上一篇文章介绍了python连接hive的过程,通过地址+端口号访问到hive并对hive中的数据进行操作,这一篇文章介绍一下怎么通过windows本地pyspark+本地部署好的spark+远程虚拟机的hive,完成本地pyspark对hive的访问。
一.环境介绍
(1)关于pyspark
这个是之前就已经部署好的,本地安装了hadoop、scala、spark之后,配置好对应的系统环境变量,在python中下载好pyspark包,就可以了
(2)关于hive
这个是前几篇文章中介绍的hive部署,在虚拟机node01上完成了部署
二.pyspark连接hive
其实pyspark只是一个python接口,实际的连接hive操作是由spark完成的,也就是之前本地下载的spark,那么想要spark能够连接上hive,就需要将hive的一些配置文件放到spark中,让spark可以通过配置文件中的metastore.uris找到hive的元数据库,从而访问hive,在上一篇文章中提到了hive的hive-site.xml上配置了metastore的地址为node01的地址+端口号,那么将hive-site.xml放到spark中,spark就明白要到这个地址去找到hive啦。
<property>
<name>hive.metastore.uris</name>
<value>thrift://192.168.121.130:9083</value>
<description>Thrift URI for the remote metastore. Used by metastore client to connect to remote metastore.</description>
</property>
1.配置文件
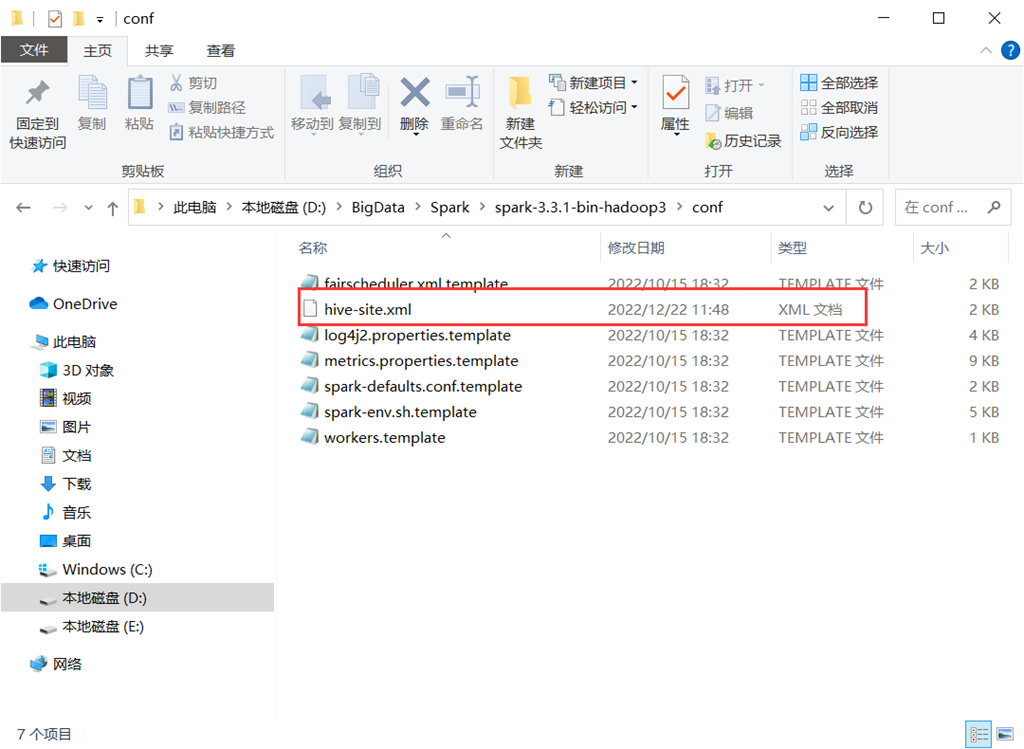
(1)将虚拟机上hive的conf文件夹下的hive-site.xml,复制到本地spark的conf文件夹中
