0.ABSTRACT
0. 1逐句翻译
Deep learning has been actively studied for time series forecasting, and the mainstream paradigm is based on the end-to-end training of neural network architectures, ranging from classical LSTM/RNNs to more recent TCNs and Transformers.
深度学习在时间序列预测方面已经得到了积极的研究,主流的范式是基于神经网络体系结构的端到端训练,从经典的LSTM/ rnn到最近的tns和Transformers。
Motivated by the recent success of representation learning in computer vision and natural language processing, we argue that a more promising paradigm for time series forecasting, is to first learn disentangled feature representations, followed by a simple regression fine-tuning step – we justify such a paradigm from a causal perspective.
受最近计算机视觉和自然语言处理中表示学习的成功激励,我们认为时间序列预测更有前途的范式是,首先学习解纠缠的特征表示,然后是简单的回归微调步骤——我们从因果关系的角度证明这样的范式。
(目前我理解这里的意思是首先纠正每个点的表征结果,再进行微调)
Following this principle, we propose a new time series representation learning framework for long sequence time series forecasting named CoST, which applies contrastive learning methods to learn disentangled seasonal-trend representations.
遵循这一原则,我们提出了一种用于长序列时间序列预测的时间序列表示学习框架CoST,该框架采用对比学习方法来学习分离的节趋势表示。
CoST comprises both time domain and frequency domain contrastive losses to learn discriminative trend and seasonal representations, respectively.
CoST 包括时域和频域的对比损失,分别用来学习判别趋势和 seasonal 表征(这里季节性的表征大约指的是周期性表征)。
Extensive experiments on real-world datasets show that CoST consistently outperforms the state-of-the-art methods by a considerable margin, achieving a 21.3% improvement in MSE on multivariate benchmarks.
在真实数据集上的大量实验表明,CoST始终在相当大的范围内优于最先进的方法,在多元基准测试中实现了21.3%的MSE改进。
It is also robust to various choices of backbone encoders, as well as downstream regressors.
它对各种骨干编码器的选择,以及下游回归量也具有鲁棒性。
Code is available at https://github.com/salesforce/CoS
0.2总结
- 1.首先我们首先清楚的事情就是一个序列具有时域和频域信息,如果我们采用单一的网络来学习这个东西显然不太合理,因此我们需要两个网络来学习这个东西。
- 2.为了解决这个问题这篇论文将一个序列分成趋势和季节性表征(我个人理解这里可以称为周期性)来进行学习具体如下:
1 INTRODUCTION
1.1 逐句翻译
第一段(介绍序列流预测的事情,现在都用强有力的非线性层来进行学习并取得好效果)
Time series forecasting has been widely applied to various domains,such as electricity pricing (Cuaresma et al., 2004), demand forecasting (Carbonneau et al., 2008), capacity planning and management(Kim, 2003), and anomaly detection (Laptev et al., 2017).
时间序列预测已广泛应用于各个领域,如电力定价(Cuaresma等人,2004),需求预测(Carbonneau等人,2008),容量规划和管理(Kim, 2003),以及异常检测(Laptev等人,2017)。
Recently, there has been a surge of efforts applying deep learning for forecasting (Wen et al., 2017; Bai et al., 2018; Zhou et al., 2021), and owing to the increase in data availability and computational resources, these approaches have offered promising performance over conventional methods in forecasting literature.
最近,将深度学习应用于预测的努力激增(Wen et al., 2017;Bai等人,2018;Zhou等人,2021年),由于数据可用性和计算资源的增加,这些方法在预测文献中比传统方法提供了有前景的性能。
Compared to conventional approaches, these methods are able to jointly learn feature representations and the prediction function (or forecasting function) bystacking a series of non-linear layers to perform feature extraction,followed by a regression layer focused on forecasting.
与传统方法相比,这些方法可以通过叠加一系列非线性层来进行特征提取,然后建立以预测为重点的回归层,从而共同学习特征表示和预测函数(或预测函数)。
第二段(但是这些逐渐复杂的网络,加剧了过拟合等问题,因此本文提出了一个返璞归真的方法)
However, jointly learning these layers end-to-end from observed data may lead to the model over-fitting and capturing spurious correlations of the unpredictable noise contained in the observed data.
然而,从观测数据中端到端的联合学习这些层可能会导致模型过拟合和捕获观测数据中包含的不可预测噪声的虚假相关性。(虽然他们学习能力强,但是他们更容易过拟合)
The situation is exacerbated when the learned representations are entangled – when a single dimension of the feature representation encodes information from multiple local independent modules of the data-generating process – and a local independent module experiences a distribution shift.
