机器学习——聚类算法k-means
常见的聚类算法,k-means算法(k-均值算法)由簇中样本的平均值来代表整个簇。
聚类分析概述
简单地描述, 聚类(Clustering)是将数据集划分为若干相似对象组成的多个组(group)或簇(cluster)的过程,使得 同一组中对象间的相似 度最大化,不同组中对象间的相似度最小化。或者说一个簇(cluster)就是由彼此相似的一组对象所构成的集合,不同簇中的对象通常不相似或相似度很低。

提示:以下是本篇文章正文内容,下面案例可供参考
一、k-means背景?
Ø1957年,斯图亚特·劳埃德最先提出这一标准算法,当初是作为一门应
用于脉码调制的技术
Ø 1965年, E.W.Forgy发表了一个本质上是相同的方法
Ø 1975年和1979年,Hartigan和Wong分别提出了一个更高效的版本
Ø 1982年,这一算法才在贝尔实验室被正式提出,命名为K-Means
二、k-means算法思想
初始随机给定K个簇中心,按照最邻近原则把待分类样本点分到各个簇。然后按平均法重新计算各个簇的质心,从而确定新的簇心。一直迭代,直到簇心的移动距离小于某个给定的值。

1.k-means聚类算法练习-1

解:下面步骤显示了对于给定的数据集k-means聚类算法的执行过程。
(1)根据题目,假设划分的两个簇分别为C1和C2,中心分别为(4,5)和(5,5),下面计算10个样本到这2个簇中心的距离,并将10个样本指派到与其最近的簇。
(2)第一轮迭代结果如下:
属于簇C1的样本有:{P7,P1,P2,P4,P5,P8}
属于簇C2的样本有:{P10,P3,P6,P9}
重新计算新的簇的中心,有:C1的中心为(3.5,5.167),C2的中心为(6.75,4.25)
(3)继续计算10个样本到新的簇的中心的距离,重新分配到新的簇中,第二轮迭代结果如下:
属于簇C1的样本有:{ P1,P2,P4,P5,P7,P10}
属于簇C2的样本有:{ P3,P6,P8,P9}
重新计算新的簇的中心,有:C1的中心为(3.67,5.83),C2的中心为(6.5,3.25)。
(4)继续计算10个样本到新的簇的中心的距离,重新分配到新的簇中,发现簇中心不再发生变化,算法终止。
2.算法练习-1代码实现
代码如下(示例):
"""
1.随机取k个中心点
2. 计算所有点到中心点的距离
将所有点 分别放入 中心点所在的簇
更新中心点
如果中心点不变 结束迭代
迭代
"""
import numpy as np
import matplotlib.pyplot as plt
#获取数据集
def loadDataSet(filename):
return np.loadtxt(filename,delimiter=",",dtype=np.float)
#取出k个中心点
def initCenters(dataset,k):
"""
返回的k个中心点
:param dataset:数据集
:param k:中心点的个数
:return:
"""
centersIndex = np.random.choice(len(dataset),k,replace=False)
return dataset[centersIndex]
#计算距离公式
def distance(x,y):
return np.sqrt(np.sum((x-y)**2))
#kmeans的核心算法
def kmeans(dataset,k):
"""
返回k个簇
:param dataset:
:param k:
:return:
"""
#初始化中心点
centers = initCenters(dataset,k)
n,m = dataset.shape
#用于存储每个样本属于哪个簇
clusters = np.full(n,np.nan)
#迭代 标志
flag = True
while flag:
flag = False
#计算所有点到簇中心的距离
for i in range(n):
minDist,clustersIndex = 99999999,0
for j in range(len(centers)):
dist = distance(dataset[i],centers[j])
if dist<minDist:
#为样本分簇
minDist = dist
clustersIndex = j
if clusters[i]!=clustersIndex:
clusters[i]=clustersIndex
flag = True
#更新簇中心
for i in range(k):
subdataset = dataset[np.where(clusters==i)]
centers[i] = np.mean(subdataset,axis=0)
return clusters,centers
#显示
def show(dataset,k,clusters,centers):
n,m = dataset.shape
if m>2:
print("维度大于2")
return 1
#根据簇不同 marker不同
colors = ["r","g","b","y"]
for i in range(n):
clusterIndex = clusters[i].astype(np.int)
plt.plot(dataset[i][0],dataset[i][1],color=colors[clusterIndex],marker="o")
for i in range(k):
plt.scatter(centers[i][0],centers[i][1],marker="s")
plt.show()
if __name__=="__main__":
dataset = loadDataSet("testSet.txt")
clusters,centers = kmeans(dataset,4)
show(dataset,4,clusters,centers)
k-means算法的评价准则:误差平方和准则
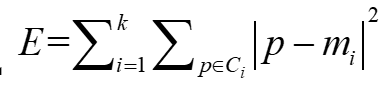
- k是簇的个数,P是簇Ci中的样本,mi是簇Ci的均值
–误差平方和达到最优(小)时,可以使各聚类的类内尽可能紧凑,而使各聚类之间尽可能分开。
– 对于同一个数据集,由于k-means算法对初始选取的聚类中心敏感,因此可用该准则评价聚类结果的优劣。
– 通常,对于任意一个数据集,k-means算法无法达到全局最优,只能达到局部最优。
k-means总结
• 优点:
– 可扩展性较好,算法复杂度为O(nkt)。
• 其中:n为样本个数,k是簇的个数,t是迭代次数。
• 缺点:
– 簇数目k需要事先给定,但非常难以选定;
– 初始聚类中心的选择对聚类结果有较大的影响;
– 不适合于发现非球状簇;
– 对噪声和离群点数据敏感。