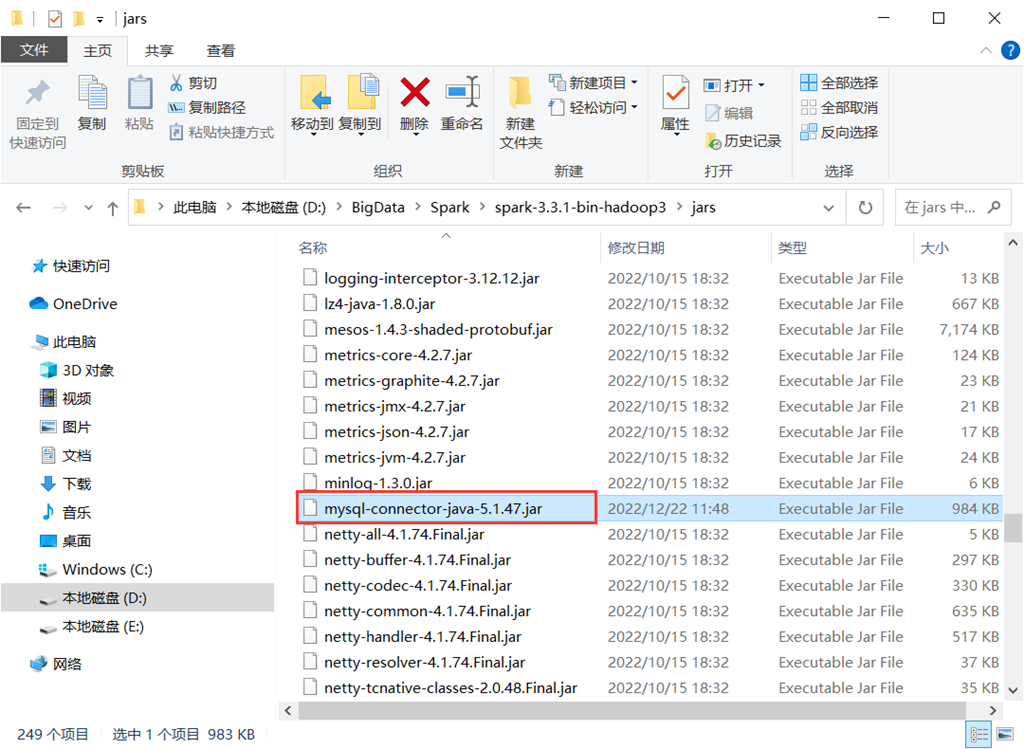
(2)将虚拟机上hive的lib文件夹下的mysql连接包mysql-connector-java-5.1.47(也是前面文章中部署hive时提到的),复制到本地spark的jars文件夹中
3.修改hosts
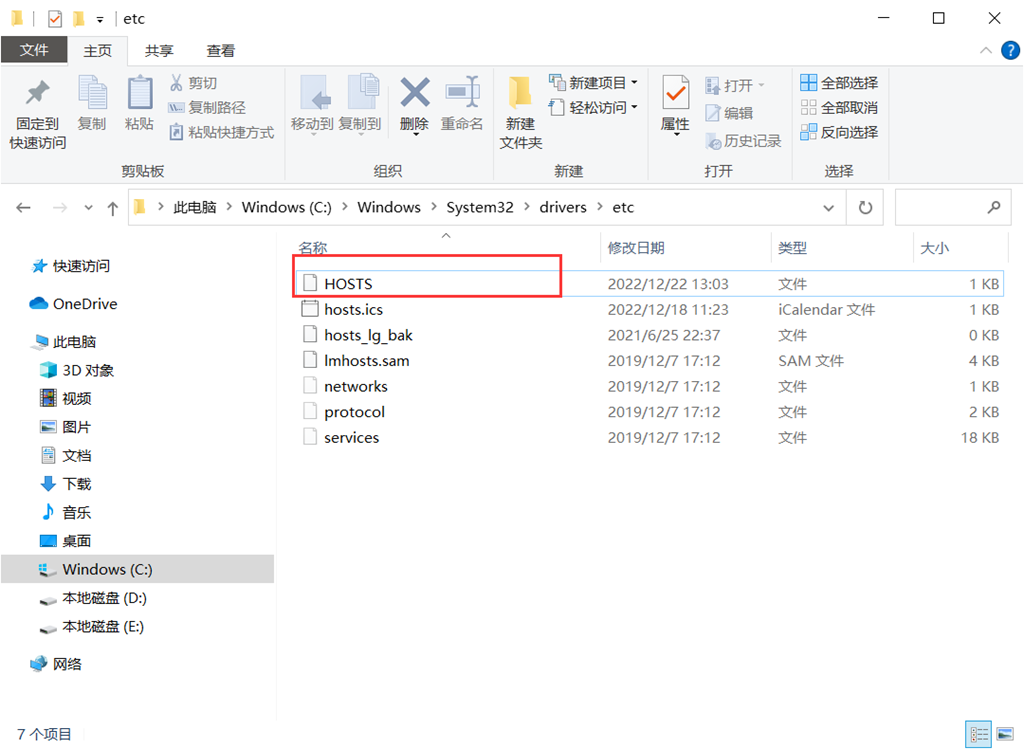
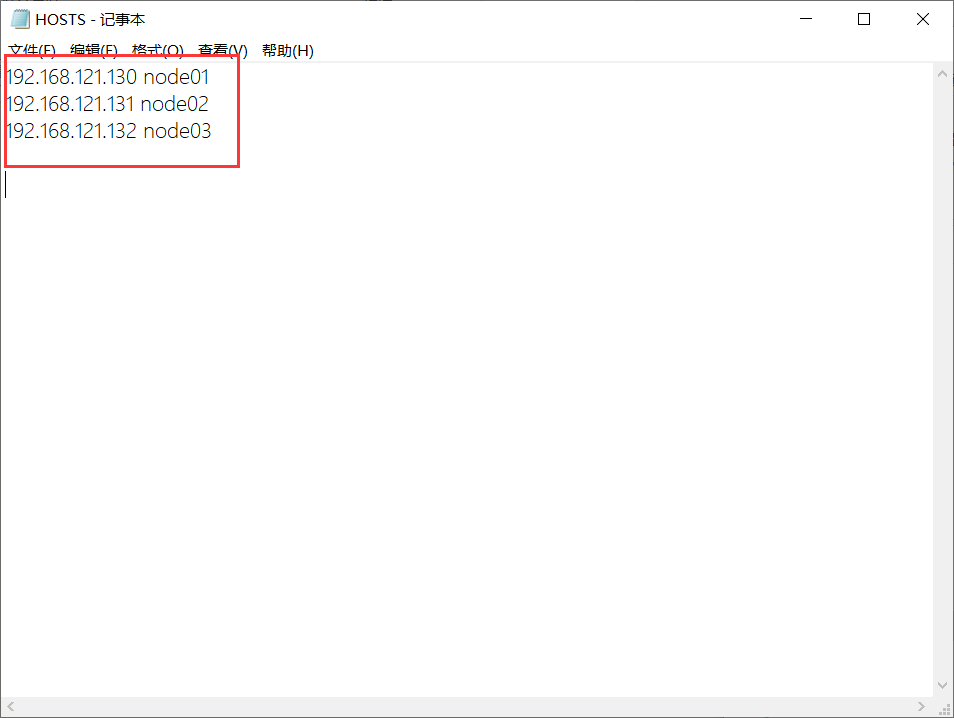
在C:\Windows\System32\drivers\etc中修改HOSTS文件,在下方添加虚拟机的地址
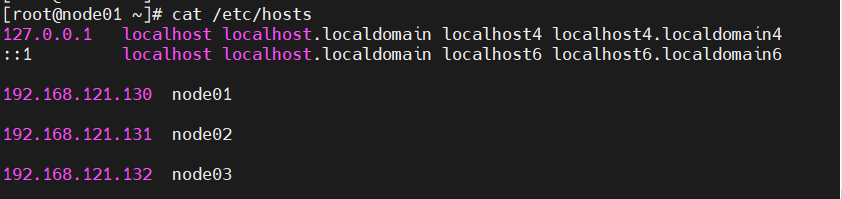
如果忘记了虚拟机服务器的地址,可以使用以下命令查看(也是前面在部署hive时就已经设置好了的)
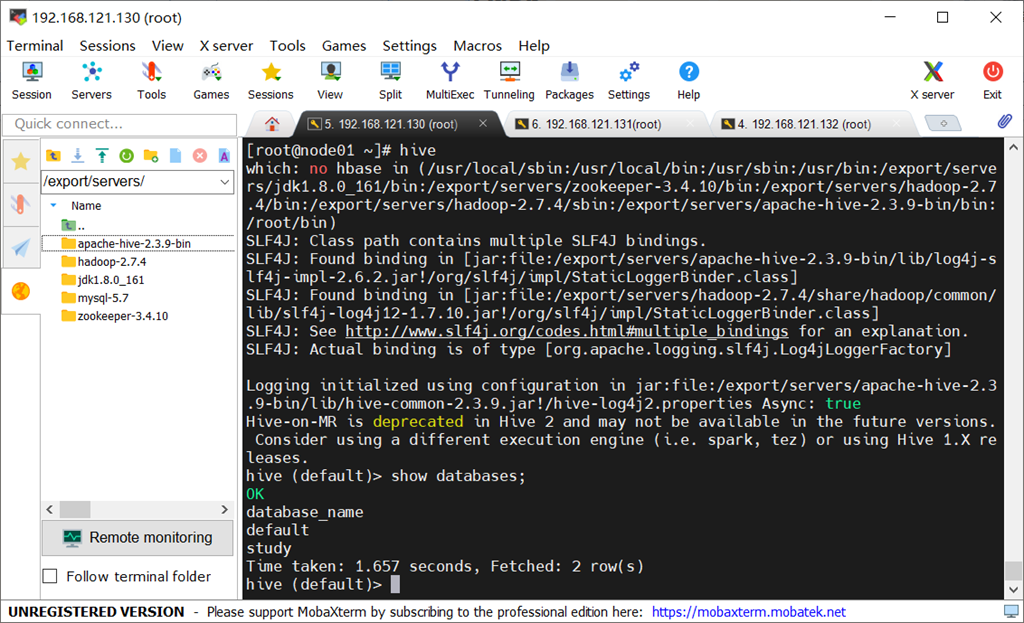