当学习到的表示纠缠在一起时——当特征表示的一个维度对来自数据生成过程中的多个局部独立模块的信息进行编码时——并且一个局部独立模块经历分布转移时,这种情况会加剧。(作者认为一个点表示太多信息时,过拟合会加剧)
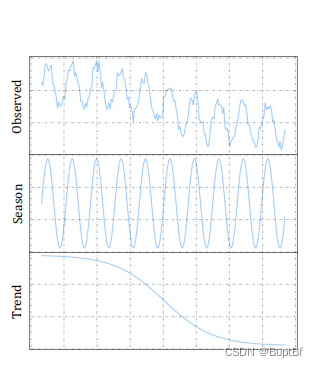
Figure 1 is an example of such a case, where the observed time series is generated by a seasonal module and nonlinear trend module.
图1就是这样一个例子,其中观测到的时间序列由季节模块和非线性趋势模块生成。
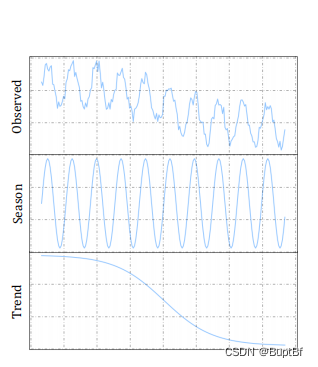
If we know that the seasonal module has experienced a distribution shift, we could still makes a reasonable prediction based on the invariant trend module.
如果我们知道季节模块已经发生了分布转移,我们仍然可以基于不变趋势模块进行合理的预测。
However, if we learn an entangled feature representation from the observed data, it would be challenging for the learned model to handle this distribution shift, even if it only happens in a local component of the data-generating process.
然而,如果我们从观察到的数据中学习一个纠缠的特征表示,对于学习到的模型来说,处理这种分布转移将是一个挑战,即使它只发生在数据生成过程的一个局部组件中。
In summary, the learned representations and prediction associations from the end-to-end training approach are unable to transfer nor generalize well when the data is generated from a non-stationary environment, a very common scenario in the time series analysis.
综上所述,当数据来自非平稳环境(时间序列分析中非常常见的场景)时,从端到端训练方法学习到的表示和预测关联无法很好地传递和一般化。
Therefore, in this work, we take a step back and aim to learn disentangled seasonal-trend representations which are more useful for time series forecasting.
因此,在这项工作中,我们退一步,旨在学习解开的季节和趋势表示,这是更有用的时间序列预测。
(这里作者大约是在说,周期性和变化趋势更加适合去表征一个序列的信息)
第三段(seasonal-trend 表征是必要的、稳定的,作者用对比学习再次增加其抗干扰能力)
To achieve this goal, we leverage the idea of structural time series models (Scott & Varian, 2015;Qiu et al., 2018), which formulates time series as a sum of trend, seasonal and error variables, and exploit such prior knowledge to learn time series representations.
为了实现这一目标,我们利用了结构性时间序列模型的思想(Scott & Varian, 2015;Qiu等人,2018),将时间序列构建为趋势、季节和误差变量的和,并利用这些先验知识学习时间序列表示。
First, we present the necessity of learning disentangled seasonal-trend representations through a causal lens, and demonstrate that such representations are robust to interventions on the error variable.
首先,我们通过因果透镜提出学习解纠缠的季节趋势表示的必要性,并证明这种表示对误差变量的干预是稳健的。(大约就是说这种 seasonal-trend 表征是必要的、稳定的)
Then, inspired by Mitrovic et al. (2020), we propose to simulate interventions on the error variable via data augmentations and learn the disentangled seasonal-trend representations via contrastive learning.
然后,受Mitrovic等人(2020)的启发,我们建议通过数据增强来模拟对误差变量的干预,并通过对比学习来学习解离的季节趋势表示。(用对比学习来增加抗干扰的能力)
第四段(简单讲述本文模型的具体框架)
Based on the above motivations, we propose a novel contrastive learning framework to learn disentangled seasonal-trend representations for the Long Sequence Time-series Forecasting (LSTF) task (Zhou et al., 2021).
于上述动机,我们提出了一种新的对比学习框架,用于学习长序列时间序列预测(LSTF)任务的解纠缠的季节趋势表示(Zhou et al., 2021)。
Specifically, CoST leverages inductive biases in the model architecture to learn disentangled seasonal-trend representations.
具体来说,CoST利用模型架构中的归纳偏差来学习分离的季节趋势表示。
CoST efficiently learns trend representations, mitigating the problem of lookback window selection by introducing a mixture of auto-regressive experts.
