我们已经知道,监督学习主要就是分类和回归两种方法。本文以支持向量机(support vector machine,SVM)来说明,如何采取机器学习中回归方法来预测股票价格。这在传统量化中是根本不可能实现的,在机器学习领域却能达到50%以上的胜率。
1、支持向量机
支持向量机
支持向量机是一种监督学习算法,可用于分类和回归问题,如支持分类的 SVC和支持回归的SVR。这是20世纪90年代被开发出来的,直到现在,都是高性能算法的首选,在机器学习领域有极为广泛的应用。
核心思想
算法的核心思想是寻找最能将特征分离到不同域的超平面。它的理论根据就是,任何一个P维物体(空间)都可以被一个P-1 维的超平面分成两部分,就像我们可以用刀(二维平面)将西瓜(三维物体)分成两半。
术语概念
直接看图吧,我们要图中将红蓝点分开,应该怎么办吧呢。
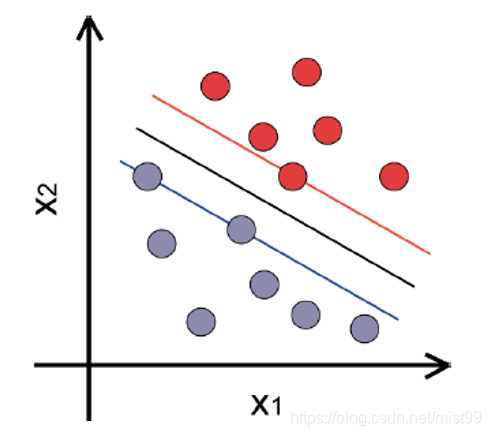
决策边界
如图所示,红点和蓝点分别代表两类样本,二维空间中的超平面就是图中的黑色直线。如果一条直线可以让两类样本中的点到这条直线的最短距离取最大值,一般认为这条直线就是最稳定的分界线,在机器学习中我们称之为“决策边界”;
支持向量:而决定这条直线的点往往是由少数几个支撑点决定的,这些点称为支持向量。就是如下图中红线和蓝线穿过的点。而支持向量与决策边界之间的距离就叫做边距。
sklearn中如何使用
这里我们使用的是SVR,直接从sklearn中引用SVR模块就可以了
from sklearn import svm
sk_model =svm.SVR(kernel='linear')
这里只有一个关键参数,就是核(kernel)
算法预测的原理
1)如果用机器学习的语言表述,我们根据已知的“特征”x1 和“标签”y ,通过“训练”得到一个反映两者线性关系的模型。
2)如果这种关系在未来一段时间内能够延续,那么任意给出一个股票当前时刻的特征因子x1,我们就可以“预测”该股票未来时刻的价格 ?̂ = ?0 +?1?1。
3)根据已有的特征和标签训练模型,使用新的特征进行预测,两者构成了监督学习最核心的两个环节。
2、策略描述
标的选择:沪深300指数
训练数据:2011~2016年共7年的日线数据
预测数据:基于训练出的模型,预测2017,2018,2019年每天的涨跌
数据描述:

这个日线数据有以下的字段:
【ts_code】 股票或基金的代码,上证股票SH结尾,深证股票以SZ结尾
【trade_date】 交易日期
【open】 开盘价
【high】 最高价
【low】 最低价
【close】 收盘价
【change】 涨跌幅,复权之后的真实涨跌幅,保证准确
策略实现描述
- 计算当日~前20日的滚动收盘价,作为我们这里的特征,共21个特征
- 采用SVM中的SVR线性回归模型来进行训练
- 训练好模型后就可以用来预测第二天的收盘价
- 通过将预测到的明日收盘价来和明日开盘价比较,就可以得到涨跌预测
- 然后我们根据预测结果计算策略收益,用图形展示出来
3、代码实现
代码的基本实现步骤:
1.准备数据
index_data,features_train,labels_train= getStockData(“000300.SH”,20,‘20110101’,‘20161231’)
2.训练模型
sk_model = trainModel(features_train,labels_train)
3.验证测试集
index_test, features_test, labels_test = getStockData(“000300.SH”,20, ‘20170101’, ‘20171231’) predictData(sk_model,features_test,
labels_test,index_test)
下面是各个函数的具体实现:
#数据获取和处理
def getStockData(ts_code,bar_num,start_date,end_date):
#1.读取数据
index_data = pd.read_csv(ts_code+'.csv',parse_dates=['trade_date']) #parse_dates
#选取字段
index_data = index_data[['trade_date','close','open']]
#按日期排序
index_data.sort_values(by='trade_date', inplace=True)
#设置日期索引
index_data.set_index('trade_date', inplace=True)
#2.特征处理
#这里以当日收盘价和之前n天的收盘价作为特征
for i in range(1,bar_num+1):
index_data['close_'+str(i)] = index_data['close'].shift(i)
#去掉前面的空值
index_data = index_data[bar_num:]
#3.按日期截取
index_data = index_data[(index_data.index>pd.to_datetime(start_date))&(index_data.index<pd.to_datetime(end_date))]
#特征数据
features_data = index_data[[x for x in index_data.columns if 'close' in x]]
