转载地址:RWKV解读:在Transformer的时代的新RNN - 知乎作者:徐传飞 在Transformer时代,介绍一个非Transformer架构的新网络——RWKV,RWKV是一种创新的深度学习网络架构,它将Transformer与RNN各自的优点相结合,同时实现高度并行化训练与高效推理,时间复杂度为线性… https://zhuanlan.zhihu.com/p/656323242
https://zhuanlan.zhihu.com/p/656323242
作者:徐传飞
在Transformer时代,介绍一个非Transformer架构的新网络——RWKV,RWKV是一种创新的深度学习网络架构,它将Transformer与RNN各自的优点相结合,同时实现高度并行化训练与高效推理,时间复杂度为线性复杂度,在长序列推理场景下具有优于Transformer的性能潜力。
一、RWKV简介
最开始自然语言使用RNN来建模,它是一种基于循环层的特征提取网络结构,循环层可以将前一个时间步的隐藏状态传递到下一个时间步,从而实现对自然语言的建模。
RNN由于存在循环结构(如下图所示),每个时间步的计算都要依赖上一个时间步的隐藏状态,导致计算复杂度较高,而且容易出现梯度消失或梯度爆炸的问题,导致训练效率低下,因此RNN网络扩展性不好。

RNN结构
Transformer在2017年由谷歌提出,是一种基于自注意力机制的特征提取网络结构,主要用于自然语言处理领域。自注意力机制可以对输入序列中的每个位置进行注意力计算,从而获取全局上下文信息。Transformer中的编码器和解码器可以实现机器翻译、文本生成等任务。Transformer核心是self-attention机制(如下图所示)。它是整句处理自然语言,因此它的训练效率较高,可并行化处理。Transformer缺点是计算复杂度高,O(N^2*d),其中N是序列长度、d为token嵌入的维度,它的时间复杂度对长序列不友好。

Self-attention机制
二、基本原理
基于RNN和Transformer问题,提出RWKV改进线性注意力机制,解决RNN难并行化的问题,并有RNN相似的时间复杂度以及与Transformer相近的效果。接下来,我们依次介绍线性Transformer和Attention Free Transformer引出RWKV的基本原理。
1、线性Transformer
线性Transformer(Linear Transformer)解决的问题是将Transformer中self-attention的计算复杂度由O(N^2)降低为O(N) ,其中N是序列长度。这对加快Transformer整体的加速非常重要。
Transformer中self-attention的典型计算如下:
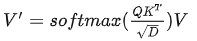
公式(1)
其中矩阵Q、K、V是由输入 x 经线性变化得到的query、key、value。如果用下标i来表示矩阵的第i行(如 Qi 表示矩阵 Q 的第i行),那么可以将公式(1)中的计算用如下形式抽象出来:

公式(2)
其中sim() 为抽象出的计算Query和Key相似度的函数。Linear Transformer采用了kernel来定义sim():

公式(3)
其中 ϕ 是一个特征映射函数,可根据情况自行设计。self-attention转化为:

公式(4)
原始Transformer的计算复杂度随序列长N呈二次方增长,这是因为attention的计算包含两层for循环,外层是对于每一个Query,我们需要计算它对应token的新表征;内层for循环是为了计算每一个Query对应的新表征,需要让该Query与每一个Key进行计算。 所以外层是 for q in Queries,内层是 for k in Keys。Queries数量和Keys数量都是N,所以复杂度是 O(N^2) 。而Linear Transformer,它只有外层for q in Queries这个循环了。因为求和项的计算与i无关,所以所有的 Qi 可以共享求和项的值。换言之,求和项的值可以只计算一次,然后存在内存中供所有 Qi 去使用。所以Linear Transformer的计算复杂度是O(N) 。引入以下两个新符号:

稍作变换,可以将Si 和Zi 写作递归形式:
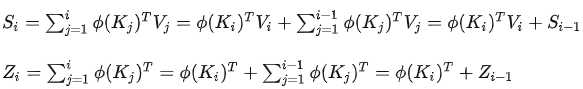
公式(5)
因此,在inference阶段,当需要计算第i时刻的输出时,Linear Transformer可以复用之前的状态 Si−1 和 Zi−1 ,再额外加上一个与当前时刻相关的计算量即可。而Transformer在计算第i时刻的输出时,它在第i-1个时刻的所有计算都无法被i时刻所复用。因此,Linear Transformer更加高效。
总结一下:
- Linear Transformer的计算复杂度为 O(N) (不考虑embedding的维度的情况下)。
- 如上述公式所示,因为Si可由Si−1计算得到(Zi同理),所以它可实现Sequential Decoding(先算S1,由S1算S2,以此类推)。能Sequential Decoding是让这类Transformer看起来像RNN的核心原因。
2、Attention Free Transformer
Attention Free Transformer (AFT) 是Apple公司提出的一种新型的神经网络模型,它在传统的 Transformer 模型的基础上,通过使用像Residual Connection之类的技术来消除注意力机制,从而减少计算量和提升性能。AFT的Decoder形式:

