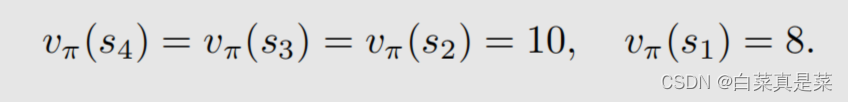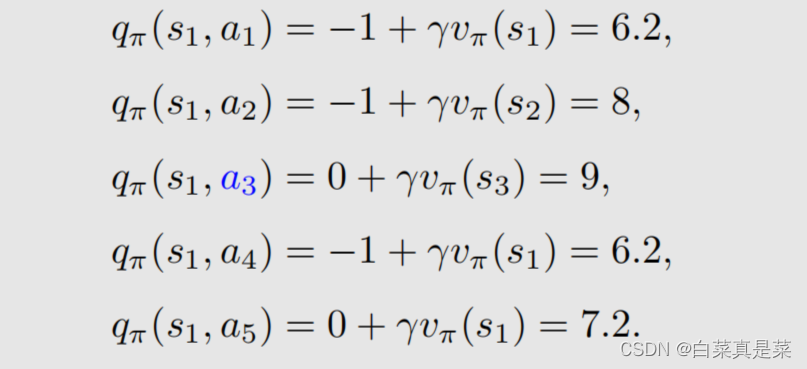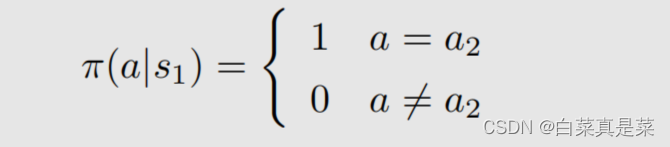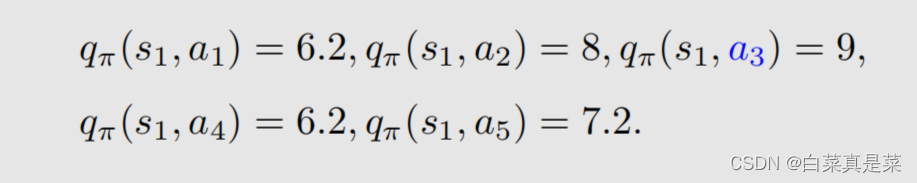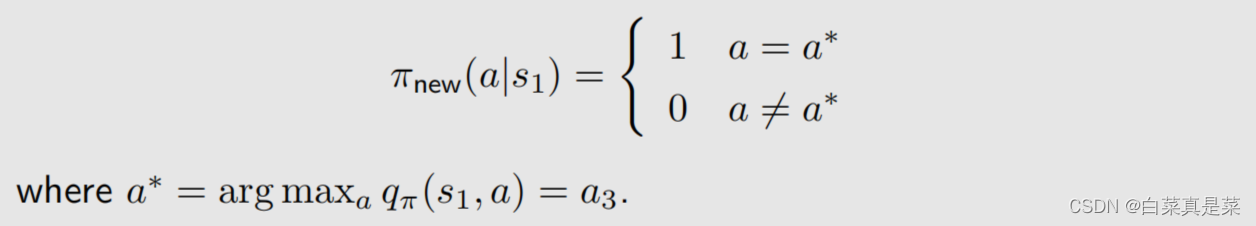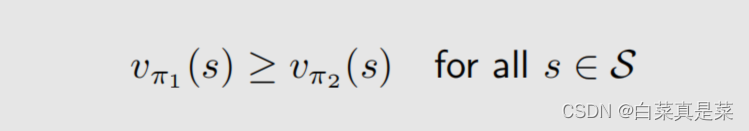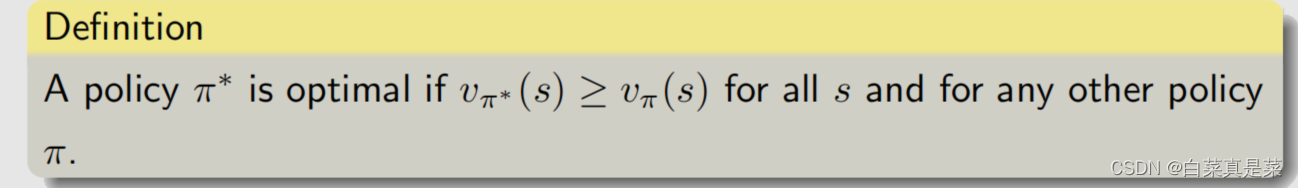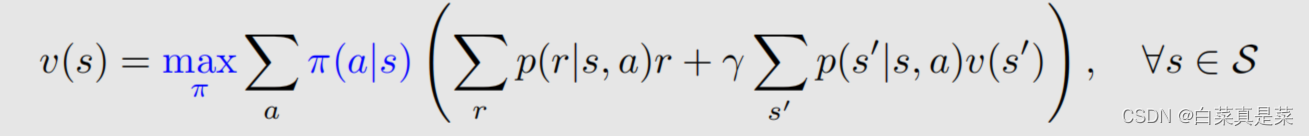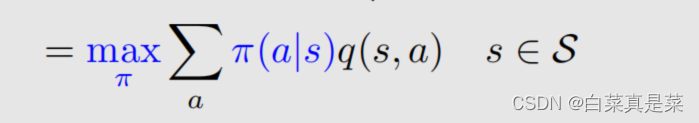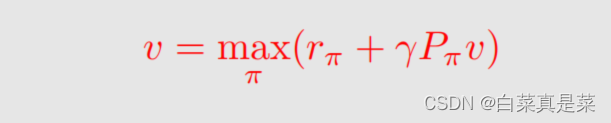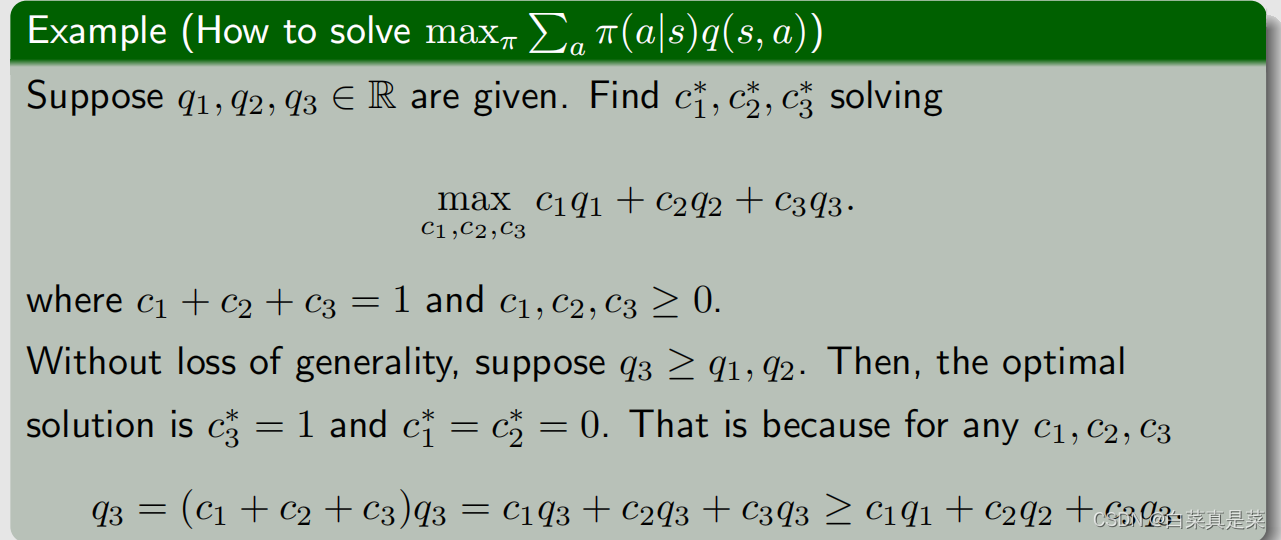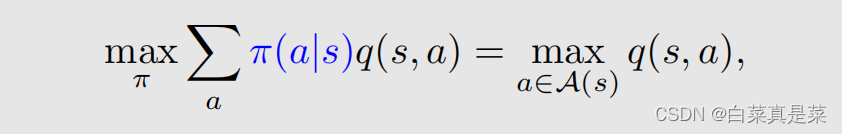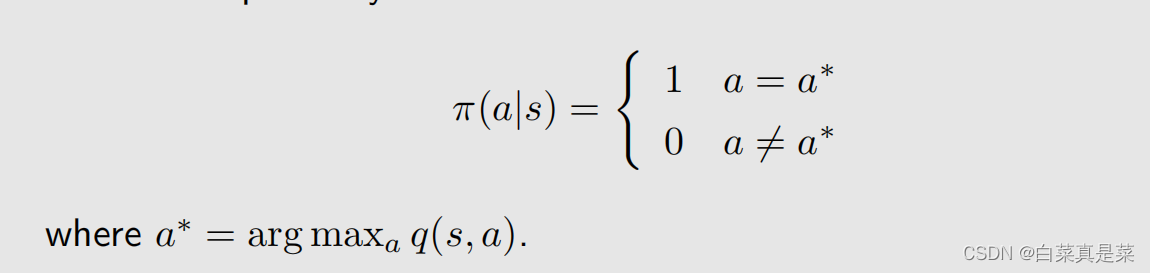