注:学习、交流就在博主的个人weixin公众号 “FPGA动力联盟” 留言或直接+博主weixin “fpga_start” 私信~
完整的参考工程源码在某宝有售:https://item.taobao.com/item.htm?ft=t&id=683288101628
该篇文章记录了博主基于FPGA的DDR3开发所需要的一些细节,一方面是对博主自己工作的详细总结,方便日后遗忘了重新查阅,另一方面希望所有读了这篇文章的朋友们都能够掌握DDR3开发所需的基本知识。
本篇将分成四个部分来循序渐进的描述DDR3相关的开发知识,其中第一部分介绍DDR3原理,第二部分具体介绍DDR3芯片,第三部分介绍FPGA-DDR3硬件设计,第四部分介绍DDR3- FPGA读写逻辑~
第一部分:DDR3原理
在介绍DDR3之前,先介绍一下存储器(memory)的分类,存储器一般可以分为内部存储器(内存)、外部存储器(外存)、缓冲存储器(缓存)以及闪存这几个大类:
内存也称为主存储器,位于系统主机板上,可以同CPU/FPGA直接进行信息交换,其主要特点是运行速度快,容量小。
外存也称为辅助存储器,不能与CPU之间直接进行信息交换。其主要特点是:存取速度相对内存要慢得多,存储容量大。内存与外存本质区别是,一个是内部运行提供缓存和处理的功能;而外存主要是针对储存文件、图片、视频、文字等信息的载体,也可以理解为储存空间。
缓存就是数据交换的缓冲区(称作Cache),当某一硬件要读取数据时,会首先从缓存中查找需要的数据,如果找到了则直接执行,找不到的话则从内存中找。由于缓存的运行速度比内存快得多,故缓存的作用就是帮助硬件更快地运行。
闪存(Flash Memory)是一种长寿命的非易失性(在断电情况下仍能保持所存储的数据信息)的存储器,数据删除不是以单个的字节为单位而是以固定的区块为单位(注意:NOR Flash 为字节存储),区块大小一般为256KB到20MB。闪存是电子可擦除只读存储器(EEPROM)的变种,闪存与EEPROM不同的是,EEPROM能在字节水平上进行删除和重写而不是整个芯片擦写,而闪存中的大部分芯片需要块擦除。由于其断电时仍能保存数据,闪存通常被用来保存设置信息,如在电脑的BIOS(基本程序)、数码相机中保存资料等。
存储器的详细分类如下图所示:
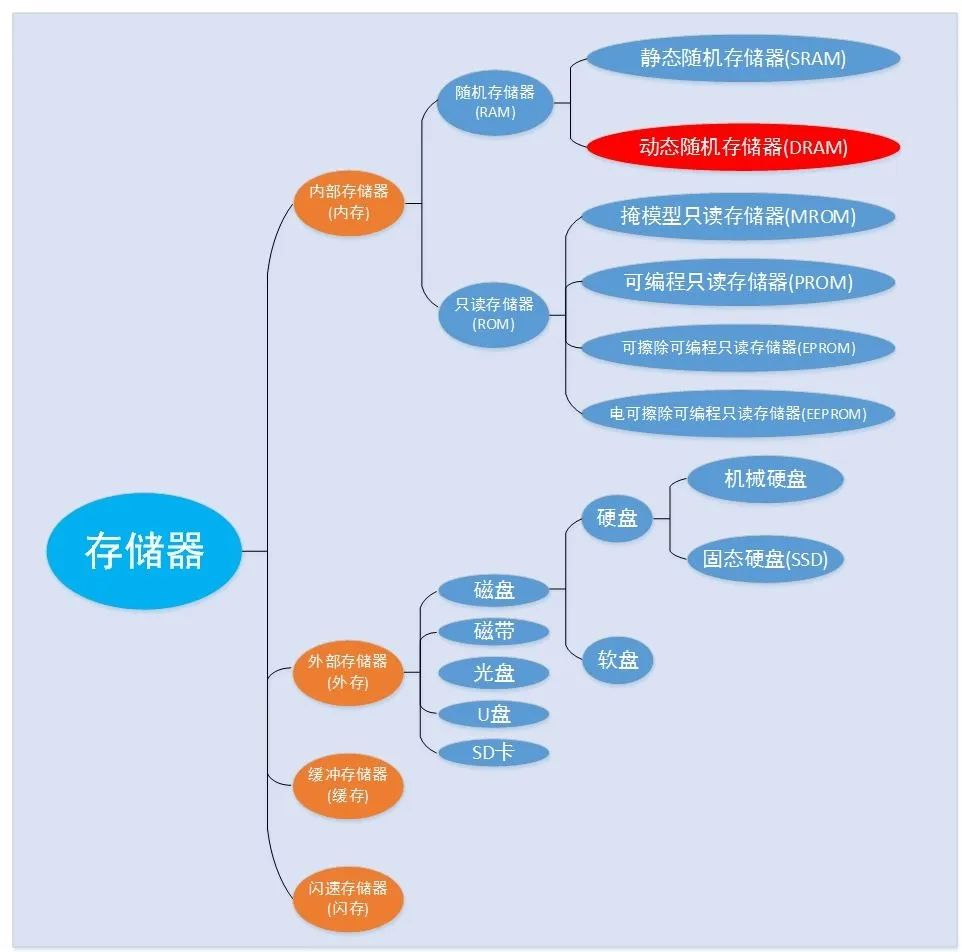
图1:存储器分类
内存中的随机存储器(Random Access Memory,RAM)是一种存储单元内容可按需随意取出或存入,且存取的速度与存储单元位置无关的存储器。这种存储器在断电时将丢失其存储内容,故主要用于存储短时间使用的程序或数据。按照存储信息的不同,随机存储器又分为静态随机存储器(Static RAM,SRAM)和动态随机存储器(Dynamic RAM,DRAM):
静态随机存储器SRAM(Static RAM)不需要刷新电路就能保存它内部存储的数据。除此以外,还有一种随机存储器SSRAM(Synchronous SRAM)即同步静态随机存取存储器。同步是指Memory工作需要同步时钟,内部的命令的发送与数据的传输都以它为基准;随机是指数据不是线性依次存储,而是由指定地址进行数据读写。对于SSRAM的所有访问都在时钟的上升/下降沿启动,地址、数据输入和其它控制信号均与时钟信号相关。这一点与异步SRAM不同,异步SRAM的访问独立于时钟,数据输入和输出都由地址的变化控制。
动态随机存储器DRAM(Dynamic RAM)则每隔一段时间,要刷新充电一次,否则内部的数据会消失。综上所述,SRAM具有较高的性能,但是SRAM也有它的缺点,即它的集成度较低,相同容量的DRAM内存可以设计为较小的体积,但是SRAM却需要很大的体积,且功耗较大。所以在主板上SRAM存储器要占用一部分面积。SRAM的速率高、性能好,它常应用于CPU与主存之间的高速缓存。有一种动态随机存储器SDRAM(Synchronous DRAM)即同步动态随机存取存储器。同步是指 Memory工作需要同步时钟,内部命令的发送与数据的传输都以它为基准;动态是指存储阵列需要不断的刷新来保证数据不丢失;随机是指数据不是线性依次存储,而是自由指定地址进行数据读写,DDR,DDR2、DDR3以及DDR4就属于SDRAM的一类。
SDRAM从发展到现在已经经历了五代,分别是:第一代SDRSDRAM,第二代DDRSDRAM,第三代DDR2SDRAM,第四代DDR3 SDRAM,第五代DDR4 SDRAM。第一代SDRAM采用单端(Single-Ended)时钟信号,而且是时钟上升沿采样。而第二代、第三代与第四代DDR由于时钟上下沿采样,因此工作频率比SDR翻倍,所以采用可降低干扰的差分时钟信号作为同步时钟。
DDR2以及DDR3可以看作是DDR技术标准的一种升级和扩展:DDR的核心频率(DDR芯片内部进行逻辑处理的时钟频率)与工作频率(工作频率指的是DDR芯片管脚的时钟频率)相等,但传输频率(指的是DDR芯片读写的频率)为时钟频率的两倍,也就是说在一个时钟周期内必须传输两次数据。而DDR2采用“4bit Prefetch (4位预取)”机制,核心频率为传输频率的1/4,这样即使核心频率还为200MHz,DDR2内存的数据传输频率也能达到800MHz,也就是所谓的DDR2-800。DDR3采用“8bit Prefetch(8位预取)”机制,这样DRAM的核心频率只有传输频率的1/8,所以DDR3-800的核心频率只有100MHz,如果核心频率为200MHz,DDR3内存的数据传输频率能达到1600MHz,数据传输频率为DDR2的两倍,即DDR3-1600。总得来说,需要知道DDR3三个频率之间的关系:
工作频率=数据传输频率/2。因为DDR是利用时钟的上升沿与下降沿均传输数据,所以DDR芯片的工作频率(时钟引脚的频率)为传输频率的一半。
核心频率=数据传输频率/DDR的预取数。对于DDR来说,预取数为2;对于DDR2来说,预取数为4;对于DDR3来说,预取数为8。
下面具体介绍DDR3:
DDR3 SDRAM(Double-Data-Rate Synchronous Dynamic Random Access Memory)属于上文提到的SDRAM类。DDR3 在DDR2的基础上继承发展而来,其数据传输速度为 DDR2的两倍。同时,DDR3 标准可以使单颗内存芯片的容量更为扩大,达到 512Mb 至 8Gb,从而使采用 DDR3 芯片的内存条容量扩大到最高16GB。此外,DDR3的工作电压降低为1.5V,比采用1.8V的DDR2省电30%左右。说到底,这些指标上的提升在技术上最大的支撑来自于芯片制造工艺的提升,90nm 甚至更先进的45nm制造工艺使得同样功能的 MOS 管可以制造的更小,从而带来更快、更密、更省电的技术提升。DDR3现今是并行 SDRAM 家族中速度最快的成熟标准,JEDEC标准规定的DDR3最高速度可达1600MT/s (1MT/s 即为每秒钟一百万次传输)。不仅如此,内存厂商还可以生产速度高于 JEDEC 标准的DDR3产品,如速度为2000MT/s 的DDR3产品,甚至有报道称其最高速度可高达 2500MT/s。
DDR3相较于DDR2而言主要有如下几个特点:
1.突发长度(Burst Length,BL):由于DDR3的预取为8bit,所以突发传输周期(Burst Length,BL)也固定为8。预取为8bit意味着DDR3内部时钟在一次读/写数据时,操作8bit数据,在相同时间内接口为了能够处理得过来,其接口读写数据速度必须为内部核心时钟频率的8倍。因此就有了DDR3-1600的芯片接口读写速率(也就是数据传输速率)为1600MT/s,其实内部时钟为200MHz。
2.寻址时序(Timing):就像DDR2从DDR转变而来后延迟周期数增加一样,DDR3的CL周期也将比DDR2有所提高。DDR2的CL范围一般在2~5之间,而DDR3则在5~11之间,且附加延迟(AL)的设计也有所变化。DDR2时AL的范围是0~4,而DDR3时AL有三种选项,分别是0、CL-1和CL-2。另外,DDR3还新增加了一个时序参数-写入延迟(CWD),这一参数将根据具体的工作频率而定。
3.DDR3新增的重置(Reset)功能:重置是DDR3新增的一项重要功能,并为此专门准备了一个引脚。DRAM业界很早以前就要求增加这一功能,如今终于在DDR3上实现了。这一引脚将使DDR3的初始化处理变得简单。当Reset命令有效时,DDR3内存将停止所有操作,并切换至最少量活动状态,以节约电力。在Reset期间,DDR3内存将关闭内在的大部分功能,所有数据接收与发送器都将关闭,所有内部的程序装置将复位,DLL(延迟锁相环路)与时钟电路将停止工作,而且不理睬数据总线上的任何动静。这样一来,将使DDR3达到最节省电力的目的。
4.DDR3新增ZQ校准功能:ZQ也是一个新增的脚,在这个引脚上接有一个240欧姆的低公差参考电阻。这个引脚通过一个命令集,通过片上校准引擎(On-Die Calibration Engine,ODCE)来自动校验数据输出驱动器导通电阻与ODT的终结电阻值。当系统发出这一指令后,将用相应的时钟周期(在加电与初始化之后用512个时钟周期,在退出自刷新操作后用256个时钟周期、在其他情况下用64个时钟周期)对导通电阻和ODT电阻进行重新校准。
5.参考电压分成两个:在DDR3系统中,对于内存系统工作非常重要的参考电压信号VREF将分为两个信号,即为命令与地址信号服务的VREFCA和为数据总线服务的VREFDQ。
6.逻辑Bank数量:DDR2 SDRAM中有4Bank和8Bank的设计,目的就是为了应对未来大容量芯片的需求。而DDR3很可能将从2Gb容量起步,因此起始的逻辑Bank就是8个,另外还为未来的16个逻辑Bank做好了准备。
7.封装(Packages):DDR3由于新增了一些功能,所以在引脚方面会有所增加,8bit芯片采用78球FBGA封装,16bit芯片采用96球FBGA封装,而DDR2则有60/68/84球FBGA封装三种规格。并且DDR3必须是绿色封装,不能含有任何有害物质。
8.降低功耗:DDR3内存在达到高带宽的同时,其功耗反而可以降低,其核心工作电压从DDR2的1.8V降至1.5V,相关数据预测DDR3将比现时DDR2节省30%的功耗,当然发热量我们也不需要担心,不但内存带宽大幅提升,功耗表现也比上代更好
内存技术从SDR,DDR,DDR2,DDR3一路发展而来,传输速度以指数递增,除了晶圆制造工艺的提升因素之外,还因为采用了Double Data Rate以及Prefetch(预取)两项技术。实际上,无论是SDR还是DDR或DDR2、DDR3,内存芯片内部的核心时钟频率基本上是保持一致的,都是100MHz到200MHz(某些厂商生产的超频内存除外)。DDR即Double Data Rate技术使数据传输速度较SDR提升了一倍。如下图所示, SDR仅在时钟的上升沿传输数据,而DDR在时钟信号上、下沿同时传输数据。例如同为133MHz时钟,DDR却可以达到266Mb/s的数据传传输速度。
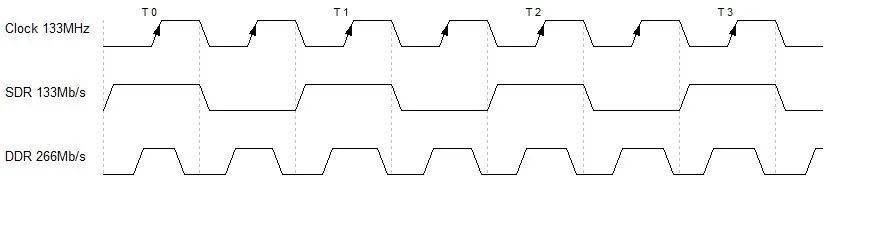
图2:SDR与DDR的核心时钟频率与接口传输频率比较
Double Data Rate技术使数据外传速度提升了一倍,而芯片内部数据传输速度的提升则是通过Prefetch(预取)技术实现的。所谓Prefetch(预取)简单的说就是在一个内核时钟周期同时寻址多个存储单元并将这些数据以并行的方式统一传输到IO Buffer中,之后以更高的外传速度将IO Buffer中的数据传输出去。这个更高的速度在DDR中就是通过Double Data Rate实现的,也正因为如此,DDR芯片时钟管脚的时钟频率与芯片内部的核心频率是一致的。如下图所示为DDR的Prefetch过程中,在16位的内存芯片中一次将2个16bit数据从内核传输到外部MUX单元,之后分别在Clock信号的上、下沿分两次将这2个16bit数据传输给FPGA或其他内存控制器,整个过程经历的时间恰好为一个内核时钟周期。
发展到DDR2,芯片内核每次Prefetch (预取) 4倍的数据至IO Buffer中,为了进一步提高外传速度,芯片的内核时钟与外部接口时钟(即DDR芯片的Clock管脚时钟)不再是同一时钟,外部Clock时钟频率变为内核时钟的2倍。同理,DDR3每次Prefetch 8倍的数据,其芯片Clock频率为内核频率(100MHz至200MHz)的4倍,即JEDEC标准(JESD79-3)规定的400MHz至800MHz,再加上在Clock信号上、下跳变沿同时传输数据,DDR3的数据传输速率便达到了800MT/s到1600MT/s。具体到内存条速度,我们以PC3-12800为例,其采用的DDR3-1600芯片的核心频率为200MHz,经过Prefetch后在800MHz Clock信号工作频率的双边沿(Double Data Rate)作用下,使芯片的数据传输速率为1600 MT/s,内存条每次传输64比特或者说8字节数据,1600x8便得到12800MB/s的峰值比特率。
下表列出了JEDEC标准(JESD79-3)规定的DDR3芯片以及内存条相关参数。需要说明的是,如前所述,并不是所有的内存产品都完全遵从JEDEC标准,有些厂家会生产速度更高速的DDR3芯片,一般情况下这些芯片是从芯片检测流程中筛选出来的频率动态范围更大的芯片,或者是可加压超频工作的芯片。
| 名称 |
核心频率 |
核心时钟周期 |
管脚时钟频率 |
数据传输速率 |
对应内存条名称 |
内存条峰值比特率 |
| DDR3-800 |
100MHz |
10ns |
400MHz |
800MT/s |
PC3-6400 |
6400MB/ |
| DDR3-1066 |
133MHz |
7.5ns |
533MHz |
1066MT/s |
PC3-8500 |
8533MB/s |
| DDR3-1333 |
166MHz |
6ns |
667MHz |
1333MT/s |
PC3-10600 |
10667MB/s |
| DDR3-1600 |
200MHz |
5ns |
800MHz |
1600MT/s |
PC3-12800 |
12800MB/s |
注意:Clock管脚时钟频率就是DDR的工作频率。最后,在了解了DDR的上面基础知识的前提下,下表列出了不同DDR芯片的相关特性:
| SDRAM器件比较 |
| 条目 |
DDR3 |
DDR2 |
DDR |
| 工作频率 |
400/533/667/800 MHz |
200/266/333/400 MHz |
100/133/166/200 MHz |
| 数据传输速率 |
800/1066/1333/1600 MT/s |
400/533/667/800 MT/s |
200/266/333/400 MT/s |
| 预取位宽 |
8-bit |
4-bit |
2-bit |
| 输入时钟类型 |
差分时钟 |
差分时钟 |
差分时钟 |
| 突发长度 |
8, 4 |
4,8 |
2,4,8 |
| DQS |
差分数据选通 |
差分数据选通 |
单端数据选通 |
| 电源电压 |
1.5V |
1.8V |
2.5V |
| 数据电平标准 |
SSTL_15 |
SSTL_18 |
SSTL_2 |
| CL |
5,6,7,8,9时钟 |
3,4,5时钟 |
2,2.5,3时钟 |
| ODT |
支持 |
支持 |
不支持 |
| 芯片封装 |
FBGA |
FBGA |
TSOP(II)/FBGA/LQFP |
下面介绍DDR3的原理:
DDR3的内部是一个存储阵列,将数据“填”进去,你可以它想象成一张表格,如下图所示。和表格的检索原理一样,先指定一个行(Row),再指定一个列(Column),我们就可以准确地找到所需要的单元格,这就是内存芯片寻址的基本原理。对于内存,这个单元格可称为存储单元,那么这个表格(存储阵列)就是逻辑Bank(Logical Bank,下面简称Bank,与之对应的还有一种叫做物理BANK(又称RANK)。

