我愿称之为国货之光,来自清华和南开的NeuralPS 2022 Paper
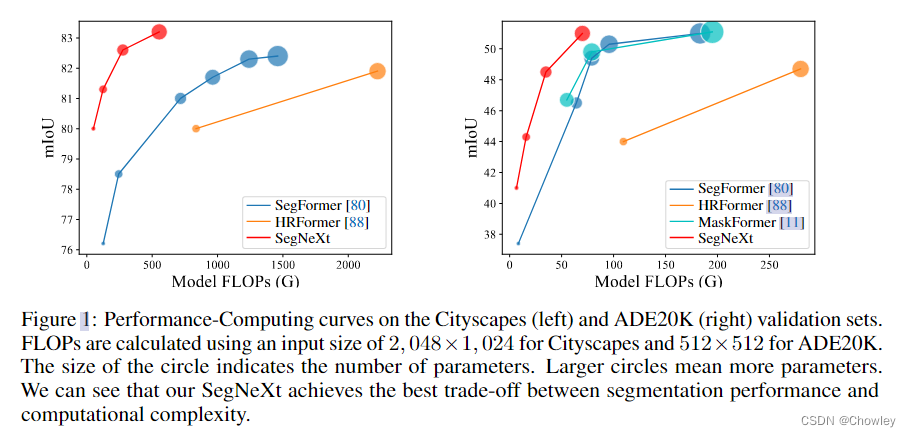
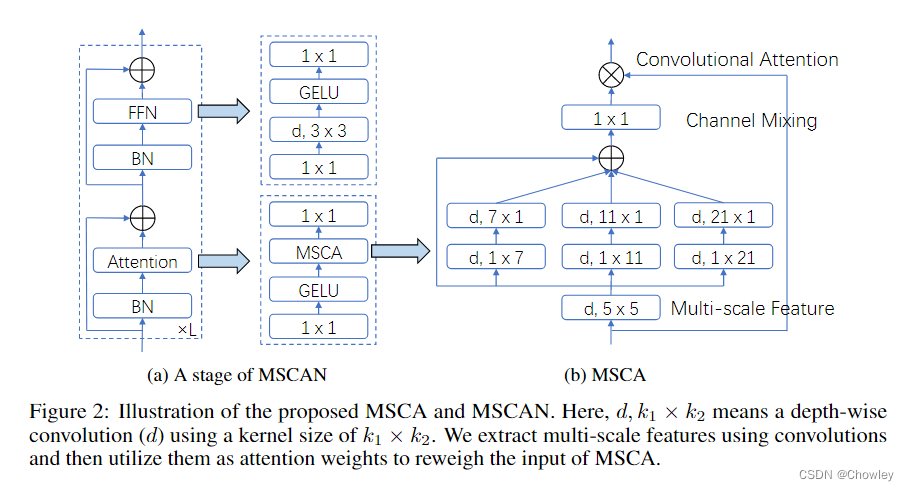
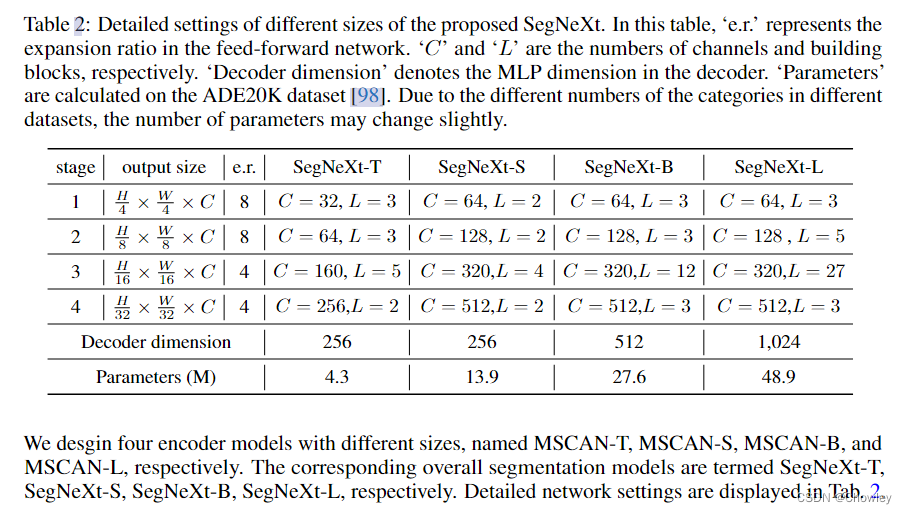
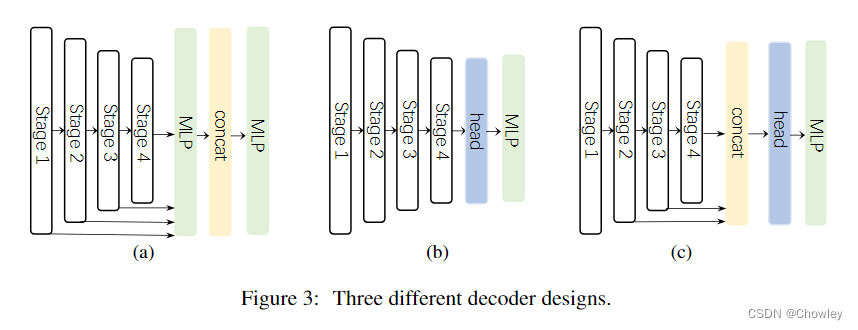
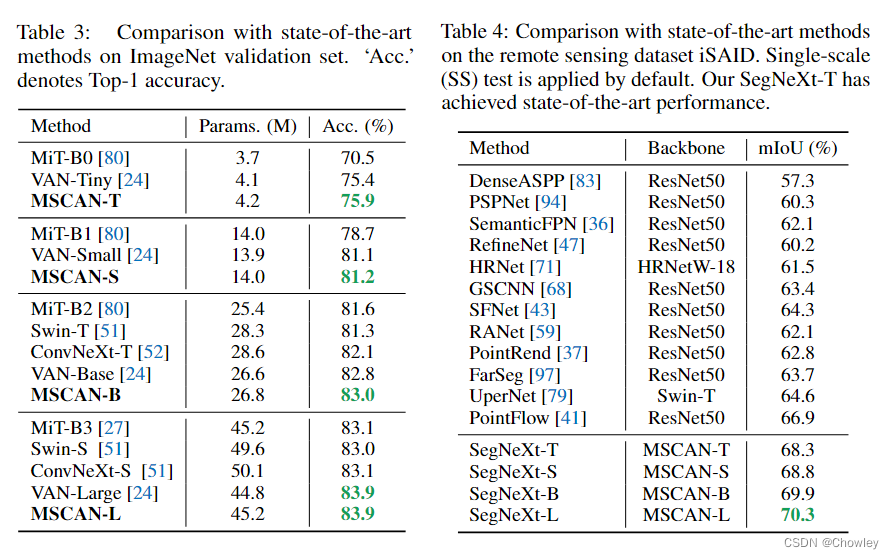
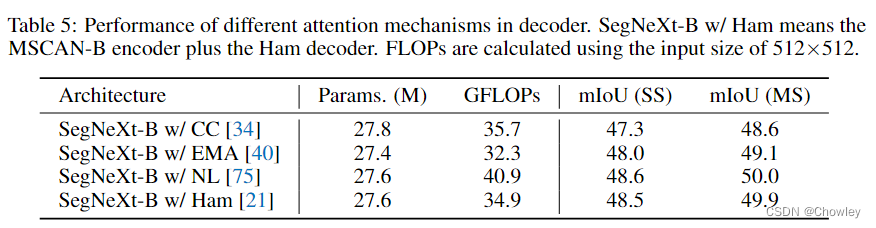
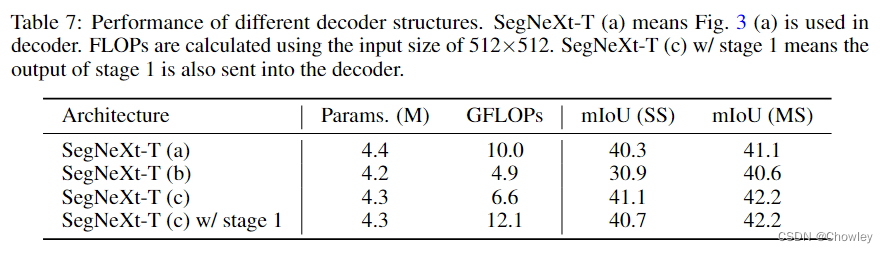
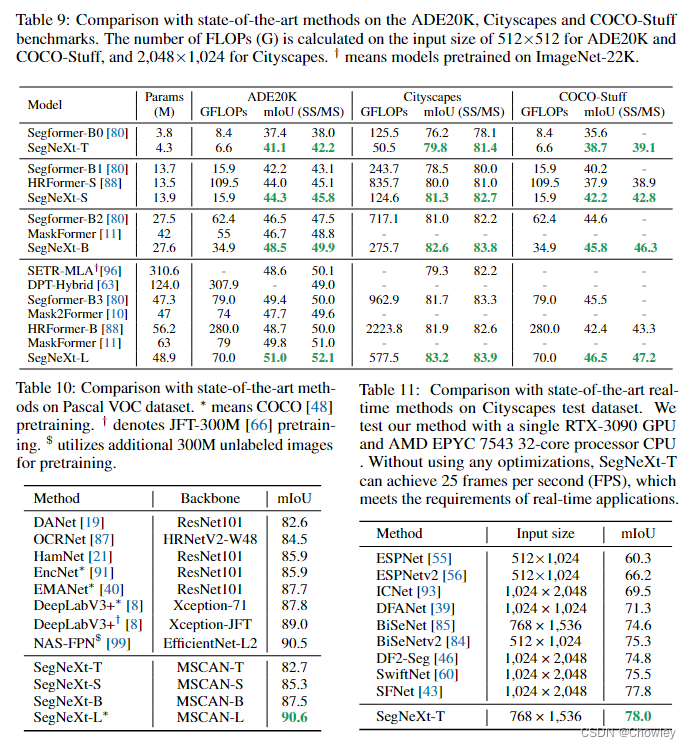
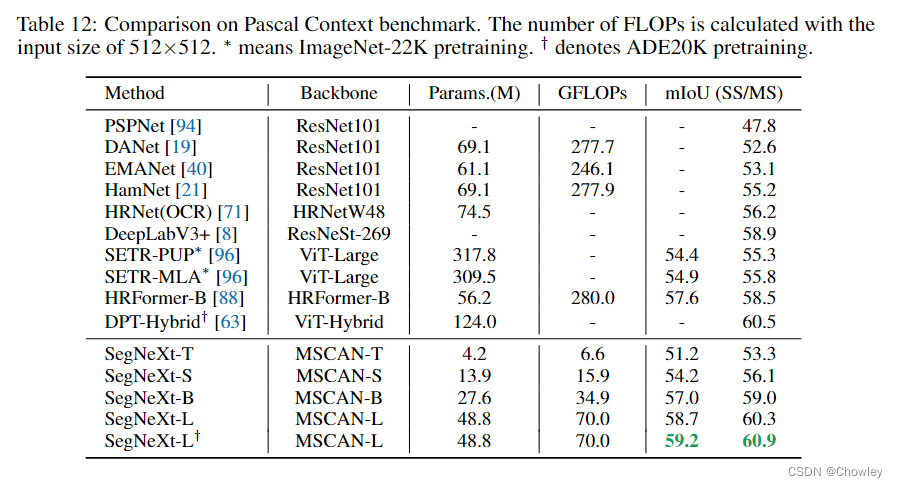
通过回顾以往成功的语义分割工作,我们总结了不同模型所具有的几个关键属性,如Tab所示。1.基于以上观察,我们认为一个成功的语义分割模型应该具备以下特征:(1)强大的骨干网络作为编码者。与以往基于CNN的模型相比,基于变压器的模型的性能提升大多来自于更强大的主干网络。(二)多尺度信息互动。