三.测试连接
在完成了上面的操作后,spark就已经可以访问到hive了,下面分别通过本地spark-shell和pyspark操作来查看是否配置成功
1.spark-shell
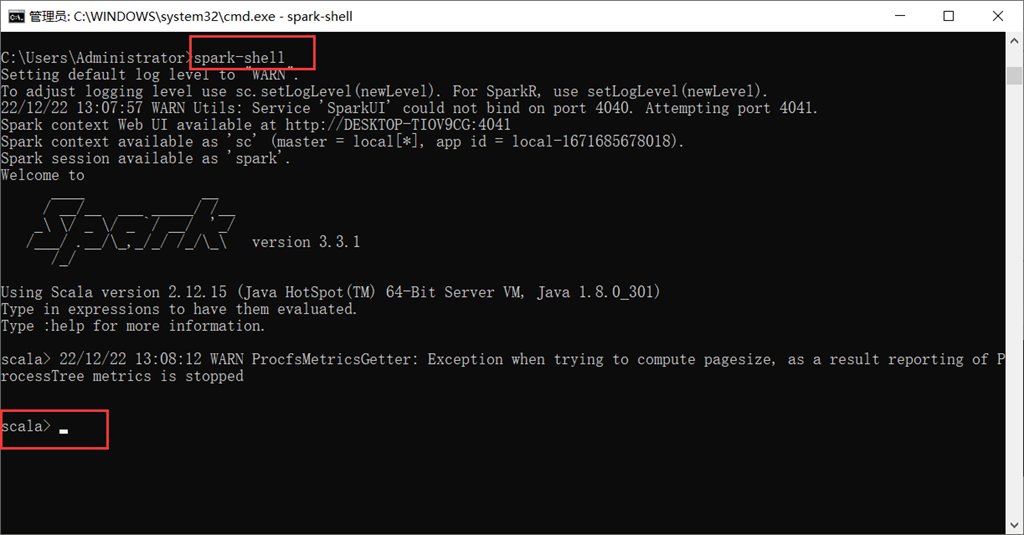
(1)进入spark-shell
直接命令行输入spark-shell(在配置好环境变量的情况下)
(2)语句
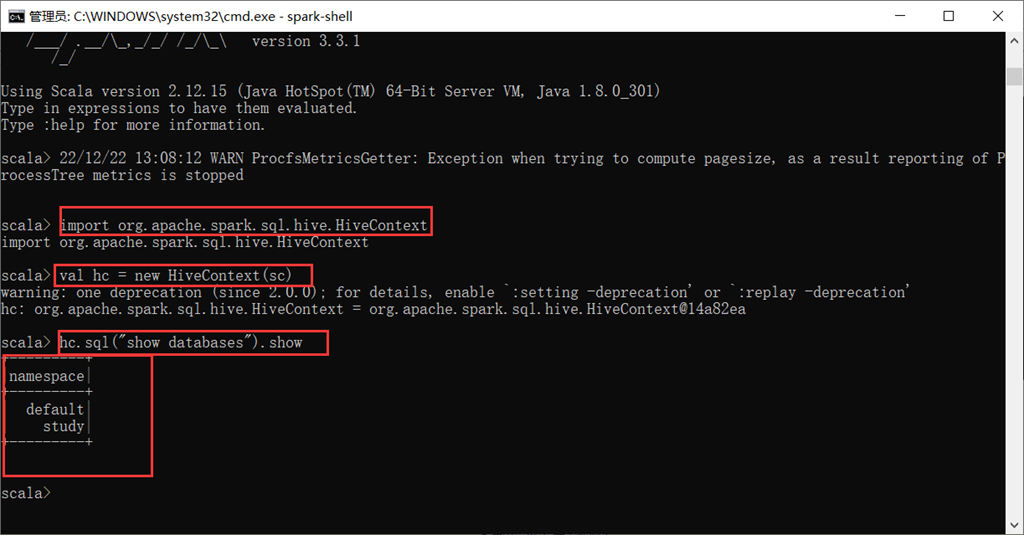
①导入hivecontext包
import org.apache.spark.sql.hive.HiveContext
②构建hivecontext
val hc = new HiveContext(sc)
③使用sql语句查看数据库
hc.sql("show databases").show
2.pyspark
