上一篇文章:【Yarn】Yarn Service端如何处理客户端提交的任务 在上一篇文章中,我们知道服务器接收到客户端提交的任务之后,会启动多个状态机进行联合操作,最终来解决任务提交之后的全流程。多个状态机合作完成任务。
然后我们看了 【yarn】yarn Container 状态机正常执行流程
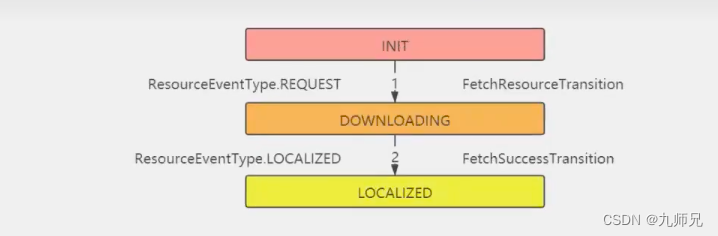
现在我们要看Application状态机的执行流程,但是状态机执行流程复杂,这里我们只看正常执行流程。
可以看到正常执行会有7个状态机的转换。