点击下方卡片,关注“自动驾驶之心”公众号
ADAS巨卷干货,即可获取
今天自动驾驶之心很荣幸邀请到小乌龟,为大家分享分割大模型近期的发展情况。如果您有相关工作需要分享,请在文末联系我们!
>>点击进入→自动驾驶之心【语义分割】技术交流群
后台回复【分割综述】获取语义分割、实例分割、全景分割、弱监督分割等超全学习资料!
作者|小乌龟
编辑|自动驾驶之心
计算机视觉分割是计算机视觉领域的一个重要子领域,它旨在将图像中的每个像素分配到不同的类别或对象上。这种技术通常被用于图像识别、场景理解、医学图像处理等多个应用场景,具有广泛的实际应用价值。此前解决分割问题大致有两种方法。第一种是交互式分割,该方法允许分割任何类别的 对象,但需要一个人通过迭代细化掩码来指导该方法。第二种是自动分割,允许分割提前定义的特定对象类别(例如,猫或椅子),但需要大量的手动注释对象来训练(例如,数千甚至数万个分割猫的例子)。这两种方法都没有提供通用的、全自动的分割方法。
计算机视觉领域也迎来通用模型趋势,随着计算机视觉领域模型泛化能力的提升,有望推动通用的多模态AI系统发展,在工业制造、通用机器人、智能家居、游戏、虚拟现实等领域得到应用。本文介绍了近期分割大模型发展情况。
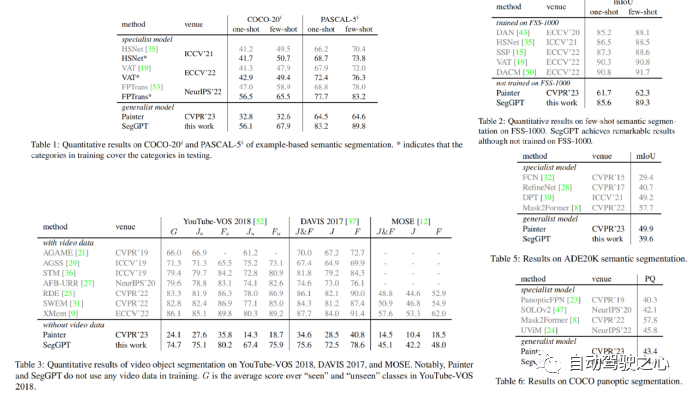
1.SAM
SAM(Segment Anything Model)Meta 的 FAIR 实验室发布的一种最先进的图像分割模型,该模型将自然语言处理领域的prompt范式引入计算机视觉领域,可以通过点击、框选和自动识别三种交互方式,实现精准的图像分割,突破性地提升了图像分割的效率。
1.1.任务
SAM 接受了数百万张图像和超过十亿个掩码的训练,可为任何提示返回有效的分割掩码。在这种情况下,提示是分割任务,可以是前景/背景点、粗框或遮罩、点击、文本,或者一般来说,指示图像中要分割的内容的任何信息。该任务也用作模型的预训练目标。

1.2.网络架构
SAM 的架构包含三个组件,它们协同工作以返回有效的分割掩码:
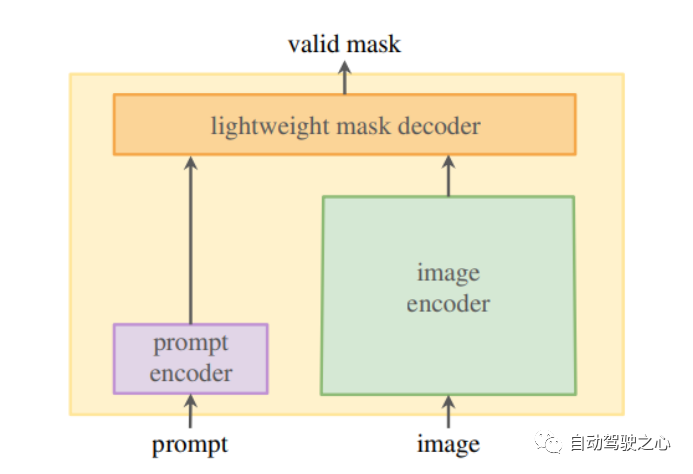
1.1.1.图像编码器
在最高级别,图像编码器(掩码自动编码器、MAE、预训练视觉变换器、ViT)生成一次性图像嵌入,可以在提示模型之前应用。
1.1.2.提示编码器
提示编码器将背景点、遮罩、边界框或文本实时编码到嵌入向量中。该研究考虑了两组提示:稀疏(点、框、文本)和密集(掩码)。
点和框由位置编码表示,并为每种提示类型添加学习嵌入。自由格式的文本提示由来自 CLIP 的现成文本编码器表示。密集提示,如蒙版,嵌入卷积并与图像嵌入逐元素求和。
1.1.3.掩码解码器
轻量级掩码解码器根据来自图像和提示编码器的嵌入预测分割掩码。它将图像嵌入、提示嵌入和输出标记映射到掩码。所有嵌入都由解码器块更新,解码器块在两个方向(从提示到图像嵌入和返回)使用提示自我注意和交叉注意。
掩码被注释并用于更新模型权重。这种布局增强了数据集,并允许模型随着时间的推移学习和改进,使其高效灵活。
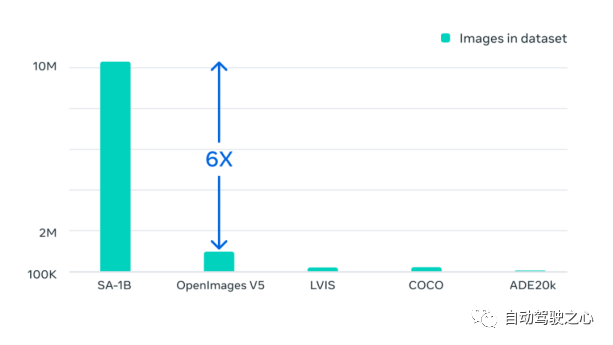
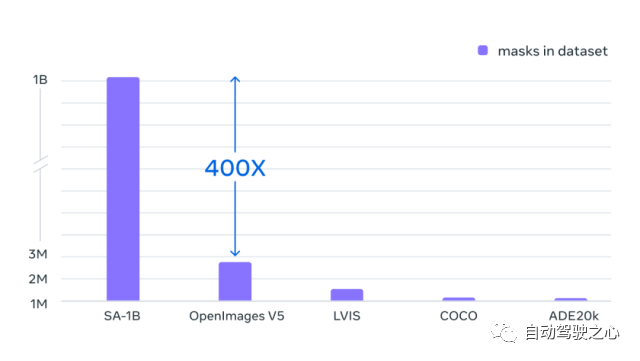
1.3.数据集
Segment Anything 10 亿掩码 (SA-1B) 数据集是迄今为止最大的标记分割数据集。它专为高级分割模型的开发和评估而设计。。标注者使用 SAM 交互地注释图像,之后新注释的数据又反过来更新 SAM,可谓是相互促进。
使用该方法,交互式地注释一个掩码只需大约 14 秒。与之前的大规模分割数据收集工作相比,Meta 的方法比 COCO 完全手动基于多边形的掩码注释快 6.5 倍,比之前最大的数据注释工作快 2 倍,这是因为有了 SAM 模型辅助的结果。
最终的数据集超过 11 亿个分割掩码,在大约 1100 万张经过许可和隐私保护图像上收集而来。SA-1B 的掩码比任何现有的分割数据集多 400 倍,并且经人工评估研究证实,这些掩码具有高质量和多样性,在某些情况下甚至在质量上可与之前更小、完全手动注释的数据集的掩码相媲美 。
1.4.零样本迁移实验
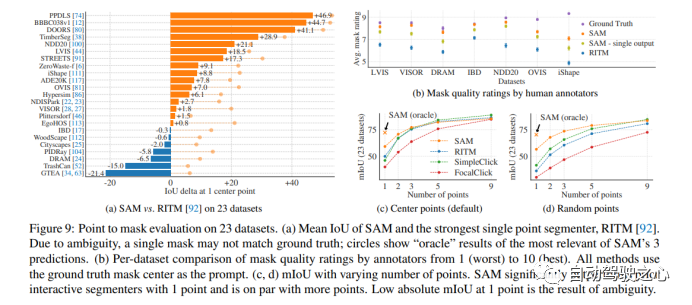
1.1.4.零样本单点有效掩码评估
1.1.5.零样本边缘检测

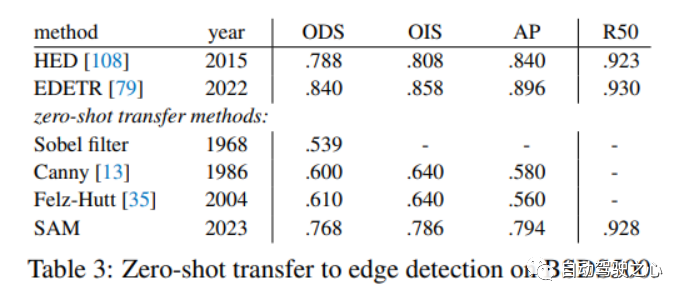
1.1.6.零样本对象建议
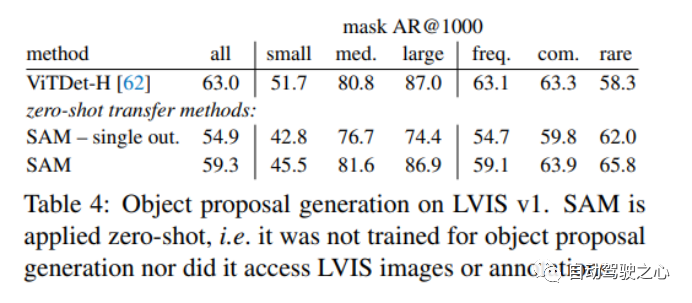
1.1.7.零样本实例分割
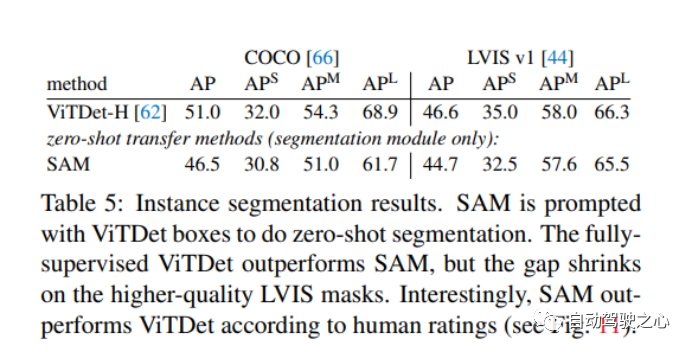
