-
基本的产品活跃状态监控,留存分析、流失分析、新增变化、忠诚分析、渠道分析等。
-
基本信息获取,例如机型、网络类型、操作系统,IP地域等,绘制基础用户人群画像。
-
推荐系统,根据用户行为操作,为用户绘制兴趣画像,进行精准的兴趣推荐。
-
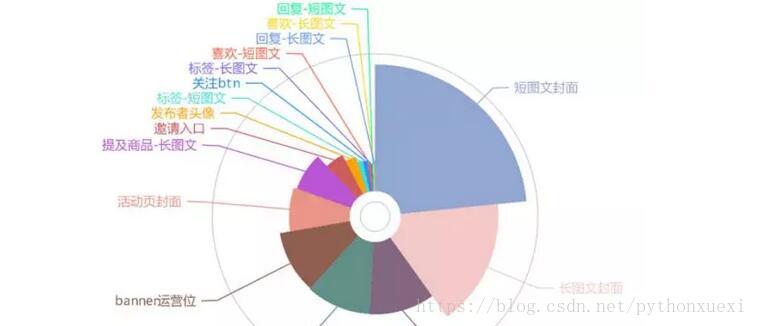
查看页面的按钮点击分布,提升主路径的转化效果,删减页面僵尸按钮,产品做减法,优化用户体验。
-
-
主路径流失分析,漏斗模型,提升转化效果。
-
搜索效果分析,掌握用户的搜索热点,帮助进行数据运营
-

其实还有很多很多其他数据方面的应用。
我们通过真实的基础数据收集,进一步的进行加工整理,能够从中获取很多有用的信息,用于精准化运营、洞察性运营,提升用户体验,优化我们的产品。
只要想象力足够,收集的信息足够完全,我们是可以通过数据做很多事情的。
但前提是收集的数据足够多,足够准确!
(2) 维护一张埋点数据编码表
说到收集的数据足够多,足够准确,我们维护了近一千个点位的操作数据收集。
相信对于第三方数据分析平台熟悉的童鞋,可能会有所了解。
除了之前提到的机型、操作系统、分辨率、ip、网络模式等基础数据的收集,跟操作严格绑定的有页面编号、内容id、用户id、操作类型、控件id等相关数据,共34个属性。
我们用一个excel表维护起所有的点位定义,进行属性编码化,维护起页面编码表、按钮控件编码表、操作类型编码表等等。
最终在我们这里展现的是一个近1000*34的上报维度表,后续所有的埋点以及点位测试,都是围绕于这一张点位上报表进行。
这也是数据测与研发测初期产生的“矛盾点”,量太他娘的大了。
(3) 为何不使用第三方数据分析平台?
或许有人问了,为何不使用第三方的数据分析平台呢?诸如友盟+、神策、GrowingIO等之类的。
其实使用多了你就会知道了,第三方的数据分析平台,能够给你带来的大部分都是一些常规性的分析,诸如流失、留存、渠道、用户成分等等。
想要做到更定制化,甚至对数据应用的更深、挖掘的更深,相对来说比较难的。
并且,对于部分对于数据保密性要求较高的公司来说,企业的数据上报的第三方的数据分析公司的服,务中,总是存在风险的。
在大数据人才市场紧迫的前期,很多中小型企业对于第三方数据分析平台的依赖会较大。
在大数据市场进一步发展之后,相信很大一部分企业都会建立起自己的数据团队,用于公司的全面数据化。
所以,从这个角度来说,埋点相关的体系建设也是一件不可避免的事。
而之前炒的略火的无埋点技术,从个人了解的信息来说,可能应对常规的数据分析工作应该是足够了。
但同样,想对数据做更多的深层挖掘,必然无法绕开对数据的精细收集。
(4) 原子操作上报而不是关系链上报。
此外,对于埋点体系的建设,有一个很重要的注意点就是:我们上报的一定是原子操作。
不过本身就是一个矛盾点所在,举个例子,如果我们需要对一个用户的真实操作路径分析,记录路径关系链,我们在做真实的路径转化时,就很方便,因为关系链路都以及记录下来了。
确实很多公司就是这么干的。
而如果记录的是原子操作,想要汇聚成一个访问链路,则需我们自己根据时间序列,把事件串起来,进行一步一步分析。
表面看起来,记录关系链对我们分析是更友好的,因为对于后期的关系跳转挖掘是很方便的。
但是,想要维护起关系链就很麻烦了,特别是对于那种产品迭代速度很快的产品,逻辑关系是经常变化的。
那么,你把逻辑关系一起上报,维护的成本就很大了。
而对于原子操作,我不care逻辑关系,我只需要操作了这个点位,我就上报这个点位的原子信息即可,有新增点位添加埋点即可,逻辑关系再怎么变化都不影响。
3 与研发之间的“爱恨情仇”
对于很多初建数据团队的公司来说,数据层面的很多事,很多人都无法理解,包括研发团队。
比如...