与主要识别单个对象的图像分类任务不同,语义分割是一项密集的预测任务,因此需要处理单个图像中不同大小的对象。(三)空间注意力。空间注意力允许模型通过对语义区域内的区域进行优先排序来执行分割。(4)计算复杂度低。这在处理来自遥感和城市场景的高分辨率图像时尤其关键。 在考虑到上述分析的基础上,本文对卷积注意的设计进行了重新思考,并提出了一种高效的语义分割编解码器结构。不同于以前的基于变压器的模型使用解码器中的卷积作为特征提炼,我们的方法颠倒了变压器-卷积编解码器的体系结构。具体地说,对于编码器中的每个块,我们更新了传统卷积块的设计,并利用多尺度卷积特征通过遵循VAN的简单的逐元素乘法来引起空间注意。我们发现,这种建立空间注意的简单方法在空间信息编码中比标准卷积和自我注意都更有效。对于解码器,我们收集了不同阶段的多层特征,并使用Hamburger[Is Attention Better Than Matrix Decomposition]进一步提取全局上下文。在这种情况下,我们的方法可以从局部到全局获得多尺度上下文,在空间和通道维度上实现自适应,从低层次到高层次聚合信息。 我们的网络,称为SegNeXt,除了译码部分外,主要由卷积运算组成,译码部分包含用于全局信息提取的基于分解的Hamburger模块21。这使得我们的SegNeXt比以前严重依赖转换器的分割方法效率高得多。如图1所示,SegNeXt的性能明显优于目前基于变压器的方法。特别是,在处理城市景观数据集中的高分辨率城市场景时,我们的SegNeXt-S的性能优于SegFormer-B2(81.3%比81.0%),只需要大约1/6(124.6G比717.1G)的计算成本和1/2的参数(13.9M比27.6M)。 贡献可以概括如下:
【Semantic Segmentation】 【Multi-Scale Networks】 【Attention Mechanisms】
在本文中,我们分析了以往成功的分割模型,找出了它们所具有的良好特性。基于这些发现,我们提出了一个定制的卷积注意模块MSCA和一个CNN风格的网络SegNeXt。实验结果表明,SegNeXt在很大程度上超过了目前最先进的基于变压器的方法。最近,基于变压器的模型主导了各种细分市场排行榜。相反,本文表明,当使用适当的设计时,基于CNN的方法仍然可以比基于变压器的方法执行得更好。我们希望这篇论文能够鼓励研究人员进一步研究CNN的潜力。
时代在进步,华人的成就也在进步,希望未来能有更多的华人作者出现
但这篇paper的代码是融合了MMSegmentation,使用源码还需大家仔细学习