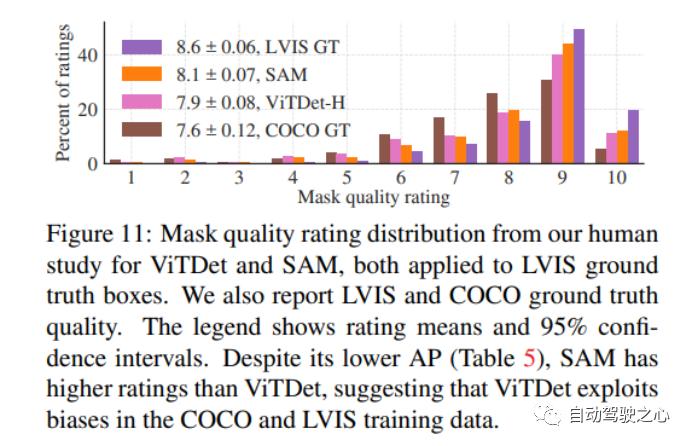
1.1.8.零样本文本转掩码

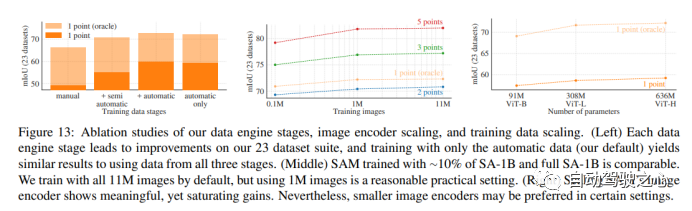
1.1.9.消融实验
2.Grounded-SAM
SAM发布后,很快出现了结合多种基础能力的衍生模型。例如由前微软亚研院首席科学家沈向洋博士创办的IDEA研究院,基于SAM、自有Grounding DINO模型、Stable Diffusion技术,研发出Grounded SAM模型,可以直接通过文本描述实现图片的检测、分割、生成。
借助Grounding DINO强大的零样本检测能力,Grounded SAM可以通过文本描述就可以找到图片中的任意物体,然后通过SAM强大的分割能力,细粒度的分割出mas。最后,还可以利用Stable Diffusion对分割出来的区域做可控的文图生成。


Grounding DINO例子

Grounded-Segment-Anything例子

3.SegGPT
国内的智源研究院视觉团队提出了通用分割模型SegGPT——Segment Everything in Context,首个利用视觉上下文完成各种分割任务的通用视觉模型。就像这样,在一张画面中标注出彩虹,就能批量分割其他画面中的彩虹。

和 SAM 相比,视觉模型的 In-context 能力是最大差异点 :
SegGPT “一通百通”:可使用一个或几个示例图片和对应的掩码即可分割大量测试图片。用户在画面上标注识别一类物体,即可批量化识别分割出其他所有同类物体,无论是在当前画面还是其他画面或视频环境中。
SAM“一触即通”:通过一个点、边界框或一句话,在待预测图片上给出交互提示,识别分割画面上的指定物体。
这也就意味着,SAM的精细标注能力,与SegGPT的批量化标注分割能力,还能进一步相结合,产生全新的CV应用。
具体而言,SegGPT 是智源通用视觉模型 Painter 的衍生模型,针对分割一切物体的目标做出优化。SegGPT 训练完成后无需微调,只需提供示例即可自动推理并完成对应分割任务,包括图像和视频中的实例、类别、零部件、轮廓、文本、人脸等等。
该模型具有以下优势能力:
通用能力:SegGPT具有上下文推理能力,模型能够根据上下文(prompt)中提供掩码,对预测进行自适应的调整,实现对“everything”的分割,包括实例、类别、零部件、轮廓、文本、人脸、医学图像等。