CoST有效地学习趋势表示,通过引入自回归专家的混合,减轻了向后看窗口选择的问题。
It also learns more powerful seasonal representations by leveraging a learnable Fourier layer which enables intra-frequency interactions. Both trend and seasonal representations are learned via contrastive loss functions.
它还通过利用可学习的傅里叶层来学习更强大的季节表征,从而实现频率内的相互作用。趋势和季节表征均通过对比损失函数学习。
The trend representations are learned in the time domain, whereas the seasonal representations are learned via a novel frequency domain contrastive loss which encourages discriminative seasonal representations and side steps the issue of determining the period of seasonal patterns present in the data.
趋势表示是在时间域学习的,而季节表示是通过一种新的频域对比损失学习的,它鼓励歧视性的季节表示,并回避了确定数据中呈现的季节模式周期的问题。
The contributions of our work are as follows:
-
We show via a causal perspective, the benefits of learning disentangled seasonal-trend representations for time series forecasting via contrastive learning.
-
We propose CoST, a time series representation learning approach which leverages inductive biases in the model architecture to learn disentangled seasonal and trend representations, as well as incorporating a novel frequency domain contrastive loss to encourage discriminative seasonal representations.
-
CoST outperforms existing state-of-the-art approaches by a considerable margin on realworld benchmarks – 21.3% improvement in MSE for the multivariate setting. We also
analyze the benefits of each proposed module, and establish that CoST is robust to various
choices of backbone encoders and downstream regressors via extensive ablation studies.
1.我们通过因果关系的视角展示了学习的好处,通过对比学习来解开时间序列预测的季节趋势表示。
2.我们提出了一种时间序列表示学习方法CoST,该方法利用模型架构中的归纳偏差来学习分离的季节和趋势表示,并加入了一种新的频域对比损失来鼓励区别的季节表示。
4. 成本比现有的最先进的方法在现实世界的基准上有相当大的差距- MSE提高21.3%
1.2 总结
- 1.序列流预测相关模型应用逐渐广泛(就是知道一段的情况,预测未来一段的情况)
- 2.序列模型逐渐变得更加复杂,但是这些更加复杂的非线性表征模型更容易过拟合
- 3.因此本文作者提出了seasonal-trend 表征,并证明了其是必要的、稳定的
- 4.为了增加模型的稳定性,本文作者使用了对比学习来增强其稳定性
2.SEASONAL-TREND REPRESENTATIONS FOR TIME SERIES
2.1 逐句翻译
Problem Formulation(问题定义)

问题定义:
- 1.这是一个序列流相关的问题输入是(T,m),其中m是维度
- 2.就是用之前的h个结果(h,m)预测未来的k个结果(k,m)
In this work, instead of jointly learning the representation and prediction association through g(·), we focus on learning feature representations from observed data, with the goal of improving predictive performance. Formally,we aim to learn a nonlinear feature embedding functionV = f(X), where X ∈ Rh×m and V ∈ Rh×d, to project m-dimensional raw signals into a d-dimensional latent space for each timestamp.
在这项工作中,我们没有通过g(·)共同学习表示和预测关联,而是专注于从观察数据中学习特征表示,以提高预测性能为目标。形式上,我们的目标是学习一个非线性特征嵌入函数V = f(X),其中X∈Rh×m和V∈Rh×d,将m维原始信号投影到每个时间戳的d维潜在空间。
Subsequently, the learned representation of the final timestamp vh is used as inputs for the downstream regressor of the forecasting task.
随后,学习到的最终时间戳vh表示被用作预测任务的下游回归变量的输入。
Disentangled Seasonal-Trend Representation Learning and Its Causal Interpretation (解开的季节趋势表示学习及其因果解释)
第一段(就是我们想要很好的传递信息,就得把各种数据信息来源拆分开)
As discussed in Bengio et al. (2013), complex data arise from the rich interaction of multiple sources – a good representation should be able to disentangle the various explanatory sources, making it robust to complex and richly structured variations. Not doing so may otherwise lead to capturing spurious features that do not transfer well under non i.i.d. data distribution settings.
正如Bengio等人(2013)所讨论的,复杂的数据来自于多个来源的丰富交互——一个好的表示应该能够分离各种解释来源,使其对复杂和结构丰富的变化稳健。如果不这样做,可能会导致捕获在非i.i.d.数据分布设置下不能很好地传输的虚假特征。
第二段(简单介绍本文说到的季节变化和趋势变化为什么可以预测,因为这两个是不受噪声影响的)
To achieve this goal, it is necessary to introduce structural priors for time series. Here, we borrow ideas from Bayesian Structural Time Series models (Scott & Varian, 2015; Qiu et al., 2018).
