原文链接:
http://xueshu.baidu.com/s?wd=paperuri:(ba0044ede74ce3a08eb2f83cc970284b)&filter=sc_long_sign&sc_ks_para=q%3DCluster+Canonical+Correlation+Analysis&tn=SE_baiduxueshu_c1gjeupa&ie=utf-8&sc_us=15456908664490711842
一、引出问题
CCA是一个常见的处理脑电信号(SSVEP、P300等)的算法,但是CCA算法要求处理的信号必须是配对的,当每个类别有一些数据点有两种不同的方式进行配对时,CCA就无法直接应用。在这篇文章中,对该算法做了拓展和改进,包括Kernel canonical correlation analysis(KCCA)、Mean Canonical Correlation Analysis(Mean-CCA)、Cluster Canonical Correlation Analysis(Cluster-CCA)和Cluster Kernel Canonical Correlation Analysis(cluster-KCCA)
下图表示了各种获取集合之间相关子空间的方法,其中‘△’和‘〇’分别代表每个集合中的两个聚类。
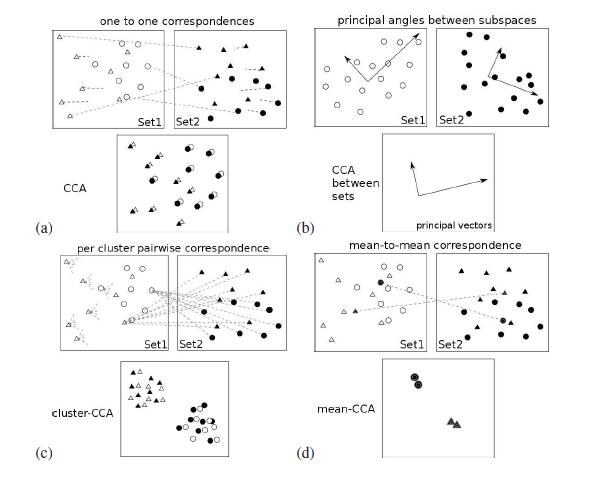
(a)CCA:使用集合之间的成对对应关系,不能分离两个集群,(b)CCA for sets:计算两个子空间之间的主角,不能处理多个集群,(c)cluster-CCA:使用集群内的所有成对对应 (d)Mean-CCA:计算平均聚类向量之间的CCA。
二、研究方法
2.1 CCA
首先,先了解一下CCA,两个零均值的多元随机变量\[X\epsilon R^{D_{x}}\]和\[Y\epsilon R^{D_{y}}\],设集合Sx={X1,......,Xn}和Sy={y1,......,yn},CCA的目标是通过选择一个的方向\[w\epsilon R^{D_{x}}\]找到一个新的坐标x,同样通过选择一个方向 \[v\epsilon R^{D_{y}}\],使得在w和v上Sx和Sy的投影之间的相关性最大,
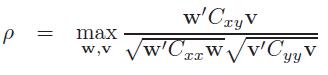
其中,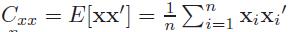
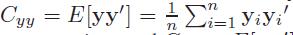
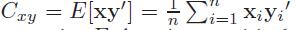
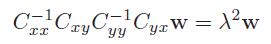
2.2 KCCA
Kernel canonical correlation analysis通过使用“核技巧”,重新定义CCA来提取非线性关系。
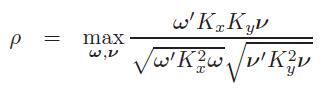
其中,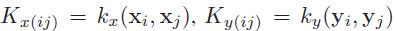 是n*n的核矩阵,kx()和ky()是核函数
是n*n的核矩阵,kx()和ky()是核函数
 是投影系数 。
是投影系数 。
注意:CCA和KCCA 都要求数据是成对对应的!
考虑一下,如果有两组数据,每组数据分为C个不同但相互对应的类,令Tx={X1,......,Xn}和Ty={y1,......,yn},其中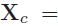
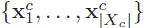 和
和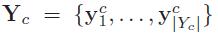 分别为集合中第C类的数据点。通过选择方向w和v找到X和y的新坐标,使得Tx和Ty在w和v上的投影有最大的相关性,同时,类之间可以很好地分离。但是无法直接计算这些投影之间的相关性,因为他们在w和v上的投影没有任何直接的对应关系。因此提出了Mean-CCA与Cluster-CCA。
分别为集合中第C类的数据点。通过选择方向w和v找到X和y的新坐标,使得Tx和Ty在w和v上的投影有最大的相关性,同时,类之间可以很好地分离。但是无法直接计算这些投影之间的相关性,因为他们在w和v上的投影没有任何直接的对应关系。因此提出了Mean-CCA与Cluster-CCA。
2.3 Mean-CCA
Mean-CCA是通过建立两个集合的平均聚类向量之间的对应关系来使之产生一对一的对应关系,令聚类均值
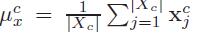 和
和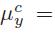
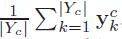
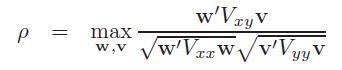
其中,
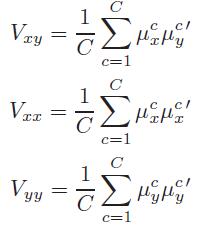
2.4 Cluster-CCA
Cluster-CCA不是建立类均值之间的对应关系,而是建立两个集合中给定类中所有数据点之间的一一对应关系。
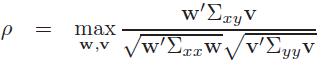
其中,
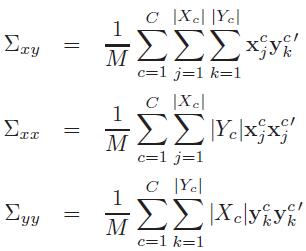
其中, ,是成对对应的总数。
,是成对对应的总数。
注意:Mean-CCA与Cluster-CCA,都假定协方差矩阵是针对零均值随机变量计算的!
Cluster-CCA不适用于大型数据集,因为M随着每个集合的数据数量成二次增长(例如,当|Xc|=|Yc|=L时,M=C(L*L)),其实,协方差矩阵可以定义为:
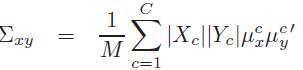
其实,Mean-CCA与Cluster-CCA相比较来说,忽略了数据本身的一些信息,Cluster-CCA是对数据中的所有点进行估计,因此,Cluster-CCA相对于Mean-CCA来说,性能好很多。
2.5 cluster-KCCA
类似于KCCA,Cluster-CCA也可以扩展到高维空间的非线性投影来观察两个集合间的关系:
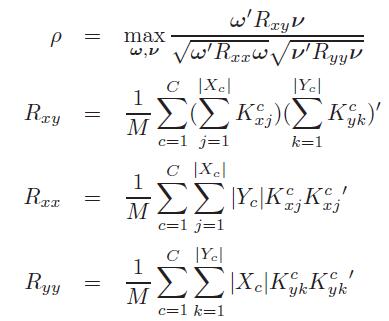
其中,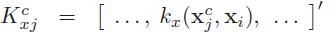
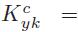
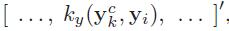
三、实验
3.1 实验设计
下面是对通过实验对Cluster-KCCA性能的评估,在所有实验中使用的都是KCCA的正则化版本,通过交叉验证获得正则化常数,文本和图像的核化方法都采用径向X^2(卡方)核,归一化参数被设置为训练集中X^2(卡方)距离的平均值。最后,利用归一化相关得分计算低维投影向量之间的相似性,所有的实验都用随机试验分组重复了十次。
评估是在五个公开的数据集上进行的,分别是Pascal VOC 2007 、TVGraz 、 WikiText-Image Dataset 、Heterogeneous Face Biometrics(HFB) 和Materials Dataset 。
Pascal VOC 2007:包含5011/4952(训练/测试)个图像及其注释,分为20个类别。图像由Pascal挑战提供,图像注释用作文本模式,并且定义在804个关键词的词汇表上。我们将实验限制在属于单个类别的图像和注释中,从而将数据降至2954/3192。其中,一些注释是空的,即不包含关键字,因此形成了两个不同的数据集,即VOC和VOCfull。在VOC 中,删除了所有带有空注释的图像,以保持图像和文本之间的平衡,共得到1905/2032(训练/测试)个数据。在VOCfull中,保留了无注释的图像。VOC和VOCfull的测试集是相同的。
TVGraz:由Khan等人编辑,包含了检索了Caltech-256数据集的10个类的网页,由于版权问题,TVGraz数据集存储为URL列表,并且必须由每个新用户重新编译,我们从网页(2592个网址)中收集了2058个图像和文字,并随机分为1588/500(训练/测试)。
WikiText-Image Dataset:由Rasiwasia等编译。使用维基百科网站上的精选文章。它由2173/693(训练/测试)个图像和10个来自不同类别的文本文章组成。
Heterogeneous Face Biometrics(HFB):包括四个近红外(NIR)图像和四个视觉(VIS)图像,他们各自没有任何自然配对,其中,这两种模式都是图像,但是来自不同的感觉。我们遵循协议,70名受试者的图像用来训练,其余30名作为测试集。
Materials Dataset :由图像以及来自17中不同材料的音频组成,我们与已发表的分类任务和跨模式检索任务的结果进行了比较。
3.2 实验结果
3.2.1 cluster-(K)CCA
使用Pascal数据集的‘bus’、‘car’和‘motorbike’的类构建玩具数据集,下图为Pascal VOC数据集的图像和文本的低维映射和类别区分。
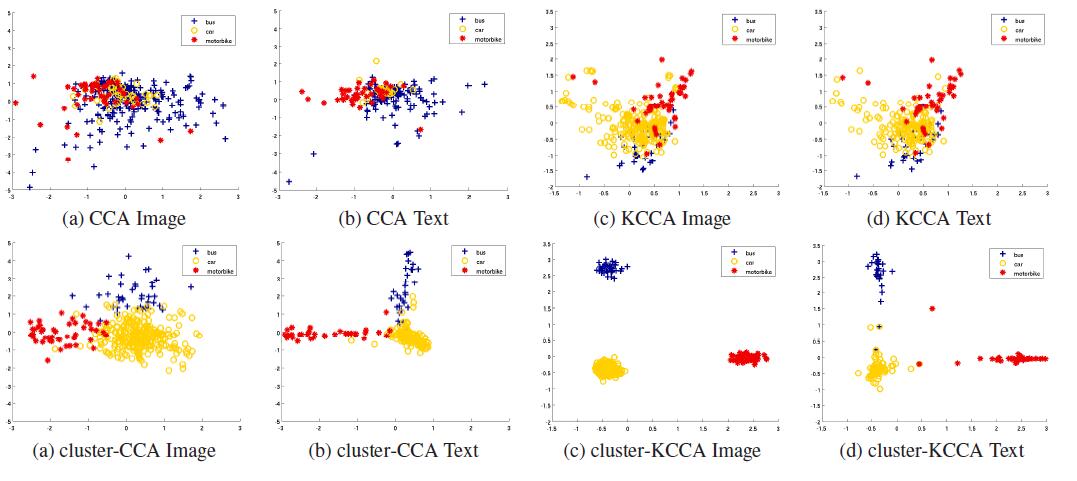
从图中可以清楚地看到,CCA虽然产生了文本与图像之间高度相关的映射,但无法实现类别的区分。而Cluster-KCCA可以实现类别的区分。
3.2.2 跨模态检索
下表为各方法分别在各数据集上的性能
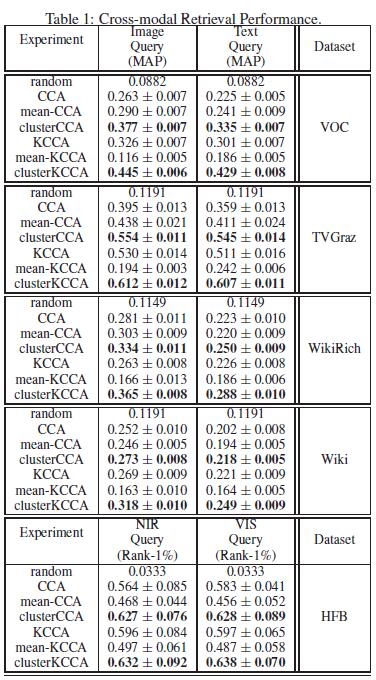
从表中,我们可以看到,mean-CCA的性能高于CCA,KCCA的性能也不是太好,而cluster-CCA和cluster-KCCA的性能明显优于其他算法。
下图为在TVGraz数据集上,各个算法的PR曲线

下图展示了使用cluster-KCCA检索的一些例子,前三行为图像检索到文本的示例,后三个为文本检索到图像的示例



3.2.3 cluster-(K)CCA在VOC(full)上的性能比较
我们在上面已经提到,VOCfull是没有删除无注释图像的数据集,CCA无法应用于这个数据集,因为有一些图像相对应的文本不存在,而cluster-KCCA不需要成对的对应关系,下表列出了cluster-CCA与cluster-KCCA在同样数据集上的检索结果,他们的测试集都是相同的,所以不会因为数据集的差异对结果造成的影响。
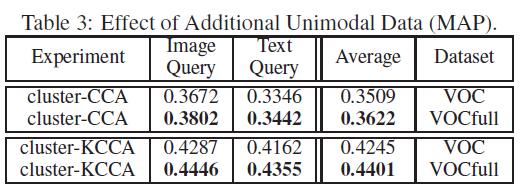
从表中可以看出,当有额外的图像(无额外文本)的时候,cluster-(K)CCA算法的性能高于数据完全对应(无任何额外的图像和文本)的数据集,即:额外的图像或者文本有助于提高该算法的性能。
四、结论
将CCA和cluster-CCA核化后,可以将其应用范围扩展至非线性,将CCA改进至cluster- CCA后,可以改进CCA只能应用于所有数据必须成对对应的数据集的性能,即:拓宽了应用范围。当然,也是有一定弊端的,就是在大型数据集上使用时,计算量很大,因为它在计算协方差的时候对数据的数量呈平方的关系增长。
各数据集参考文献:
Pascal VOC 2007 :M. Everingham, L. Van Gool, C. K. I. Williams, J. Winn,
and A. Zisserman. The PASCAL Visual Object Classes
Challenge 2007 (VOC2007) Results. http://www.pascalnetwork.
org/challenges/VOC/voc2007/workshop/index.html.
链接:http://host.robots.ox.ac.uk/pascal/VOC/voc2007/htmldoc/voc.html
TVGraz :I. Khan, A. Saffari, and H. Bischof. Tvgraz: Multi-modal
learning of object categories by combining textualand visual
features. In Proceedings 33rd Workshop of the Austrian Association
for PatternRecognition, 2009
链接:
http://xueshu.baidu.com/s?wd=paperuri:(8f22858b81aabbd7707db189279d9a4f)&filter=sc_long_sign&sc_ks_para=q%3DTVGraz%3A+Multi-Modal+Learning+of+Object+Categories+by+Combining+Textual+and+Visual+Features&tn=SE_baiduxueshu_c1gjeupa&ie=utf-8&sc_us=9275424831294604053
WikiText-Image Dataset :N. Rasiwasia, J. Costa Pereira, E. Coviello, G. Doyle,
G.and Lanckriet, R. Levy, and N. Vasconcelos. A new approach
to cross-modal multimedia retrieval. In Proceedings
18th ACM International Conference on Multimedia, 2010
链接:http://xueshu.baidu.com/s?wd=paperuri:(341c8e50c52e1b9a84297fd786343ff9)&filter=sc_long_sign&sc_ks_para=q%3DA+new+approach+to+cross-modal+multimedia+retrieval&tn=SE_baiduxueshu_c1gjeupa&ie=utf-8&sc_us=14965492576112519918
Heterogeneous Face Biometrics(HFB):S. Z. Li, Z. Lei, and M. Ao. The HFB face database for
heterogeneous face biometrics research. In IEEE Conf. on
Computer Vision and Pattern Recognition Workshops, 2009,
pages 1–8.
链接:
http://xueshu.baidu.com/s?wd=paperuri:(dae80635d08b082f8cf0db8404b7b14a)&filter=sc_long_sign&sc_ks_para=q%3DThe+HFB+Face+Database+for+Heterogeneous+Face+Biometrics+research&tn=SE_baiduxueshu_c1gjeupa&ie=utf-8&sc_us=2875153112935655430
Materials Dataset:C. H. Lampert and O. Krmer. Weakly-paired maximum covariance
analysis for multimodal dimensionality reduction
and transfer learning. In Proceedings of the 11th European
conference on Computer vision, pages 566–579, 2010.
链接:
http://xueshu.baidu.com/s?wd=paperuri:(ff0a8601c17f027b59c7393281fccce7)&filter=sc_long_sign&sc_ks_para=q%3DWeakly-Paired+Maximum+Covariance+Analysis+for+Multimodal+Dimensionality+Reduction+and+Transfer+Learning&tn=SE_baiduxueshu_c1gjeupa&ie=utf-8&sc_us=7723943620216524500