灵活推理能力:支持任意数量的prompt;支持针对特定场景的tuned prompt;可以用不同颜色的mask表示不同目标,实现并行分割推理。
自动视频分割和追踪能力:以第一帧图像和对应的物体掩码作为上下文示例,SegGPT能够自动对后续视频帧进行分割,并且可以用掩码的颜色作为物体的ID,实现自动追踪。
3.1.方法
SegGPT 训练框架将视觉任务的输出空间重新定义为“图像”,并将不同的任务统一为同一个图像修复问题,即随机mask任务输出图像并重建缺失的pixel。为了保持简单性和通用性,作者没有对架构和损失函数进行修改,即vanilla ViT和简单的 smooth-ℓ1损失,但在上下文训练中设计了一种新的随机着色方案更好的泛化能力。
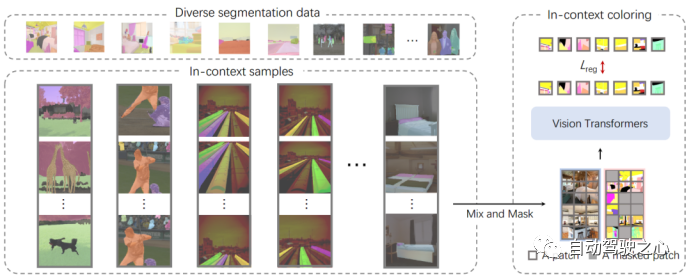
3.1.1.In-Context Coloring
在Painter的传统框架中,每个任务的颜色空间都是预定义的,导致solution往往会collapse成为multi-task learning的任务。拟议的上下文内着色随机着色方案包括对另一张具有相似背景的图像进行采样,将颜色映射到随机颜色,并使用混合上下文训练来关注context而不是特定的颜色信息。分段数据集的统一允许根据特定任务制定一致的数据采样策略,为不同的数据类型(例如语义和实例分割)定义不同的上下文,并且使用相同的颜色来指代相同的类别或实例。
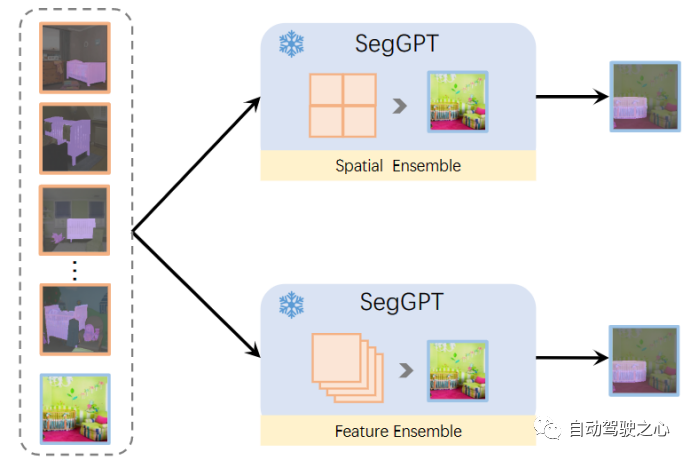
3.1.2.Context Ensemble
一旦训练完成,这种训练模式就可以在推理过程中释放出来。SegGPT支持在上下文中进行任意分割,例如,使用单个图像及其目标图像的示例。目标图像可以是单一颜色(不包括background),也可以是多种颜色,例如,在一个镜头中分割多个类别或感兴趣的对象。具体来说,给定要测试的输入图像,我们将其与示例图像拼接并将其提供给 SegGPT 以获得相应的context的预测。为了提供更准确和具体的上下文,可以使用多个示例。一种称为空间的Ensemble,多个example连接在n×n网格中,然后二次采样到与单个示例相同的大小。这种方法符合上下文着色的直觉,并且可以在几乎没有额外成本的情况下在上下文中提取多个示例的语义信息。另一种方法是特征集成。多个示例在批次维度中组合并独立计算,除了查询图像的特征在每个注意层之后被平均。通过这种方式,查询图像在推理过程中收集了有关多个示例的信息。
