目录
生存分析基本概念
生存率估计
1. 乘积极限法
2. 寿命表法
3. 生存曲线
生存曲线比较
COX比例风险回归模型
1. 建立COX回归模型
2. 比例风险假定的检验
3. 生存预测
生存分析基本概念
logistic回归中因变量是终点事件发生与否,而生存分析则关注的是终点事件所经历的时间。
生存资料的特点:1.随访资料,包括两个方面时间和结局;2.时间—事件变量;3.有不完全数据;
生存分析:就是用来研究“生存”过程的统计方法;研究生存时间;时间与事件的关系
生存资料的三要素:
- 研究因素
- 生存时间
- 生存结局
生存资料的分析:
(1)估计:根据样本生存资料估计总体生存率和其他有关指标;
(2)比较:对不同组生存曲线进行比较;
(3)影响因素分析:目的是探索和了解影响预后的因素,或平衡某些因素的影响后,研究某个或者某些因素对生存的影响。
生存时间(survival time):根据研究目的确定的观察起点到某一给定终点 事件出现的时间。 类型:
(1)完全数据:随访研究中,在规定的时间内,若观察到某些对象的死亡结局所经历的时间,称为生存时间的完全数据。
(2)删失数据:随访研究中,在规定的时间内,由于某些原因未能观察到某些对象的死亡结局,提供的是从手术到停止观察的时间长度,并非确切的生存时间,称为生存时间的删失数据(censored data)
删失常见的原因:
- 研究结束时终点事件未发生
- 由于未继续就诊、拒绝随访或失去联系等失访,未能观察到其死亡结局