为了实现这一目标,有必要引入时间序列的结构先验。在这里,我们借鉴了贝叶斯结构时间序列模型(Scott & Varian, 2015;邱等人,2018)。
As illustrated in the causal graph in Figure 2, we assume that the observed time series data X is generated from the error variable E and the error-free latent variable X* . X* in turn, is generated from the trend variable T and seasonal variable S.
如图2的因果图所示,我们假设观测到的时间序列数据X是由误差变量E和无误差潜变量X生成的。X依次由趋势变量T和季节变量S生成。
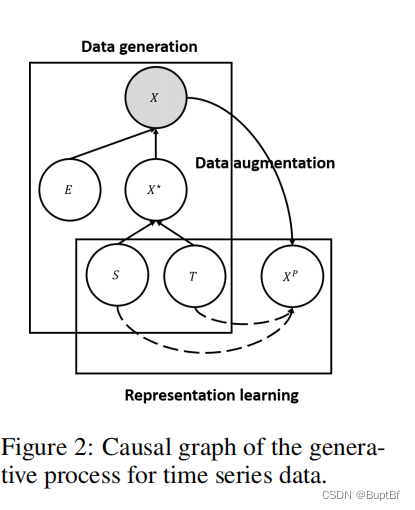
As E is not predictable, the optimal prediction can be achieved if we are able to uncover X* which only depends on T and S.
由于E是不可预测的,如果我们能够发现X*,只依赖于T和S,就可以实现最优的预测。
第三段(首先,作者注意到现在的网络都没有预测上面所述的浅层X*,不能应对噪声分布的变化)
Firstly, we highlight that existing work using end-to-end deep forecasting methods to directly model the time-lagged relationship and the multivariate interactions along the observed data X.
首先我们注意到现在存在的工作都使用端到端的深度网络取预测:直接建模时滞关系和沿着观测数据X的多元相互作用。
Unfortunately, each X includes unpredictable noise E, which might lead to capturing spurious correlations.
不幸的是,每个X都包含不可预测的噪声E,这可能导致捕获虚假的相关性。
Thus, we aim to learn the error-free latent variable X* .
因此,我们的目标是学习无误差潜变量X*。
第四段(周期性和趋势可以分离并学习并实现预测)
Secondly, by the independent mechanisms assumption (Peters et al., 2017; Parascandolo et al., 2018), we can see that the seasonal and trend modules do not influence or inform each other.
其次,通过独立机制假设(Peters et al., 2017;Parascandolo et al., 2018),我们可以看到季节和趋势模块互不影响也不相互通知。(周期和趋势互相不影响)
Therefore, even if one mechanism changes due to a distribution shift, the other remains unchanged.
因此,即使一种机制由于分配的转移而改变,另一种机制仍然保持不变。
The design of disentangling seasonality and trend leads to better transfer, or generalization in non-stationary environments.
分离季节性和趋势的设计可以在非平稳环境中更好地传递或泛化。
Furthermore, independent seasonal and trend mechanisms can be learned independently and be flexibly re-used and re-purposed.
此外,独立的季节和趋势机制可以独立学习,并可以灵活地重用和再利用。
第五段(因为这些周期性和趋势不受到噪声变化的干扰,所以加不同的噪声可以获得数据增强)
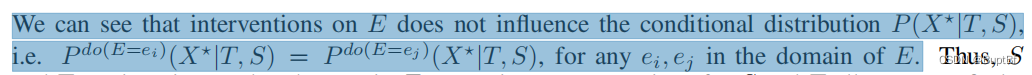
我们可以看到,对E的干预不影响X*关于T和S的条件分布
Thus, S and T are invariant under changes in E. Learning representations for S and T allows us to find a stable association with the optimal prediction (of X*) in terms of various types of errors.
因此,S和T在e的变化下是不变的。学习S和T的表示可以让我们在各种类型的错误方面找到与最佳预测(X*)的稳定关联。
Since the targets X* are unknown, we construct a proxy contrastive learning task inspired by Mitrovic et al. (2020).
由于目标X*是未知的,受Mitrovic等人(2020)的启发,我们构建了一个代理对比学习任务。
Specifically, we use data augmentations as interventions on the error E and learn invariant representations of T and S via contrastive learning.
具体来说,我们使用数据增强作为误差E的干预,并通过对比学习学习T和S的不变表示。
Since it is impossible to generate all possible variations of errors, we select three typical augmentations: scale, shift and jitter, which can simulate a large and diverse set of errors, beneficial for learning better representations.
由于不可能生成所有可能的误差变化,我们选择了三种典型的增广:缩放、移位和抖动,这可以模拟大量和多样化的误差集合,有利于学习更好的表示。