#标签数据
# 回归问题的标签就是预测的股价,所以下一天的收盘价就是前一天的标签;
labels_data = index_data['close'].shift(-1)
# 进行训练的数据里不能有nan值,因为这一个值对整体影响可以忽略,可以删除也可以填充,这里采用的填充
labels_data.fillna(method='ffill', inplace=True)
return index_data,features_data,labels_data
模型训练
def trainModel(features_train,label_train):
#选择模型
sk_model =svm.SVR(kernel='linear')
#训练模型(执行大概需要几分钟时间)
print("开始训练=========>")
sk_model.fit(features_train,label_train)
print("<========= 训练结束")
return sk_model
预测价格和计算收益
def predictData(sk_model,features_data,labels_data,base_data):
#准备用列表方式构造新dataframe
date_line = list(labels_data.index.strftime("%Y-%m-%d")) # 日期序列 将timestamp转换成string
next_close = list(labels_data) #明日的收盘价
current_close = list(features_data['close']) #取今日的收盘价
next_open = list(base_data['open'].shift(-1)) #取明天的开盘价
#预测价格
predict = sk_model.predict(features_data)
#训练结果评分
# score = sk_model.score(predict, labels_data)
# print('预测得分:%.4f'%score)
# 预测的明日收盘价,转换成list
predict = list(predict)
#构造新的dataframe
index_data = pd.DataFrame({'date': date_line, 'next_close': next_close,'next_predict':predict,'close':current_close,'next_open':next_open})
print(index_data.head())
print(index_data.columns)
#计算持仓
index_data['position'] = np.where(index_data['next_predict']>index_data['next_open']*(1+0.002),1,0) #这里设置2/1000的滑点
#模型收益计算和可视化
index_data['PL'] = np.where(index_data['position']==1,(index_data['next_close']-index_data['next_open'])/index_data['next_open'],0)
print(index_data.head())
index_data['strategy'] = (index_data['PL'].shift(1) + 1).cumprod()
index_data['baseline'] = (index_data['next_close'].pct_change() + 1).cumprod()
index_data.dropna(inplace=True)
print(index_data.head())
# 绘制图形
plt.plot(index_data['strategy'])
plt.plot(index_data['baseline'])
plt.legend(loc='best')
# plt.savefig('1.jpg')
plt.show()
4、策略效果
我们用的2011~2016年数据训练好的模型进行预测,下面看先一下对各个时期的预测结果。
1)对训练数据(2011~2016年)的测试
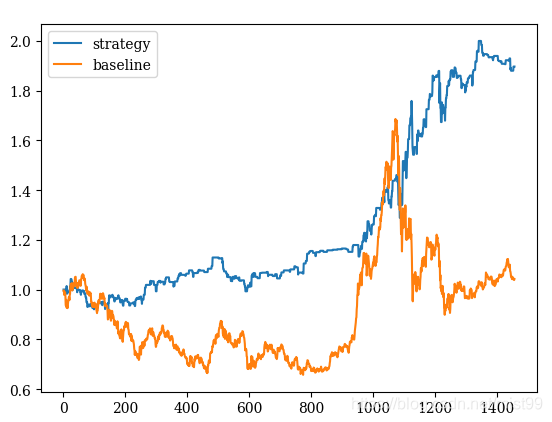
说明:这结果好到爆有没有,当然,这是训练数据,再好都没有意义的
2)对2017年数据测试
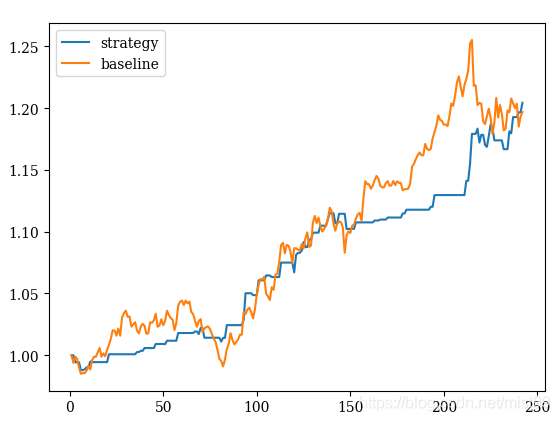
说明:这个效果也很不错,虽然收益率跟直接持有差不多,但是够平滑
3)对2018年数据测试
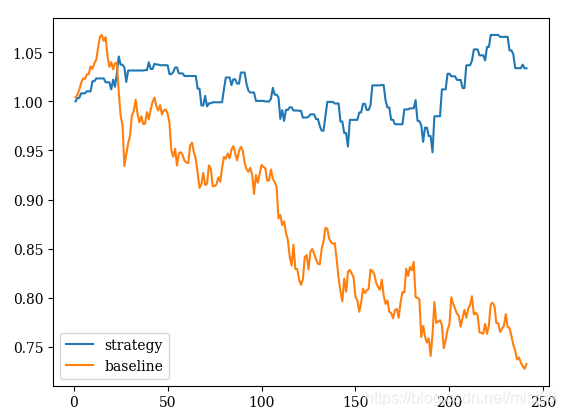
说明:这个效果就很明显了,在大盘大幅下跌的情况下保持了正收益。
5、总结
总的来看,这个策略效果还是不错的,但是要注意,只是这样的策略是完全无法用于实战的,本文只是展示了程序实现的逻辑和流程。
1)一方面,完全没有考虑交易费用、滑点等损耗。
2)另一方面,单纯用价格预测价格,特征太单一了,可靠性不高。
扩展练习:
- 选取长度的特征或不同的特征组合
- 不用线性核,采用多项式核或高斯核
- 不用支持向量回归,改用其他的回归算法