- 因死于其他原因终止观察
起始事件:标志研究对象生存过程开始的特征事件,又称为起点事件,与终点事件相对应。
终点事件:指研究者所关心的特定事件,又称为失效事件,标志着“生存”的终止。失效事件不一定是不好额事件,只表示特点事件的发生。
截尾:又称为终检或删失,指在发生终点事件之前,被观察对象的观测过程终止了。没有观察到所关心终点事件的发生。
特点:不完全信息(不知道确切的生存时间),但可知真实的生存时间不会短于现在观察的时间。
生存概率和死亡概率:
生存概率:某单位时段开始存活的个体,到该时段结束时仍存活的可能性。

死亡概率:表示某单位时段开始存活的个体,在该时段内死亡的可能性。

若观察时段相同,p+q=1
生存率与风险率:
生存率(survival rate)也即是生存函数指观察对象活过t个单位时段的可能性,记为S(t)。 如果没有删失数据,直接法计算生存率: 若有删失数据,须分段计算生存概率:
若有删失数据,须分段计算生存概率:
风险率(hazard rate)或风险函数表示t时刻存活的个体在t时刻的瞬时死亡风险。
生存率估计
非参数法估计的生存率主要有寿命表法(life table method)和乘积极限法(product limit method),前者适用于生存时间按区间分组的大样本资料,后者适用于仅含个体生存时间的小样本或者大样本资料。
分析思想:先求出各个时段的生存概率,然后根据概率乘法定理估计生存率。
1. 乘积极限法