(1) 你们给我们增加了很多“额外的”工作量!
埋点的点位上报事件,对于业务端来说,并不是直接可见的,所以,很多人会认为这个事情是“额外的”工作量,又不是业务逻辑,有什么卵用呢,还这么多工作量。
特别是在前期,第一波埋点梳理的时候,数百个点位,将会花费客户端以及H5前端人员巨多的时间,看到数据编码表,直至眩晕!
在数据推行的前期,不止是研发团队,就连业务端的人员,对于数据的意识也没有想象中的了解。
所以,在开发团队,特别是客户端以及涉及到埋点的H5前端来说,花费这么多的人力去做数据收集、埋点这个事情,就变得极其的不可理解,甚至是微有“抵触”的。
(2) 数据团队的“窦娥之冤”!
但对于数据团队来说,自己也不是业务团队呀,说白了这些数据收集过来,自己又不是最终受益者,数据的加工处理者而已,也是个苦力。
所以,老实讲来,数据团队也挺“冤”的。
打个简单的比喻,一般的业务开发工作就如耕种一些产出能直接食用的作物,用户采摘了就能直接食用。
而对于埋点,就如耕种的是麦子,采摘的人是面粉加工人员,采摘了之后需要加工成面粉甚至是做成面包,面食,用户才可以食用。
所以,对于对底端“耕地”的开发人员来说,能够直接提供给用户,种了次数比较多轻车熟路的,能够量化成果的其他“作物”是比较喜欢的。
而离用户距离较远,用户不能直接食用,且第一次种的“麦子”,就相对没有这么喜欢了。
(3) 到底该谁来测试数据埋点的完整性?
关于数据埋点,还有一个比较巨大的争执点:谁来为埋点数据的准确性以及完整性买单。
数据埋点一旦出现故障,整个数据化运营线就崩了,特别是在运营人员&各个决策者在形成以数据量化结果,以数据驱动决策的习惯之后。
但是,之前我们也说过了,点位的繁多,谁参与测试都会崩溃。各种“矛盾心理”,让数据上报是否完全、是否准确这个事情变得更难办。
研发团队不想在埋点这个事情上,浪费过多的人力物力;测试团队对于数据技能要求略高的埋点完整性测试,显得略微乏力;而对于数据团队来说,无法将更多的人力放在每次繁重而又略显枯燥的测试工作中。
以上种种,造成了几个团队之间为“埋点”的事情,“忧心忡忡”,“爱恨交加”!
相信很大一部分开始涉及数据化的公司,都会遇到这个矛盾点。
那么,如何解决这个问题,其实说白了就是跨团队合作的问题。
4 如何有效跨团队的合作
(1) 合作事务的边界之争。
在跨团队合作的事情上,一个需要注意的问题就是确定事务的边界。
一旦协商了边界,确定了好双方的边界,双方按照约定好的边界交互,并行进行开发即可。
没必要跨界好心多做一些事情,因为这会扰乱友方团队的规划;当然,更不能将自己要做的事情打折,这会由于己方耽搁整个项目的进度。
而双方一旦确立边界,严格按照边界进行开展即可,当然,如果遇到问题也是可以协商的,但绝不是推诿。
-
数据团队负责为客户端以及H5前端人员提供上报接口,制定接口规范,制定埋点体系规范,确定什么地方该上报,该上报什么数据。
他无需关注这些基础信息怎么获取,接口怎么调,数据怎么封装。
而客户端以及前端团队则需要根据埋点体系规划需求文档,在该上报的点位,按照文档获取到相关的信息,进行封装,调用上报接口进行上报即可。
他无需关注这个数据上报上去之后怎么存储,怎么清洗,怎么处理,怎么挖掘。
双方的边界就在于埋点上报接口,只要双方确定这个问题无误即可开展埋点上报的合作。
所以,就个人认为来说,开发人员不应该把因为页面逻辑结构杂乱,不好埋点的问题抛给数据,这属于内部技术能解决的问题,但可以协商暂缓或者说换其他方案,而不是单纯的把问题抛出来。
每个人应该把边界内的事情做好,而不是抛给友队。
再来回想一下关于数据埋点完整性测试的问题。一旦出现故障,对于业务影响巨大,这是一个巨大的锅,该谁来背?
