Visual Attention Network
[Submitted on 20 Feb 2022 (v1), last revised 11 Jul 2022 (this version, v5)]
Computer Vision and Pattern Recognition
https://github.com/Visual-Attention-Network
关键词:Attention, Vision Backbone, Deep Learning, ConvNets
0摘要:
虽然最初是为自然语言处理任务而设计的,但自注意机制最近已经席卷了各种计算机视觉领域。然而,图像的2D特性给在计算机视觉中应用自注意机制带来了三个挑战。
(1) 将图像处理为1D序列忽略了它们的2D结构。
(2) 二次复杂度对于高分辨率图像来说太昂贵了。
(3) 它只捕捉空间适应性,而忽略了通道适应性。
【视觉的注意力可以被分为四个类别: 通道注意力、空间注意力、时间注意力和分支注意力。】
在本文中,提出了一种新的线性注意力,称为大核注意力(LKA)模块,以在自注意力中实现自适应和长程相关性(long-range correlations,所以长程依赖可以理解为:当你想使用语言模型,并有效利用较早时间步的信息,最终产生预测的时候,那么你就要和较长路程前的信息建立一种依赖关系,这就是长程依赖。),同时避免其缺点。此外,还提出了一种基于LKA的神经网络,即视觉注意网络(VAN)。尽管极为简单,但VAN在各种任务(包括图像分类、对象检测、语义分割、全景分割、姿态估计等)中都超过了类似尺寸的视觉transformer(ViT)和卷积神经网络(CNN)。
1简介
本文的贡献总结如下:
2相关工作
2.1CNN
2.2Visual Attention Methods
2.3Vision MLPs
3方法
3.1 LKA
注意机制可以看作是一种自适应选择过程,它可以根据输入特征选择有区别的特征并自动忽略噪声响应。注意机制的关键步骤是生成注意图(attention map),它指示不同部分的重要性。为此,我们应该学习不同特征之间的关系。
在不同部分之间建立关系有两种众所周知的方法。
【作者的工作与MobileNet有相似之处,MobileNet将标准卷积解耦为两部分,即深度卷积和逐点卷积】
为了克服上面列出的缺点,并利用自注意和大核卷积的优点,本文建议分解大核卷积操作以捕获长距离关系。如图2所示,大核卷积可以分为三个部分:局部空间卷积(depthwise conv)、空间长程卷积(depthwise dilation conv)和通道卷积(1×1 conv)。
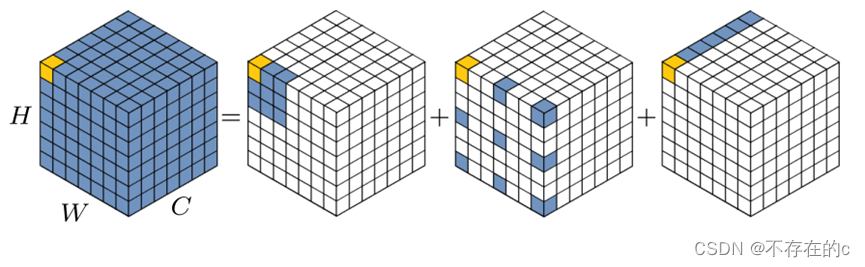
图2.大核卷积的分解图。标准卷积可以分解为三个部分:深度卷积(DW-Conv)、深度扩展卷积(DW-D-Conv)和点卷积(1×1 Conv)。彩色网格表示卷积核的位置,黄色网格表示中心点。13*13卷积分解为5*5深度卷积,5*5深度空洞卷积(膨胀速率为3),和1*1卷积;注:上图中省略了零填充。
通过上面的分解,可以用少量的计算成本和参数来捕获长程关系。在获得长程关系后,可以估计一个点的重要性并生成注意力图。如图3(a)所示,LKA模块可以写为
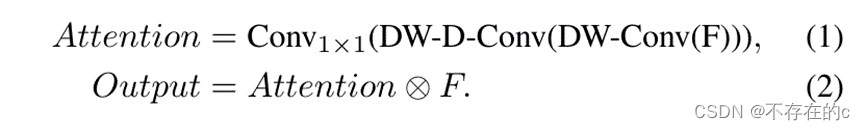
F
∈
R
C
×
H
×
W
F ∈R^{C×H×W}
F∈RC×H×W:input features;
A
t
t
e
n
t
i
o
n
∈
R
C
×
H
×
W
Attention ∈R_{C×H×W}
Attention∈RC×H×W:attention map;
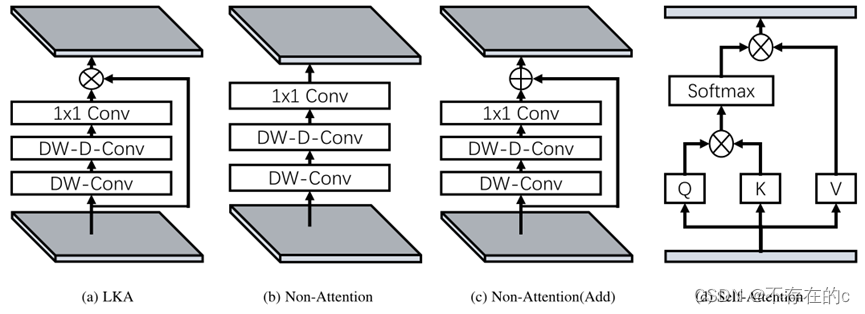
图3.不同模块的结构:(a)提出的大核注意力(LKA);(b) 非注意模块;(c) 用加法代替LKA中的乘法;(d) 自我关注。值得注意的是,(d)设计用于1D序列。
注意力图中的值表示每个特征的重要性。⊗指元素乘积。
源代码:
# LKA
class AttentionModule(nn.Module):
def __init__(self, dim):
super().__init__()
# 深度卷积
self.conv0 = nn.Conv2d(dim, dim, 5, padding=2, groups=dim)
# 深度空洞卷积
self.conv_spatial = nn.Conv2d(
dim, dim, 7, stride=1, padding=9, groups=dim, dilation=3)
# 逐点卷积
self.conv1 = nn.Conv2d(dim, dim, 1)
def forward(self, x):
u = x.clone()
attn = self.conv0(x)
attn = self.conv_spatial(attn)
attn = self.conv1(attn)
# 注意力操作
return u * attn
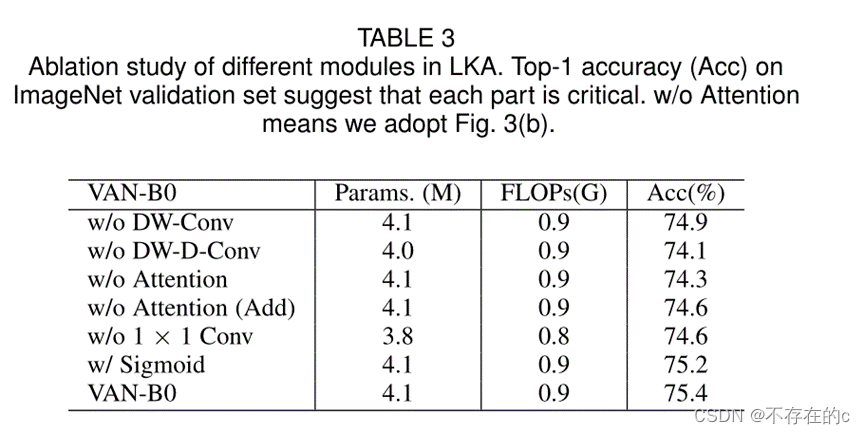
与常见的注意方法不同,LKA不需要额外的标准化函数,如sigmoid和softmax,如表3所示(VAN-B0 Acc最高)。
w/o:without
w/:with
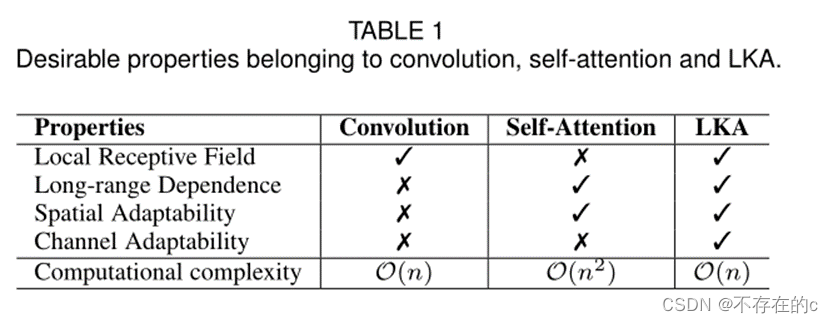
本文还认为,注意力方法的关键特征是基于输入特征自适应调整输出,而不是归一化注意力图。如表1所示,本文提出的LKA结合了卷积和自注意力机制的优点。它考虑了局部上下文信息、大的感受野、线性复杂性和动态过程。此外,LKA不仅在空间维度上实现了适应性,而且在通道维度上也实现了适应性。值得注意的是,不同的通道通常代表深度神经网络中的不同对象,通道维度的适应性对于视觉任务也很重要。
LKA的优点总结:
3.2 VAN
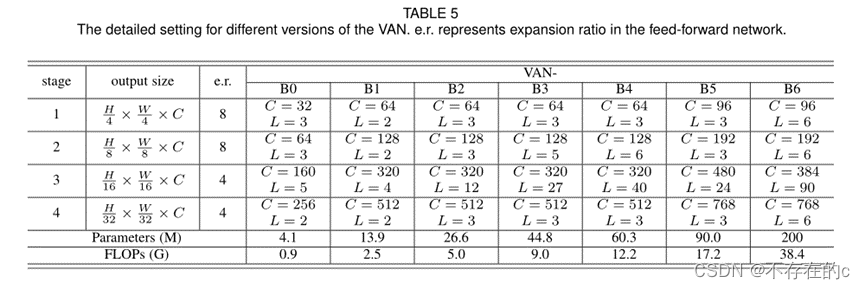
VAN具有简单的分层结构,即输出空间分辨率降低的四个阶段序列,即分别为H/4×W/4、H/8×W/8、H/16×W/16和H/32×W/32。这里,H和W表示输入图像的高度和宽度。随着分辨率的降低,输出通道的数量也在增加。输出通道Ci的变化如表5所示。
对于图4所示的每个阶段,首先对输入进行下采样,并使用步幅数来控制下采样率。在下采样之后,阶段中的所有其他层保持相同的输出大小,即空间分辨率和通道数。然后,依次堆叠L组归一化,1×1 Conv、GELU激活、大核关注和前馈网络(FFN)以提取特征。
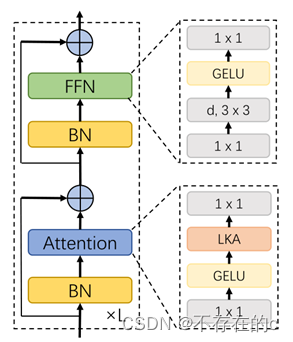
图4. VAN的一个阶段。d表示深度卷积。k×k表示k×k卷积。
根据参数和计算成本,本文设计了七种架构VAN-B0、VAN-B1、VAN-B2、VAN-B3、VAN-B4、VAN-B5、VAN-B6。整个网络的详细信息如表5所示。
源代码:
# attention
class SpatialAttention(nn.Module):
def __init__(self, d_model):
super().__init__()
# 1*1
self.proj_1 = nn.Conv2d(d_model, d_model, 1)
# 激活函数
self.activation = nn.GELU()
# LKA
self.spatial_gating_unit = AttentionModule(d_model)
# 1*1
self.proj_2 = nn.Conv2d(d_model, d_model, 1)
def forward(self, x):
# res
shorcut = x.clone()
x = self.proj_1(x)
x = self.activation(x)
x = self.spatial_gating_unit(x)
x = self.proj_2(x)
x = x + shorcut
return x
class Block(nn.Module):
def __init__(self, dim, mlp_ratio=4., drop=0., drop_path=0., act_layer=nn.GELU):
super().__init__()
# BN
self.norm1 = nn.BatchNorm2d(dim)
# attention
self.attn = SpatialAttention(dim)
# 正则化 随机删除分支
# identity模块不改变输入,直接return input
# 一种编码技巧吧,比如我们要加深网络,有些层是不改变输入数据的维度的,
# 在增减网络的过程中我们就可以用identity占个位置,这样网络整体层数永远不变
# van_small drop_path=0.1
# 结合drop_path的调用,若x为输入的张量,其通道为[B,C,H,W]
# 那么drop_path的含义为在一个Batch_size中
# 随机有drop_prob的样本,不经过主干,而直接由分支进行恒等映射。
self.drop_path = DropPath(
drop_path) if drop_path > 0. else nn.Identity()
# BN2
self.norm2 = nn.BatchNorm2d(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
# FFN
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim,
act_layer=act_layer, drop=drop)
layer_scale_init_value = 1e-2
self.layer_scale_1 = nn.Parameter(
layer_scale_init_value * torch.ones((dim)), requires_grad=True)
self.layer_scale_2 = nn.Parameter(
layer_scale_init_value * torch.ones((dim)), requires_grad=True)
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
# trunc_normal_函数:截断正太分布
# 截断分布是指,限制变量xx 取值范围(scope)的一种分布
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
# 使用val的值来填充输入的Tensor
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
elif isinstance(m, nn.Conv2d):
fan_out = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
# groups = 1 时就是标准的卷积运算
# groups = input_channels的情况是这样的
# 当输入通道数等于输出通道数时,就是深度可分离卷积的depthwise conv
# 可查看mobilenet的论文理解该卷积
fan_out //= m.groups
m.weight.data.normal_(0, math.sqrt(2.0 / fan_out))
if m.bias is not None:
# bias初始化为0
m.bias.data.zero_()
def forward(self, x):
x = x + self.drop_path(self.layer_scale_1.unsqueeze(-1).unsqueeze(-1)
* self.attn(self.norm1(x)))
x = x + \
self.drop_path(
self.layer_scale_2.unsqueeze(-1).unsqueeze(-1) * self.mlp(self.norm2(x)))
return x
复杂度分析
假设输入和输出的特征都具有相同的大小 HxWxC,则参数和FLOPs可以被写成如下
参数P和FLOPs的数量可以表示为:
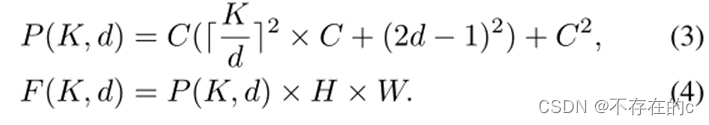
d表示膨胀率,K表示核大小。根据FLOP和参数的公式,FLOP与参数的预算节省率相同。
实现细节
默认采用K=21。对于K=21。公式(3)当d=3时取最小值,这对应于5×5深度卷积和7×7深度卷积与扩张3。
4实验
4.1图像分类
4.1.1 ImageNet-1K Experiments
设置
略
消融实验
本文进行了消融研究,以证明LKA的每个组成部分都至关重要。为了快速获得实验结果, 选择VAN-B0作为 的基线模型。表3中的实验结果表明,LKA中的所有组件对于提高性能是必不可少的。
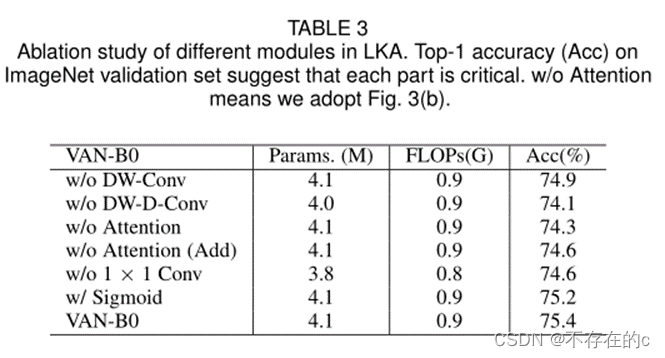
-
DW-Conv. 可以利用图像的局部上下文信息。没有它,分类性能将下降0.5%(74.9%对75.4%),这表明了局部结构信息在图像处理中的重要性。
-
DW-D-Conv. 表示深度空洞卷积,其在捕获LKA中的长程依赖性中起作用。没有它,分类性能将下降1.3%(74.1%对75.4%),这证实了本文的观点,即长程依赖对视觉任务至关重要。
-
Attention Mechanism. 注意力机制的引入可以被视为使网络具有自适应特性。受益于此,VAN-B0实现了约1.1%(74.3%对75.4%)的改进。
-
1 × 1 Conv. 这里,1×1 Conv捕获了通道维度中的关系。结合注意力机制,引入了通道维度的适应性。它带来了0.8%(74.6%对75.4%)的改善,这证明了通道维度适应性的必要性。
-
Sigmoid function. Sigmoid函数是将注意力图从0归一化为1的常用归一化函数。然而, 发现LKA模块在 的实验中没有必要。没有sigmoid的VAN-B0实现了0.2%(75.4%对75.2%)的改善和更少的计算。
此外, 还进行了消融研究,以分解表6中不同大小的卷积核。 可以发现,分解21×21卷积比分解7×7卷积效果更好,这表明大核对视觉任务至关重要。分解更大的28×28卷积, 发现与分解21×21卷积相比,增益并不明显。
因此, 默认选择分解21×21卷积。
4.1.2 Visualization
4.1.3 Pretraining on ImageNet-22K
4.2目标检测
4.3图像分割
4.4全景分割
4.5姿态评估
4.6细颗粒分类
4.7显著性检测
5讨论
最近,基于transformer的模型迅速征服了各种视觉排行榜。正如 所知,自注意力只是一种特殊的注意机制。然而,人们逐渐默认采用自注意,而忽略了潜在的关注方法。本文提出了一种新的注意力模块LKA和基于CNN的网络VAN。它超越了用于视觉任务的最先进的基于transformer的方法。希望这篇论文能促使人们重新思考自注意力是否不可替代,以及哪种注意力更适合视觉任务。
6 future work
未来,将在以下方面继续完善VAN:
-
继续改进它的结构。在本文中,只展示了一个直观的结构,还存在很多潜在的改进点,例如:应用大核、引入多尺度结构和使用多分支结构。
-
大规模的自监督学习和迁移学习。VAN 自然地结合了CNN和ViT的优点。一方面VAN利用了图像的2D结构。另一方面 VAN可以基于输入图片动态的调整输出,它很适合自监督学习和迁移学习。结合了这两点,作者认为VAN可以在这两个领域有更好的性能。
-
更多的应用场景。由于资源有限,作者只展示了它在视觉任务中的优秀性能。作者期待VAN在各个领域都展示优秀性能并变成一个通用的模型。
7 conclusion
在本文中, 提出了一种新的视觉注意LKA,它结合了卷积和自我注意的优点。基于LKA, 构建了一个 vision backbone VAN,在一些视觉任务中实现了最先进的性能,包括图像分类、对象检测、语义分割等。未来,将从第6节中提到的方向继续改进该框架。
# 四阶段模型
class VAN(nn.Module):
#
def __init__(self, img_size=224, in_chans=3, num_classes=3, embed_dims=[64, 128, 256, 512],
mlp_ratios=[4, 4, 4, 4], drop_rate=0., drop_path_rate=0., norm_layer=nn.LayerNorm,
depths=[3, 4, 6, 3], num_stages=4, flag=False, pretrained_cfg=None):
super().__init__()
if flag == False:
self.num_classes = num_classes
self.depths = depths
self.num_stages = num_stages
# 返回一个一维的tensor(张量),这个张量包含了从start到end(包括端点)的等距的steps个数据点
dpr = [x.item() for x in torch.linspace(0, drop_path_rate,
sum(depths))] # stochastic depth decay rule
cur = 0
for i in range(num_stages):
# 这里还下采样了
# 提取特征
patch_embed = OverlapPatchEmbed(img_size=img_size if i == 0 else img_size // (2 ** (i + 1)),
patch_size=7 if i == 0 else 3,
stride=4 if i == 0 else 2,
in_chans=in_chans if i == 0 else embed_dims[i - 1],
embed_dim=embed_dims[i])
block = nn.ModuleList([Block(
dim=embed_dims[i], mlp_ratio=mlp_ratios[i], drop=drop_rate, drop_path=dpr[cur + j])
for j in range(depths[i])])
# LayerNorm也是归一化的一种方法
norm = norm_layer(embed_dims[i])
cur += depths[i]
# setattr() 函数对应函数 getattr(),用于设置属性值,该属性不一定是存在的。
setattr(self, f"patch_embed{i + 1}", patch_embed)
setattr(self, f"block{i + 1}", block)
setattr(self, f"norm{i + 1}", norm)
# classification head
self.head = nn.Linear(
embed_dims[3], num_classes) if num_classes > 0 else nn.Identity()
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
elif isinstance(m, nn.Conv2d):
fan_out = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
fan_out //= m.groups
m.weight.data.normal_(0, math.sqrt(2.0 / fan_out))
if m.bias is not None:
m.bias.data.zero_()
# 冻结
def freeze_patch_emb(self):
self.patch_embed1.requires_grad = False
@torch.jit.ignore
def no_weight_decay(self):
# has pos_embed may be better
return {'pos_embed1', 'pos_embed2', 'pos_embed3', 'pos_embed4', 'cls_token'}
def get_classifier(self):
return self.head
def reset_classifier(self, num_classes, global_pool=''):
self.num_classes = num_classes
self.head = nn.Linear(
self.embed_dim, num_classes) if num_classes > 0 else nn.Identity()
def forward_features(self, x):
B = x.shape[0]
x, H, W = self.patch_embed1(x)
for blk in self.block1:
x = blk(x)
x = x.flatten(2).transpose(1, 2)
x = self.norm1(x)
x = x.reshape(B, H, W, -1).permute(0, 3, 1, 2).contiguous()
x, H, W = self.patch_embed2(x)
for blk in self.block2:
x = blk(x)
x = x.flatten(2).transpose(1, 2)
x = self.norm2(x)
x = x.reshape(B, H, W, -1).permute(0, 3, 1, 2).contiguous()
x, H, W = self.patch_embed3(x)
for blk in self.block3:
x = blk(x)
x = x.flatten(2).transpose(1, 2)
x = self.norm3(x)
x = x.reshape(B, H, W, -1).permute(0, 3, 1, 2).contiguous()
x, H, W = self.patch_embed4(x)
for blk in self.block4:
x = blk(x)
x = x.flatten(2).transpose(1, 2)
x = self.norm4(x)
return x.mean(dim=1)
def forward(self, x):
x = self.forward_features(x)
x = self.head(x)
return x
网络架构
VAN(
(patch_embed1): OverlapPatchEmbed(
(proj): Conv2d(3, 32, kernel_size=(7, 7), stride=(4, 4), padding=(3, 3))
(norm): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(block1): ModuleList(
(0): Block(
(norm1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(attn): Attention(
(proj_1): Conv2d(32, 32, kernel_size=(1, 1), stride=(1, 1))
(activation): GELU()
(spatial_gating_unit): LKA(
(conv0): Conv2d(32, 32, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2), groups=32)
(conv_spatial): Conv2d(32, 32, kernel_size=(7, 7), stride=(1, 1), padding=(9, 9), dilation=(3, 3), groups=32)
(conv1): Conv2d(32, 32, kernel_size=(1, 1), stride=(1, 1))
)
(proj_2): Conv2d(32, 32, kernel_size=(1, 1), stride=(1, 1))
)
(drop_path): Identity()
(norm2): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(mlp): Mlp(
(fc1): Conv2d(32, 256, kernel_size=(1, 1), stride=(1, 1))
(dwconv): DWConv(
(dwconv): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=256)
)
(act): GELU()
(fc2): Conv2d(256, 32, kernel_size=(1, 1), stride=(1, 1))
(drop): Dropout(p=0.0, inplace=False)
)
)
(1): Block(
(norm1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(attn): Attention(
(proj_1): Conv2d(32, 32, kernel_size=(1, 1), stride=(1, 1))
(activation): GELU()
(spatial_gating_unit): LKA(
(conv0): Conv2d(32, 32, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2), groups=32)
(conv_spatial): Conv2d(32, 32, kernel_size=(7, 7), stride=(1, 1), padding=(9, 9), dilation=(3, 3), groups=32)
(conv1): Conv2d(32, 32, kernel_size=(1, 1), stride=(1, 1))
)
(proj_2): Conv2d(32, 32, kernel_size=(1, 1), stride=(1, 1))
)
(drop_path): DropPath(drop_prob=0.008)
(norm2): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(mlp): Mlp(
(fc1): Conv2d(32, 256, kernel_size=(1, 1), stride=(1, 1))
(dwconv): DWConv(
(dwconv): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=256)
)
(act): GELU()
(fc2): Conv2d(256, 32, kernel_size=(1, 1), stride=(1, 1))
(drop): Dropout(p=0.0, inplace=False)
)
)
(2): Block(
(norm1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(attn): Attention(
(proj_1): Conv2d(32, 32, kernel_size=(1, 1), stride=(1, 1))
(activation): GELU()
(spatial_gating_unit): LKA(
(conv0): Conv2d(32, 32, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2), groups=32)
(conv_spatial): Conv2d(32, 32, kernel_size=(7, 7), stride=(1, 1), padding=(9, 9), dilation=(3, 3), groups=32)
(conv1): Conv2d(32, 32, kernel_size=(1, 1), stride=(1, 1))
)
(proj_2): Conv2d(32, 32, kernel_size=(1, 1), stride=(1, 1))
)
(drop_path): DropPath(drop_prob=0.017)
(norm2): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(mlp): Mlp(
(fc1): Conv2d(32, 256, kernel_size=(1, 1), stride=(1, 1))
(dwconv): DWConv(
(dwconv): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=256)
)
(act): GELU()
(fc2): Conv2d(256, 32, kernel_size=(1, 1), stride=(1, 1))
(drop): Dropout(p=0.0, inplace=False)
)
)
)
(norm1): LayerNorm((32,), eps=1e-06, elementwise_affine=True)
(patch_embed2): OverlapPatchEmbed(
(proj): Conv2d(32, 64, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(norm): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(block2): ModuleList(
(0): Block(
(norm1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(attn): Attention(
(proj_1): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1))
(activation): GELU()
(spatial_gating_unit): LKA(
(conv0): Conv2d(64, 64, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2), groups=64)
(conv_spatial): Conv2d(64, 64, kernel_size=(7, 7), stride=(1, 1), padding=(9, 9), dilation=(3, 3), groups=64)
(conv1): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1))
)
(proj_2): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1))
)
(drop_path): DropPath(drop_prob=0.025)
(norm2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(mlp): Mlp(
(fc1): Conv2d(64, 512, kernel_size=(1, 1), stride=(1, 1))
(dwconv): DWConv(
(dwconv): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=512)
)
(act): GELU()
(fc2): Conv2d(512, 64, kernel_size=(1, 1), stride=(1, 1))
(drop): Dropout(p=0.0, inplace=False)
)
)
(1): Block(
(norm1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(attn): Attention(
(proj_1): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1))
(activation): GELU()
(spatial_gating_unit): LKA(
(conv0): Conv2d(64, 64, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2), groups=64)
(conv_spatial): Conv2d(64, 64, kernel_size=(7, 7), stride=(1, 1), padding=(9, 9), dilation=(3, 3), groups=64)
(conv1): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1))
)
(proj_2): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1))
)
(drop_path): DropPath(drop_prob=0.033)
(norm2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(mlp): Mlp(
(fc1): Conv2d(64, 512, kernel_size=(1, 1), stride=(1, 1))
(dwconv): DWConv(
(dwconv): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=512)
)
(act): GELU()
(fc2): Conv2d(512, 64, kernel_size=(1, 1), stride=(1, 1))
(drop): Dropout(p=0.0, inplace=False)
)
)
(2): Block(
(norm1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(attn): Attention(
(proj_1): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1))
(activation): GELU()
(spatial_gating_unit): LKA(
(conv0): Conv2d(64, 64, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2), groups=64)
(conv_spatial): Conv2d(64, 64, kernel_size=(7, 7), stride=(1, 1), padding=(9, 9), dilation=(3, 3), groups=64)
(conv1): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1))
)
(proj_2): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1))
)
(drop_path): DropPath(drop_prob=0.042)
(norm2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(mlp): Mlp(
(fc1): Conv2d(64, 512, kernel_size=(1, 1), stride=(1, 1))
(dwconv): DWConv(
(dwconv): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=512)
)
(act): GELU()
(fc2): Conv2d(512, 64, kernel_size=(1, 1), stride=(1, 1))
(drop): Dropout(p=0.0, inplace=False)
)
)
)
(norm2): LayerNorm((64,), eps=1e-06, elementwise_affine=True)
(patch_embed3): OverlapPatchEmbed(
(proj): Conv2d(64, 160, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(norm): BatchNorm2d(160, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(block3): ModuleList(
(0): Block(
(norm1): BatchNorm2d(160, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(attn): Attention(
(proj_1): Conv2d(160, 160, kernel_size=(1, 1), stride=(1, 1))
(activation): GELU()
(spatial_gating_unit): LKA(
(conv0): Conv2d(160, 160, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2), groups=160)
(conv_spatial): Conv2d(160, 160, kernel_size=(7, 7), stride=(1, 1), padding=(9, 9), dilation=(3, 3), groups=160)
(conv1): Conv2d(160, 160, kernel_size=(1, 1), stride=(1, 1))
)
(proj_2): Conv2d(160, 160, kernel_size=(1, 1), stride=(1, 1))
)
(drop_path): DropPath(drop_prob=0.050)
(norm2): BatchNorm2d(160, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(mlp): Mlp(
(fc1): Conv2d(160, 640, kernel_size=(1, 1), stride=(1, 1))
(dwconv): DWConv(
(dwconv): Conv2d(640, 640, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=640)
)
(act): GELU()
(fc2): Conv2d(640, 160, kernel_size=(1, 1), stride=(1, 1))
(drop): Dropout(p=0.0, inplace=False)
)
)
(1): Block(
(norm1): BatchNorm2d(160, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(attn): Attention(
(proj_1): Conv2d(160, 160, kernel_size=(1, 1), stride=(1, 1))
(activation): GELU()
(spatial_gating_unit): LKA(
(conv0): Conv2d(160, 160, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2), groups=160)
(conv_spatial): Conv2d(160, 160, kernel_size=(7, 7), stride=(1, 1), padding=(9, 9), dilation=(3, 3), groups=160)