这里很多老的教程会使用hc=hiveContext进行构建,然后使用hc.sql进行查询,然后导致查询结果错误,这样其实spark是不支持的,spark在2.x后就弃用了这种方法。具体的更多详细用法请参考官方文档
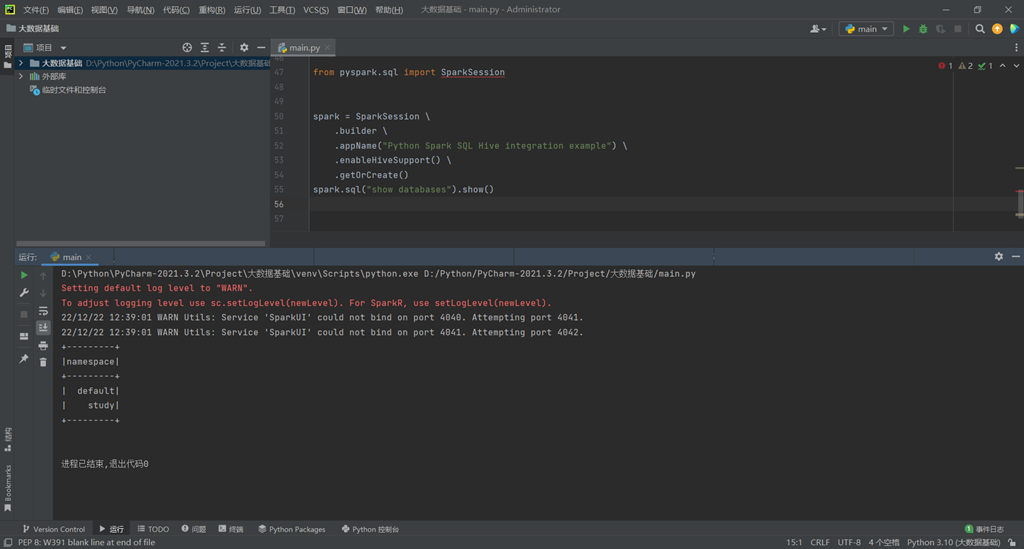
from pyspark.sql import SparkSession
spark = SparkSession \
.builder \
.appName("Python Spark SQL Hive integration example") \
.enableHiveSupport() \
.getOrCreate()
spark.sql("show databases").show()
总之如果前面一切都已经配置好了,想要使spark能够连接hive还是很简单的,复制一下配置文件就可以了,后面都是一些连接测试
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}