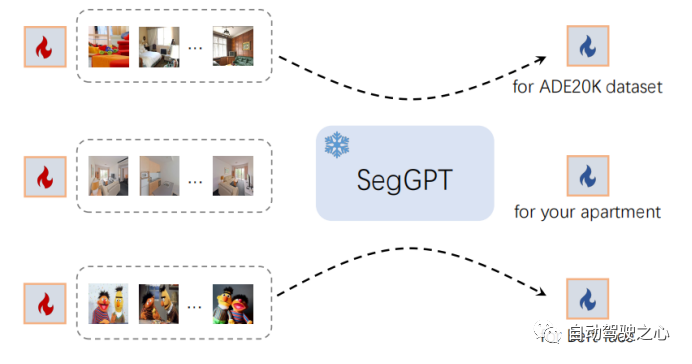
3.1.3.In-Context Tuning
SegGPT 能够在不更新模型参数的情况下适应独特的用例。我们冻结整个模型并初始化一个可学习的图像张量作为输入上下文。在训练期间只更新这个可学习的image的vector。其余的训练保持不变,例如,相同的损失函数。tuning后,作者将学习到的image张量取出来,作为特定应用的即插即用的keys。
3.2.实验
4.SEEM
SEEM是一种可提示的交互式模型,通过整合可学习的记忆提示以通过掩码引导的交叉注意力保留对话历史信息,可以一次性在图像中对所有地方的所有内容进行分割,包括语义、实例和全景分割,同时也支持各种 prompt 类型和它们的任意组合。
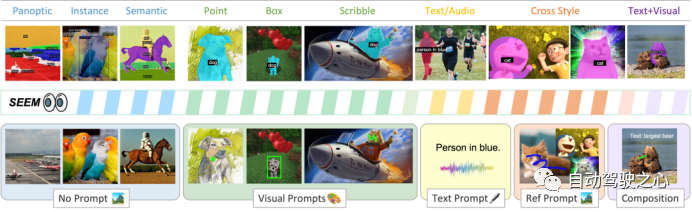
作者指出,SEEM 有以下 4 个亮点:
多功能性(Versatile):处理各种类型的 prompt ,例如点击、框选、多边形、涂鸦、文本和参考图像;
组合式(Compositional):处理 prompt 的任何组合;
交互性(Interactive):与用户多轮交互,得益于 SEEM 的记忆 prompt 来存储会话历史记录;
语义感知(Semantic-aware):为任何预测的掩码提供语义标签。
4.1.方法
SEEM 模型采用了一种通用的编码器-解码器架构,主要关注 query 和 prompt 之间的复杂交互。模型由文本编码器和视觉采样器组成。文本和视觉 prompt 被编码成可学习的查询,然后送入 SEEM 模型中,并输出 Mask 和语义标签。视觉 prompt 被编码成池化图像特征,然后在 SEEM 解码器中使用 Self-Attention 和 Cross-Attention。如图 (a) 所示:
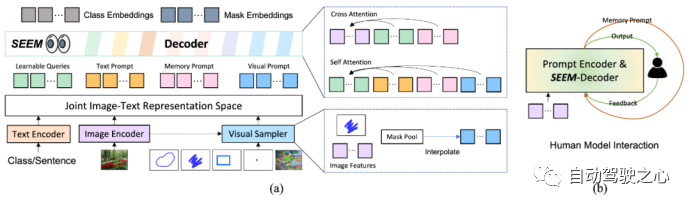
SEEM 与人之间的多轮交互如图 (b),主要包括以下 3 个步骤:
人给出 prompt;
模型向人发送预测结果;