公式(6)
其中σ是sigmoid函数;⊙是逐元素相乘(element-wise product); wi,j是待训练的参数。AFT采用的形式和上面的Linear Transformer不一样。 首先是attention score,Linear Transformer仍然是同Transformer一样,为每一个Value赋予一个weight。而AFT会为每个dimension赋予weight。换言之,在Linear Transformer中,同一个Value中不同dimension的weight是一致的;而AFT同一Value中不同dimension的weight不同。此外,attention score的计算也变得格外简单,用K去加一个可训练的bias。Q的用法很像一个gate。
可以很容易仿照公式(5)把AFT也写成递归形式,这样容易看出,AFT也可以像Linear Transformer,在inference阶段复用前面时刻的计算结果,表现如RNN形式,从而相比于Transformer变得更加高效。
3、RWKV的网络架构
RWKV的特点如下:
- 改造AFT,通过Liner Transformer变换将self-attention复杂度由O(N^2)降为 O(N) 。
- 保留AFT简单的“attention”形式和Sequential Decoding,具有RNN表现形式。
RWKV网络整体架构如下:

RWKV网络架构
首先看time-mixing block。time-mixing的目的是“global interaction”,对应于Transformer中的self-attention。
- R 表示过去的信息,用 Sigmoid 激活,遗忘机制。
- W 和相对位置有关,且 Channel Wise d 维。 U 对当前位置信号的补偿。
- WKV 类似 Attention 功能,对位置 t ,表达了过去可学习的加权和。
其中使用到的R、K、V对应于AFT(或Transformer)中的Q、K、V。也就是说,K、V的含义可以强行看作一致,把R当做Q来处理就行。
只是RKV的计算方法有点变化:

公式(7)
R、K、V的计算和Transformer的区别是,作为计算RKV(QKV)的输入的x不再是当前token的embedding,而是当前token与上一个token embedding的加权和。
然后是最重要的"attention"用了如下方法计算:

公式(8)
需要拿着这个公式和AFT的公式()去仔细对比。容易发现,改动是两点:
- 原来的依靠绝对位置的偏置wi,j没有了,改成了相对位置,并且只有一个参数w向量需要训练。
- 对当前位置单独处理,增加了参数u。
公式(8)也可以写成递归形式,这就让RWKV兼顾了Linear Transformer的O(N)以及AFT的简洁。time-mixing block的最终输出:

公式(9)
channel-mixing block根据time-mixing block的输出重新使用公式(7)去计算了一组新的R和K。然后再计算最终输出如下:

公式(10)
RWKV架构被设计为Transformer和RNN的融合体,与传统的RNN相比,它具有稳定的梯度和Transformer更深的架构的优势,同时在推理中也会比较高效。
三、实验效果
RWKV网络与不同类型的Transformer性能的实验结果对比如下图所示。RWKV时间消耗随序列长度是线性增加,且时间消耗远小于各种类型的Transformer。

性能对比
RWKV与Transformer预训练模型(BLOOM、OPT、Pythia)效果对比测试如下图所示。在六个基准测试中(Winogrande、PIQA、ARC-C、ARC-E、LAMBADA 和 SciQ),RWKV 与开源二次复杂度 transformer 模型 Pythia、OPT 和 BLOOM 具有相当的竞争力。RWKV 甚至在四个任务(PIQA、OBQA、ARC-E 和 COPA)中胜过了 Pythia 和 GPT-Neo。

效果对比
下图显示,增加上下文长度会导致 Pile 上的测试损失降低,这表明 RWKV 能够有效利用较长的上下文信息。

四、总结与展望
Transformer网络的内存和计算复杂性随序列长度二次方缩放,而循环神经网络RNN只需线性缩放。但RNN在并行化和可扩展性方面存在限制从而难以达到Transformer的能力。RWKV-LM/ChatRWKV是基于RWKV预训练的非Transformer架构的百亿级参数语言基础模型/对话模型,具有与Transformer架构LLM相当的能力并且计算效率更高(计算快,资源占用小)。
由于过去信息保存在一个历史向量中,因此对长依赖关系的能力会比原始 Attention 差。同样的,对Prompt的鲁棒性比Transformer架构差。线性attention 用element wise计算替代原始Transformer的矩阵乘计算,计算复杂度的理论优势,针对昇腾架构并非优势,而线性attention的空间复杂度会受到 flash attention。
相比于Transformer网络,RWKV生态差距较大,如针对的加速库及算法等,RWKV能否发展为主流的神经网络还有待观察。