测试团队对于这种数据埋点完整性测试这种对于垂直技能要求性略高的活,不太想接,也无力接。
客户端团队&前端团队倒是可以通过抓包,拿到他们调用接口封装的数据,校验准确性,但是他们也不想花费过多的时间在上面。
而数据团队虽然说是数据的直接接受者,但并不想为埋点端的失误背过多的书,但又是故障的第一压力承受者。
所以,几方下来,很矛盾。
但最终问题是需要解决的,并且也解决了。
埋点完整性测试的工作由数据与研发一同担保,研发需要为埋点失误买单,而数据则做测试达标的校验人,如果出现问题,同样是需要背负责任,并且产品项目端也参与进来,将测试流程纳入发布流程中,预留足够的时间去埋点以及测试。
多方来保证埋点的完整性,确保将风险降低到最低,这是一个合理的处理方式。
当然,为了确保数据完整性测试更加的效率、准确,数据团队开发了埋点测试服务,实时的根据操作动态反馈上报的数据,进行校验,进一步提升了埋点这个事情的效率。
(2) 适当的站在对方角度上思考问题。
其次,在跨部门合作的项目中,能够尽量站在的为友队角度思考问题,这是一个良性的状态。
还是以此举些栗子。
其实一开始埋点体系的规划中,上报中一些跳转的上报,是携带父子跳转逻辑关系的,确实有不少埋点是这样设计的,另一方面也是后续追踪数据更方便。
其中一个客户端开发童鞋反馈说,这种记录逻辑关系上报,一旦业务逻辑关系变化,涉及到埋点上报都需要重写,对于客户端的童鞋来说,是一个巨大的工作量。
后续进行了详细的思考之后,我决定改变体系上报的规划,这也就有了上面的那个注意点,数据的原子上报,这样客户端的童鞋只需要维护单一的页面上报即可,而不需要管下一个面跳转到哪里。
虽然,这样做对加大数据端对数据的处理复杂度,但是我们不能单纯的为了自己方便,而增加其他友队的工作量。
需要从实际的情况出发,进行问题的思考。
在后续的埋点项目中,数据测也会与业务端进行充分的沟通,确保一些不重要的点位进行移除,以降低客户端以及前端童鞋的埋点工作量。
而客户端与前端的童鞋在埋点工作上,也更尽责,更加配合,使得埋点的错误率大大的降低,埋点完整性测试的花费大大的降低。
所以,整个埋点的事情,从一开始的略微“争锋相对”,到后面虽然不能说是“相亲相爱”,但最起码算是有共识,算是“通力合作”,在一起为做好一件事情而努力!
整个事情的推动,需要我们设身处地的去思考,想办法的去最理性的解决问题,这才是跨团队合作的真谛!
(3) 关于跨团队合作项目推动执行的思考。
在整个事件的过程中,对于跨团队项目的推进这个事情上,有很深的感悟。
还是数据埋点的事,其实一开始之所以会走的这么艰难,还有一个重要的原因就是,一开始没有强需求方去推动,或者说没有项目管理的角色去把控。
因为数据化的建设,在前期整个公司都没有意识到问题的重要性。
所以,整个数据化的建设,包括数据意识的养成,都是数据团队在push的。
这也就造成了埋点这个项目,push方是数据团队,但又不是真的业务需求方,也不是项目管理方(我们的产品端把控项目进度以及整体规划)。
名不正言不顺,掌控不了整体的排期,所以整件事情才会不尴不尬。
所以,在业务团队对数据化的好处认识到一定程度上,我们将业务需求的驱动权交给了业务方,让业务方来决定哪些点位的优先级更高,这样研发团队更能体会到自己做的事情其实是很重要的,很多人care的,成就感与存在感。
其次,整个进程的把控交给项目规划方,也就是产品端做,产品端在整体排期中预留足够的时间去做数据埋点,而不是像之前那样,游离在项目把控之外。
这也是前期埋点质量得不到保证的一大原因,因为没有合理范围内的时间去做这件事。
而数据团队则作为业务团队与研发团队的桥梁,将实际的数据业务需求转换为可执行的埋点方案,push到研发测,最后再把控上报的质量。
所以,整个事情是多个部门协力在做,各司其职,业务端驱动,产品全局规划、数据进行需求转换以及把控质量、研发进行底层埋点。
只要多思考,多想想,找出问题所在,多尝试,问题总会解决的。
5 结语
基础的数据收集的越详细,后期对于数据应用的扩展就越方便。
因为你有足够多、足够详细的用户真实行为数据,能够让你更加充分、更加有依据的去解析用户的行为,进而为用户做更多有针对性的策略。
如何进行埋点体系的建设至关重要,每个细节的设计都是为了后续更方便的点位维护,以及应用挖掘方向的扩展。
期间,你也必然会遇到很多与其他团队协作方面的事,所以,也希望团队协作的一些想法能够给你带来些许帮助。
更多的相互理解、更理性的问题思考、更合理的分工搭配,都是跨团队项目合作更高效的前提。