(conv1): Conv2d(160, 160, kernel_size=(1, 1), stride=(1, 1))
)
(proj_2): Conv2d(160, 160, kernel_size=(1, 1), stride=(1, 1))
)
(drop_path): DropPath(drop_prob=0.058)
(norm2): BatchNorm2d(160, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(mlp): Mlp(
(fc1): Conv2d(160, 640, kernel_size=(1, 1), stride=(1, 1))
(dwconv): DWConv(
(dwconv): Conv2d(640, 640, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=640)
)
(act): GELU()
(fc2): Conv2d(640, 160, kernel_size=(1, 1), stride=(1, 1))
(drop): Dropout(p=0.0, inplace=False)
)
)
(2): Block(
(norm1): BatchNorm2d(160, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(attn): Attention(
(proj_1): Conv2d(160, 160, kernel_size=(1, 1), stride=(1, 1))
(activation): GELU()
(spatial_gating_unit): LKA(
(conv0): Conv2d(160, 160, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2), groups=160)
(conv_spatial): Conv2d(160, 160, kernel_size=(7, 7), stride=(1, 1), padding=(9, 9), dilation=(3, 3), groups=160)
(conv1): Conv2d(160, 160, kernel_size=(1, 1), stride=(1, 1))
)
(proj_2): Conv2d(160, 160, kernel_size=(1, 1), stride=(1, 1))
)
(drop_path): DropPath(drop_prob=0.067)
(norm2): BatchNorm2d(160, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(mlp): Mlp(
(fc1): Conv2d(160, 640, kernel_size=(1, 1), stride=(1, 1))
(dwconv): DWConv(
(dwconv): Conv2d(640, 640, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=640)
)
(act): GELU()
(fc2): Conv2d(640, 160, kernel_size=(1, 1), stride=(1, 1))
(drop): Dropout(p=0.0, inplace=False)
)
)
(3): Block(
(norm1): BatchNorm2d(160, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(attn): Attention(
(proj_1): Conv2d(160, 160, kernel_size=(1, 1), stride=(1, 1))
(activation): GELU()
(spatial_gating_unit): LKA(
(conv0): Conv2d(160, 160, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2), groups=160)
(conv_spatial): Conv2d(160, 160, kernel_size=(7, 7), stride=(1, 1), padding=(9, 9), dilation=(3, 3), groups=160)
(conv1): Conv2d(160, 160, kernel_size=(1, 1), stride=(1, 1))
)
(proj_2): Conv2d(160, 160, kernel_size=(1, 1), stride=(1, 1))
)
(drop_path): DropPath(drop_prob=0.075)
(norm2): BatchNorm2d(160, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(mlp): Mlp(
(fc1): Conv2d(160, 640, kernel_size=(1, 1), stride=(1, 1))
(dwconv): DWConv(
(dwconv): Conv2d(640, 640, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=640)
)
(act): GELU()
(fc2): Conv2d(640, 160, kernel_size=(1, 1), stride=(1, 1))
(drop): Dropout(p=0.0, inplace=False)
)
)
(4): Block(
(norm1): BatchNorm2d(160, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(attn): Attention(
(proj_1): Conv2d(160, 160, kernel_size=(1, 1), stride=(1, 1))
(activation): GELU()
(spatial_gating_unit): LKA(
(conv0): Conv2d(160, 160, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2), groups=160)
