论文地址:https://arxiv.org/abs/2101.11986
代码:https://github.com/yitu-opensource/T2T-ViT
发表于:ICCV 2021(Arxiv 2021.01)
Abstract
Transformer在语言建模中很受欢迎,最近也被探索用于解决视觉任务,例如,用于图像分类的Vision Transformer(ViT)。ViT模型将每个图像分割成具有固定长度的token序列,然后应用多个Transformer层来模拟它们的全局关系以进行分类。然而,当在ImageNet这样的中型数据集上从头开始训练时,ViT取得的性能不如CNN。我们发现这是因为:
- 对输入图像的简单地转换为token并不能对重要的局部结构(如相邻像素之间的边缘和线条)进行建模,导致训练效率低下
- 在计算预算和训练样本有限的情况下,ViT的冗余注意力backbone设计使得学到的特征丰富度有限
为了克服这些局限,我们提出了一个新的Token-To-Token Vision Transformer(T2T-ViT),它包括:
- 一个分层的Token-to-Token(T2T)变换,通过递归地将相邻的Token融合成一个Token(Token-to-Token),逐步将图像结构化为Token,这样,由周围Token表示的局部结构可以被建模,使得Token长度可以被减少
- 经过实证研究,在CNN架构设计的启发下,为Vision Transformer提供了一个具有"deep-narrow"结构的高效backbone
值得注意的是,T2T-ViT将vanilla ViT的参数量与MAC(Multi-Adds)减少了一半,而在ImageNet上从头开始训练时取得了超过3.0%的提升。通过直接在ImageNet上训练,它的性能也超过了ResNet,并达到了与MobileNet相当的性能。例如,规模与ResNet50相当的T2T-ViT(21.5M参数)在图像分辨率为384×384的ImageNet上可以达到83.3%的top1精度。
I. Motivation
ViT是最早开始用纯transformer做图像分类任务的,其基本上完全照搬了原始transformer结构而没有引入其他改进。但其实单纯只从结果上看,ViT在同中等规模训练集的情况下也是干不过ResNet的,只有在大规模训练数据的情况下才有优势,那么在这种情况下其实就限制了ViT的应用场景(甚至ViT用的JFT-300M数据集本身就不是开源的)。
从理论上分析的话,造成这种现象的原因是,NLP任务本身更加看重长距离依赖(全局信息)的提取,transformer也是基于这一目标设计的,其局部信息获取能力较弱。因此,像ViT这样直接将图像硬划分(hard split)为一个个token的话,会使得模型仍然难以学习图像的局部结构信息,这一结构上的弱点使得性能提升依赖冗余的训练数据。此外,对于CV任务而言,transformer中attention的设计有一定程度的冗余,造成了训练上的困难,不适合直接进行照搬。
本文做了个特征可视化实验,如下:

可以发现,像ResNet这样的传统CNN的话,浅层块能很好地提取纹理之类的局部信息(图中绿色的框),而深层块提取的是全局信息。但是对于ViT而言,局部信息的提取能力弱了很多,并且在深层块中学到了完全无效的信息(图中红色的框)。
为此本文着力于对transformer结构进行改进,提升其局部信息学习能力。
II. Network Architecture
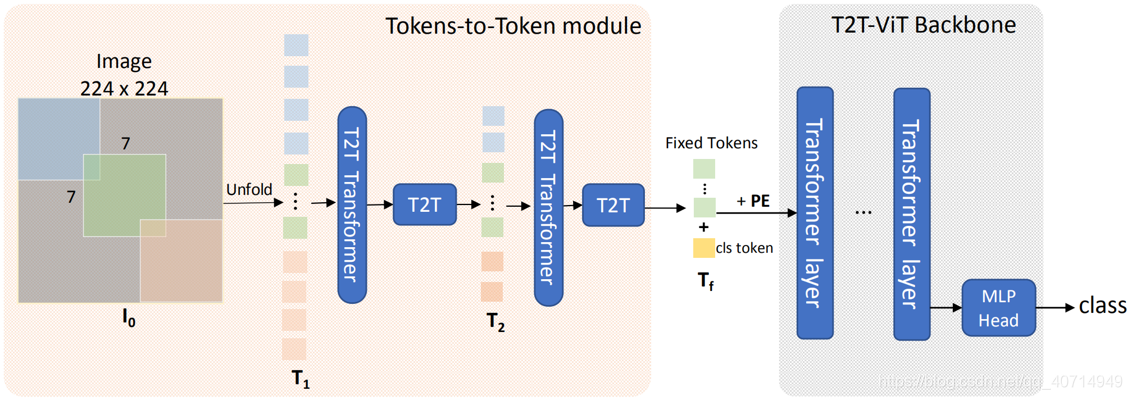
本文网络结构上的改进主要在于一个T2T模块与一个按deep narrow思路设计的transformer backbone。其实从图中T2T模块中的unfold也可以看到,T2T也是受卷积操作中"卷"的这一部分启发而来的,整个网络的核心思想就在于引入CNN中一些优秀的设计理念进入transformer。
III. Token-to-Token Module
为了把输入图像变为token,ViT采用的是简单的硬分割方式,如下:

而T2T模块从图像的拆分入手,提升token包含局部信息的能力。T2T的结构如下所示:
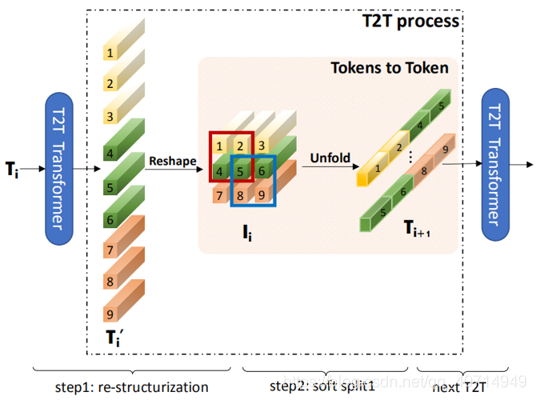
可以发现T2T分为两个阶段,Re-structurization与Soft split,接下来我们将对这两个阶段分别进行介绍。
Re-structurization
记从上一个transformer层输出的token串为
T
T
T,将其送入一个selft attention块(即T2T transformer,不过个人感觉这里称为T2T transformer layer更为严谨),有:
T
′
=
M
L
P
(
MSA
(
T
)
)
T^{\prime}=\mathrm{MLP}(\operatorname{MSA}(T))
T′=MLP(MSA(T)) 其中MSA表示多头注意力Multi-Head Attention,MLP表示由全连接层与Layer Normalization构成的多层感知机,这一部分遵循了标准transformer的设计。然后,将
T
′
T^{\prime}
T′ reshape至图片的维度 ,有:
I
=
Reshape
(
T
′
)
I=\operatorname{Reshape}\left(T^{\prime}\right)
I=Reshape(T′) 这里Reshape的意思是,将
T
′
∈
R
l
×
c
T^{\prime} \in \mathbb{R}^{l \times c}
T′∈Rl×c 调整至
I
∈
R
h
×
w
×
c
I \in \mathbb{R}^{h \times w \times c}
I∈Rh×w×c,其中
l
l
l表示token串
T
′
T^{\prime}
T′的长度,
h
,
w
,
c
h,w,c
h,w,c表示高、宽、通道数,这里显然有
l
=
h
×
w
l=h \times w
l=h×w。这里将token串重建为图像的目的是方便后序进行"卷积操作"(不过实际上只有卷而没有积,做的是滑动窗口)。
Soft Split
软分割的目的是对局部的结构信息进行建模,并且还能在一定程度上缩短token串的长度。从实现的角度来讲,软分割可以看做是一种带overlapping的硬分割。形式化地,记每个patch的大小为
k
×
k
k \times k
k×k,overlapping为
s
s
s,padding为
p
p
p。从卷积的角度来看,这里的
k
−
s
k-s
k−s就相当于卷积操作中的stride。此时,对于输入的重建(reconstructed)图像
I
∈
R
h
×
w
×
c
I \in \mathbb{R}^{h \times w \times c}
I∈Rh×w×c,其经软分割处理输出的token串
T
0
T_{0}
T0长度为:
l
o
=
⌊
h
+
2
p
−
k
k
−
s
+
1
⌋
×
⌊
w
+
2
p
−
k
k
−
s
+
1
]
l_{o}=\left\lfloor\frac{h+2 p-k}{k-s}+1\right\rfloor \times\left\lfloor\frac{w+2 p-k}{k-s}+1\right]
lo=⌊k−sh+2p−k+1⌋×⌊k−sw+2p−k+1] 注意这里其实会带来因为一个问题,由于分割的时候带了重叠,因此相当于最后分割得到的单个token长度相比不重叠的情况下要更长(因为是多个token合起来的),直接带来大量的计算开销,对此本文的做法是将T2T层的通道数砍到32或64来减少计算开销。当然,文章也指出可以直接将Transformer换成更加轻量级的版本比如Performer。
总的来看,T2T模块的思想在于,本来上一个transformer层输出的token串会直接输入到下一个transformer层,那么这里就把这个token串给重新组装成图像(特征图),然后用了个滑动窗口(相当于卷积操作中的"卷"操作)做所谓的软分割,相当于在transformer中引入了一定的卷积学习局部特征的能力。
IV. T2T-ViT Backbone
上节讲的Token-to-Token Module做的相当于是对输入图像的一个预处理操作,但也正如之前提到的,NLP中的原始transformer在直接用于视觉任务会带来大量的冗余特征与无效特征,因此接下来还需要对transformer的内部结构进行一定的改进。这里一个有意思的点是,本文就直接明说了,尝试将CNN中的一些经典结构设计方案引入到transformer中,并且真的一个个就这么去试了。提到的方案有以下这么几种:
- DenseNet中的dense connection
- Wide-ResNet中的deep-narrow结构与shallow-wide架构
- SENet中的channel attention
- ResNeXt中的split head
- GhostNet中的ghost operation
最后实验结果是,deep-narrow和channel attention都能有效地减少通道维度,提升网络深度和特征丰富度,只不过前者相对而言还更加好使,因此本文最终使用的是deep-narrow结构。具体来讲,deep narrow的设计思想就是在每一层使用更小的通道数,并增加层数,此外相应的hidden dimension也会降低。
V. Summary
本文作为对ViT的改进,核心思想在于将CNN中的一些设计理念引入transformer。提出了Token to Token的方法,在图像转token的这一过程中引入了更多的局部信息,从而改善了transformer全局信息提取能力强而局部信息提取能力弱的问题。此外,在transformer的结构设计层面,引入了CNN中deep narrow的思想,使用更少的通道数、更多的层数来提升transformer的性能。最终的结果是T2T-ViT在同训练集近似参数量的情况下已经能超越CNN模型,使得transformer在视觉任务中从"能用"便为了“可用”,现在陆续也出现了一些以T2T-ViT为backbone的工作。