模型更新记忆 prompt。
4.1.1.多功能
除了文本输入外,SEEM 还引入了视觉提示 来处理所有的非文本输入,例如点、框、涂鸦和另一幅图像的区域引用等。
当文本提示无法准确识别正确的分割区域时,非文本提示就能够提供有用的补充信息,帮助准确定位分割区域。以往的交互式分割方法通常将空间查询转换为掩模,然后将它们馈送到图像骨干网络中,或者针对每种输入类型(点、框)使用不同的提示编码器。然而,这些方法存在重量过大或难以泛化的问题。
为了解决这些问题,SEEM 提出了使用视觉提示来统一所有非文本输入。这些视觉提示以令牌的形式统一表示,并位于同一视觉嵌入空间中,这样就可以使用同一种方法来处理所有非文本输入。为了提取这些视觉提示的特征,该模型还引入了一个称为“视觉采样器”的方法,用于从输入图像或引用图像的特征映射中提取特定位置的特征。
此外,SEEM 还通过全景和引用分割来持续学习通用的视觉-语义空间,使得视觉提示与文本提示能够自然地对齐,从而更好地指导分割过程。在学习语义标签时,提示特征与文本提示映射到相同的空间以计算相似度矩阵,从而更好地协同完成分割任务。
4.1.2.可组合
用户可以使用不同或组合的输入类型表达其意图,因此在实际应用中,组合式提示方法至关重要。
然而,在模型训练时会遇到两个问题。首先,训练数据通常只涵盖一种交互类型(例如,无、文本、视觉)。其次,虽然我们已经使用视觉提示来统一所有非文本提示并将它们与文本提示对齐,但它们的嵌入空间仍然本质上不同。
为了解决这个问题,本文提出了将不同类型的提示与不同的输出进行匹配的方法。在模型训练后,SEEM 模型变得熟悉了所有提示类型,并支持各种组合方式,例如无提示、单提示类型或同时使用视觉和文本提示。值得注意的是,即使是从未像这样训练过的样本,视觉和文本提示也可以简单地连接并馈送到 SEEM 解码器中。
4.1.3.可交互
SEEM 通过引入记忆提示来进行多轮交互式分割,使得分割结果得到进一步优化。记忆提示是用来传递先前迭代中的分割结果,将历史信息编码到模型中,以在当前轮次中使用。
不同于之前的工作使用一个网络来编码掩模,SEEM 采用掩模引导的交叉注意力机制来编码历史信息,这可以更有效地利用分割历史信息来进行下一轮次的优化。值得注意的是,这种方法也可以扩展到同时进行多个对象的交互式分割。
4.1.4.语义感知