DDR3内部的BANK可以看做是一个M×N的阵列,B代表Bank编号,C代表列地址编号,R代表行地址编号。如果寻址命令是B1、R2、C6,就能确定地址是图中红格的位置,从而读写该地址所在的内存空间。
目前DDR3内存芯片基本上都是8个Bank设计,也就是说一共有8个这样的“表格”。寻址的流程也就是先指定Bank地址,再指定行地址,然后指定列地址,最终确定寻址单元。
对DDR3系统而言,还存在物理Bank的概念,这是对内存子系统的一个相关术语,并不针对内存芯片。内存为了保证CPU正常工作,必须一次传输完CPU 在一个传输周期内所需要的数据。而CPU在一个传输周期能接受的数据容量就是CPU数据总线的位宽,单位是bit(位)。控制内存与CPU之间数据交换的FPGA芯片也因此将内存总线的数据位宽等同于CPU数据总线的位宽,这个位宽就称为物理Bank(Physical Bank,有的资料称之为Rank)的位宽。目前这个位宽基本为64bit。
附:物理Bank解释
传统内存系统为了保证CPU的正常工作,必须一次传输完CPU在一个传输周期内所需要的数据。而CPU在一个传输周期能接收的数据容量就是CPU数据总线的位宽,单位是bit(位)。内存与CPU之间的数据交换通过主板上的FPGA芯片进行,内存总线的数据位宽等同于CPU数据总线的位宽,这个位宽就称之为物理Bank(Physical Bank,简称rank)的位宽。以目前主流的DDR系统为例,CPU与内存之间的接口位宽是64bit,也就意味着CPU在一个周期内会向内存发送或从内存读取64bit的数据,那么这一个64bit的数据集合就是一个内存条Bank。一条内存条的物理Bank是由所采用的内存颗粒的位宽决定的,各个芯片位宽之和为64bit就是单物理Bank;如果是128bit就是双物理Bank。
在实际工作中,逻辑Bank地址与相应的行地址是同时发出的,此时这个命令称之为“行激活”(Row Active)。在此之后,将发送列地址寻址命令与具体的操作命令(是读还是写),这两个命令也是同时发出的,所以一般都会以“读/写命令”来表示列寻址。根据相关的标准,从行有效到读/写命令发出之间的间隔被定义为tRCD,即RAS to CAS Delay(RAS至CAS延迟,RAS就是行地址选通脉冲,CAS就是列地址选通脉冲),我们可以理解为行选通周期。tRCD是DDR的一个重要时序参数,广义的tRCD以核心时钟周期(tCK,Clock Time)数为单位,比如tRCD=3,就代表延迟周期为两个时钟周期,具体到确切的时间,则要根据时钟频率而定。以DDR3-800为例,DDR3-800的数据传输频率(等效频率)为800MHz,由于DDR3的预取(Prefetch)位宽为8位,所以核心频率为100MHz (800MHz/8),核心时钟的周期为10ns,如果tRCD=3,则表示延时为30ns。

图3:tRCD时序
上图是tRCD=3的时序图,NOP=Not Operation,表示无操作,灰色区域表示Don’t Care。
接下来,相关的列地址被选中以后,将会触发数据传输,但从存储单元中输出到真正出现在内存芯片的I/O接口之间还需要一定的时间(数据触发本身就有延时,而且还需要进行信号放大),这段时间就是列地址脉冲选通潜伏期(CAS Latency,CL),CL的数值与tRCD一样,以时钟周期数表示。比如DDR3-800的有效频率(传输数据频率)为800MHz,由于DDR3的预取数为8,所以核心频率为100MHz,核心周期为10ns,如果CL=2,那么就意味着列地址脉冲选通潜伏期为20ns。CL只针对读取操作有效。
由于芯片体积的原因,存储单元中的电容容量很小,所以信号要经过放大来保证其有效的识别性,这个放大/驱动工作由Sense Amplifier负责,一个存储体对应一个Sense Amplifier通道。但它要有一个准备时间才能保证信号的发送强度(事前还要进行电压比较以进行逻辑电平的判断),因此从数据I/O总线上有数据到数据输出之前的一个时钟上升沿开始,数据即已传向Sense Amplifier,也就是说此时数据已经被触发,经过一定的驱动时间最终传向数据I/O总线进行输出,这段时间我们称之为tAC(Access Time from CLK,时钟触发后的访问时间)。
Sense Amplifier在DDR结构中扮演的角色如下所示:
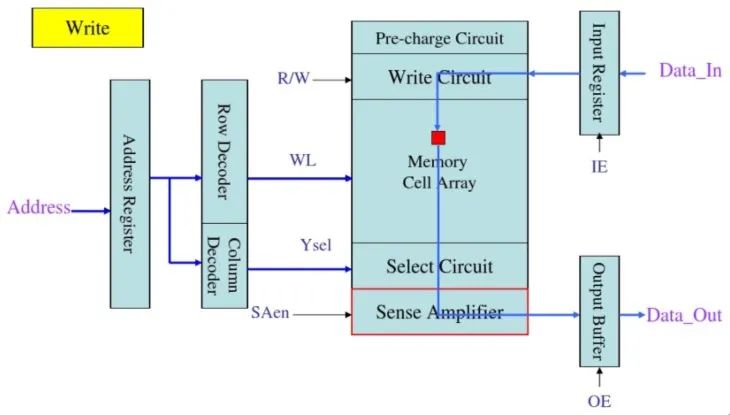
图4:DDR结构中的Sense Amplifier
tAC和CAS的示意图如下图所示

图5:CAS与tAC
目前内存的读写基本都是连续的,因为与CPU交换的数据量以一个Cache Line(即CPU内Cache的存储单位)的容量为准,一般为64字节。而现有的Rank位宽为8字节(64bit),那么就要一次连续传输8次,这就涉及到我们也经常能遇到的突发传输的概念。突发(Burst)是指在同一行中相邻的存储单元连续进行数据传输的方式,连续传输的周期数就是突发长度(Burst Lengths,简称BL)。
在进行突发传输时,只要指定起始列地址与突发长度,内存就会依次地自动对后面相应数量的存储单元进行读/写操作而不再需要控制器连续地提供列地址。这样,除了第一组数据的传输需要若干个周期(主要是之前的延迟,一般的是tRCD+CL)外,其后每个数据只需一个周期的即可获得。下图是CAS=2,BL=4时的时序图
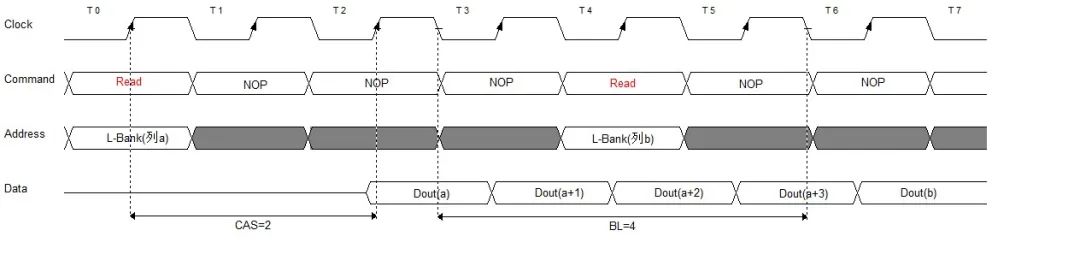
图6:DDR突发传输
突发连续读取模式:只要指定起始列地址与突发长度,后续的寻址与数据的读取自动进行,而只要控制好两段突发读取命令的间隔周期(与BL相同)即可做到连续的突发传输。
谈到了突发长度时。如果BL=4,那么也就是说一次就传送4×64bit的数据。但是,如果其中的第二组数据是不需要的,怎么办?还都传输吗?为了屏蔽不需要的数据,人们采用了数据掩码(Data I/O Mask,简称DQM)技术。通过DQM,内存可以控制I/O端口取消哪些输出或输入的数据。这里需要强调的是,在读取时,被屏蔽的数据仍然会从存储体传出,只是在“掩码逻辑单元”处被屏蔽。DQM由FPGA控制,为了精确屏蔽一个P-Bank位宽中的每个字节,每个DIMM有8个DQM 信号线,每个信号针对一个字节。这样,对于4bit位宽芯片,两个芯片共用一个DQM信号线,对于8bit位宽芯片,一个芯片占用一个DQM信号,而对于 16bit位宽芯片,则需要两个DQM引脚。
在数据读取完之后,为了腾出读出放大器以供同一Bank内其他行的寻址并传输数据,内存芯片将进行预充电的操作来关闭当前工作行。还是以上面那个Bank示意图为例。当前寻址的存储单元是B1、R2、C6。如果接下来的寻址命令是B1、R2、C4,则不用预充电,因为读出放大器正在为这一行服务。但如果地址命令是B1、R4、C4,由于是同一Bank的不同行,那么就必须要先把R2关闭,才能对R4寻址。从开始关闭现有的工作行,到可以打开新的工作行之间的间隔就是tRP(Row Precharge command Period,行预充电有效周期),单位也是时钟周期数。
整个充电的步骤如下图所示:
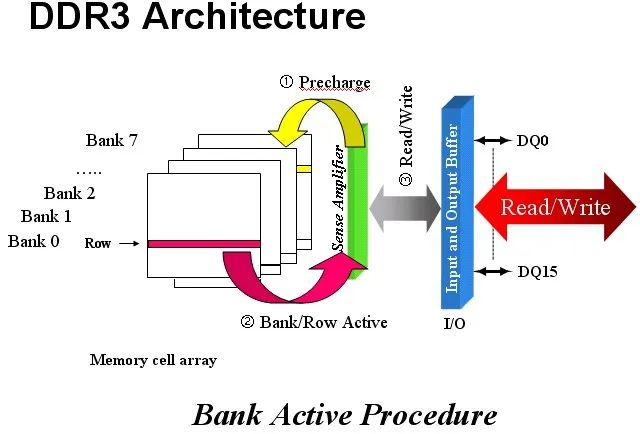
图7:DDR3结构
在不同Bank间读写也是这样,先把原来数据写回,再激活新的Bank/Row。
下面介绍数据选取脉冲(DQS):
DQS 是DDR中的重要功能,它的功能主要用来在一个时钟周期内准确的区分出每个传输周期,并便于接收方准确接收数据。每一颗芯片都有一个DQS信号线,它是双向的,在写入时它用来传送由FPGA发来的DQS信号,读取时,则由芯片生成DQS向FPGA发送。完全可以说,它就是数据的同步信号。
在读取时,DQS与数据信号同时生成(也是在CK与CK#的交叉点)。而DDR内存中的CL也就是从CAS发出到DQS生成的间隔,DQS生成时,芯片内部的预取已经完毕了,由于预取的原因,实际的数据传出可能会提前于DQS发生(数据提前于DQS传出)。由于是并行传输,DDR内存对tAC也有一定的要求,对于DDR266,tAC的允许范围是±0.75ns,对于DDR333,则是±0.7ns,有关它们的时序图示见前文,其中CL里包含了一段DQS 的导入期。
DQS 在读取时与数据同步传输,那么接收时也是以DQS的上下沿为准吗?不,如果以DQS的上下沿区分数据周期的危险很大。由于芯片有预取的操作,所以输出时的同步很难控制,只能限制在一定的时间范围内,数据在各I/O端口的出现时间可能有快有慢,会与DQS有一定的间隔,这也就是为什么要有一个tAC规定的原因。而在接收方,一切必须保证同步接收,不能有tAC之类的偏差。这样在写入时,芯片不再自己生成DQS,而以发送方传来的DQS为基准,并相应延后一定的时间,在DQS的中部为数据周期的选取分割点(在读取时分割点就是上下沿),从这里分隔开两个传输周期。这样做的好处是,由于各数据信号都会有一个逻辑电平保持周期,即使发送时不同步,在DQS上下沿时都处于保持周期中,此时数据接收触发的准确性无疑是最高的。
DDR3的写时序的时序图如下图所示:

图8:DDR3写时序
DDR3的读时序的时序图如下图所示:
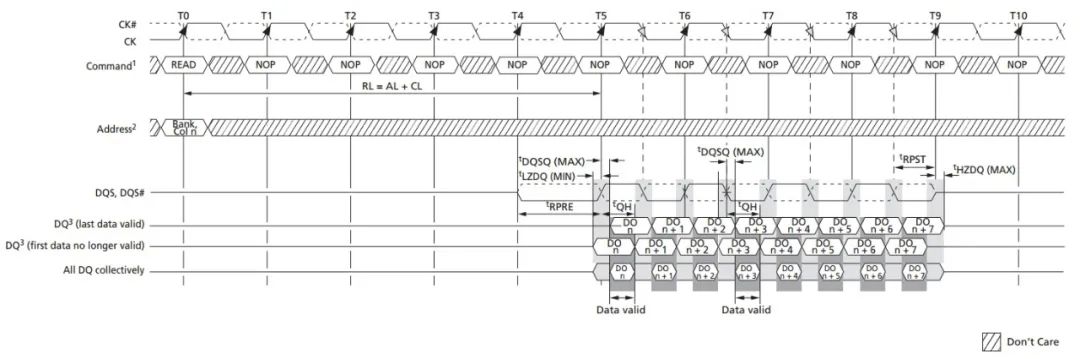
图9:DDR3读时序
由上面的时序图可知,在写时序中,有效数据DQ的正中间正好对应DQS的跳边沿,而在读时序中,有效数据的正中间对应着DQS信号的正中间。
最后在简单说一说DDR中采用的ODT(On-Die Termination)技术:
ODT(On-DieTermination),是从DDR2 SDRAM时代开始新增的功能。其允许用户通过读写DDR2/3内部的MR1寄存器,来控制DDR3 SDRAM中各个信号内部终端电阻的连接或者断开。在DDR3 SDRAM中,ODT功能主要应用于:
1、DQ, DQS, DQS# andDM for X4 configuration
2、DQ, DQS, DQS#, DM,TDQS and TDQS# for X8 configuration
3、DQU, DQL, DQSU,DQSU#, DQSL, DQSL#, DMU and DML for X16 configuration
ODT(On-DieTermination)技术的目的是通过使DDR SDRAM控制器能够独立的打开或者关断DDR内部的终端电阻来提高存储器通道的信号完整性,在DLL关闭模式,ODT功能被禁用。
一个DDR通道,通常会挂接多个Rank,这些Rank的数据线、地址线等等都是共用;数据信号也就依次传递到每个Rank,到达线路末端的时候,波形会有反射,从而影响到原始信号;因此需要加上终端电阻,吸收余波。之前的DDR,终端电阻做在板子上,但是因为种种原因,效果不是太好,到了DDR2,把终端电阻做到了DDR颗粒内部,也就称为On Die Termination,Die上的终端电阻,Die是硅片的意思,这里也就是DDR颗粒。
ODT技术具体的内部结构图如下:
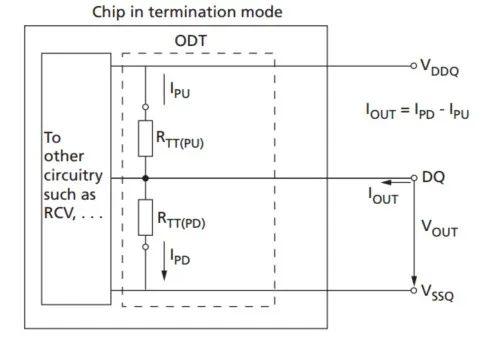
图10:DDR3内部的ODT结构
等效结构如下图所示:
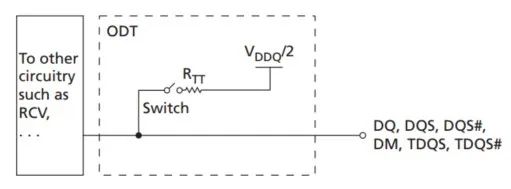
图11:DDR3内部的ODT结构的戴维南等效模型
ODT终端电阻的电阻值RTT可通过模式寄存器MR1的A9,A6,A2来进行设置,具体设置可参考DDR3 SDRAM芯片数据手册 。
总的来说,ODT技术有以下三个优点:
1、去掉了主板上的终结电阻器等电器元件,这样会大大降低主板的制造成本,并且也使主板的设计更加简洁。
2、由于ODT技术可以迅速的开启和关闭空闲的内存芯片,在很大程度上减少了内存闲置时的功率消耗。
3、芯片内部终结电阻也要比主板的终端电阻具有更好的信号完整性。这也使得进一步提高DDR2内存的工作频率成为可能。
第二部分:DDR3芯片
博主的该篇调试笔记以美光(micron)的DDR3芯片为例介绍,芯片具体型号为:MT41J256M16HA-125,其基本性能介绍如下图所示:

图12:DDR3芯片主要特性
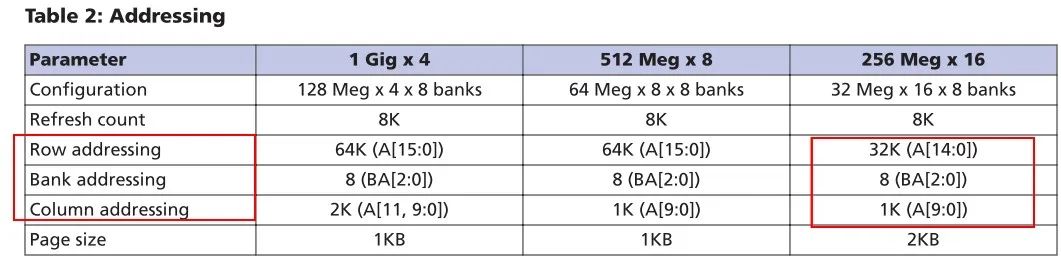
图13:DDR3的容量及地址
该芯片行地址线为row[14:0],即215=32K;列地址线为column[9:0],即210=1K;bank地址为bank[2:0],即23=8个bank;每个存储单元的数据为data[15:0],即24=16bit位宽,因此可以计算得到该芯片为存储容量为:32K×1K×8×16=232=4Gb。
该芯片的管脚信号描述如下:
| 管脚名称 |
类型 |
功能 |
| A[14:13], A12/BC#, A11, A10/AP, A[9:0] |
Input |
为地址输入,为 ACTIVATE命令提供行地址,同时为READ/WRTE命令提供列地址和自动预充电位(A10),以便从某个Bank的内存阵列里选出一个位置。LOAD MODE命令期间,地址输入提供一个操作码。地址输入的参考值是 VREFCA。A12/BC#:在模式寄存器(MR)使能时,A12在READ和 WRITE命令期间被采样,以决定burst chop(on-the-fly)是否会被执行(HIGH=BL8执行 burst chop),或者LoW-BC4不执行 burst chop |
| BA[2:0] |
Input |
是Bank地址输入,定义 ACTIVATE、READ、WRITE或 PRECHARGE命令是对哪个Bank操作的。BA[2:0]定义在 LOAD MODE命令期间哪个模式(MR0、MR1、MR2)被装载,BA[2:0]的参考值是ⅤREFCA |
| CK, CK# |
Input |
差分时上钟输入,所有控制和地址输入信号在CK上升沿和CK#的下降沿交叉处被采样,输出数据选通(DQS,DQS#)参考CK和CK#的交叉点。 |
| CKE |
Input |
时钟使能。使能(高)和禁止(低)内电路和DRAM上的时钟。由DDR3 SDRAM配置和操作模式决定特定电路被使能和禁止。CKE为低,提供 PRECHARGE POWER-DOWN和 SELF REFRESH操作(所有Bank都处于空闲),或者有效掉电(在任何Bank里的行有效)。CKE与掉电状态的进入、退出以及自刷新的进入同步。CKE与自刷新的退出异步,输入Buffer(除了CKE、CK#、 RESET#和ODT)在POWER-DOWN期间被禁止。输入Buffer(除了CKE和 RESET#)在SELF REFRESH期间被禁止。CKE的参考值是ⅤREFCA。 |
| CS# |
Input |
片选信号。使能(低)和禁止(高)命令译码,当CS#为高时,所有命令被屏蔽、CS#提供了多Bank系统的Bank选择功能,CS#是命令代码的一部分,CS#的参考值是 VREFCA |
| LDM |
Input |
低8位数据输入屏蔽。LDM是低8位写数据的输入屏蔽信号,在写期间,当伴随低8位输入数据的LDM信号被采样为高时,输入数据的低8位被屏蔽。虽然LDM仅作为输入脚,但是LDM负载被设计成与DQ和DQS脚负载相匹配。DM的参考值是 VREFCA。 |
| ODT |
Input |
片上终端使能。ODT使能(高)和禁止(低)片内终端电阻,在正常操作使能时,ODT仅对下面的引脚有效:DQ[15:0]、LDQS、LDQS#、UDQS、UDQS#、 UDM 以及LDM。如果通过LOADMODE命令禁止,ODT输入被忽略。ODT的参考值是 VREFCA。 |
| RAS#, CAS#, WE# |
Input |
命令输入,这3个信号,连同CS#,定义一个命令,其参考值是ⅤREFCA。 |
| RESET# |
Input |
复位信号,低位有效,参考值是VSS,复位信号是异步于时钟的。 |
| UDM |
Input |
高8位数据输入屏蔽。 |
| DQ[7:0] |
I/O |
低8位数据输入/输出。参考值是 VREFDQ。 |
| DQ[15:8] |
I/O |
高8位数据输入/输出。参考值是 VREFDQ。 |
| LDQS, LDQS# |
I/O |
低8位数据选通。读时是输出,边缘与读出的数据对齐。写时是输入,中心与写数据对齐。 |
| UDQS, UDQS# |
I/O |
高8位数据选通。读时是输出,边缘与读出的数据对齐。写时是输入,中心与写数据对齐。 |
| VDD |
Supply |
电源电压,1.5V±0,075V。 |
| VDDQ |
Supply |
DQ电源,1.5V±0.075V。为了降低噪声,在芯片上进行了隔离。 |
| VREFCA |
Supply |
控制、命令、地址的参考电压。VREFCA在所有时刻(包括自刷新)都必须保持规定的电压。 |
| VREFDQ |
Supply |
数据的参考电压。VREFDQ在所有时刻(除了自刷新)都必须保持规定的电压。 |
| VSS |
Supply |
地。 |
| VSSQ |
Supply |
DQ地,为了降低噪声,在芯片上进行了隔离。 |
| ZQ |
Reference |
输出驱动校准的外部参考,这个引脚应该连接240欧姆电阻到VSSQ。 |
| NC |
– |
管脚悬空。 |
第三部分:DDR3-FPGA硬件设计
本次硬件设计参考黑金的成熟设计方案来进行说明。
下面介绍原理图设计:
1) 电源设计
DDR3需要3种电源:1.5V的主电源VDD、0.75V的参考电源VREF以及0.75V的匹配电阻上拉参考电源VTT。根据上节芯片手册的电源管脚介绍可知,电源分为4种,分别是电源电压VDD、数据电压VDDQ、控制/命令/地址参考VREFCA、数据参考VREFDQ。一般芯片的VDD和VDDQ共用1.5V的主电源VDD,参考电压VREFCA和VREFDQ共用0.75V的参考电源VREF,而0.75V的匹配电阻上拉参考电源VTT的使用在下面将介绍。因此我们选择TI公司的TPS51200来给DDR3供电。如下图所示:

图14:专用于DDR的芯片
通过外部提供3.3V和1.5V电源,TPS51200输出VREF和VTT,原理图如下图所示:
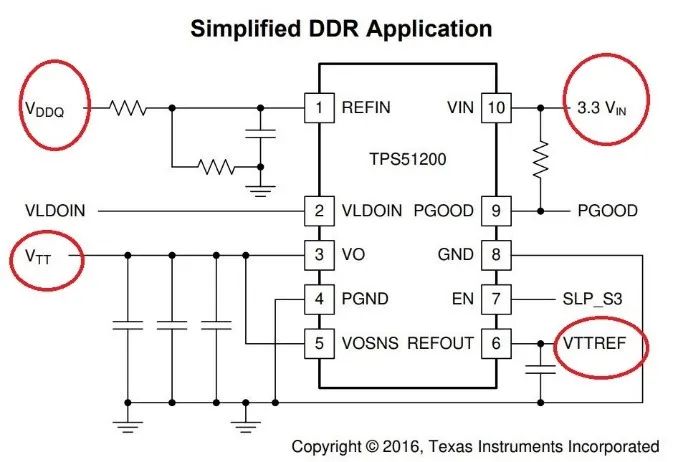
图15:专用于DDR的芯片原理图

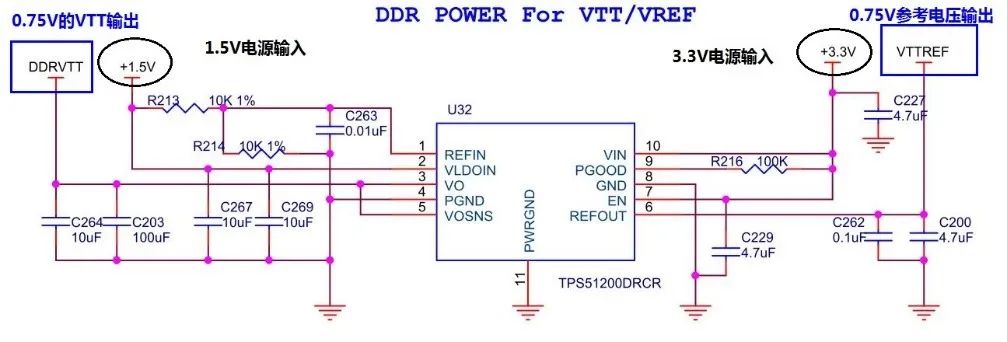
图16:DDR3电源芯片实际使用的原理图
由于FPGA也需要用到1.5V和3.3V的bank电压,因此在系统电源中肯定包含这两种电压,因此1.5V和3.3V可以作为TPS51200的输入,从而产生VREF和VTT,同时1.5V电源还可以作为DDR3的VDD和VDDQ。DDR3芯片的电源管脚连接图如下所示:
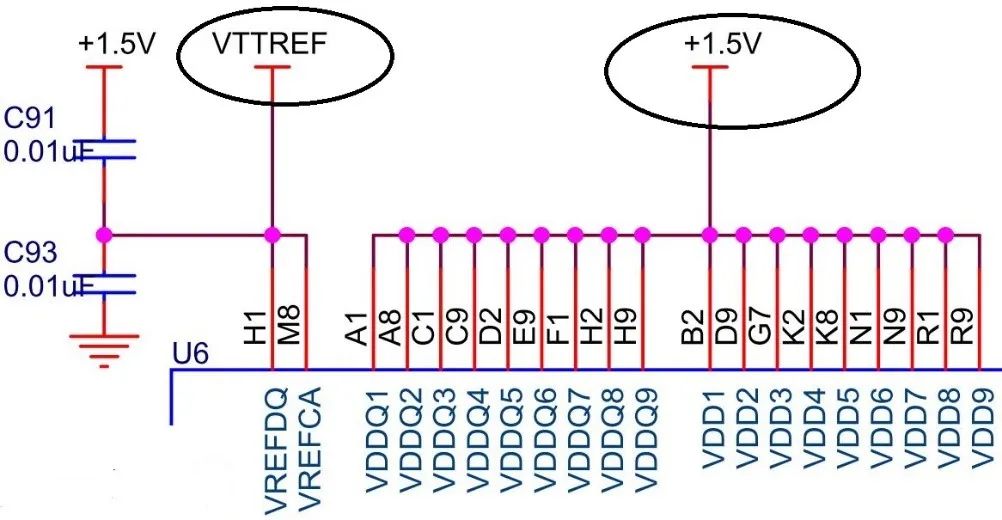
图17:DDR3电源供电连接
另外,适当数量的滤波电容耦合在电源与地之间也是十分必要的,如下图所示:

图18:DDR3电源滤波电容
2) DDR3芯片端的信号设计
DDR3的数据、控制、地址、复位等信号直接接入FPGA的专用bank管脚,具体细节后文介绍。这里需要注意的是,DDR3的内部对数据DQ、LDM、UDM、LDQ以及UDQ信号设计了端接(ODT功能),所以不需要外接匹配电阻,但地址、命令和控制线则最好外接匹配电阻以保证信号完整性,这时就需要VTT了(不是必须的,但推荐加上电阻上拉匹配以保证更稳定,高端FPGA有数控阻抗DCI功能,这时就可以不加外部电阻)。另外DDR3差分时钟来自于FPGA,输入到DDR3时,需要外部100Ω终端匹配、ZQ端口下拉240Ω电阻、RESET#下拉4.7K电阻。如下图所示:
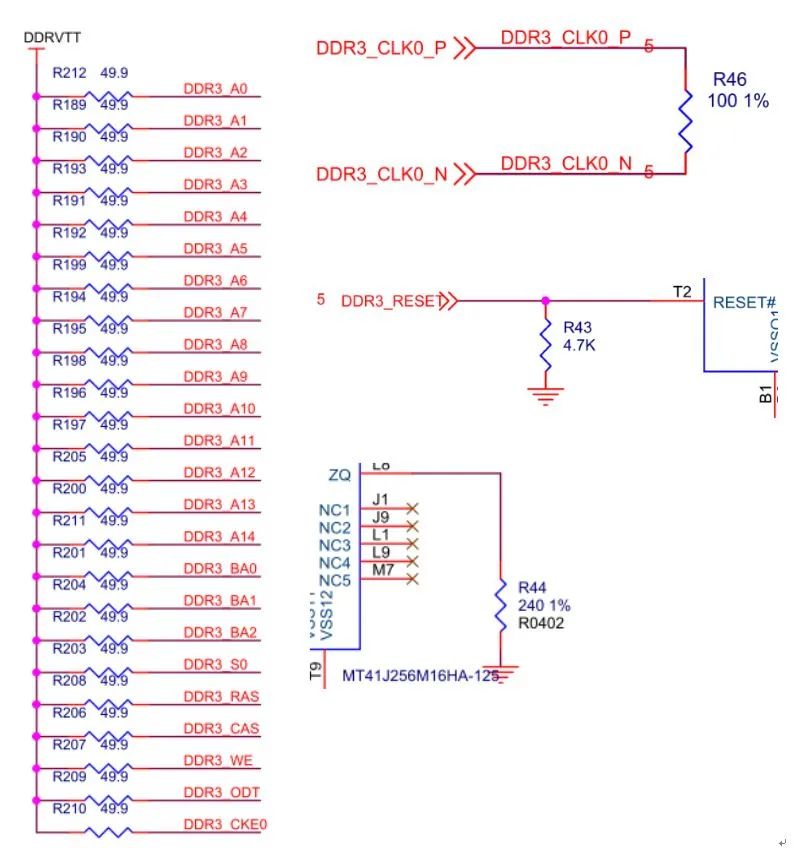
图19:DDR3原路图的地址、控制、时钟等细节
由于本设计采用2片DDR3的设计,因此需要共用时钟、地址、控制、命令等信号,而数据线则并行结合成32bit。如下图所示为两片DDR3的设计:
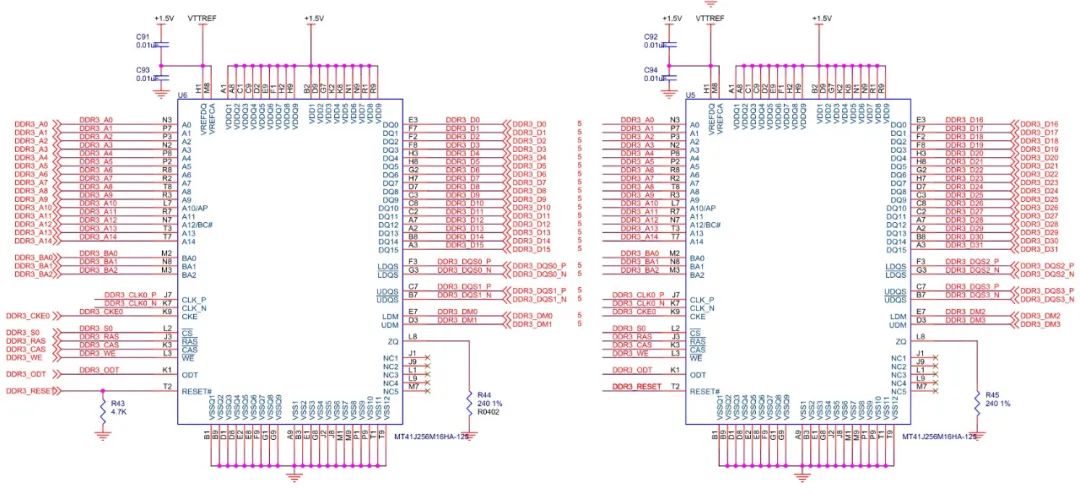
图20:两片DDR3原路图
3) FPGA端的DDR3信号设计
由于DDR3的读写比较复杂,xilinx提供专门的IP来帮助用户快速完成设计。因此DDR3信号接入FPGA时,为了能够调用IP核,硬件连接有许多需要注意的地方,用户可以参考UG586文档中的Design Guidelines(192页)来指导硬件设计。下面具体介绍相关内容:
XilinxFPGA为了支持更高速度的DDR 读写速度,对bank进行了专门的设计。在七系列的FPGA中,每个bank有50个管脚,除去bank顶部和底部的单端管脚外,剩余的48个管脚分成4个字节组,每个字节组里面包含DDR3的一个DQS选通差分信号管脚以及10个信号管脚,共占用12个管脚。在DDR3中,一个DQS选通信号对于8bit数据,因此bank一个字节组里的10个信号管脚中的8个管脚用做8bit数据,还有1个管脚作为DDR3的DM信号,剩下的一个管脚作为设计冗余,如下图所示为FPGA的bank图:
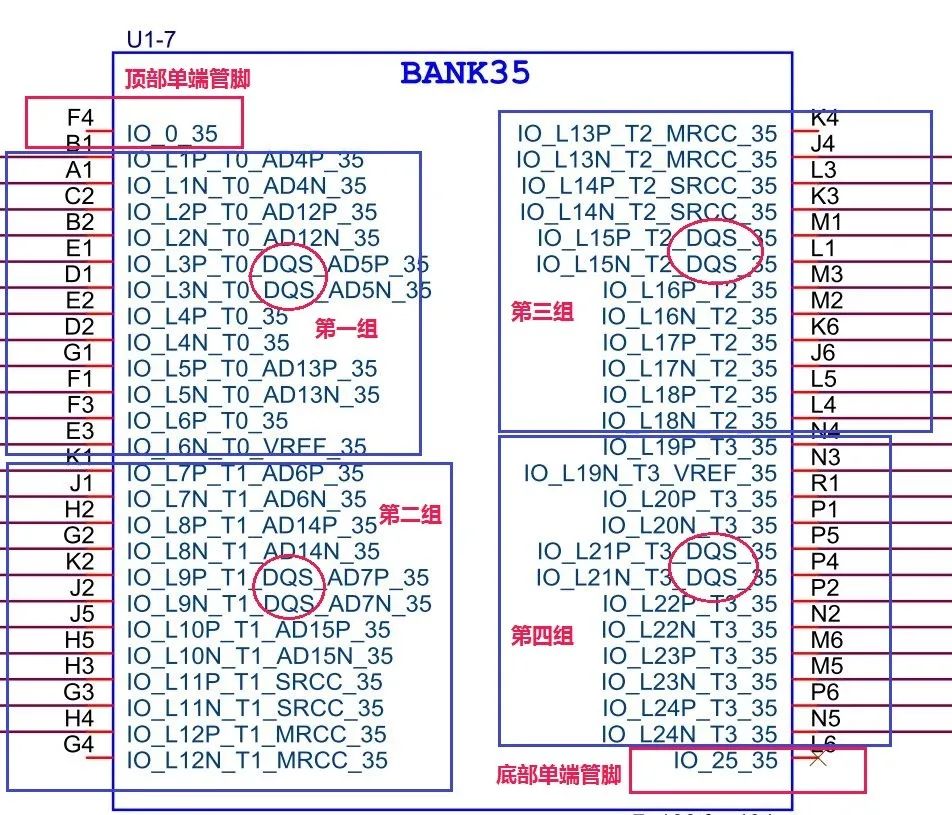
图21:FPGA的bank用作DDR3时的组间分类
Xilinx公司强烈建议用户按照以下方式来进行硬件设计:
-
控制信号(RAS_N, CAS_N, WE_N, CS_N, CKE, ODT)和地址信号不能接入包含数据信号的bank字节组当中。
-
为了获得更高读写速度,数据所在bank的两个VREF管脚需要接入VTT电源。只有当DDR3读写速度不大于800Mb/s时,才可以使用内部VREF,此时两个VREF管脚可以当成普通管脚使用。
查阅7系列FPGA数据手册,可以发现对于xc7a100t-fgg484芯片来说,bank34和bank35属于同一列。因此bank34可以用作时钟、地址、控制、复位等信号接入,bank35则用来接入DQ、DQS以及DM信号。
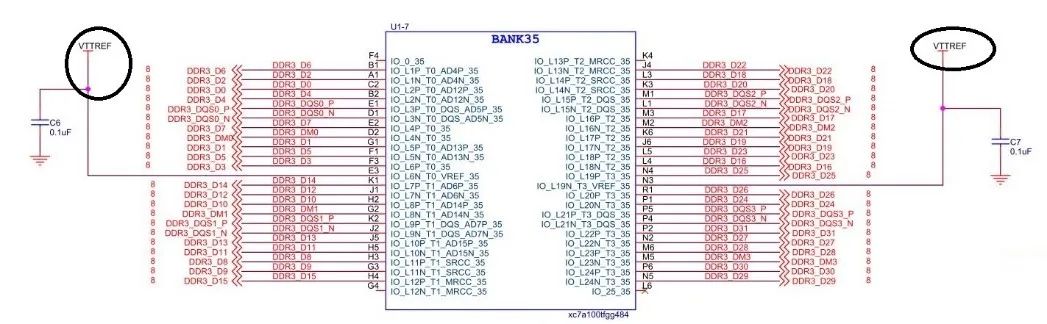
图22:FPGA的DQ、DQS、DM所在bank
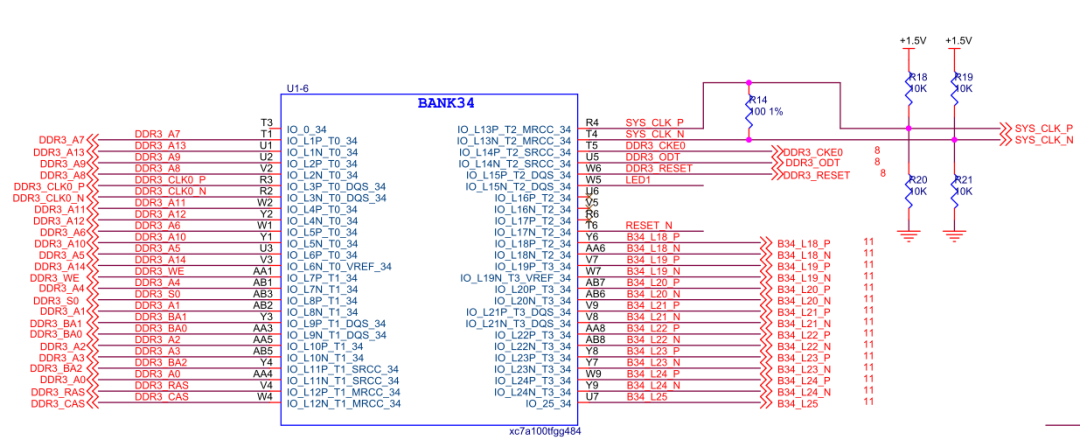
图23:FPGA的地址、控制、时钟所在bank
第四部分:DDR3-FPGA的PCB设计注意事项
在DDR的PCB设计中,一般需要考虑等长和拓扑结构。等长比较好处理,给出一定的等长精度通常是PCB设计师能够完成的。但是对于不同速率的DDR,选择合适的拓扑结构非常关键,在DDR布线中经常使用的有T形拓扑结构、菊花链拓扑结构以及Fly-by拓扑结构。当然,如果只有单片的DDR芯片,那就不需要所谓的拓扑结构了,DDR芯片的信号只需要点对点的和 FPGA管脚连接,保证等长即可。拓扑结构针对的是两片及以上的DDR设计。另外需要说明的是:DDR的DQ、DQS以及DM信号都和FPGA是点对点连接,没有拓扑结构。拓扑结构针对的是时钟、地址、控制这三类信号。
也称为星型拓扑结构,其结构如下图所示。星型拓扑结构每个分支的接收端负载和走线长度尽量保持一致,这就保证了每个分支接收端负载同时收到信号,原则上每条分支上一般都需要终端电阻上拉到VTT,终端电阻的阻值应和连线的特征阻抗相匹配(实际操作时上只在最大T点上拉电阻RT到VTT)。星形拓扑结构可以有效地避免时钟、地址和控制信号的不同步问题。
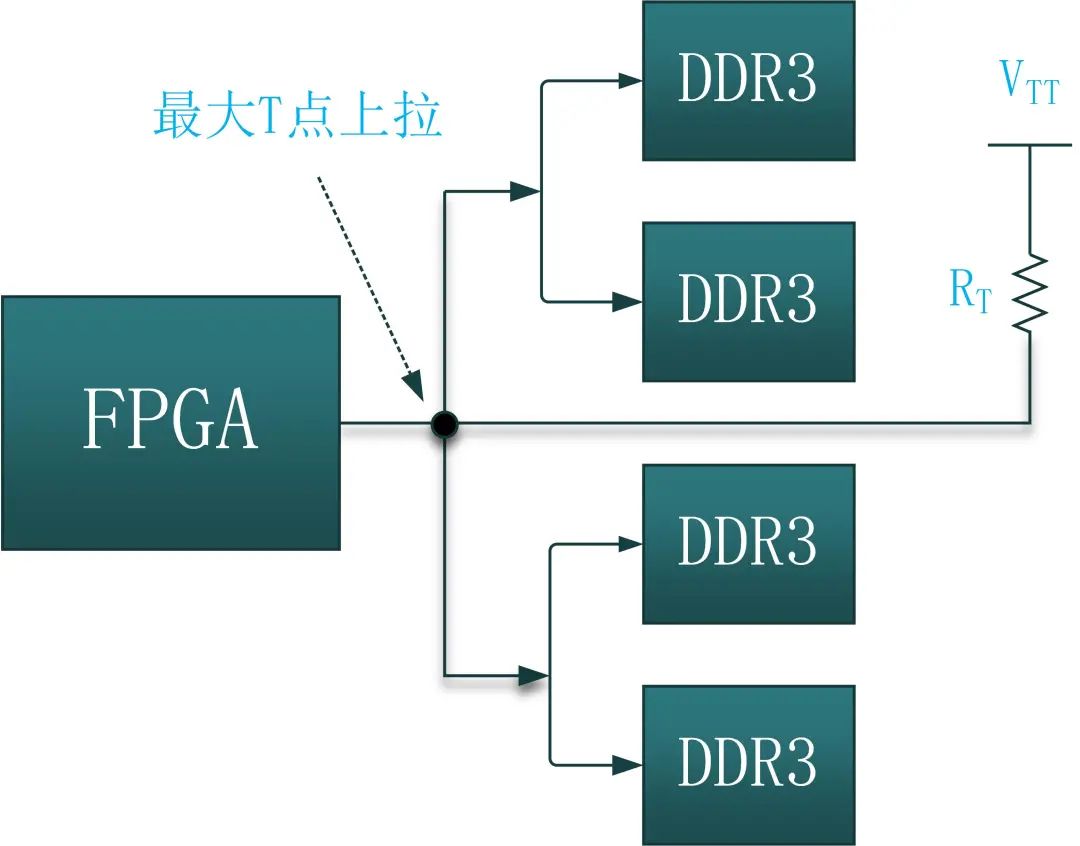
图24:DDR的时钟、控制以及地址信号T型拓扑
和星型拓扑结构不同,菊花链拓扑结构没有保持驱动端到各个负载走线长度尽量一致,而是确保各个驱动端到信号主干道的长度尽量短。菊花链拓扑结构走线的特点,牺牲了时钟、地址、控制信号的同步,但最大的特点是尽可能降低各负载分支走线长度,避免分支信号对主干信号的反射干扰。
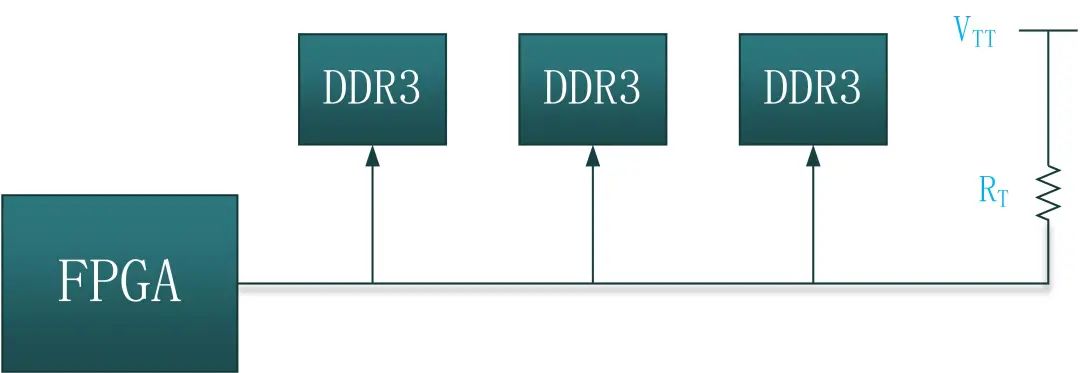
图25:DDR的时钟、控制以及地址信号菊花链型拓扑
在信号频率低于800MHz的情况下,上面两种拓扑结构均能满足系统性能需要。但是当信号速率到达1000MHz甚至更高,T型拓扑结构就不能满足性能需要。原因就在于T型拓扑结构过长的支路走线长度,在不添加终端电阻的情况下很难和主干道实现阻抗匹配,而为了实现各个支路的阻抗匹配添加终端电阻,又加大了电路设计的工作量和成本,是我们不愿意看到的。因此高速信号使用T型拓扑结构,特别是Stub>4的时候,支路信号对主干信号的反射干扰是很严重的。通常DDR2使用和速率要求不高的DDR3使用T型拓扑结构。菊花链拓扑结构主要在DDR3中使用,菊花链拓扑结构的主要优势是支路走线短,一般认为菊花链支路走线长度小于信号上升沿传播长度的1/10,可以有效削弱支路信号反射对主干信号的干扰,不同的书本上说法也不一样,大体上走线长度小于上升沿传播长度的1/6-1/10都是可以的,实际设计中我们肯定希望这个长度越短越好。菊花链拓扑结构可以有效抑制支路的反射信号,但相对于T型拓扑结构,菊花链拓扑结构的时钟、地址和控制信号并不能同时到达不同的DDR芯片。为了解决菊花链拓扑结构信号不同步的问题,DDR3的新标准中加入了时间补偿技术,通过DDR3内部调整实现信号同步。当信号频率高达1600MHz的时候,T型拓扑结构已经无能为力,只有菊花链或其衍生的拓扑结构能满足这样的性能需求。一般的DDR3都会建议采用菊花链拓扑结构的改进型拓扑结构,Fly-by拓扑结构,如下图所示。Fly-by拓扑结构要求支路布线长度Stub=0,Fly-by具有更好的信号完整性。
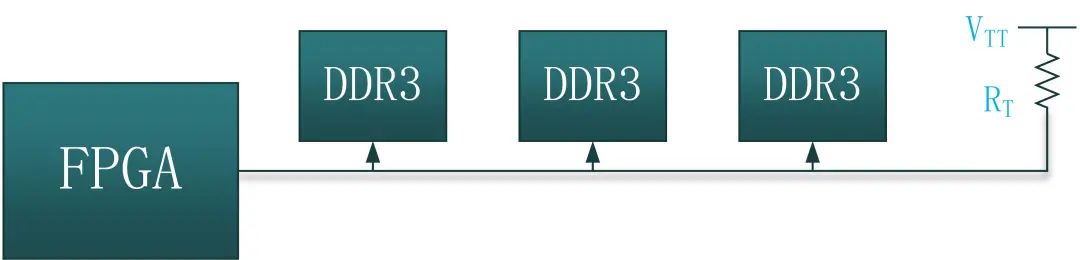
图26:DDR的时钟、控制以及地址信号Fly-by型拓扑
在菊花链拓扑的实际应用中,为了抑制Stub过长和分支太多对主干信号的反射干扰,以及加强主干信号驱动能力,一般在末端预留端接电阻电路。末端下拉电阻会增大IO口驱动功耗,所以采用末端上拉电阻的方式进行端接。计算信号驱动部分的戴维南等效电压作为上拉电压Vtt,Rt为驱动部分的等效电阻,通常上拉电压取值为IO驱动电压的一般,即Vtt=Vddr/2。
如下图所示为数据、时钟、控制以及地址的T型拓扑结构图:
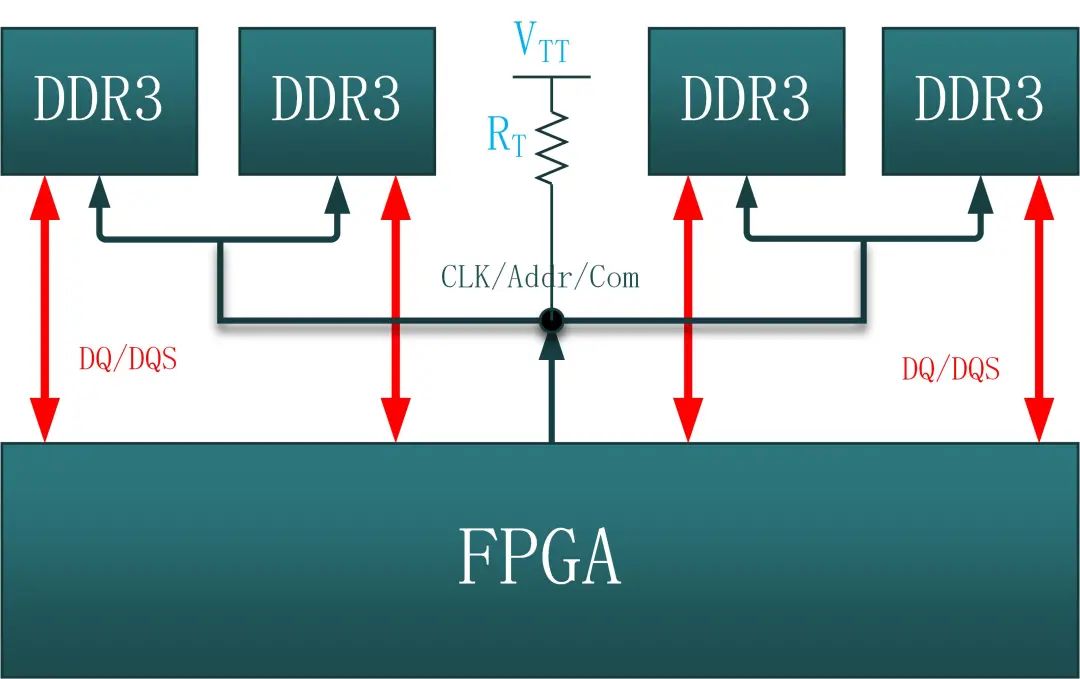
图27:T型拓扑整体结构
如下图所示为数据、时钟、控制以及地址的Fly-by型拓扑结构图:
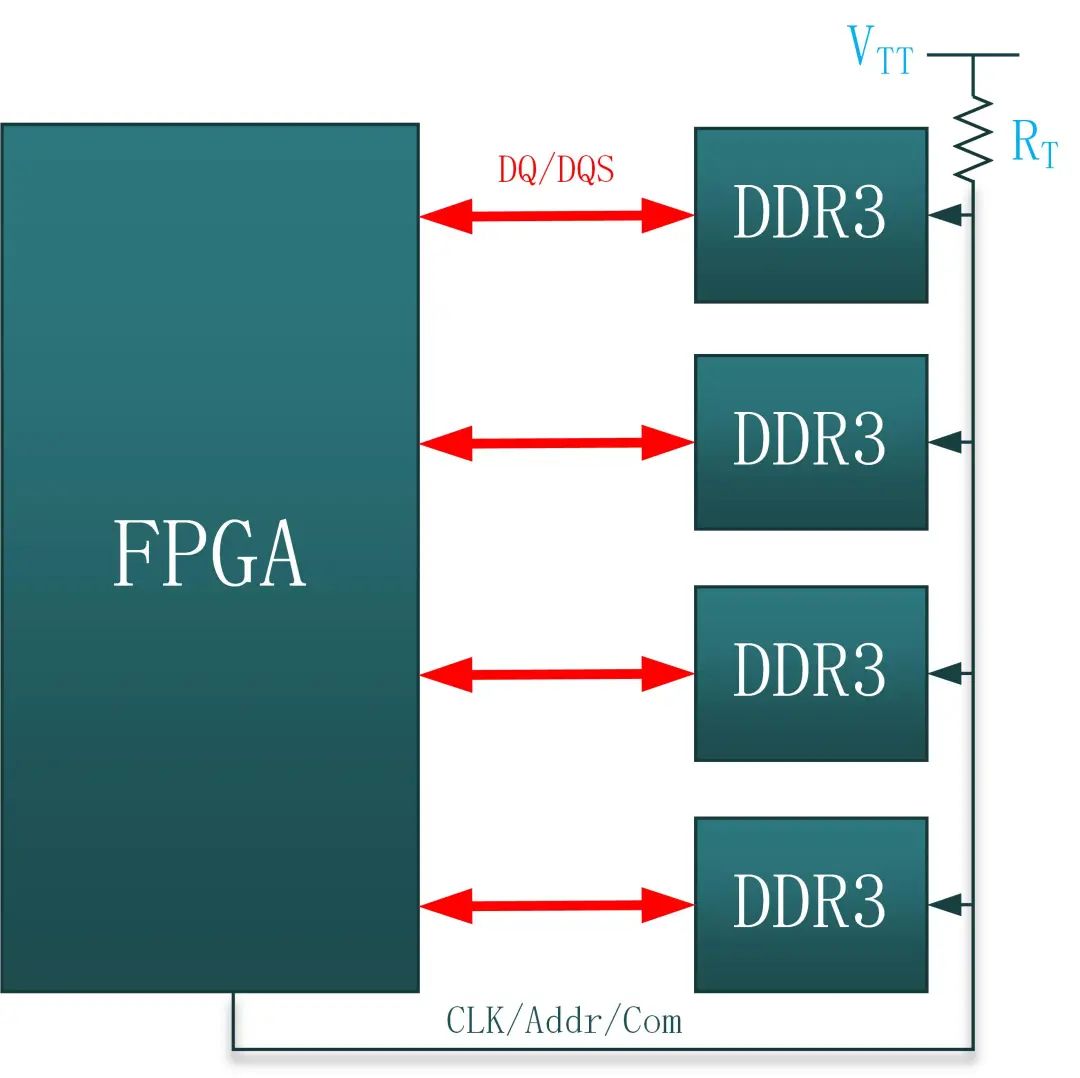
图28:Fly-by型拓扑整体结构
一般来说,对于2~4片的DDR3设计来说,T型和Fly-by拓扑结构布线都可以,但是当超过4片DDR3后,T型结构已经不能满足要求。所以笔者建议只要不是单片的DDR3设计,拓扑结构都用Fly-by就好。对于Fly-by拓扑结构的布线设计具体来说:
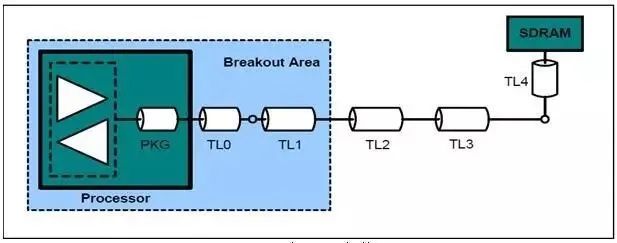
图29:Fly-by拓扑结构中的DQ、DM连接方式
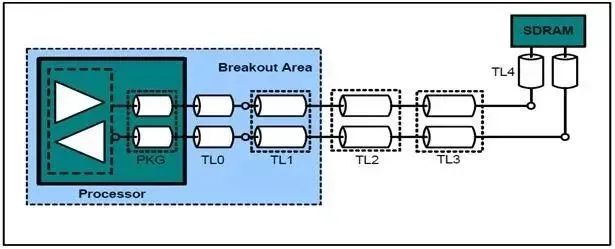
图30:Fly-by拓扑结构中的DQS连接方式

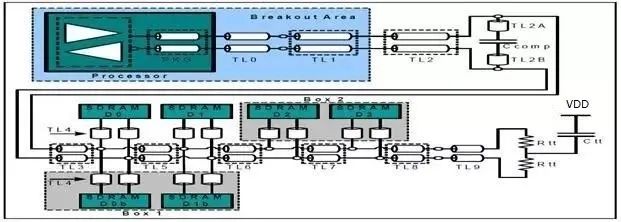
图31:Fly-by拓扑结构中的时钟连接方式
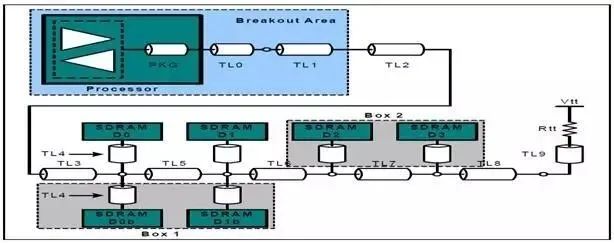
图32:Fly-by拓扑结构中的地址、控制信号连接方式
如下为网友提供的几张T型和Fly-by的PCB走线,仅供参考:

图33:T型拓扑

图34:T型拓扑
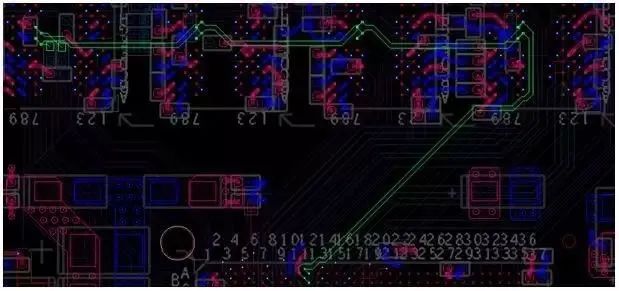
图35:Fly-by拓扑
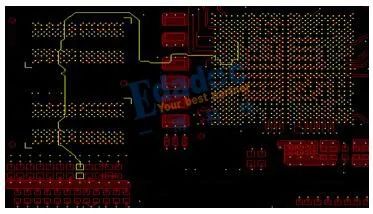
图36:Fly-by拓扑
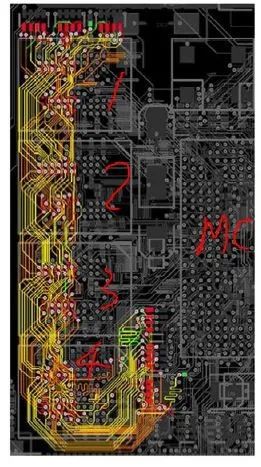
图37:Fly-by拓扑
第五部分:DDR3-FPGA读写设计
博主在进行读写设计时,利用黑金的AX7102开发板,FPGA型号为xc7a100t-fgg484,板载两片DDR3,共8Gb存储空间,具体型号是micron公司的MT41J256M16HA-125。下面记录读写设计的过程:
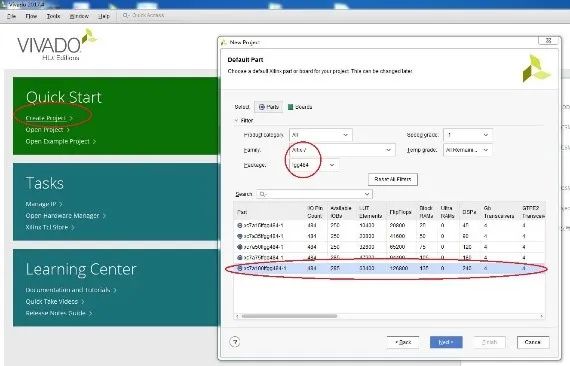
1.在vivao中新建一个工程,选择对应的FPGA:
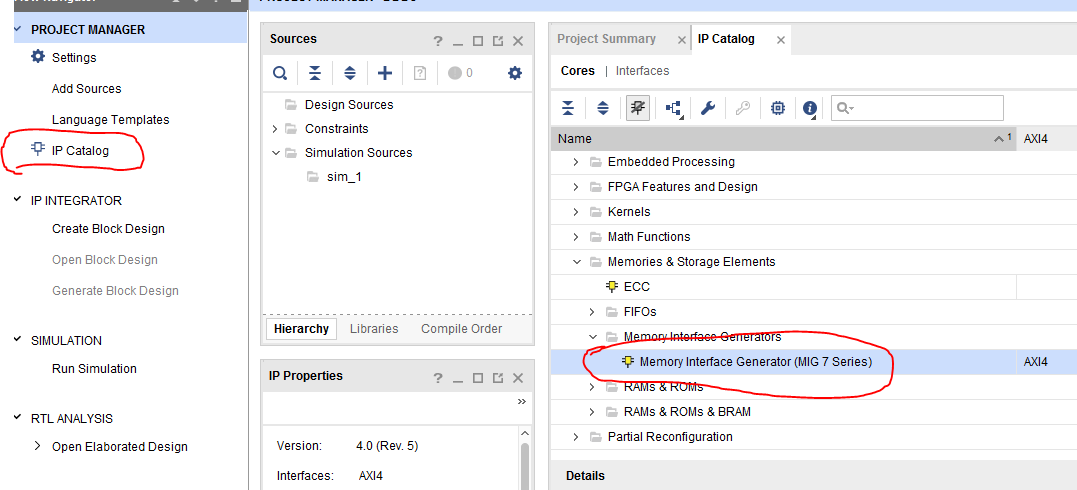
2.添加MIG(memoryinterface generator)的IP核
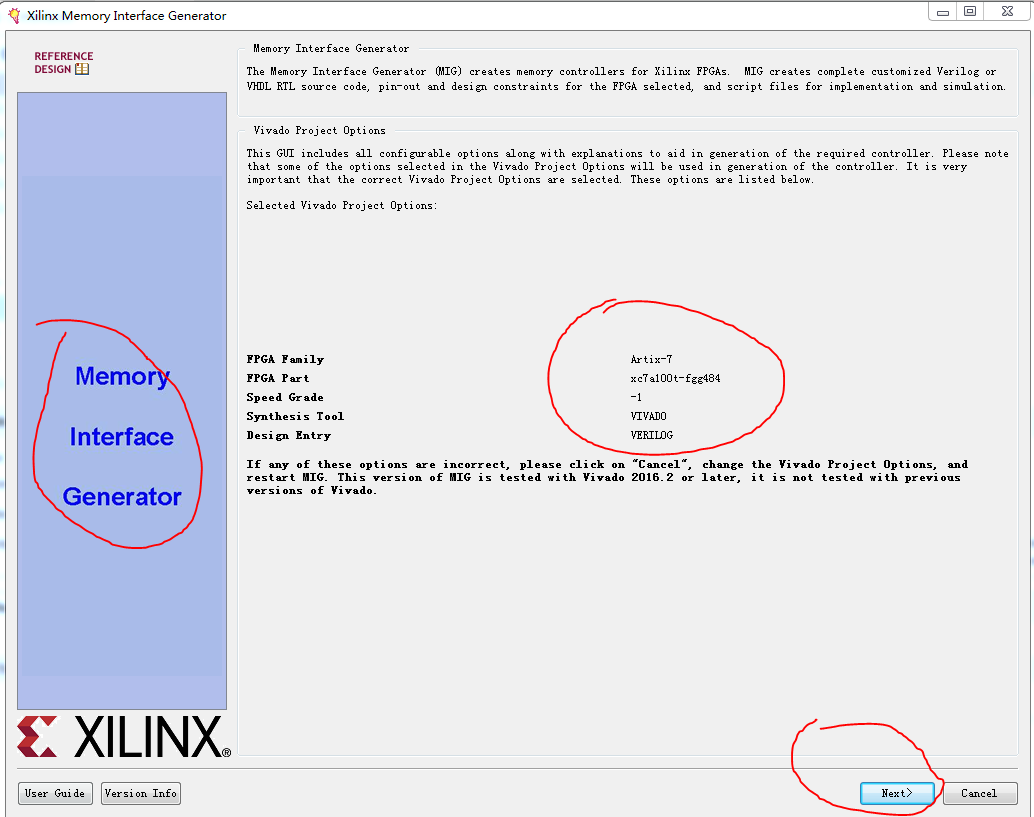
3.双击该IP核后,会出现配置界面,首页显示的是用户选择的FPGA型号。确认无误后,点击next:
4.该界面的配置如下图所示:
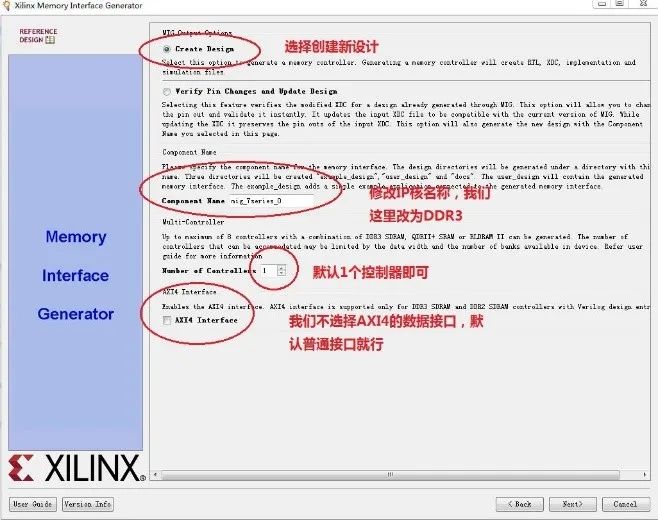
5.该界面配置如图所示:
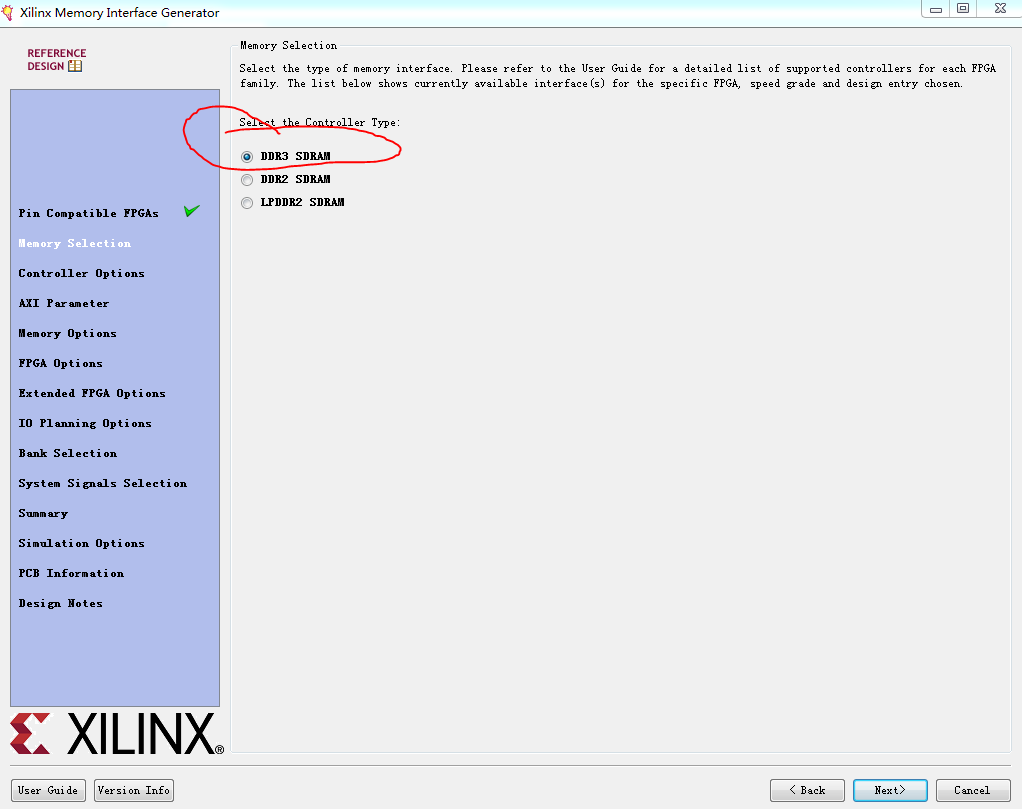
6.硬件芯片是DDR3,因此该界面的配置选择DDR3 SDRAM即可,如下图所示:
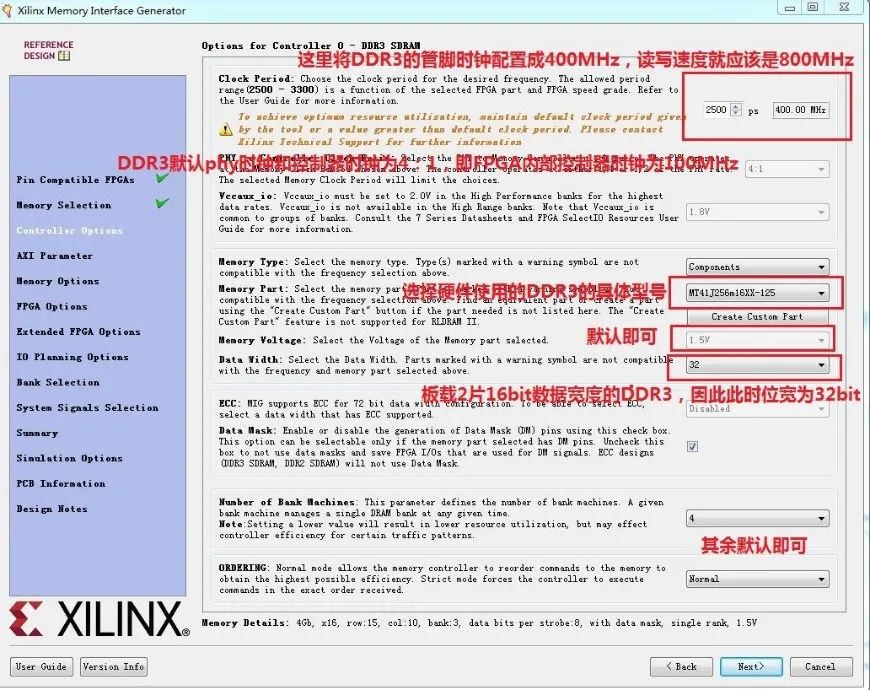
7.接下来是配置的重头戏:
8.设置系统输入时钟,来自于200MHz差分晶振:

9.如下图所示:
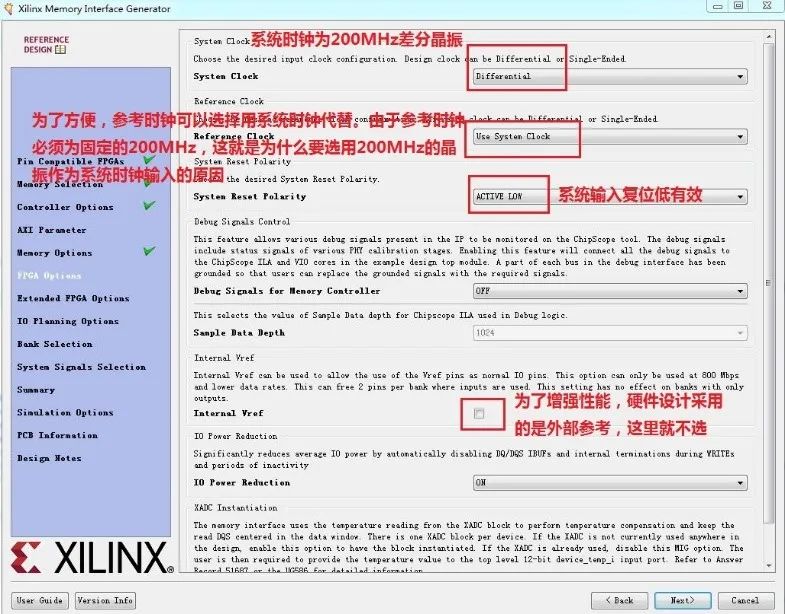
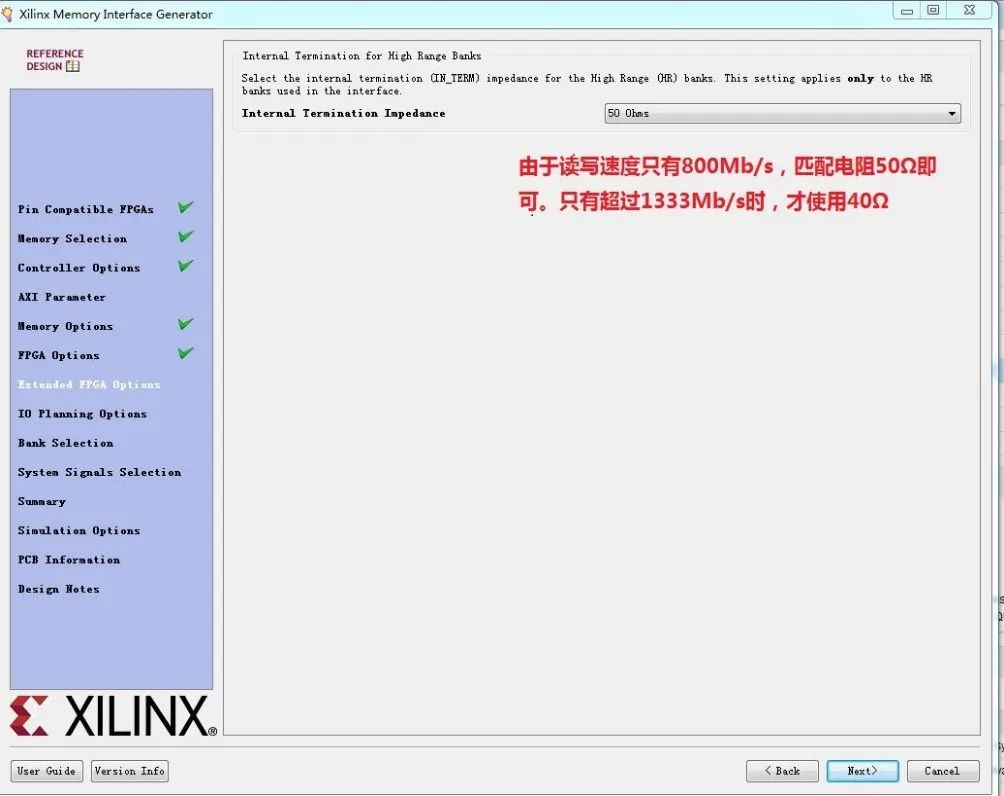
10.如下图所示:
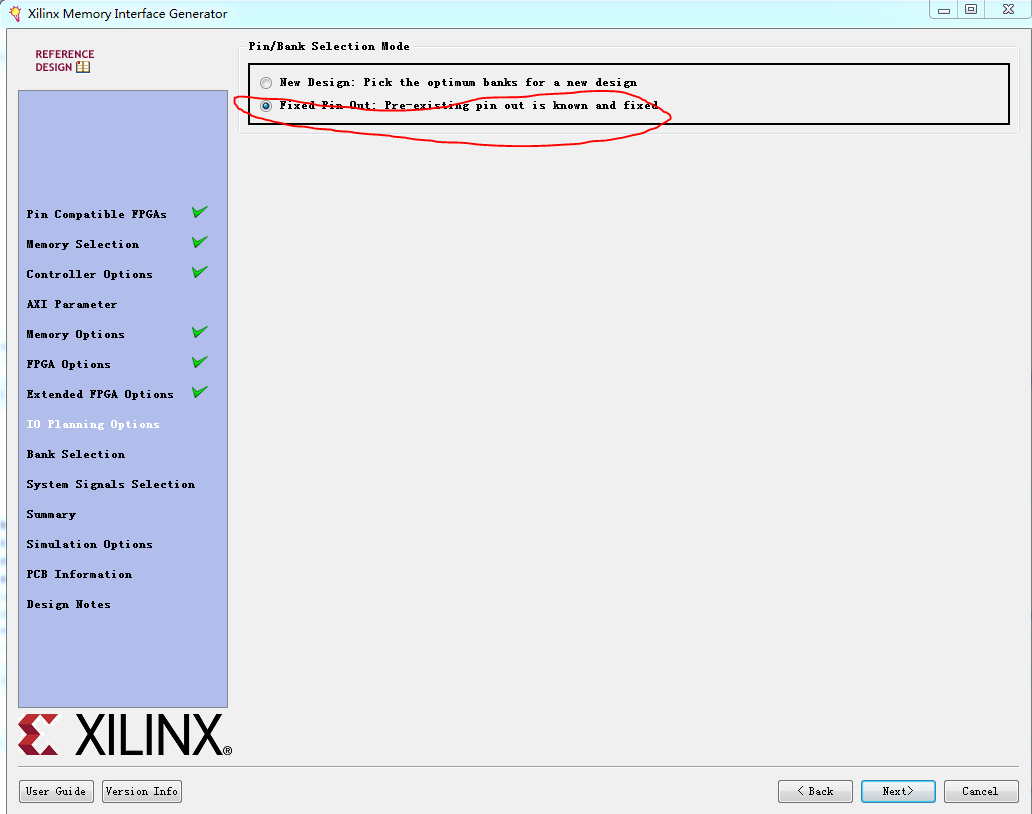
11.接下来根据FPGA硬件的管脚定义来配置IP核的信号,我们选择“FixedPin Out”
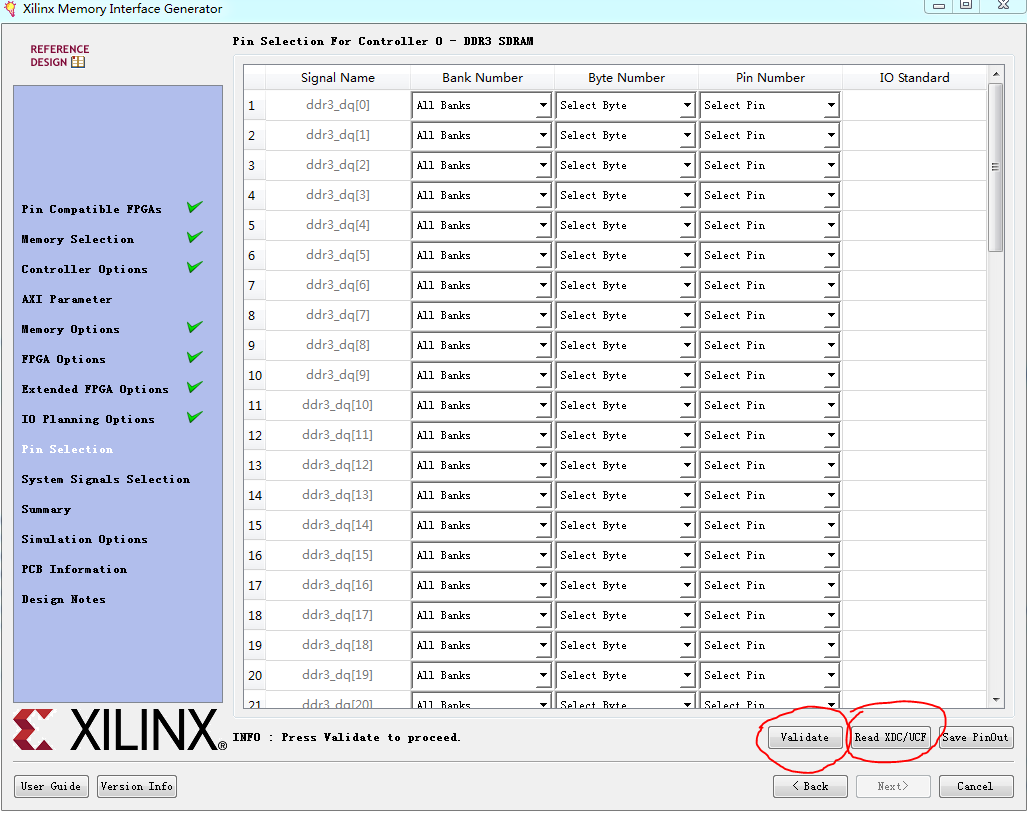
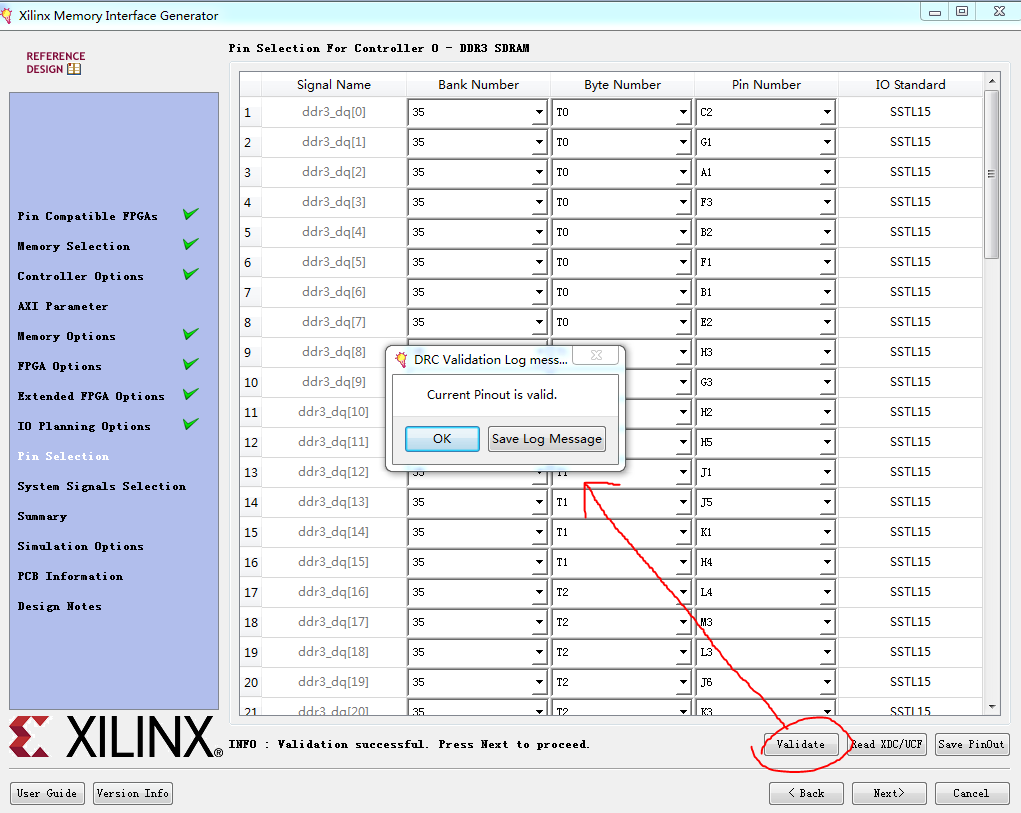
12.开始一个个的输入DDR3信号对应的管脚,如果事先写好了管脚约束文件,也可以直接载入。填写完成后,点击“Validate”检查,看写的是否有误。
13.下图是本人填好管脚定义后的界面,检查过后显示无误后,进入下一步:
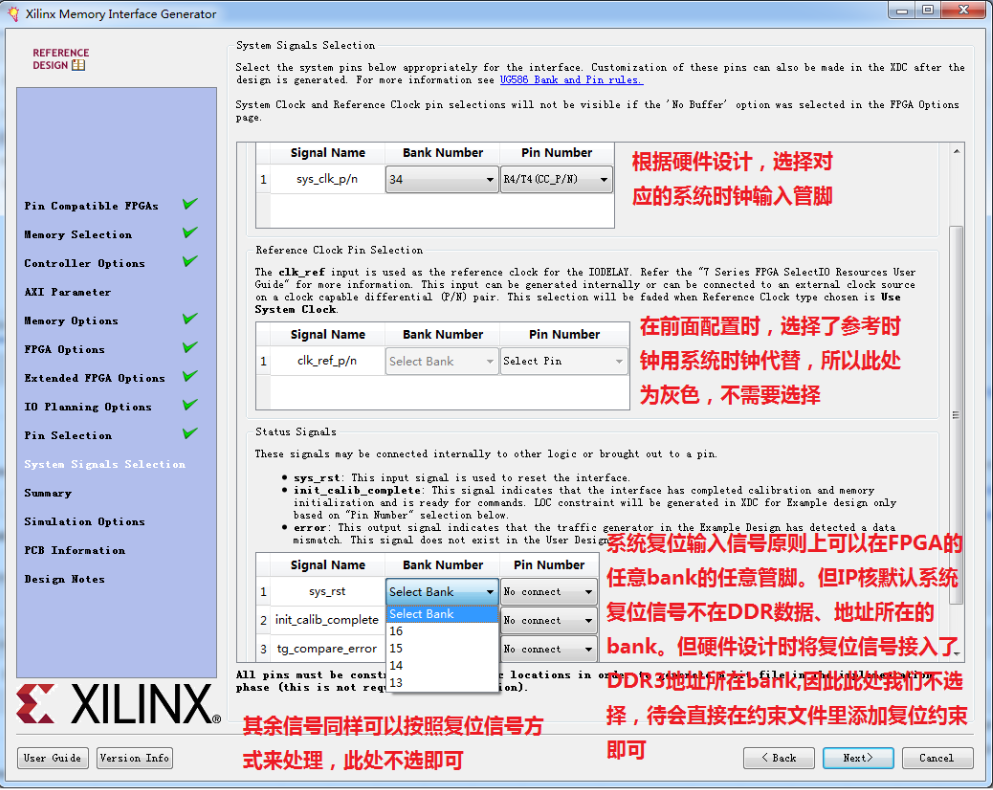
14.定义系统时钟输入、参考时钟输入以及系统复位管脚位置:
15.到这里就配置完成了,该界面显示配置的IP核的信息,用户可以查看:
16.该界面毫无意义,直接点“accept”即可:
17.接下来就没啥了,一直“next”,最后点击“genereate”生成IP核。
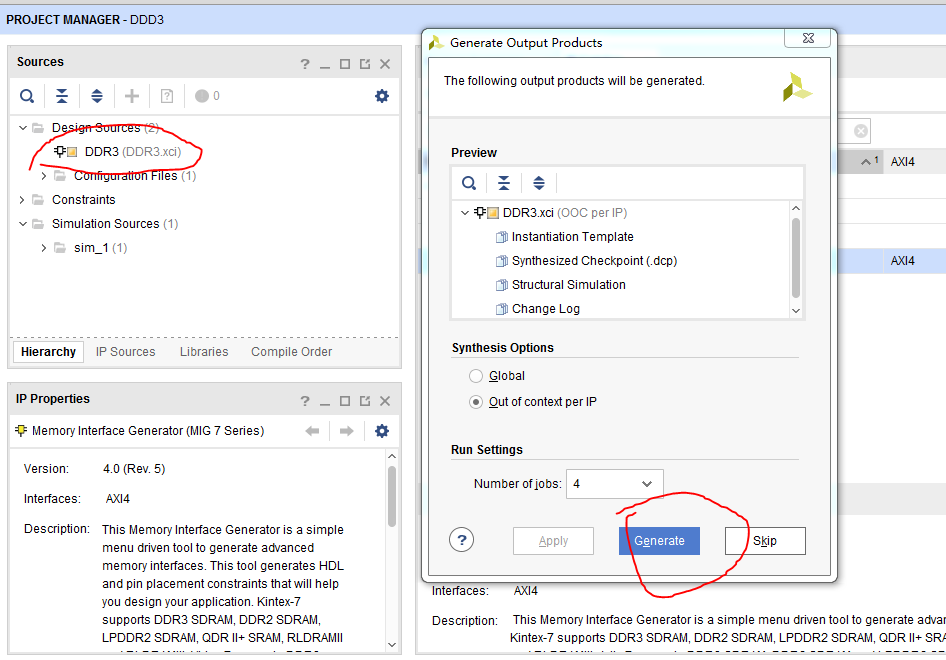
18.在工程界面新建一个顶层约束文件“DDR3_TOP.xdc”,然后在工程界面选择“IP source”,点开DDR3IP核的下拉列表,在“synthesis”里打开“DDR3.xdc”,复制其中全部的约束内容到顶层约束文件中,并在顶层约束文件中添加系统复位和任意一个状态显示的管脚(随意选择一个管脚,这不重要,只是为了确保后面提到的逻辑不被综合掉,便于chipscope查看)即可。