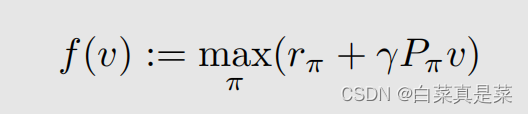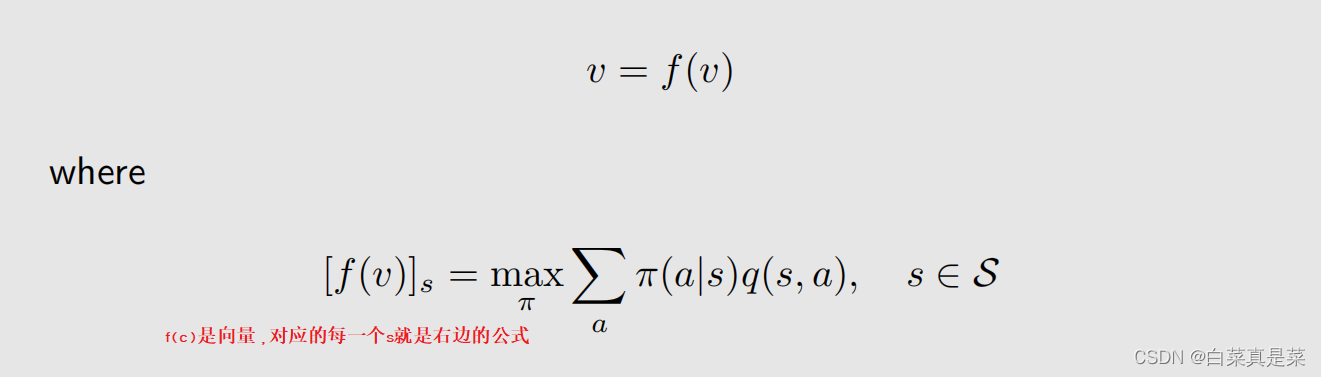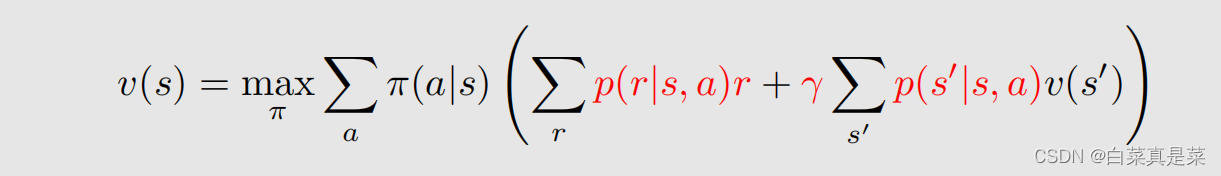只为记录学习心得 学习视频来源B站up主 西湖大学空中机器人: 链接:https://www.bilibili.com/video/BV1sd4y167NS/?spm_id_from=333.337.search-card.all.click&vd_source=ad94eb95d81e9e6b1a5d71459ef1a76d 目录 1.举例入门 2.最优策略 3.贝尔曼最优公式 4.贝尔曼最优公式详细分析 5.分析最优策略的性质
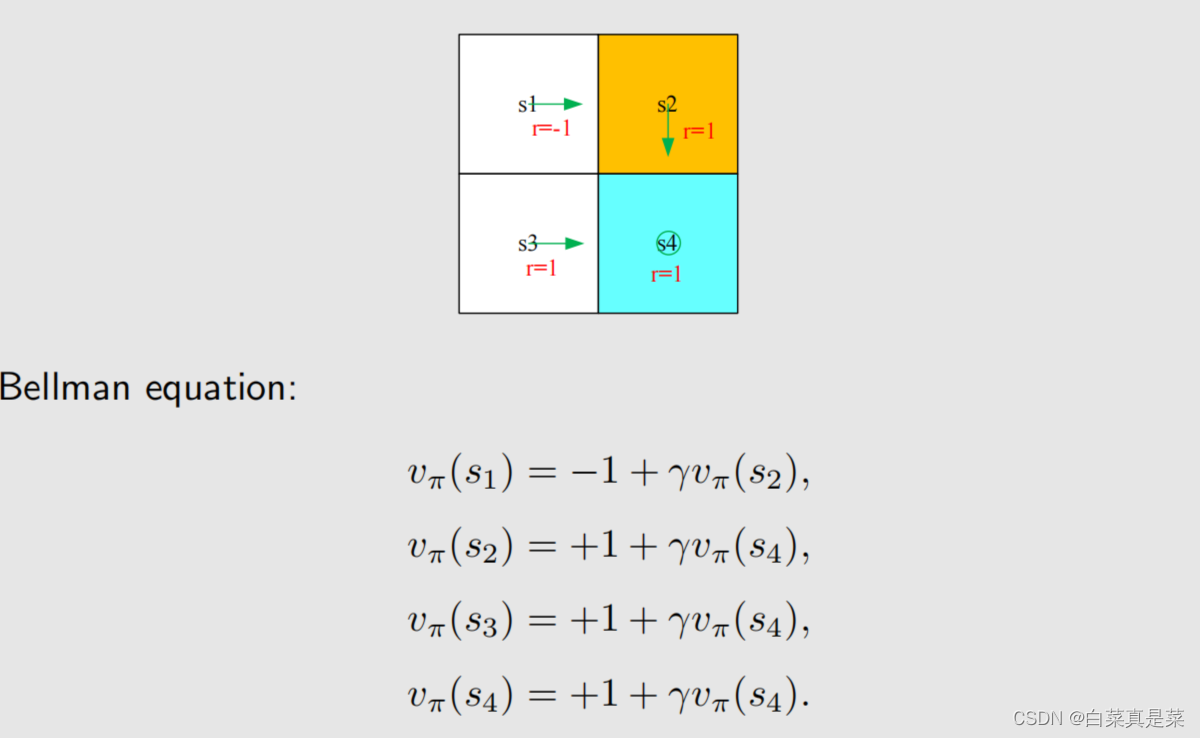
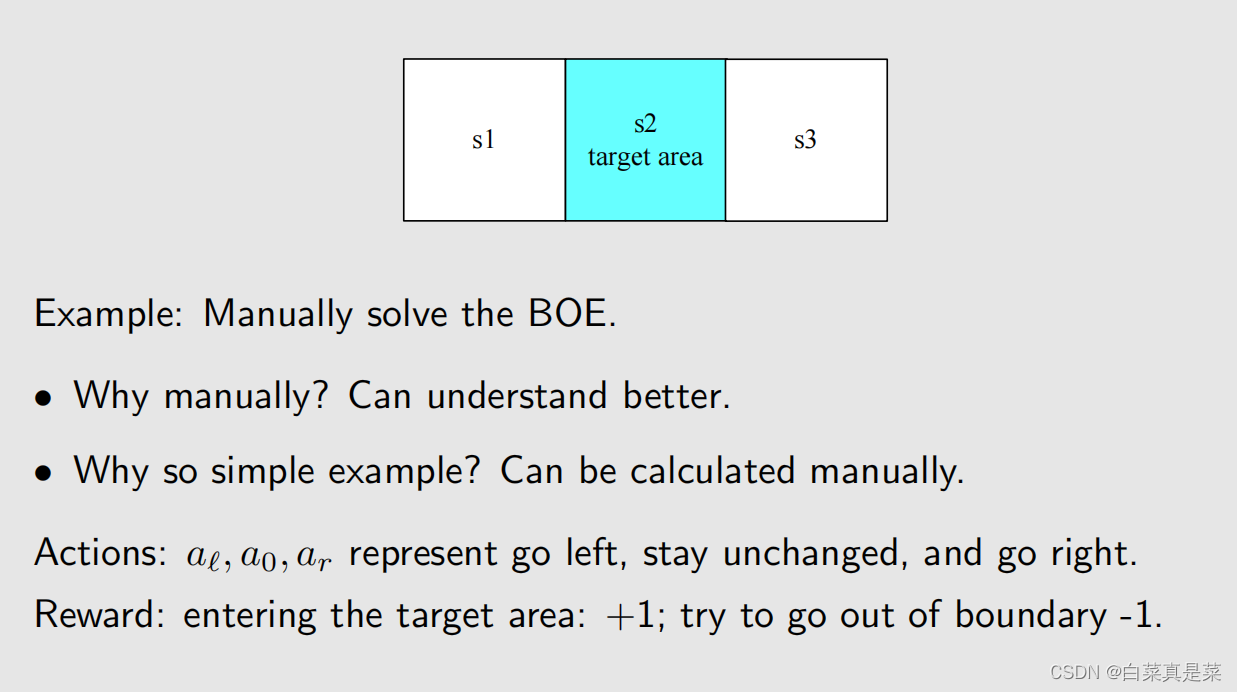
1.举例入门 贝尔曼最优公式(Bellman optimality equation,BOE)是贝尔曼公式的一种特殊情况 强化学习的目的就是为了寻找最优策略,下面先介绍最优策略的定义以及如何寻找最优策略 首先以例子入门 上面先利用贝尔曼公式求解每一个状态,取γ=0.9,得到state value的值,如下 有了state value就可以求解出action value,如下 有了这些准备后,会发现一个问题,就是例子中当前策略是往右走的,这是一个不好的策略,那么应该如何去提升?问题的答案就是利用action value进行提升 首先是现在的策略policy可以写成下面这一种形式 在这个策略下,我们已经计算出了action value,并且发现a3的action value值是最大的 那么能不能选择a3作为新的策略,具体来说就是这个新的策略会在a=a时概率为1,不等于a时概率为0,a*就是使action value最大值的那个动作,如下所示 也就是现在的策略是往右边走的(a2),但新的策略是往下走的(a3) 为什么能够选择action value最大的action能够得到一个比较好的策略? 直观上理解:因为action value本身就代表action的价值,如果选择action value很大的那个action,就意味着能够得到更多的reward 数学上理解:是否计算出当前action value最大的action,就能得到最优策略呢?例子中因为其他状态s2、s3、s4的策略已经是最优了,因此计算出s1当前action value最大的action,就能得到最优策略,如果其他状态的策略不是最优的,那还能得到最优策略吗,如当前策略是这样 这里面就会包含一些不确定性,但是,只要我们一遍一遍去做迭代,不断更新,最后一定会得到最优策略,这个理解已经超过直观理解了,因此需要依赖数学进行更严格更透彻的分析,这个数学的工具就是贝尔曼最优公式 回到目录
2.最优策略 state value是怎么衡量策略的好坏呢?如果对所有的状态s,π1得到的state value都大于π2得到的state value,就说π1比π2好 进一步就可以定义最优,如果策略π*对任意一个状态,相比任意的其他一个策略π,所得到的state value都要打,就说这个π*是最优的,定义如下 定义并不麻烦,麻烦的是定义出来后要回答一系列的问题,如: ①这个最优策略是否存在? ②最优策略是唯一的吗? ③最优策略是随机性的还是确定性的? ④怎么得到最优策略? 为了回答这些问题,我们需要研究贝尔曼最优公式 回到目录
3.贝尔曼最优公式 公式如下 这个公式很熟悉,就是贝尔曼公式,改动的地方就是前面加了maxπ,加了这个之后,式子里面的π(a|s)就不再是给定的了,因此这里面嵌套了一个优化问题,需要先解决优化问题求解出来这个π,再把π代入式子里面。式子可以写成另一种形式 这里除了π(a|s)、v(s)、v(s’)是未知的,其他都是已知的。它的矩阵向量形式就是 这里maxπ可以写成 回到目录
4.贝尔曼最优公式详细分析 贝尔曼最优公式的矩阵-向量形式中,v和π都是需要求解的,而一个式子,怎么能求两个未知量呢? 可以通过下面的例子来初步理解 同样是一个式子求解两个未知量,当要满足x为最大化等式右边式子时,首先要最小化a,因为这里是-a2,那么只有当a=0时才能得到最大化的式子2x-1,这样就能解出来了,将改思想应用到贝尔曼最优公式中 现在要做的就是确定下π(a|s),这里有多个a,在grid world例子中有5个a,分别是q(s,a1)、q(s,a2)、q(s,a3)、q(s,a4)、q(s,a5)。有这5个值,如何求解这个π,通过下面一个简单的例子了解 这个问题是为了找到c*1、c*2、c*3,使得函数能达到最大值,约束条件是c1+c2+c3=1,c1,c2,c3≥0,这个也是π的约束条件。假设q3≥q1,q2,那么该问题的最优解决方法就是c*3=1,c*1=c*2=0。因为q3是最大的,那么我们希望把所有的权重全放到q3上,因此将c*3设为最大1,数学上的解释就是因为c3=1时,下面式子成立 q3=(c1+c2+c3)q3=c1q3+c2q3+c3q3≥c1q1+c2q2+c3q3 通过这个例子就可以知道怎么来确定π,就是求最大的q值 什么时候最优呢?π的选取是a*=1,不是a*=0,a*是最大q值对应的那个动作 这就是最优项maxπΣaπ(a|s)的处理方式
接下来是形式上的变化,令 贝尔曼最优公式就能写成 为了求解贝尔曼最优公式,再引入一个基础contraction mapping theorem(压缩映射定理),下图是概念 那么压缩映射定理有三个结论,只要 f 是压缩映射,就有
通过一系列的证明,在赵老师视频的书中有公式证明,可以得到贝尔曼最优公式是一个压缩映射,因此贝尔曼最优公式存在唯一解v*,且能够通过迭代计算得出,下图是步骤 下面是一个例子 迭代次数可以设定一个条件,满足 || vk-vk-1 || < ε
下面是贝尔曼最优公式解的最优性 回到目录
5.分析最优策略的性质 对于下面的贝尔曼最优公式 我们要求的是 v(s)、π(a|s)、v(s’) 三个,其他都是已知的,既然是用已知求未知,那么能影响未知的因素,就是已知条件,也就是说贝尔曼最优公式是由这些已知因素决定的,分别是:
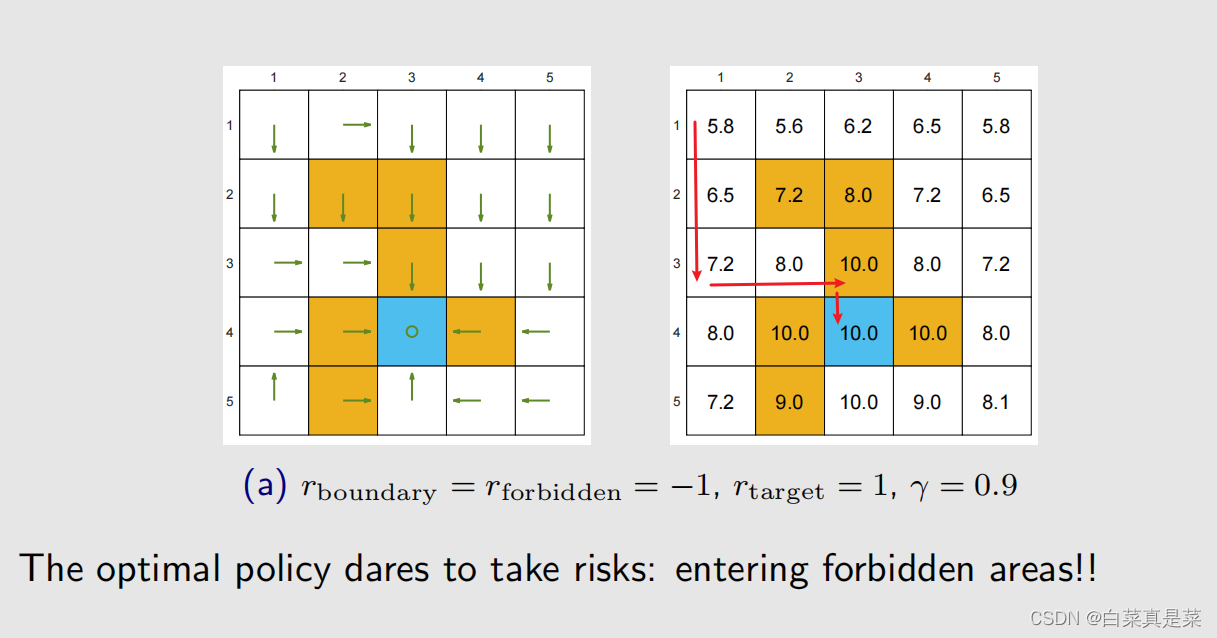
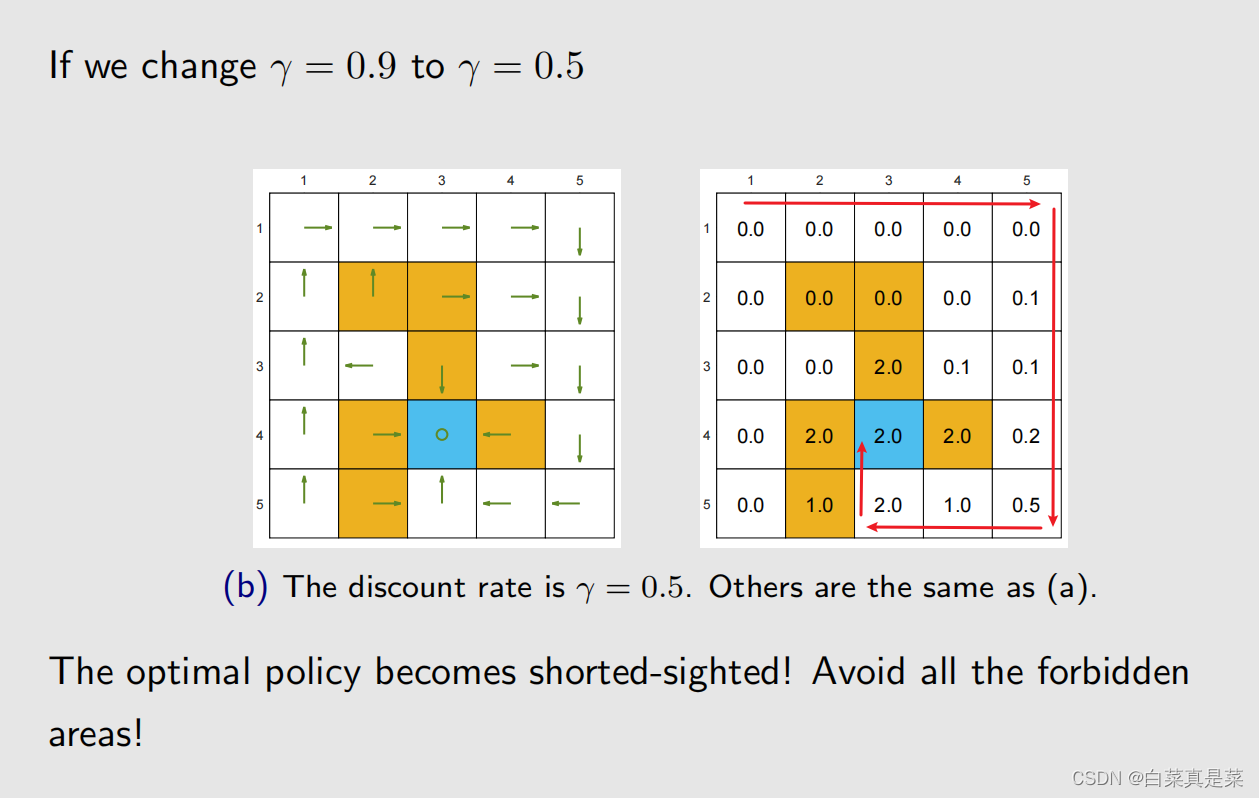
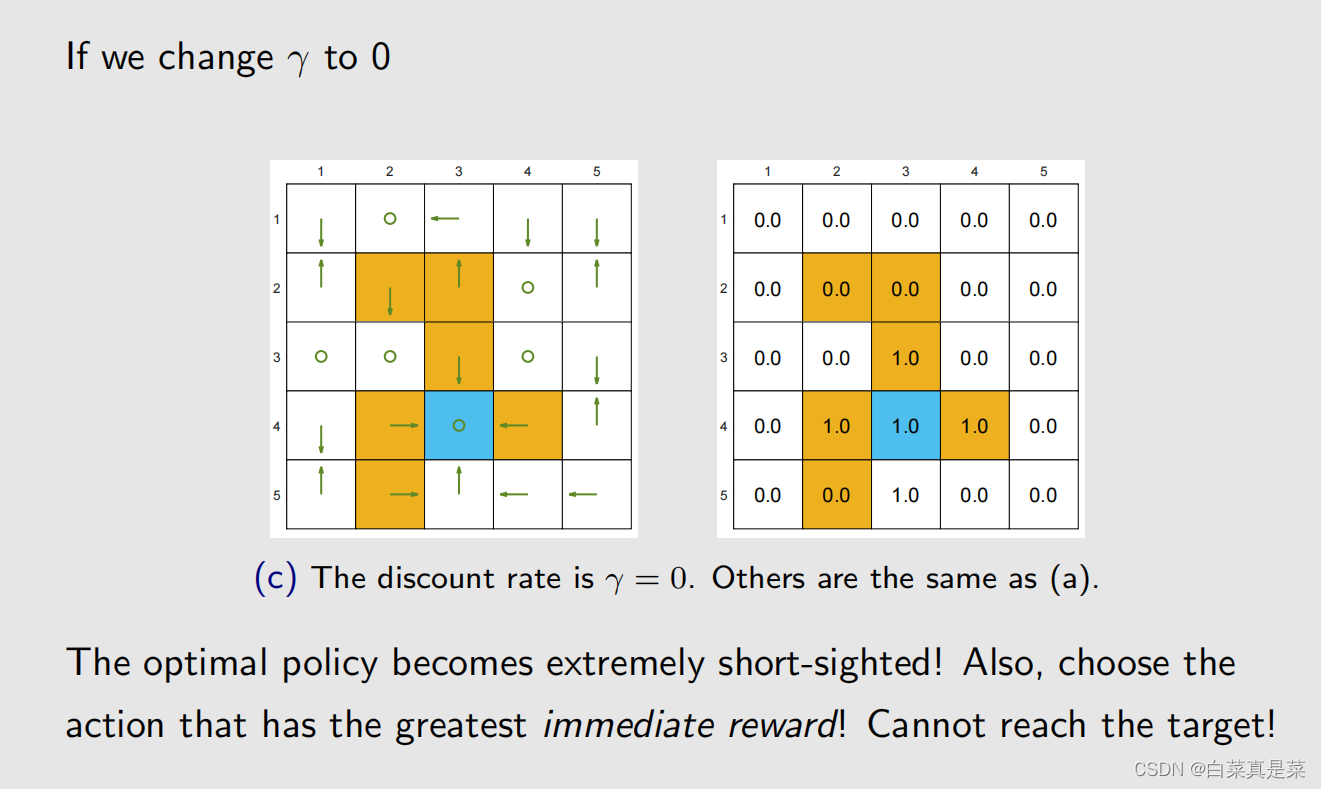
接下来考虑改变r和改变γ的时候最优策略会发生什么样的改变,因为系统模型一般是很难改变的,就不考虑改变系统模型 下面举例 这里可以发现,这个最优策略并不是绕一大圈到达蓝色目标区,而是进入了一个黄色禁止区后达到蓝色目标区 【弹幕看到一个有意思问答过程: 问:这个地方绕一大圈得到的reward是一个比较小的正数,而直接经过forbidden得到的reward是一个-1+0.9=-0.1 为什么会得到这样的policy呢?不应该绕一大圈吗? 答:因为到了目标位置之后不会停下,还会继续原地打转,会有等比数列形式的累积奖励 问:但是绕一大圈之后达到目标位置也不会停下,会一直打转,得到的奖励不应该比直接穿过forbidden的return高吗 答:我理解是你在绕一大圈时到达目标区时,我已经在里面打转到比你到达值还多了】 如果是改变参数 γ ,从0.9 -> 0.5 改变的原因是绕一大圈得到的return比直接穿过得到的return大,实质原因之前也提过,当 γ 比较大时,agent比较远视,会重视未来的reward,当 γ 比较小时,agent比较近视,会重视近期的reward 再次改变参数 γ ,从 0.5 -> 0 这时候最优策略已经变得非常近视了,瞎掉的程度,只关注即时奖励,以第3行第2列为例,该状态往上、右、下都会得到负奖励,而原地不动和向左奖励不变,这里程序里面是随机选择一个,恰好选的是原地不动,再以第3行第3列为例,该状态原地不动、往下都会得到负奖励,而往左奖励是0,往右奖励是+1,因此策略是往右 如果是增大惩罚 rforbidden = -10,此时 γ = 0.9 此时策略已经和 rforbidden = -1时不一样了 如果改变 r ,变成 ar+b 形式,如下,上面改成下面的,rotherstep并不是多出来的,是因为之前它等于0,所以就隐藏了,比如从一个白色的格子到另一个白色的格子,是不会有奖惩的,但是增加偏置量时,它就从0变成1 做了这个改变,实际上的最优策略会改变吗?实际上是不会改变的,因为最重要的不在于单个奖励的绝对价值,而在于这些奖励之间相互的价值,因为一个增加偏置量,其他也增加相同偏置量,等于没变。这个可以用下面的定理说明 该意思如下 回到目录
欢迎指正!