与之前的类别无关的交互式分割方法不同,SEEM 将语义标签应用于来自所有类型提示组合的掩码,因为它的视觉提示特征与文本特征在一个联合视觉-语义空间中是对齐的。
在训练过程中,虽然没有为交互式分割训练任何语义标签,但是由于联合视觉-语义空间的存在,掩膜嵌入(mask embeddings)和 视觉取样器 (visual sampler)之间的相似度矩阵可以被计算出来,从而使得计算出的 logits 可以很好的对齐。
这样,在推理过程中,查询图像就可以汇集多个示例的信息。
4.2.实验
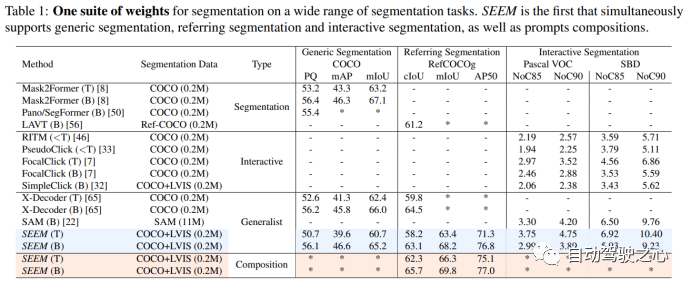
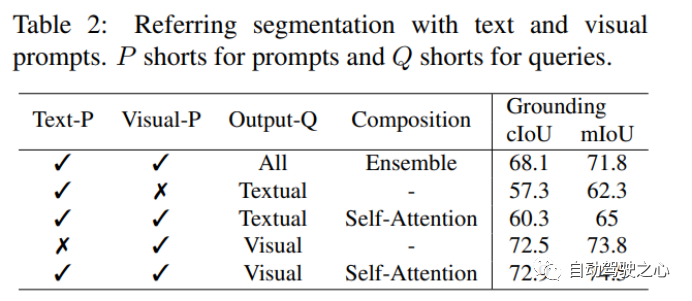
Visual 比 Textual 效果更显著,当使用 Visual + Textual 进行提示时,IOU 精度达到了最高。

(一)视频课程来了!
自动驾驶之心为大家汇集了毫米波雷达视觉融合、高精地图、BEV感知、传感器标定、传感器部署、自动驾驶协同感知、语义分割、自动驾驶仿真、L4感知、决策规划、轨迹预测等多个方向学习视频,欢迎大家自取(扫码进入学习)

(扫码学习最新视频)
视频官网:www.zdjszx.com
(二)国内首个自动驾驶学习社区
近1000人的交流社区,和20+自动驾驶技术栈学习路线,想要了解更多自动驾驶感知(分类、检测、分割、关键点、车道线、3D目标检测、Occpuancy、多传感器融合、目标跟踪、光流估计、轨迹预测)、自动驾驶定位建图(SLAM、高精地图)、自动驾驶规划控制、领域技术方案、AI模型部署落地实战、行业动态、岗位发布,欢迎扫描下方二维码,加入自动驾驶之心知识星球,这是一个真正有干货的地方,与领域大佬交流入门、学习、工作、跳槽上的各类难题,日常分享论文+代码+视频,期待交流!

(三)【自动驾驶之心】全栈技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦目标检测、语义分割、全景分割、实例分割、关键点检测、车道线、目标跟踪、3D目标检测、BEV感知、多传感器融合、SLAM、光流估计、深度估计、轨迹预测、高精地图、NeRF、规划控制、模型部署落地、自动驾驶仿真测试、产品经理、硬件配置、AI求职交流等方向;

添加汽车人助理微信邀请入群
备注:学校/公司+方向+昵称