又称为K-M法,乘积的含义:生存率等于生存概率的乘积;极限的含义:寿命表法中的时间区间长度趋近于0,也即是有明确的生存时间或截尾时间。
条件:每个对象均有确切的生存时间/截尾时间;tk时刻的生存率等于tk时刻之前各点生存概率的乘积;不需要对资料分布类型进行假设。
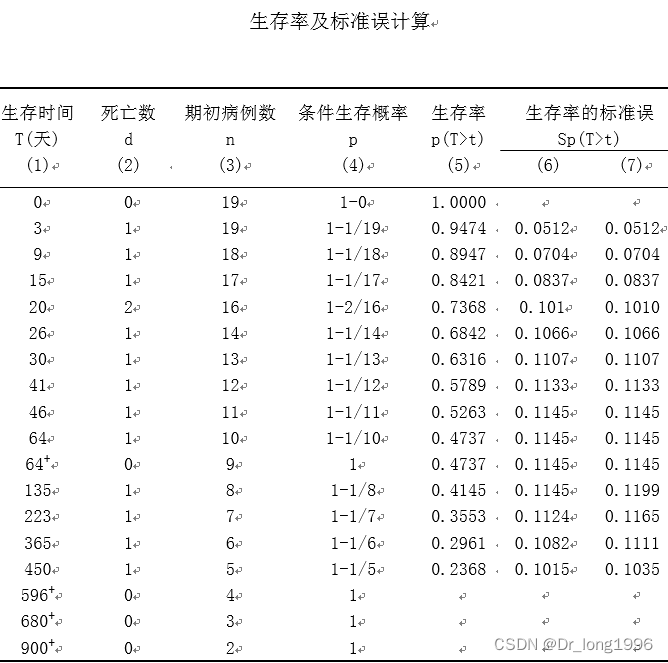
基本计算步骤:
- 将生存时间(
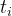 )由小到大排序,完全数据和删失数据相同时,删失数据在完全数据的后面;
)由小到大排序,完全数据和删失数据相同时,删失数据在完全数据的后面;
- 列出时间区间[
 )上的死亡数
)上的死亡数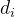 和删失数
和删失数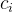 ;
;
- 计算期初例数,恰在某一时刻之前的生存人数
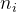 ;
;
- 计算死亡概率
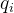 和生存概率
和生存概率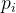 ;
;
- 计算生存率
 ,注意删失时间处不做变换,删失时间的影响只体现在期初例数的计算上。