19.新建工程的顶层文件“DDR_TOP.V”和用于测试DDR3 读写性能的子模块“mem_burst.v”,如下图所示:
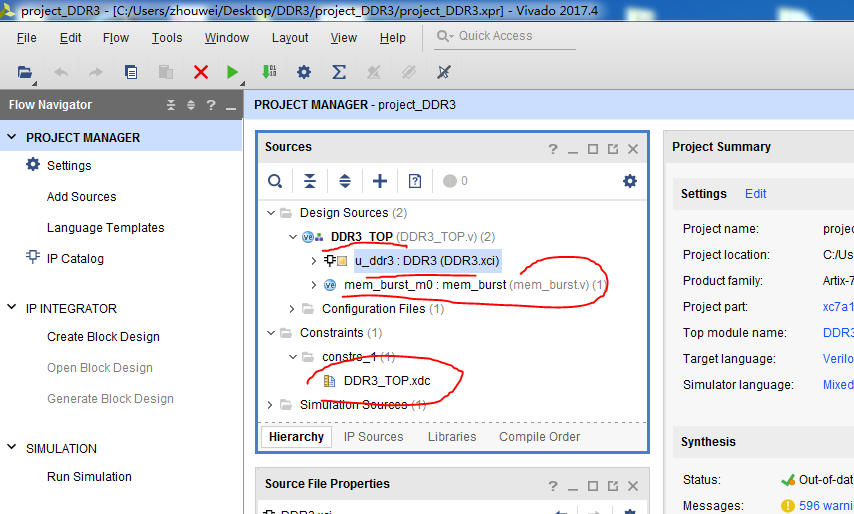
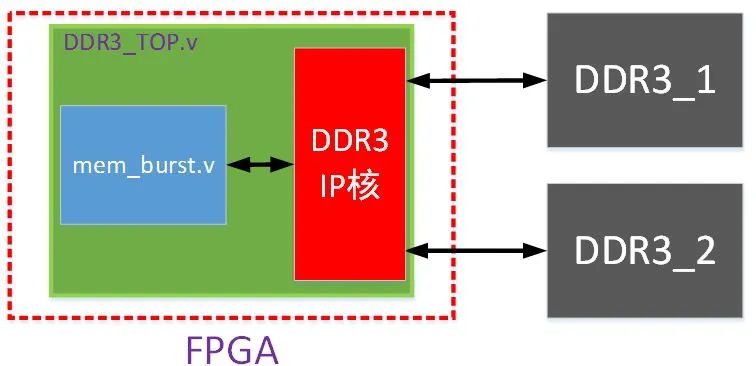
20.工程文件之间的具体关系如下图所示,利用mem_burst.v实现对两片16bit位宽的DDR3同时读写,也就是对32bit位宽的一片DDR3读写,读写容量为8Gb。
21.下面给出顶层文件“DDR_TOP.V”的完整代码:
moduleDDR3_TOP(
//
inout [31:0] ddr3_dq,//32bit的DDR3并行数据输入/输出端口
inout[3:0] ddr3_dqs_n,//由于DDR3每8bit数据会对应一个数据选通信//号,因此这里是4bit数据选通信号,且选通信号是差分输入/输出端口
inout [3:0] ddr3_dqs_p,//数据选通信号p端
//
output [14:0] ddr3_addr,//FPGA控制DDR3的15bit地址线
output [2:0] ddr3_ba,// FPGA控制DDR3的3bit bank地址线
output ddr3_ras_n,// FPGA控制DDR3的行选通控制信号
output ddr3_cas_n, // FPGA控制DDR3的列选通控制信号
output ddr3_we_n, // FPGA控制DDR3的读/写使能控制信号
output ddr3_reset_n, // FPGA控制DDR3的复位信号
output ddr3_ck_p, // FPGA控制DDR3的读/写差分时钟
output ddr3_ck_n, //
output ddr3_cke, // FPGA控制DDR3的差分时钟使能
output ddr3_cs_n, // FPGA控制DDR3的片选信号
output [3:0] ddr3_dm, // FPGA控制DDR3的mask信号,每8bit数据会//对应一个数据mask信号
output ddr3_odt, // FPGA控制DDR3的片上匹配电阻
//
input sys_clk_p,//FPGA系统工作时钟,必须为200MHz差分晶振输入
input sys_clk_n,
output error,//随意指定的一个FPGA管脚,只是为了内部chipscope观//察的信号不被综合优化掉
input sys_rst// FPGA系统复位输入,按照DDR3的IP设置,必须低电//平有效
);
localparam nCK_PER_CLK = 4;//DDR3管脚时钟和内部时钟的比值,为固定值4,如果是//DDR2,则为2,如果是DDR则为1.
localparam DQ_WIDTH = 32;//DDR3数据位宽,在本设计为两片16bit的DDR3组合成//32bit的数据位宽
localparam ADDR_WIDTH= 29;//读写DDR3的地址,根据IP核的定义,这里的地址为//1bit rank+3bit bank+15bit row address + 10bit row address =29bit
localparam DATA_WIDTH= 32;//FPGA操作时的数据位宽为32bit
localparamAPP_DATA_WIDTH = 2 * nCK_PER_CLK * DATA_WIDTH;//DDR3 IP核的数据//位宽为256 BIT,因为8倍预取数据的原因,所以IP核一次读写的数据为8*32bit
localparamAPP_MASK_WIDTH = APP_DATA_WIDTH / 8;//每8bit数据对应1bit mask信号,因此这里共32BIT mask信号
wire init_calib_complete;//板卡上电后,DDR3 IP核会对DDR初始化校正,完成之后IP核拉高此信号,因此用户只有监测到该信号为高电平后才能对DDR进行读写操作,PHY asserts init_calib_complete when calibration is finished.
wire[ADDR_WIDTH-1:0] app_addr;//IP核读写地址输入:29bit=1bit rank+3bit bank+15bit row address + 10bit row address,对于本设计来说,rank值为0.
wire[2:0] app_cmd;//3bit的IP核操作码输入,000为写命令,001为读命令
wire app_en;//IP核的命令使能输入:Thisis the active-High strobe for the app_addr[], app_cmd[2:0] inputs.
wire app_rdy;// //IP核输出的命令ready信号:This output indicates that the UI is ready to accept commands. Ifthe signal is deasserted when app_en is enabled, the current app_cmd andapp_addr must be retried until app_rdy is asserted.
wire[APP_DATA_WIDTH-1:0] app_rd_data;//IP核的256bit数据输入或输出
wire app_rd_data_end;// This active-High outputindicates that the current clock cycle is
thelast cycle of output data on app_rd_data[]. This is valid only when app_rd_data_validis active-High.
wire app_rd_data_valid;// This active-High outputindicates that app_rd_data[] is valid.
wire[APP_DATA_WIDTH-1:0] app_wdf_data;// This provides the data for write commands.
wire app_wdf_end;//This active-High input indicates that the current clock cycle is the last cycleof input data on app_wdf_data[].
wire[APP_MASK_WIDTH-1:0] app_wdf_mask;// This provides the mask for app_wdf_data[].
wire app_wdf_rdy;//This output indicates that the write data FIFO is ready to receive data. Writedata is accepted when app_wdf_rdy = 1’b1 and app_wdf_wren = 1’b1.
wire app_sr_active;//This output is reserved.
wireapp_ref_ack;// This active-High input requests that a refresh command be issuedto the DRAM.
wireapp_zq_ack;// This active-High output indicates that the Memory Controller hassent the requested ZQ calibration command to the PHY interface.
wireapp_wdf_wren;// This is the active-High strobe for app_wdf_data[].
wire clk;// This UI clock must be a quarter of the DRAM clock. DDR3 IP核输出的用户时钟,这里为100MHz
wire rst;// This is the active-High UI reset. IP核提供给用户的复位信号
DDR3 u_ddr3(
// Memory interface ports
.ddr3_addr (ddr3_addr),
.ddr3_ba (ddr3_ba),
.ddr3_cas_n (ddr3_cas_n),
.ddr3_ck_n (ddr3_ck_n),
.ddr3_ck_p (ddr3_ck_p),
.ddr3_cke (ddr3_cke),
.ddr3_ras_n (ddr3_ras_n),
.ddr3_we_n (ddr3_we_n),
.ddr3_dq (ddr3_dq),
.ddr3_dqs_n (ddr3_dqs_n),
.ddr3_dqs_p (ddr3_dqs_p),
.ddr3_reset_n (ddr3_reset_n),
.init_calib_complete(init_calib_complete),
.ddr3_cs_n (ddr3_cs_n),
.ddr3_dm (ddr3_dm),
.ddr3_odt (ddr3_odt),
// Application interface ports
.app_addr (app_addr),
.app_cmd (app_cmd),
.app_en (app_en),
.app_wdf_data (app_wdf_data),
.app_wdf_end (app_wdf_end),
.app_wdf_wren (app_wdf_wren),
.app_rd_data (app_rd_data),
.app_rd_data_end (app_rd_data_end),
.app_rd_data_valid (app_rd_data_valid),
.app_wdf_rdy (app_wdf_rdy),
.app_sr_req (1'b0),//以下三个信号输入都设置为0,让IP自己控制,我们不用插手
.app_ref_req (1'b0),
.app_zq_req (1'b0),
.app_sr_active (app_sr_active),
.app_ref_ack (app_ref_ack),
.app_zq_ack (app_zq_ack),
.ui_clk (clk),
.ui_clk_sync_rst (rst),
.app_wdf_mask(app_wdf_mask),
// System Clock Ports
.sys_clk_p (sys_clk_p),
.sys_clk_n (sys_clk_n),
.sys_rst (sys_rst)
);
mem_burst
#(
.MEM_DATA_BITS (APP_DATA_WIDTH),
.ADDR_BITS(ADDR_WIDTH)
)
mem_burst_m0
(
.rst (rst), /*复位,来自于IP核*/
.mem_clk (clk), /*用户时钟,来自于IP核*/
///
.app_addr (app_addr),//DDR3的读写其实就是对以下这几个信号的操作,具体如何操作在子文件“mem_burst.v”文件中给出
.app_cmd (app_cmd),
.app_en (app_en),
.app_wdf_data (app_wdf_data ),
.app_wdf_end(app_wdf_end ),
.app_wdf_mask(app_wdf_mask),
.app_wdf_wren(app_wdf_wren),
.app_rd_data(app_rd_data),
.app_rd_data_end (app_rd_data_end),
.app_rd_data_valid (app_rd_data_valid ),
.app_rdy(app_rdy),
.app_wdf_rdy(app_wdf_rdy),
.init_calib_complete(init_calib_complete),
.error(error)
);
Endmodule
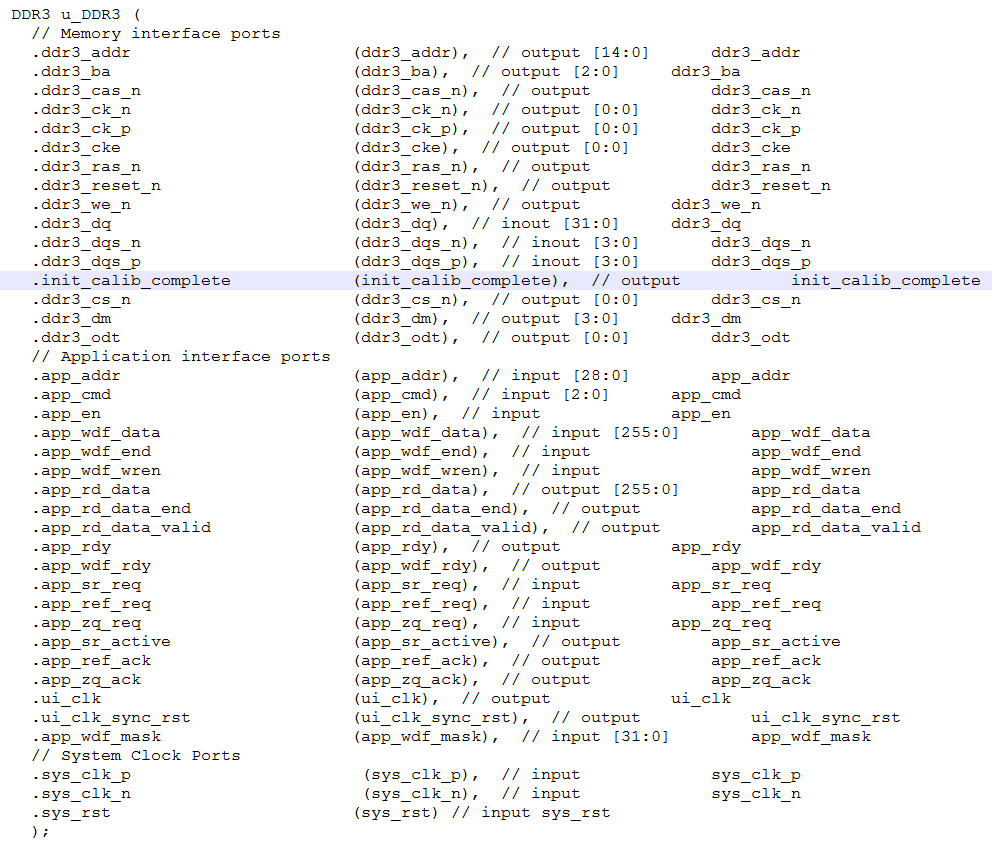
22.下面给出DDR3的例化接口文件:(没啥可说的,操作它就行了)
23.下面给出子文件“mem_burst.v”的具体内容,该文件就是对DDR3的IP核进行读写操作,间接控制两片DDR3的读写,首先看看该文件的接口:
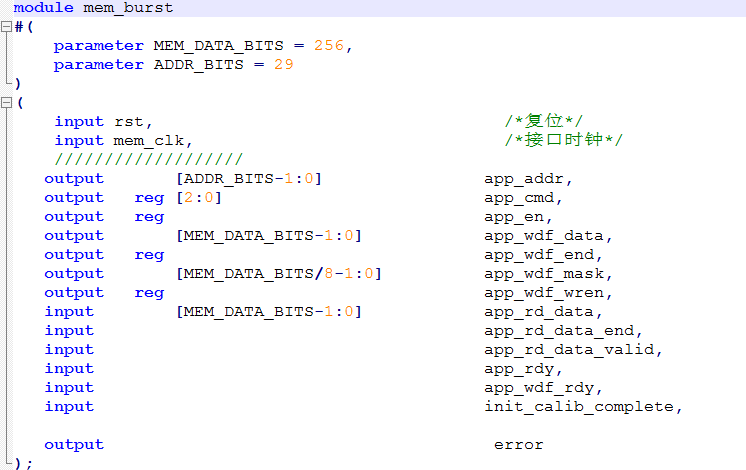
24.接下来对一些内部定义的信号以及该代码的思路介绍一下:

25.接下来我们需要如何读写,这里插入UG586介绍的读写时序,首先介绍写时序:
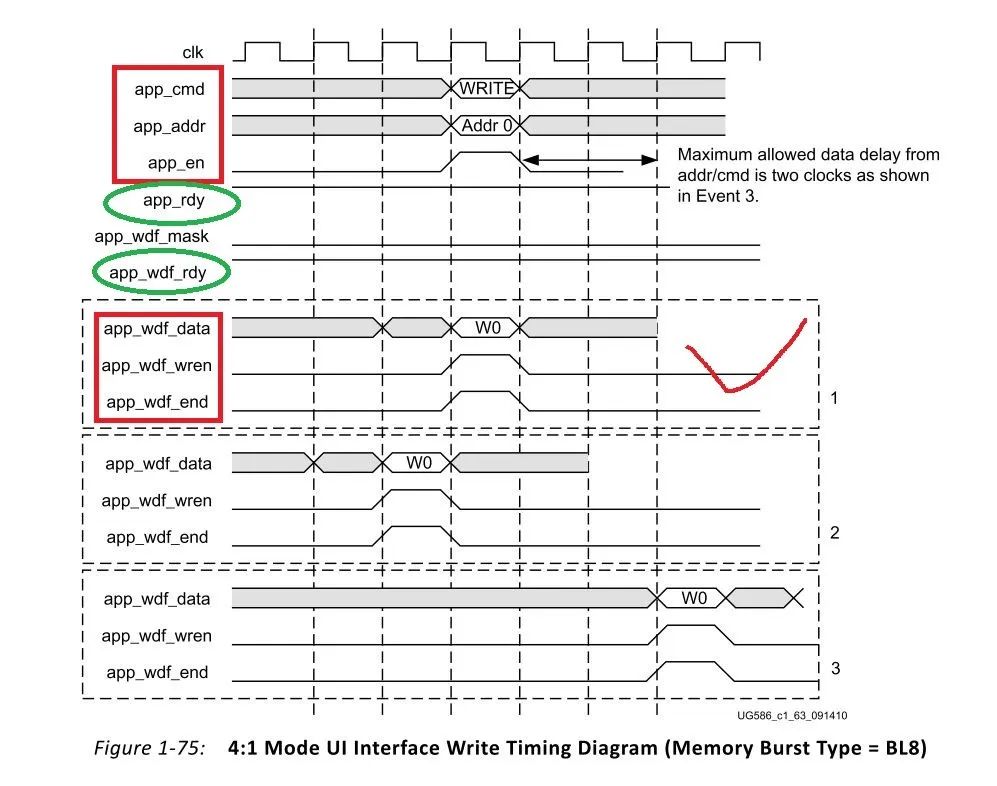
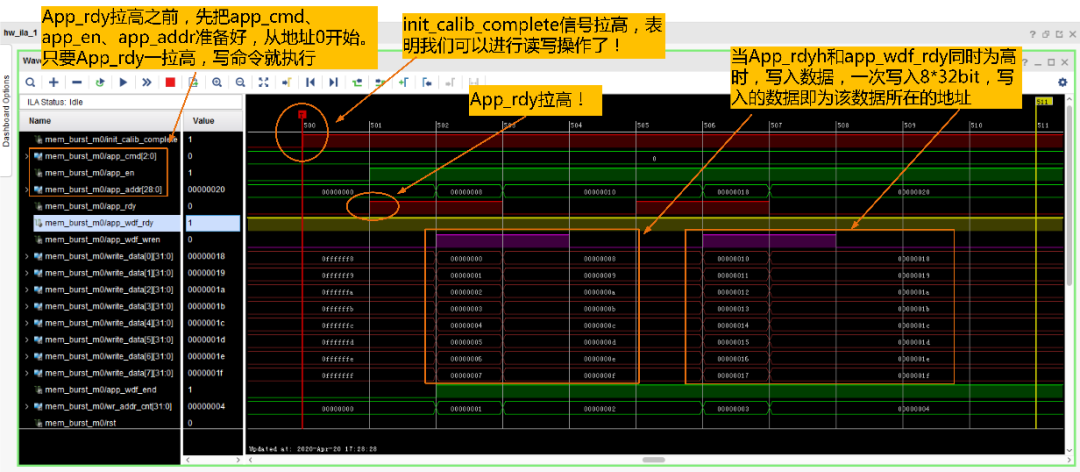
按照UG586的说明,当app_rdy为高时,将app_cmd,app_addr以及app_en拉高,此时,写命令发出。在写命令发出之前周期、当前周期或者之后3个周期之内,用户可以进行写操作。写操作执行过程同样是:当app_wdf_rdy为高时,将app_wdf_data,,app_wdf_wren以及app_wdf_end拉高,此时写操作成功。
关键:写数据和写命令是独立运行的,控制器内部有一个数据FIFO缓存用户写入的数据,因此只要数据FIFO的“app_wdf_rdy”为高,就表明FIFO可以写入数据。所以写数据可以提前于写命令操作,大家可以认为用户每发一个写命令,控制器就读FIFO里的一个数发送到DDR3。因此写数据和写命令时序不相关,只要保证写命令执行的时候,数据FIFO中有数据供控制器操作就行!
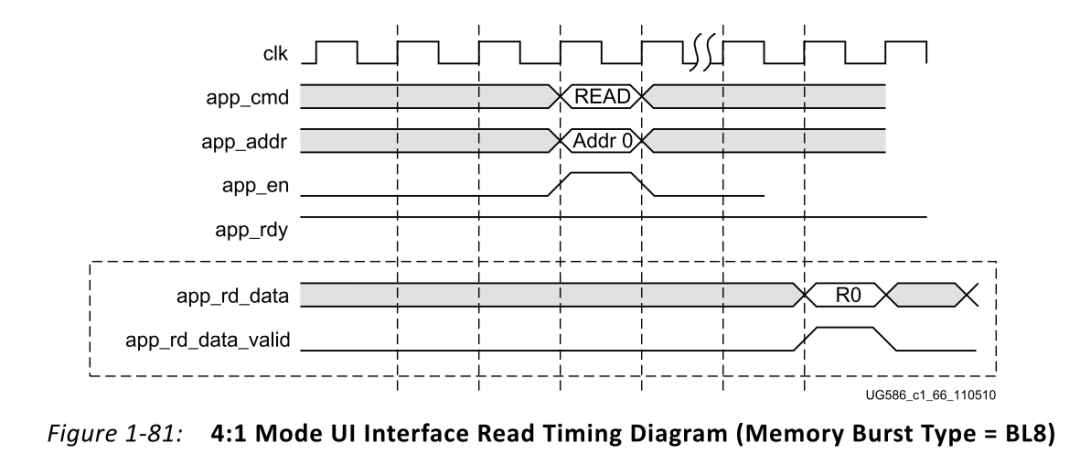
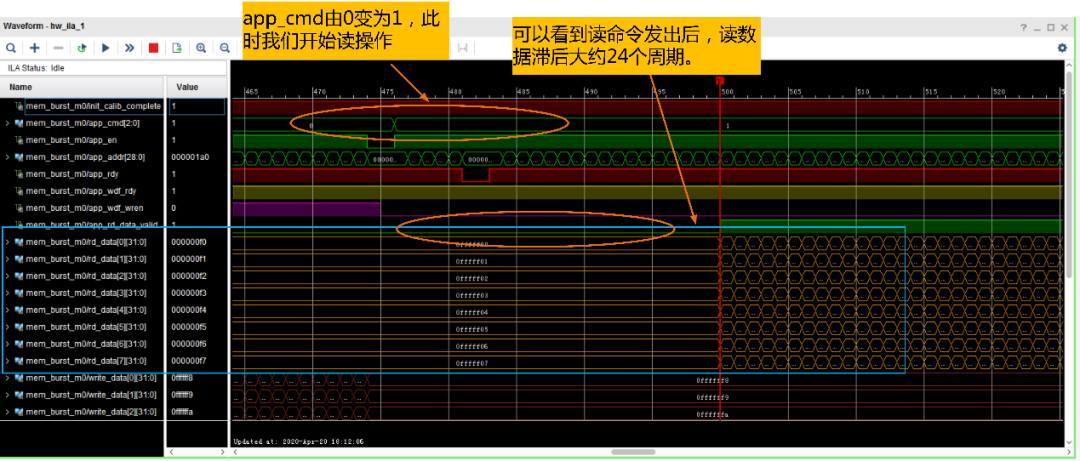
如下图所示为读操作的具体时序,同样的先进行写命令操作,时序同写命令操作一样。写命令完成后的若干个周期,app_rd_data、app_rd_data_valid以及app_rd_data_end出现。当app_rd_data_valid为高时,用户取数即可。
另外在读写操作时,我们必须记住非常重要的一点:我们写入了多少个写数据,就必须发出相同数量的写命令,对读操作也是一样。
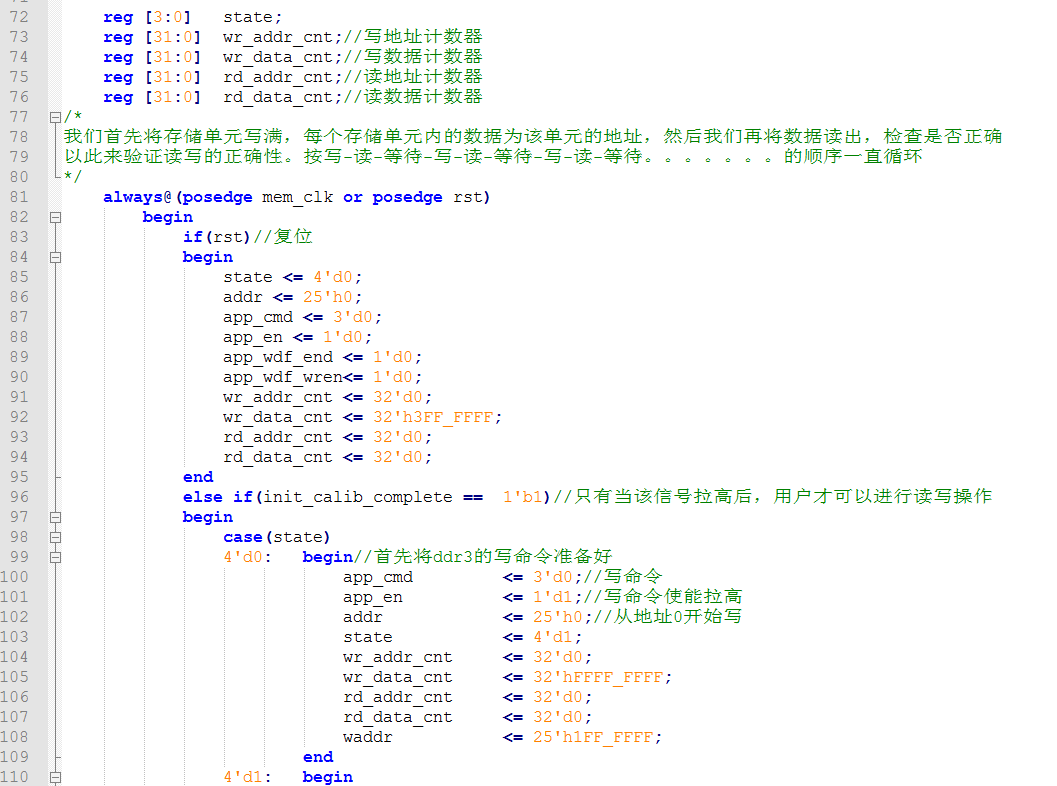
26.接下里具体分析读写代码:



27.接下来我们实际测试一下上述代码的功能是否正常,首先是从地址0开始写入:
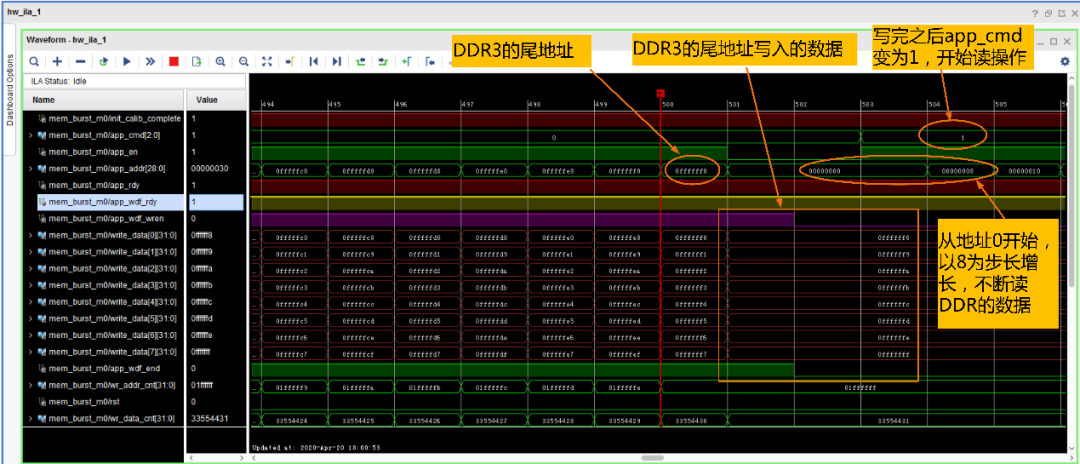
然后我们再看写入的尾地址(即29’h0FFF_FFF8~29’h0FFF_FFFF)数据,写完之后就开始了读操作:
接下来我们看看读出来的数据:
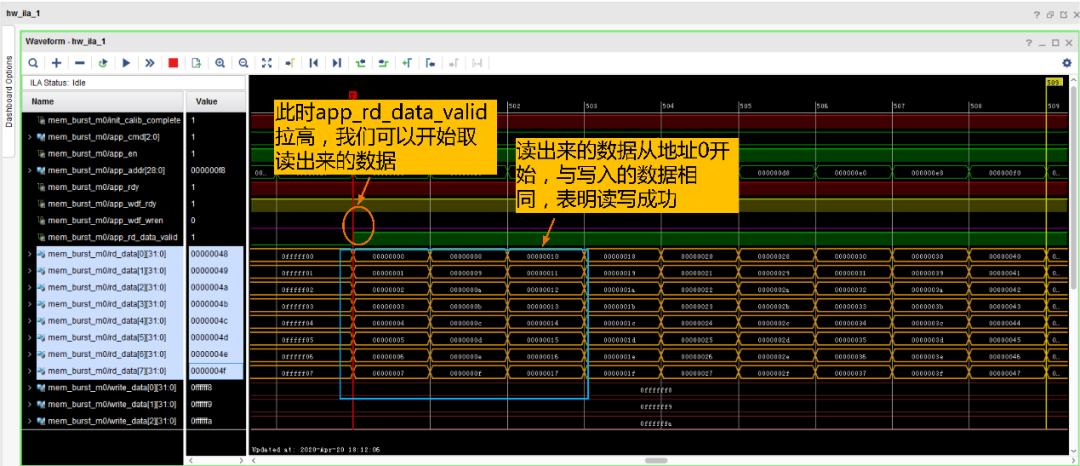
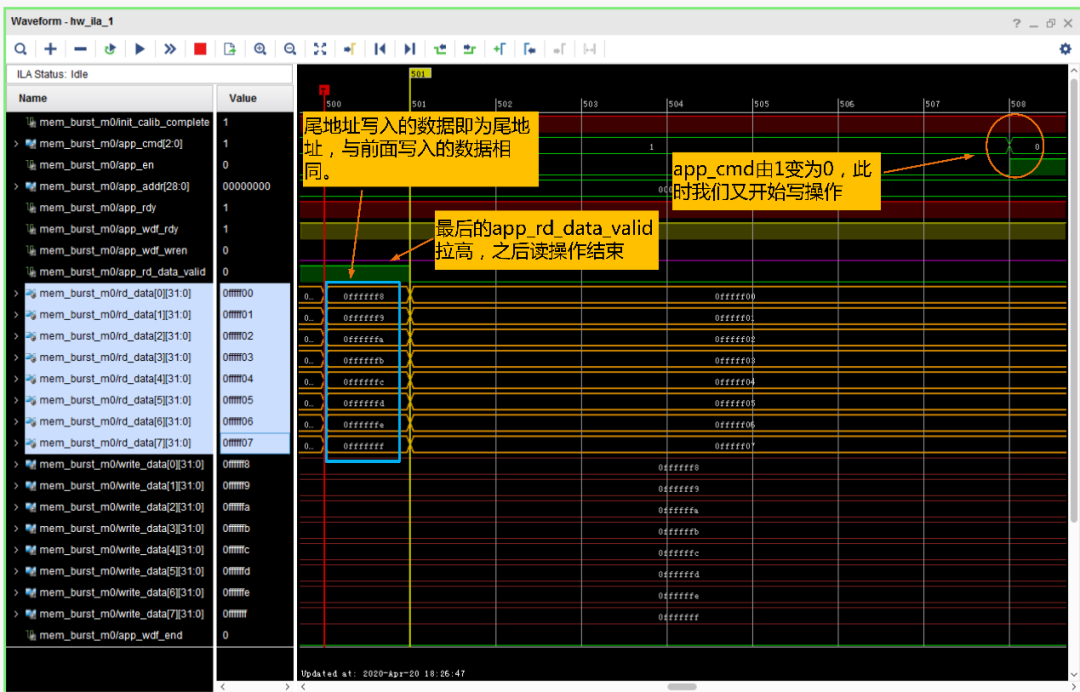
自此,说明DDR3读写都ok了,在应用到相应的项目时只需要在DDR3模块外部添加自定义的读写FIFO就可以了。
参考内容:
1,DDR3布局布线规则与实例,https://wenku.baidu.com/view/045ade1b590216fc700abb68a98271fe910eafac.html
2,DDR布线规则与过程,https://wenku.baidu.com/view/6661c8eea21614791611285e.html?sxts=1587461512922
3,DDR3布线那些事儿,https://www.cnblogs.com/tureno/articles/7856858.html
4,DDR3基本概念6 -Write leveling(写入均衡),https://blog.csdn.net/tbzj_2000/article/details/88304245
5,LPDDR4的训练(training)和校准(calibration)--Write Leveling(写入均衡),https://blog.csdn.net/wonder_coole/article/details/102788136?depth_1-utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromBaidu-4&utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromBaidu-4
6,【接口时序】8、DDR3驱动原理与FPGA实现(一、DDR的基本原理),https://www.cnblogs.com/liujinggang/p/9782796.html
7,DDR3基本知识,https://www.cnblogs.com/liujinggang/p/9782796.html
8,DDR3布局注意事项,https://blog.csdn.net/hanxuexiaoma/article/details/78977726