(conv_spatial): Conv2d(160, 160, kernel_size=(7, 7), stride=(1, 1), padding=(9, 9), dilation=(3, 3), groups=160)
(conv1): Conv2d(160, 160, kernel_size=(1, 1), stride=(1, 1))
)
(proj_2): Conv2d(160, 160, kernel_size=(1, 1), stride=(1, 1))
)
(drop_path): DropPath(drop_prob=0.083)
(norm2): BatchNorm2d(160, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(mlp): Mlp(
(fc1): Conv2d(160, 640, kernel_size=(1, 1), stride=(1, 1))
(dwconv): DWConv(
(dwconv): Conv2d(640, 640, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=640)
)
(act): GELU()
(fc2): Conv2d(640, 160, kernel_size=(1, 1), stride=(1, 1))
(drop): Dropout(p=0.0, inplace=False)
)
)
)
(norm3): LayerNorm((160,), eps=1e-06, elementwise_affine=True)
(patch_embed4): OverlapPatchEmbed(
(proj): Conv2d(160, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(norm): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(block4): ModuleList(
(0): Block(
(norm1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(attn): Attention(
(proj_1): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1))
(activation): GELU()
(spatial_gating_unit): LKA(
(conv0): Conv2d(256, 256, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2), groups=256)
(conv_spatial): Conv2d(256, 256, kernel_size=(7, 7), stride=(1, 1), padding=(9, 9), dilation=(3, 3), groups=256)
(conv1): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1))
)
(proj_2): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1))
)
(drop_path): DropPath(drop_prob=0.092)
(norm2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(mlp): Mlp(
(fc1): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1))
(dwconv): DWConv(
(dwconv): Conv2d(1024, 1024, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=1024)
)
(act): GELU()
(fc2): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1))
(drop): Dropout(p=0.0, inplace=False)
)
)
(1): Block(
(norm1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(attn): Attention(
(proj_1): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1))
(activation): GELU()
(spatial_gating_unit): LKA(
(conv0): Conv2d(256, 256, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2), groups=256)
(conv_spatial): Conv2d(256, 256, kernel_size=(7, 7), stride=(1, 1), padding=(9, 9), dilation=(3, 3), groups=256)
(conv1): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1))
)
(proj_2): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1))
)
(drop_path): DropPath(drop_prob=0.100)
(norm2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(mlp): Mlp(
(fc1): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1))
(dwconv): DWConv(
(dwconv): Conv2d(1024, 1024, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=1024)
)
(act): GELU()
(fc2): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1))
(drop): Dropout(p=0.0, inplace=False)
)
)
)
(norm4): LayerNorm((256,), eps=1e-06, elementwise_affine=True)
(head): Linear(in_features=256, out_features=3, bias=True)
)