,注意删失时间处不做变换,删失时间的影响只体现在期初例数的计算上。
(1)创建生存对象:将研究对象的结局变量由“time”(时间)和“event”(事件)组成。
生存对象可以由survival包中的函数Surv()生成,是一种将事件和时间合并在一起的数据结局。
案例:比较卵巢癌患者在两种治疗方法下的生存率
library(survival)
library(survminer)
data(ovarian)
str(ovarian)
attr(ovarian,"var.labels")[1:6]<- c("随访时间",
"结局状态:0存活,1死亡",
"患者年龄",
"疾病残留情况:1没有残留,2有残留",
"治疗方法:1环磷酰胺,2环磷酰胺加阿霉素",
"患者的ECOG评分,1较好,2较差")
library(epiDisplay)
des(ovarian)
attributes(ovarian)
summary(ovarian)
对分类变量进行因子化
ovarian$resid.ds <- factor(ovarian$resid.ds,
levels = c(1,2),
labels = c("no","yes"))
ovarian$rx <- factor(ovarian$rx,
levels = c(1,2),
labels = c("A","B"))
ovarian$ecog.ps <- factor(ovarian$ecog.ps,
levels = c(1,2),
labels = c("good","bad"))
hist(ovarian$age)#年龄不对称将,年龄进行因子化
ovarian$agegr <- cut(ovarian$age,
breaks = c(0,50,75),
labels = c("<=50",">50"))#按50为分界值将,年龄分成两组
table(ovarian$agegr)
创建生存对象:
surv.obj <- Surv(time =ovarian$futime,event = ovarian$fustat);surv.obj

在生存对象中,“+”号表示删失数据,例如,第四个值“421+”,表示这个患者并未在421天死于卵巢癌,只是没有继续随访
(2) 生存率估计
生存率估计的基本格式:
survfit(Surv(生存时间,结局)~分组变量,data),survfit根据KM法创建生存曲线,如果没有分组变量,就用"1"代替。
其中Surv(生存时间,结局)就是上面提到的生存对象。
survfit(surv.obj~1)
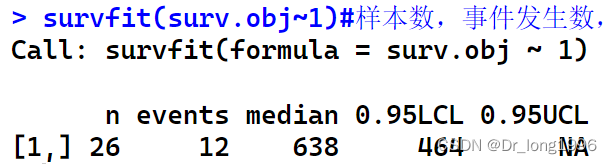
依次展示的是样本数,事件发生数,中位生存时间,中位生存时间的置信区间。因为数据样本较小,生存曲线没有穿过生存率在50%对应的水平先,无法计算生存时间置信区间的上限。
通过summary()函数对生存分析的数据进行展示,显示具体的各时间段的生存概率和生存率。
fit <- survfit(surv.obj~1)
summary(fit)#不显示删失数据
summary(fit,censored = T)#包含删失数据

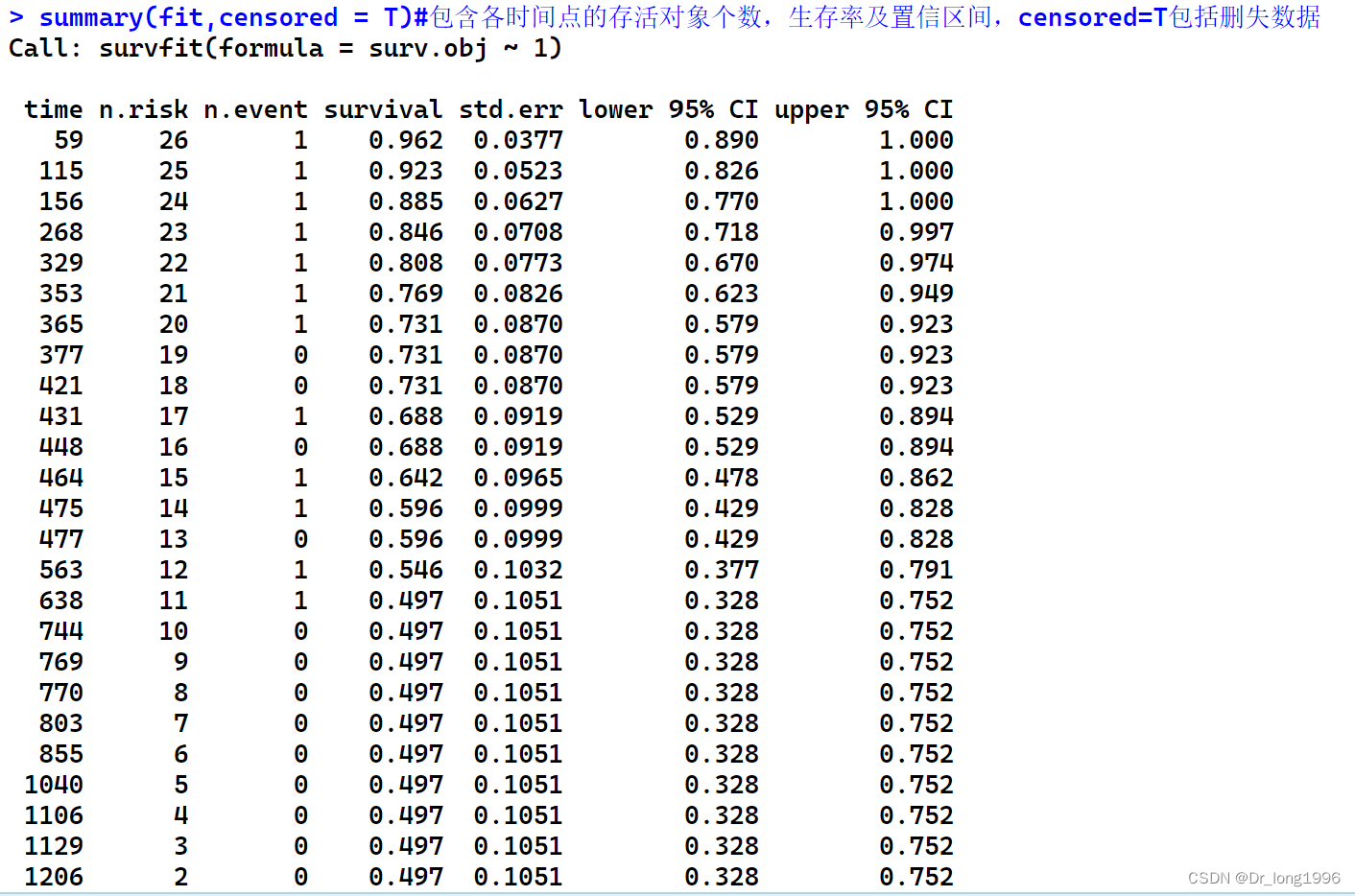
参数censored默认未FALSE,通过TRUE可以展示删失数据。包含各时间点的存活对象个数,生存率及置信区间,censored=T包括删失数据
2. 寿命表法
资料是分时间段收集,数据按时间区组分组
对于每个时间段,假定死亡情况在每个时间段均匀出现,即生存率匀速下降
假定删失的发生在时间段内也是均匀分布,区间中删失个体算半个人时,校正观察例数
两种方法的选择:
- #寿命表法:适用于时间分段或无法得知准确生存时间的资料,区间内生存率呈线性的变化
- #KM法:要求每个观测对象有明确的死亡时间和截尾时间
3. 生存曲线
生存曲线是一条横坐标以时间为参数,纵坐标以生存率为参数的统计图。
(1)基础包plot绘图
plot(fit,mark.time = T)
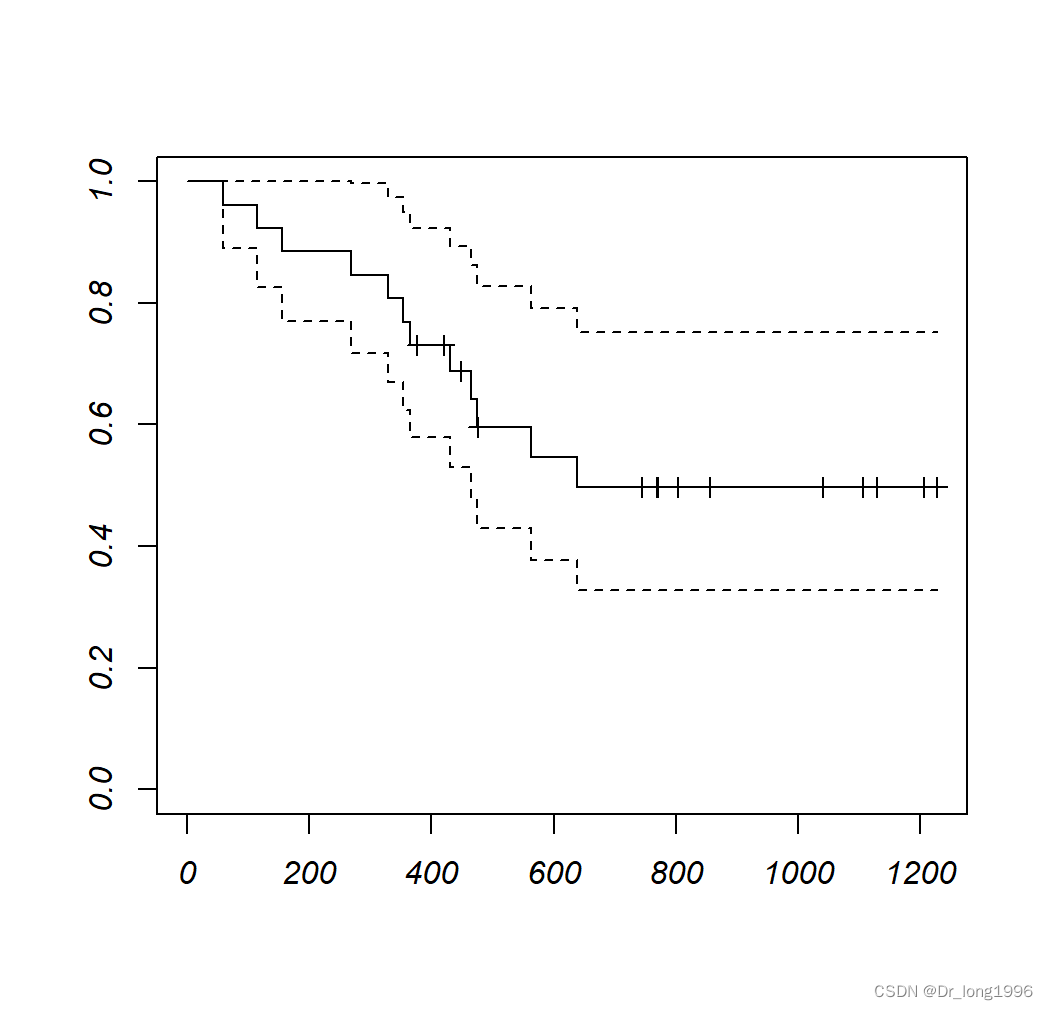
mark.time=T为删失数据添加标记"+",不想按展示置信区间conf.int=F
(2)用survival包函数ggsurvplot()绘制生存曲线
ggsurvplot(fit,pval=T,conf.int = T) #生存曲线
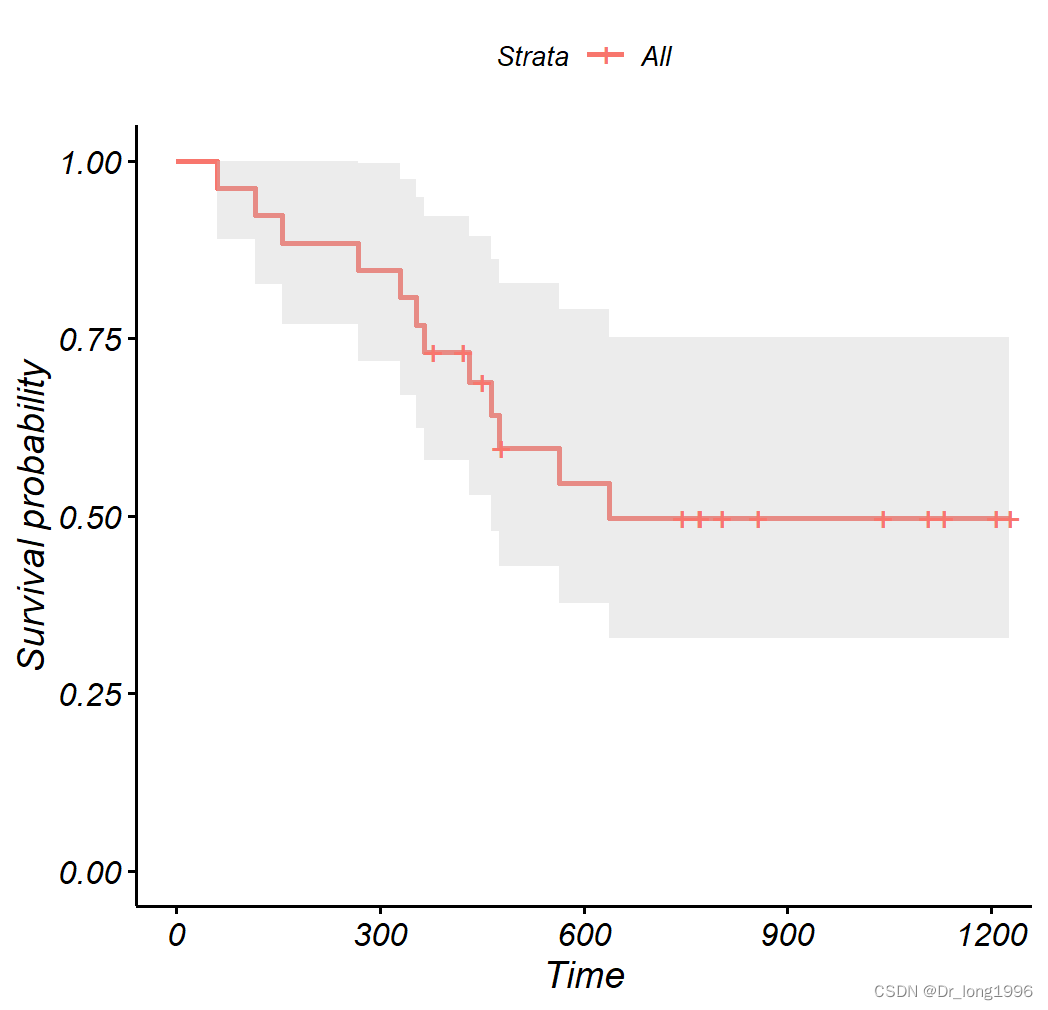
