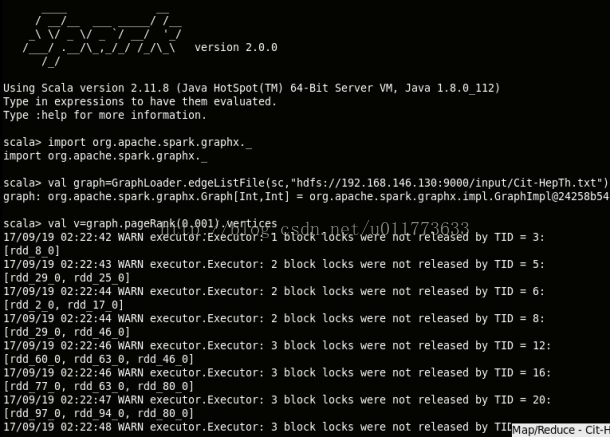
spark输出太多warning messages
WARN Executor: 2 block locks were not released by TID =
Lock release errors occur frequently in executor logs
原因:If there are any releasedLocks (after calling BlockManager.releaseAllLocksForTask earlier) and spark.storage.exceptionOnPinLeak is enabled (it is not by default) with no exception having been thrown while the task was running, a SparkException is thrown:
[releasedLocks] block locks were not released by TID = [taskId]:
[releasedLocks separated by comma]
Otherwise, if spark.storage.exceptionOnPinLeak is disabled or an exception was thrown by the task, the following WARN message is displayed in the logs instead:
WARN Executor: [releasedLocks] block locks were not released by TID = [taskId]:
[releasedLocks separated by comma]
Note If there are any releaseLocks, they lead to a SparkException or WARN message in the logs.
[jaceklaskowski/mastering-apache-spark-book/spark-executor-taskrunner.adoc]
mapWithState causes block lock warning?
The warning was added by: SPARK-12757 Add block-level read/write locks to BlockManager?
[connectedComponents() raises lots of warnings that say "block locks were not released by TID = ..."]
[Lock release errors occur frequently in executor logs]
解决:终于在调试log时候发现问题解决了
在简略Spark输出设置时[Spark安装和配置]修改过$SPARK_HOME/conf/log4j.properties.template文件只输出WARN信息,就算改成了ERROR,信息也还是会自动修改成WARN输出出来,不过多了一条提示:
Setting default log level to "WARN". To adjust logging level use sc.setLogLevel(newLevel).
就在这时发现了一个解决方案:
根据提示在代码中加入sc.setLogLevel('ERROR')就可以解决了!
from: http://blog.csdn.net/pipisorry/article/details/52916307
ref: