1、代码模板
ggplot(data = <DATA>)+
<GEOM_FUNCTION>(
mapping = aes(<MAPPINGS>),
stat = <STAT>,
position = <POSITION>
)+
<COORDINATE_FUNCTION> +
<FACET_FUNCTION>
2.为了说明图形语法的工作方式,从头开始构建一个基本图形
a.首先需要有一个数据集,然后(通过统计变换)将其转换为想要显示的信息。
- 从diamonds数据集开始
- 使用stat_count()函数为每个切割值计数
b.选择一个几何对象来表示转换后的数据中的每个观测值,然后选择几何对象的图形属性来表示数据中的变量,这会将每个变量的值映射为图形属性的水平。
- 使用条形表示每个观测值
- 将每个条形的fill属性映射为…count…变量
c.选择放置几何对象的坐标系。还可以进一步调整几何对象在坐标系中的位置(位置调整),或者将图划分为多个子图(分面)。还可以通过添加一个或多个附加图层对图进行扩展,其中每个附加图层都是用一个数据集、一个几何对象、一个映射集合、一个统计变换和一个位置调整。
- 在笛卡尔直角坐标系中放置几何对象
- 映射y值到…count…,x值到cut
使用这种方法能够构建成千上万种独特的图形。
练习题
1.2.4
(1)运行ggplot(data=mpg),你会看到什么?

(2)数据集mpg中有多少行?多少列?
有4种方法可以知道:


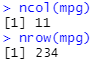
(3)变量drv的意义是什么?


(4)使用hwy和cyl绘制一张散点图。
ggplot(data = mpg)+
geom_point(mapping = aes(x = hwy, y = cyl))

(5)如果使用class和drv绘制散点图,会发生什么情况?为什么这张图没什么用处?
ggplot(data = mpg)+
geom_point(mapping = aes(x = class, y = drv))

因为class和drv都是车的类型,用这两个参数作图并不能获得什么有用的信息。
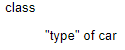

1.3
(1)以下这段代码有什么错误?为什么点不是蓝色的?
ggplot(data = mpg) +
geom_point(
mapping = aes(x = displ, y = hwy, color = "blue")
)

改一下color = "blue"的位置,就可以得到蓝色的散点图了:
ggplot(data = mpg) +
geom_point(mapping = aes(x = displ, y = hwy), color = "blue")

(2)mpg中的哪些变量是分类变量?哪些变量是连续变量?当调用mpg时,如何才能看到这些信息?

显示为chr的是分类变量,为int的是连续变量。
(3)将一个连续变量映射为color、size和shape。对分类变量和连续变量来说,这些图形属性的表现有什么不同?
color:连续变量使用的是同一种颜色,从浅到深
ggplot(data = mpg) +
geom_point(mapping = aes(x = displ, y = hwy, color = cyl))

size:一个区间的size对应不同的变量
ggplot(data = mpg) +
geom_point(mapping = aes(x = displ, y = hwy, size = cyl))

shape:连续变量映射到shape中会报错
ggplot(data = mpg) +
geom_point(mapping = aes(x = displ, y = hwy, shape = cyl))

(4)如果将同一个变量映射为多个图形属性,会发生什么情况?
将同一个变量(cyl)映射为2个图形属性(color,size):
ggplot(data = mpg) +
geom_point(mapping = aes(x = displ, y = hwy, color = cyl,size = cyl))

将同一个变量(cyl)映射为3个图形属性(color、size、alpha):
ggplot(data = mpg) +
geom_point(mapping = aes(x = displ, y = hwy, color = cyl, size = cyl,alpha = cyl))

(5)stroke这个图形属性的作用是什么?它适用于哪些形状?
边框。适用于21~24的图形样式,因为有边框和填充。
(6)如果将图形属性映射为非变量名对象,比如aes(color = displ < 5),会发生什么情况?
ggplot(data = mpg) +
geom_point(mapping = aes(x = displ, y = hwy, color = displ < 5))

1.5
(1)如果使用连续变量进行分面,会发生什么情况?
ggplot(data = mpg) +
geom_point(mapping = aes(x = displ, y = hwy)) +
facet_grid(drv ~ cyl)

(2)在使用facet_grid(drv ~ cyl)生成的图中,空白单元的意义是什么?它们和以下代码生成的图有什么关系?
ggplot(data = mpg) +
geom_point(mapping = aes(x = drv, y = cyl))

空白单元代表没有drv值和cyl值对应的组合。
(3)以下代码会绘制出什么图?“.”的作用是什么?
“.”的作用表示不在行或列的维度分面。“.”在前表示不按行分面,在后表示不按列分面。
ggplot(data = mpg) +
geom_point(mapping = aes(x = displ, y = hwy)) +
facet_grid(drv ~ .)

ggplot(data = mpg) +
geom_point(mapping = aes(x = displ, y = hwy)) +
facet_grid(. ~ cyl)

(4)查看本节的另一个分面图:
ggplot(data = mpg) +
geom_point(mapping = aes(x = displ, y = hwy)) +
facet_wrap(~ class, nrow = 2)

与使用图形属性相比,使用分面的优势和劣势分别是什么?如果有一个更大的数据集,你将如何权衡这两种方法的优劣?
-
优势:根据想要观测的变量将数据分为每一分面,显示出每一分面中的趋势及不同分面之间的差别
-
劣势:由于数据被分割为一个个的分面,数据整体的趋势就看不出来了。
-
如果有一个更大的数据集,就需要根据目标判断,如果看整体趋势的话就不用分面,如果看单个变量的变化趋势就可以使用分面。
(5)阅读?facet_wrap的帮助页面。nrow和ncol的功能分别是什么?还有哪些选项可以控制分面的布局?为什么函数facet_grid()没有变量nrow和ncol?
facet_wrap()控制分面的布局的选项:

 facet_grid()控制分面的布局的选项:
facet_grid()控制分面的布局的选项:

 因为facet_grid()只会是单列或者单行,不需要nrow和ncol这两个参数。
因为facet_grid()只会是单列或者单行,不需要nrow和ncol这两个参数。
(6)在使用函数facet_grid()时,一般应该将具有更多唯一值的变量放在列上。为什么这么做呢?
1.6
(1)在绘制折线图、箱线图、直方图和分区图时,应该分别使用哪种几何对象?
geom_line、geom_boxplot、geom_histogram、facet_grid
(2)在脑海中运行以下代码,并预测会有何种输出。接着在R中运行代码,并检查你的预测是否正确。
ggplot(
data = mpg,
mapping = aes(x = displ, y = hwy, color = drv)
) +
geom_point() +
geom_smooth(se = FALSE)

(3)show.legend = FALSE的作用是什么?删除它会发生什么情况?为什么要在本章前面的示例中使用这句代码?
ggplot(data = mpg) +
geom_smooth(
mapping = aes(x = displ, y = hwy, color = drv),
show.legend = TRUE
)

ggplot(data = mpg) +
geom_smooth(
mapping = aes(x = displ, y = hwy, color = drv),
show.legend = FALSE
)

ggplot(data = mpg) +
geom_smooth(
mapping = aes(x = displ, y = hwy, color = drv)
)

(4)geom_smooth()函数中的se参数的作用是什么?

(5) 以下代码生成的两张图有什么区别吗?为什么?
没有区别。
ggplot(data = mpg, mapping = aes(x = displ, y = hwy)) +
geom_point() +
geom_smooth()
ggplot() +
geom_point(
data = mpg,
mapping = aes(x = displ, y = hwy)
) +
geom_smooth(
data = mpg,
mapping = aes(x = displ, y = hwy)
)

(6)自己编写R代码来生成以下各图。
ggplot(data = mpg, mapping = aes(x = displ, y = hwy)) +
geom_point() +
geom_smooth(se = FALSE)

ggplot(data = mpg, mapping = aes(x = displ, y = hwy, group = drv)) +
geom_point() +
geom_smooth(se = FALSE)

ggplot(data = mpg, mapping = aes(x = displ, y = hwy, color = drv)) +
geom_point() +
geom_smooth(se = FALSE)

ggplot(data = mpg, mapping = aes(x = displ, y = hwy)) +
geom_point(mapping = aes(color = drv)) +
geom_smooth(se = FALSE)

ggplot(data = mpg, mapping = aes(x = displ, y = hwy)) +
geom_point(mapping = aes(color = drv)) +
geom_smooth(mapping = aes(linetype = drv),se = FALSE)

ggplot(data = mpg) +
geom_point(mapping = aes(x = displ, y = hwy, color = drv))

p1 <- ggplot(data = mpg, mapping = aes(displ, hwy)) +
geom_point(size = 2.5) +
geom_smooth(se = F, size = 1.5)
p2 <- ggplot(data = mpg, mapping = aes(displ, hwy)) +
geom_point(size = 2.5) +
geom_smooth(se = F, size = 1.5, mapping = aes(group = drv))
p3 <- ggplot(data = mpg, mapping = aes(displ, hwy, color = drv)) +
geom_point(size = 2.5) +
geom_smooth(se = F, size = 1.5, mapping = aes(group = drv, color = drv))
p4 <- ggplot(data = mpg, mapping = aes(displ, hwy)) +
geom_point(size = 2.5, mapping = aes(color = drv)) +
geom_smooth(se = F, size = 1.5)
p5 <- ggplot(data = mpg, mapping = aes(displ, hwy)) +
geom_point(size = 2.5, mapping = aes(color = drv)) +
geom_smooth(se = F, size = 1.5, mapping = aes(group = drv, linetype = drv))
p6 <- ggplot(data = mpg, mapping = aes(displ, hwy)) +
geom_point(size = 2.5, mapping = aes(color = drv))
# 方法一
library(gridExtra)
grid.arrange(p1, p2, p3, p4, p5, p6, nrow = 3, ncol = 2)
方法一:
 方法二:
方法二:
# 方法二
library(cowplot)
plot_grid(p1, p2, p3, p4, p5, p6, nrow = 3, ncol = 2, labels = c("A","B","C","D","E","F"))

方法三:
#方法三
library(patchwork)
p1 + p2 + p3 + p4 + p5 + p6 + plot_layout(nrow = 3) + plot_annotation(tag_levels = 'A')

1.7
(1)stat_summary()函数的默认几何对象是什么?不使用统计变换函数的话,如何使用几何对象函数重新生成下列图形?
ggplot(data = diamonds) +
stat_summary(
mapping = aes(x = cut, y = depth),
fun.min = min,
fun.max = max,
fun = median
)

stat_summary()函数的默认几何对象:pointrange
ggplot(data = diamonds) +
geom_pointrange(
mapping = aes(x = cut, y = depth),
stat = "summary",
fun.min = min,
fun.max = max,
fun = median
)
(2)geom_col()函数的功能是什么?它和geom_bar()函数有何不同?

(3)多数几何对象和统计变换都是成对出现的,总是配合使用。仔细阅读文档,列出所有成对的几何对象和统计变换。它们有什么共同之处?
(4)stat_smooth()函数会计算出什么变量?哪些参数可以控制它的行为?

(5)在比例条形图中,我们需要设定group = 1,这是为什么呢?换句话说,以下两张图会有什么问题?
group = 1表示将这些类别之和作为1,进行按比例画柱状图。
ggplot(data = diamonds) +
geom_bar(mapping = aes(x = cut, y = ..prop..))

ggplot(data = diamonds) +
geom_bar(mapping = aes(x = cut, y = ..prop.., group = 1))

ggplot(data = diamonds) +
geom_bar(mapping = aes(x = cut, y = ..prop..))
ggplot(data = diamonds) +
geom_bar(mapping = aes(x = cut, fill = color, y = ..prop..))
P1:
 P2:
P2:

1.8
(1)以下图形有什么问题?应该如何改善?
ggplot(data = mpg, mapping = aes(x = cty, y = hwy)) +
geom_point()

因为上图中hwy和cty的值都进行了舍入取整,所以这些点显示在一个网格上时,很多点彼此重叠了。通过将位置调整方式设为“抖动”,可以避免这种网格化排列。有以下两种方法:
#方法一
ggplot(data = mpg, mapping = aes(x = cty, y = hwy)) +
geom_point(position = "jitter")

#方法二
ggplot(data = mpg, mapping = aes(x = cty, y = hwy)) +
geom_jitter()

(2)geom_jitter()使用哪些参数来控制抖动的程度?

(3)对比geom_jitter()与geom_count()


(4)geom_boxplot()函数的默认位置调整方式是什么?创建mpg数据集的可视化表示来演示一下。

ggplot(data = mpg, mapping = aes(x = drv, y = hwy)) +
geom_boxplot()

1.9
(1)使用coord_polar()函数将堆叠式条形图转换为饼图。
ggplot(data = diamonds, mapping = aes(x = cut, fill = color)) +
geom_bar()

ggplot(data = diamonds, mapping = aes(x = cut, fill = color)) +
geom_bar() +
coord_polar()

(2)labs()函数的功能是什么?

(3)coord_quickmap()函数和coord_map()函数的区别是什么?

(4)下图表明城市和公路燃油效率之间有什么关系?为什么coord_fixed()函数很重要?geom_abline()函数的作用是什么?
ggplot(data = mpg, mapping = aes(x = cty, y = hwy)) +
geom_point() +
geom_abline() +
coord_fixed()

图中表明城市和公路燃油效率之间线性相关。
coord_fixed()函数:

geom_abline()函数:
