目录
1、标准卷积: Conv + BN + activate
2、DWConv深度可分离卷积
3、Bottleneck瓶颈层
4、BottleneckCSP-CSP瓶颈层
5、ResNet模块
6、SPP空间金字塔池化模块
7、focus
8、PAN特征融合
9、GIOU DIOU CIOU
yolov5的融合采用的是一个普通的CBL(conv–bn–leakyrelu)。
新版:CBL(conv–bn–SiLU)。
1、标准卷积: Conv + BN + activate
class Conv(nn.Module):
# Standard convolution
# ch_in, ch_out, kernel, stride, padding, groups
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True):
super(Conv, self).__init__()
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p), groups=g, bias=False)
self.bn = nn.BatchNorm2d(c2)
self.act = nn.Hardswish() if act is True else (act if isinstance(act, nn.Module) else nn.Identity())
def forward(self, x):
return self.act(self.bn(self.conv(x)))
def fuseforward(self, x):
return self.act(self.conv(x))
参数说明:
-
g:groups,通道分组的参数,输入通道数、输出通道数必须同时满足被groups整除;
groups: 如果输出通道为6,输入通道也为6,假设groups为3,卷积核为 1x1 ; 则卷积核的shape为2x1x1,即把输入通道分成了3份;那么卷积核的个数呢?之前是由输出通道决定的,这里也一样,输出通道为6,那么就有6个卷积核!这里实际上是将卷积核也平分为groups份,在groups份特征图上计算,以输入、输出都为6为例,每个2xhxw的特征图子层就有且仅有2个卷积核,最后相加恰好是6。这里可以起到的作用是不同通道分别计算特征!
参数的参考资料1、参考资料2!
Top --- Bottom
2、DWConv深度可分离卷积
def DWConv(c1, c2, k=1, s=1, act=True):
# Depthwise convolution
return Conv(c1, c2, k, s, g=math.gcd(c1, c2), act=act)
这里的深度可分离卷积,主要是将通道按输入输出的最大公约数进行切分,在不同的通道图层上进行特征学习!
关于深度可分离卷积的更早资料参考:我的github
3、Bottleneck瓶颈层
class Bottleneck(nn.Module):
# Standard bottleneck
def __init__(self, c1, c2, shortcut=True, g=1, e=0.5): # ch_in, ch_out, shortcut, groups, expansion
super(Bottleneck, self).__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_, c2, 3, 1, g=g)
self.add = shortcut and c1 == c2
def forward(self, x):
return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))
参数说明:
- c1:bottleneck 结构的输入通道维度;
- c2:bottleneck 结构的输出通道维度;
- shortcut:是否给bottleneck 结构添加shortcut连接,添加后即为ResNet模块;
- g:groups,通道分组的参数,输入通道数、输出通道数必须同时满足被groups整除;
- e:expansion: bottleneck 结构中的瓶颈部分的通道膨胀率,使用0.5即为变为输入的1212;
模型结构:
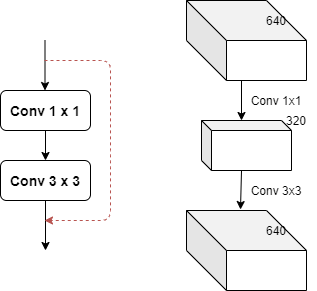
这里的瓶颈层,瓶颈主要体现在通道数channel上面!一般1x1卷积具有很强的灵活性,这里用于降低通道数,如上面的膨胀率为0.5,若输入通道为640,那么经过1x1的卷积层之后变为320;经过3x3之后变为输出的通道数,这样参数量会大量减少!
这里的shortcut即为图中的红色虚线,在实际中,shortcut(捷径)不一定是上面都不操作,也有可能有卷积处理,但此时,另一支一般是多个ResNet模块串联而成!这里使用的shortcut也成为identity分支,可以理解为恒等映射,另一个分支被称为残差分支(Residual分支)。
我们常使用的残差分支实际上是1x1+3x3+1x1的结构!
Top --- Bottom
4、BottleneckCSP-CSP瓶颈层
class BottleneckCSP(nn.Module):
# CSP Bottleneck https://github.com/WongKinYiu/CrossStagePartialNetworks
# ch_in, ch_out, number, shortcut, groups, expansion
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5):
super(BottleneckCSP, self).__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = nn.Conv2d(c1, c_, 1, 1, bias=False)
self.cv3 = nn.Conv2d(c_, c_, 1, 1, bias=False)
self.cv4 = Conv(2 * c_, c2, 1, 1)
self.bn = nn.BatchNorm2d(2 * c_) # applied to cat(cv2, cv3)
self.act = nn.LeakyReLU(0.1, inplace=True)
self.m = nn.Sequential(*[Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)])
def forward(self, x):
y1 = self.cv3(self.m(self.cv1(x)))
y2 = self.cv2(x)
return self.cv4(self.act(self.bn(torch.cat((y1, y2), dim=1))))
参数说明:
- c1:BottleneckCSP 结构的输入通道维度;
- c2:BottleneckCSP 结构的输出通道维度;
- n:bottleneck 结构 结构的个数;
- shortcut:是否给bottleneck 结构添加shortcut连接,添加后即为ResNet模块;
- g:groups,通道分组的参数,输入通道数、输出通道数必须同时满足被groups整除;
- e:expansion: bottleneck 结构中的瓶颈部分的通道膨胀率,使用0.5即为变为输入的1212;
- torch.cat((y1, y2), dim=1):这里是指定在第11个维度上进行合并,即在channel维度上合并;
- c_:BottleneckCSP 结构的中间层的通道数,由膨胀率e决定。
模型结构:
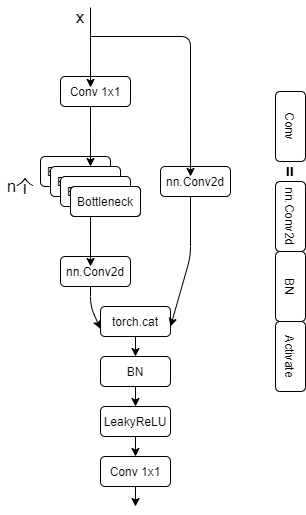
CSP瓶颈层结构在Bottleneck部分存在一个可修改的参数n,标识使用的Bottleneck结构个数!这一条也是我们的主分支,是对残差进行学习的主要结构,右侧分支nn.Conv2d实际上是shortcut分支实现不同stage的连接。
Top --- Bottom
5、ResNet模块
残差模块是深度神经网络中非常重要的模块,在创建模型的过程中经常被使用。
残差模块结构如其名,实际上就是shortcut的直接应用,最出名的残差模块应用这样的:


左边这个结构即Bottleneck结构,也叫瓶颈残差模块!右边的图片展示的是基本的残差模块!
Top --- Bottom
6、SPP空间金字塔池化模块
class SPP(nn.Module):
# Spatial pyramid pooling layer used in YOLOv3-SPP
def __init__(self, c1, c2, k=(5, 9, 13)):
super(SPP, self).__init__()
c_ = c1 // 2 # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_ * (len(k) + 1), c2, 1, 1)
self.m = nn.ModuleList([nn.MaxPool2d(kernel_size=x, stride=1, padding=x // 2) for x in k])
def forward(self, x):
x = self.cv1(x)
return self.cv2(torch.cat([x] + [m(x) for m in self.m], 1))
SPP即为空间金字塔池化模块!上面的代码是yolov5的模型代码,可视化为:
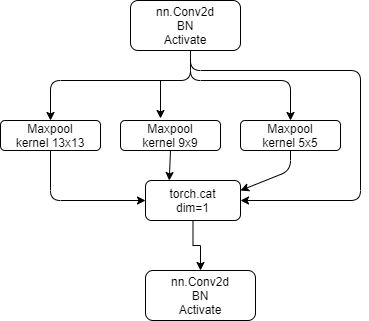
三种池化核,padding都是根据核的大小自适应,保证池化后的特征图[H, W]保持一致!
7、focus
yolov5中focus的定义如下:
class Focus(nn.Module):
# Focus wh information into c-space
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True): # ch_in, ch_out, kernel, stride, padding, groups
super().__init__()
self.conv = Conv(c1 * 4, c2, k, s, p, g, act)
# self.contract = Contract(gain=2)
def forward(self, x): # x(b,c,w,h) -> y(b,4c,w/2,h/2)
return self.conv(torch.cat([x[..., ::2, ::2], x[..., 1::2, ::2], x[..., ::2, 1::2], x[..., 1::2, 1::2]], 1))
# return self.conv(self.contract(x))
从图像上能够更加直观地理解
4 * 4 * 3 变成 2 * 2 * 12

x[..., ::2, ::2]意义如下图
... :表示所有通道(图中为3通道)
::2 :表示第一行开始到最后一行结束,步长为2的所有值(图中第一行,第三行所有值)
::2 :表示第一列开始到最后一列结束,步长为2的所有值(图中第一列,第三列所有值)
最终交集为图中标1的方块(图中红底标出)

torch.cat( )的用法
如果我们有两个tensor是A和B,想把他们拼接在一起,需要如下操作:
C = torch.cat( (A,B),0 ) #按维数0拼接(竖着拼)
C = torch.cat( (A,B),1 ) #按维数1拼接(横着拼)
————————————————
版权声明:本文为CSDN博主「ynxdb2002」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/ynxdb2002/article/details/113963263
8、PAN特征融合
Neck-路径聚合网络(PANET)
Neck主要用于生成特征金字塔。特征金字塔会增强模型对于不同缩放尺度对象的检测,从而能够识别不同大小和尺度的同一个物体。在PANET出来之前,FPN一直是对象检测框架特征聚合层的State of the art,直到PANET的出现。在YOLO V4的研究中,PANET被认为是最适合YOLO的特征融合网络,因此YOLO V5和V4都使用PANET作为Neck来聚合特征。
PANET基于 Mask R-CNN 和 FPN 框架,同时加强了信息传播。该网络的特征提取器采用了一种新的增强自下向上路径的 FPN 结构,改善了低层特征的传播。第三条通路的每个阶段都将前一阶段的特征映射作为输入,并用3x3卷积层处理它们。输出通过横向连接被添加到自上而下通路的同一阶段特征图中,这些特征图为下一阶段提供信息。同时使用自适应特征池化(Adaptive feature pooling)恢复每个候选区域和所有特征层次之间被破坏的信息路径,聚合每个特征层次上的每个候选区域,避免被任意分配。
作者:william
链接:https://www.zhihu.com/question/399884529/answer/1343439934
9、GIOU DIOU CIOU
YOLOv5学习总结(持续更新)_dididi的博客-CSDN博客_yolov5