名解析
在上文中已经谈到过,WAL文件的文件名是由24位16进制的数字组成的,那么可以执行下面的命令来查看数据库当前正在使用的WAL文件,并以此文件名为例来说明下WAL文件名的含义:
stock_analysis_data=# select pg_walfile_name(pg_current_wal_lsn());
pg_walfile_name
--------------------------
0000000100000002000000E8
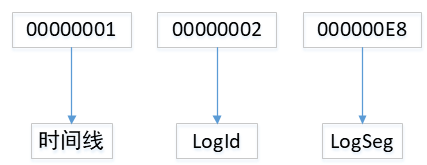
整个文件名0000000100000002000000E8,其实分成了三个部分。但是,在解释每个部分的含义之前,我们还必须引入另外一个概念——LSN。LSN,全称是Log Sequence Number 翻译过来就是日志序列号,是一个Postgresql全局的不断增长的8子节长度的数字,它会随着WAL日志的不断增加而不断地增长。
现在,我们回过头来,再看下WAL日志三个组成部分:
- 第一部分,叫做时间线,是从1开始递增地数字,很显然,当第二、三部分数字达到最大值之后,第一位会递增1。
- 第二部分,叫做LogId,实际上是LSN的高32位。
- 第三部分,叫做LogSeg,是LSN的低32位除以WAL文件的大小。WAL文件的大小默认是16M,但是可以在initdb时指定修改。
2.4 WAL文件的循环复用原理
如果单单从pg_wal目录下各个文件名称来看,WAL日志文件一直是在滚动更新的,旧文件不断地在删除、新文件不断地增加。我们又了解到,磁盘IO实际上效率是非常低的,那如果在WAL更新的过程中一方面要创建新文件,另一方面要删除旧文件,那岂不是会很耗时?其实,这是Postgresql玩的一手障眼法,当checkout命令执行后,旧的WAL文件也就没用了,当需要产生新的WAL文件时,并不是真正生成了新的文件,而是将最老的一个WAL文件进行了重命名。而且重命名也并不是我们传统意义上的rename,而是为旧文件创建了一个硬链接,然后再删除旧文件。
三、使用WAL日志进行热备份
WAL日志还有另外一个作用就是可以 利用其进行热备份(也就是不停服务,在线备份),使用WAL日志进行备份具有两种方法,一种是独占型的,另外一种是非独占型的,两者的主要区别在于:
1)前者不允许多个备份命令同时进行,而后者允许多个命令同时执行;
2)前者会在源数据目录下自动生成backup_label文件,只要有这个文件存在,数据库重启时就会从backup_label指定的checkpoint点开始恢复数据,而不是从最新的一次checkpoint开始,而后者需要我们手动创建backup_lable文件。
3)正是基于第2点原因,当我们在使用独占型的备份方式时,一旦未来得及删除backup_label文件,数据库发生了宕机,那么数据库重启后,就会从backup_label记录的checkpoint点开始恢复,就会加大前滚耗时。而且如果数据量比较大,造成从某些未来及持久化的WAL文件丢失,数据库就会报错,无法启动。
基于上述特点,在生产环境中备份建议采用非独占型的,但是在本次演示中,由于相对比较简单,笔者采用独占式的方式进行备份。
下面,笔者来演示下这个过程:
第1步,通过pg_start_backup()方法开始热备份。
stock_analysis_data=# select pg_start_backup('mydb202107091430');
pg_start_backup
-----------------
2/E9000028
可以看到在数据库的源目录下多了一个backup_lable的文件:

文件的内容如下:
START WAL LOCATION: 2/E9000028 (file 0000000100000002000000E9)
CHECKPOINT LOCATION: 2/E9000060
BACKUP METHOD: pg_start_backup
BACKUP FROM: master
START TIME: 2021-07-09 14:30:55 CST
LABEL: mydb202107091430
START TIMELINE: 1
主要是记录了备份开始时的点CHECKPOINT LOCATION,其实pg_start_backup命令本身就有两个作用:
1)执行checkpoint命令。
2)置写日志标志为:XLogCtl->Insert.forcePageWrites = true,也就是把这个标志设置为true后,数据库会把变化的整个数据块都记录到WAL文件中,而不仅仅是块中行的变化。
第一个作用很容易理解,这里不再多做解释。第二个作用主要是为了我们在做热备份的下一步考虑。当我们拷贝整个数据库源目录时,因为拷贝的是正在使用的数据块,很可能拷贝的块前半部分是旧数据,后半部分是新数据,如果WAL日志不是按照块记录变化,而是按行,这种不一致的块在将来数据重做时很难恢复。
第2步,通过cpio命令进行数据库源目录的备份
find /var/lib/pgsql/11/data | cpio -ocvB > /data/mydata.cpio
第3步,调用pg_stop_backup()结束备份
select pg_stop_backup();
pg_stop_backup主要有两个作用:
1)删除backup_label文件。
2)在WAL记录中记录一个XLOG_BACKUP_END的标记,而且会强制Postgresql开始使用下一个WAL文件。
比如在我本机上,在执行第3步之前,查看当前用的WAL文件:
postgres=# select pg_walfile_name(pg_current_wal_lsn());
pg_walfile_name
--------------------------
0000000100000002000000FD
(1 row)
在执行第三步之后:
postgres=# select pg_walfile_name(pg_current_wal_lsn());
pg_walfile_name
--------------------------
0000000100000002000000FE
发现WAL文件名称加了1。
第4步,这一步很重要,就是要复制源目录下所有的WAL文件作为备份。
原因是我们需要拷贝被标记了XLOG_BACKUP_END的WAL文件,在恢复时才能知道恢复截止到哪个点,在这个点之后的WAL文件数据全部都不要了。这个点也就是我们执行pg_stop_backup()时那个点。
结果了上述步骤,我们就完成了数据库的热备份,其实恢复起来就比较简单了:
(1)使用cpio命令将备份的文件恢复到目标目录:
cpio –icduv < /data/mydata.cpio
(2)然后将第4步备份的WAL文件复制到目标目录的pg_wal目录下。
至此,有关Postgresql进行热备份和恢复的内容就介绍完了。