(3)死亡曲线
ggsurvplot(fit,pavl=T,conf.int = F,fun = "event",ylim=c(0,1))
fun表示绘制不同类型的曲线,event绘制累积事件,cumhaz绘制累积危险函数,pct表示百分比表示生存率
总结:
Survfit(Surv(生存时间,结局)~分组变量,data),survfit根据KM法创建生存曲线,如果没有分组变量,就用"1"代替
ggsurvplot(fit,pval=TRUE,conf.int=FALSE),fit表示生存曲线函数,pval是否将p值显示到曲线上,conf.int是否显示置信区间条带
surv_diff <- survdiff(Surv(生存时间,结局)~分组变量,data),按照分组变量进行不同组别生存曲线的比较
生存曲线比较
案例:想要比较不同治疗方式下的生存率差异?
分析:由治疗方式作为分组,进行上述操作。
surv.treat <- survfit(surv.obj~rx,data=ovarian)#创建生存对象
summary(surv.treat,censored = T)#计算生存率
plot(surv.treat,mark.time = T, #绘制生存曲线
conf.int = F,
lty=c(1,2),
lwd=2,
col = c("red","blue"))
legend(60,0.3,title = "KM cur",
legend=c("环磷酰胺","环磷酰胺+阿霉素"),
lty=c(1,2),
lwd=2,
col = c("red","blue"))
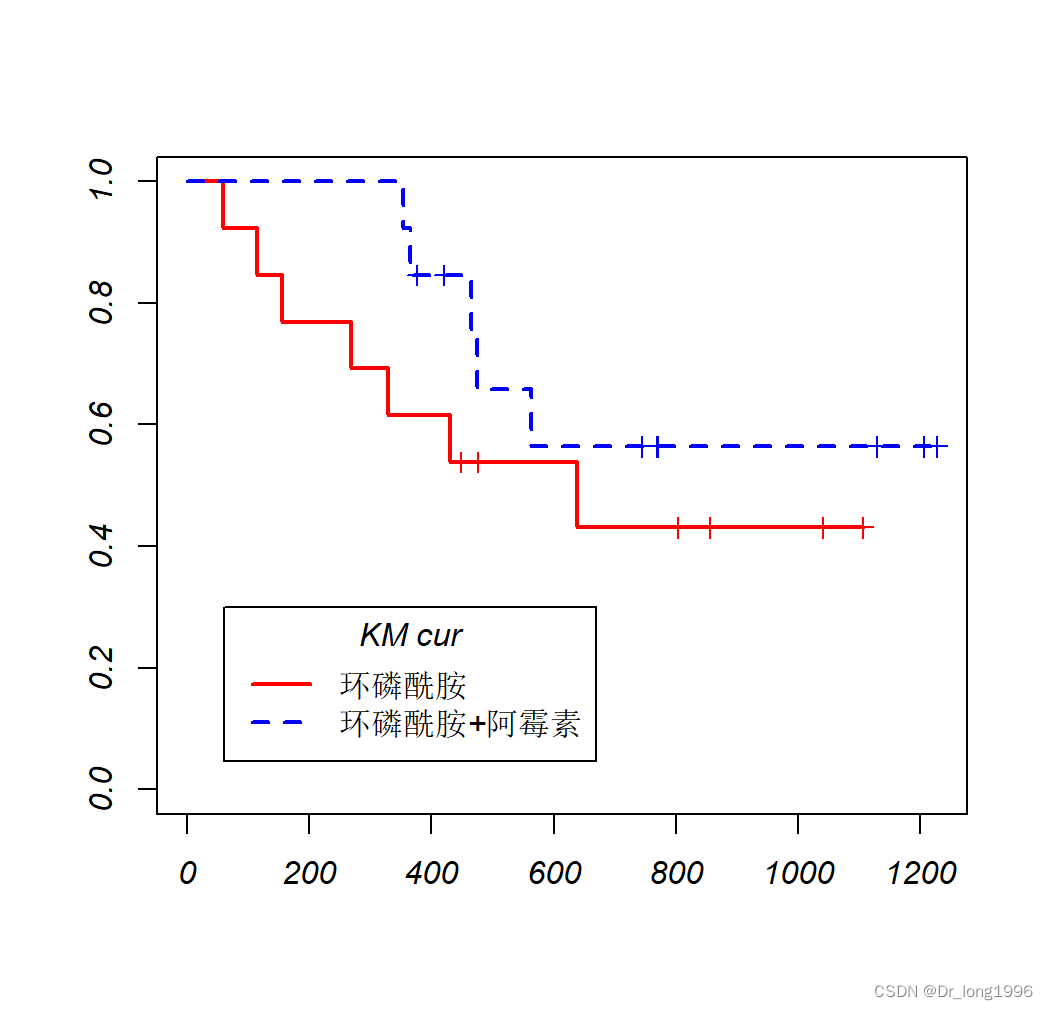
#survmuner包中的ggsurplot以ggplot2的风格提供更丰富的图形输出
ggsurvplot(surv.treat,data=ovarian,pval=T)
survdiff(surv.obj~agegr,data = ovarian)
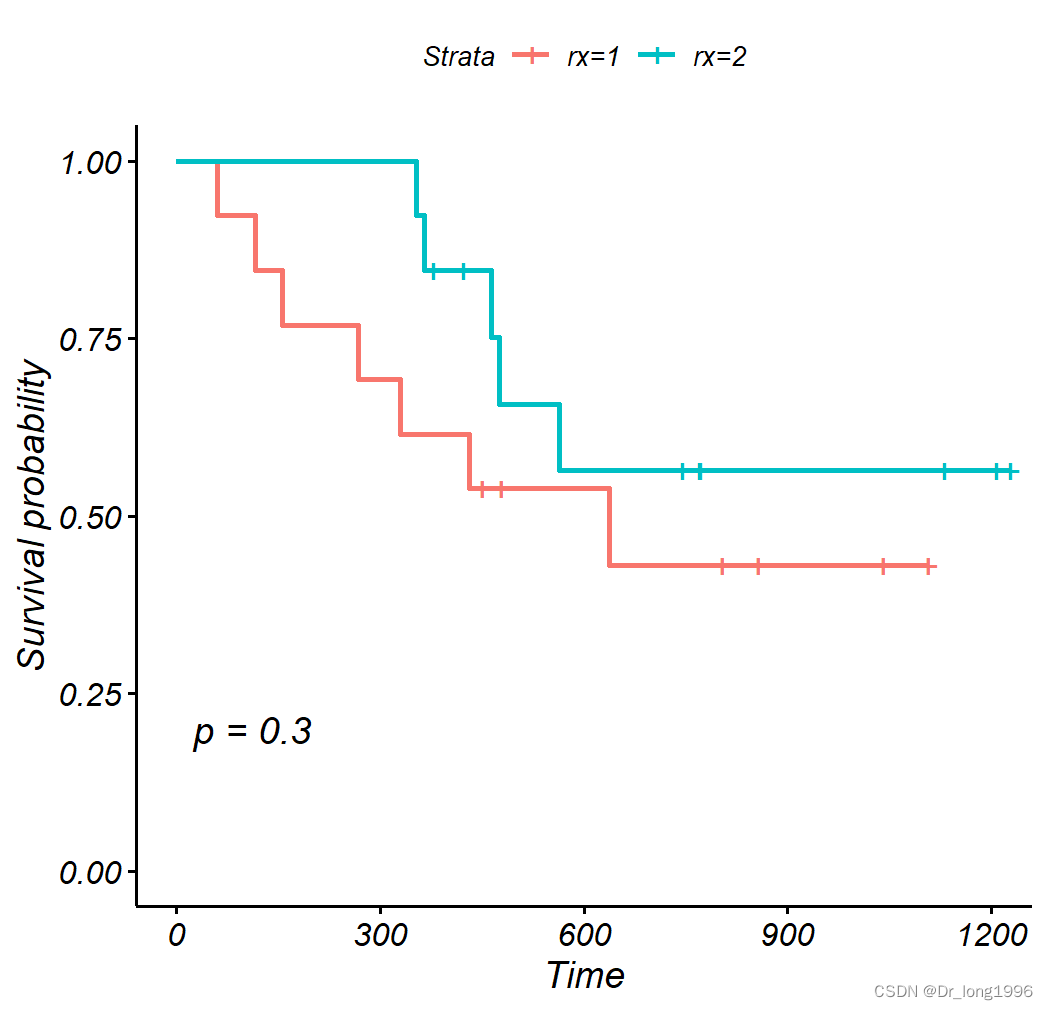
生存曲线的比较:
Log-rank检验:时序检验,属于非参数的方法,比较整个生存时间的分布。可以通过函数survdiff(生存对象~分组,data=《MYDATA》)格式计算。
surv_diff <- survdiff(Surv(futime,fustat)~rx,data=ovarian);surv_diff
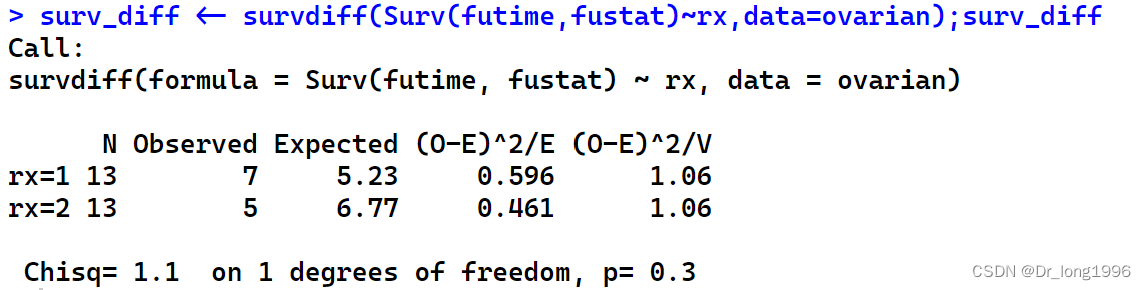
根据上述结果,两种治疗方法在生存率的差异没有统计学差异。但是两组中研究对象可能被其他影响生存的因素如年龄,疾病残留情况,患者的ECOG评分影响,需要使用回归分析,把这些因素作为协变量解释两组之间的差异。
注意:当不同时间段内生存情况的优劣存在交叉时,log-rank检验不适用,,表现为生存曲线存在明显交叉
COX比例风险回归模型
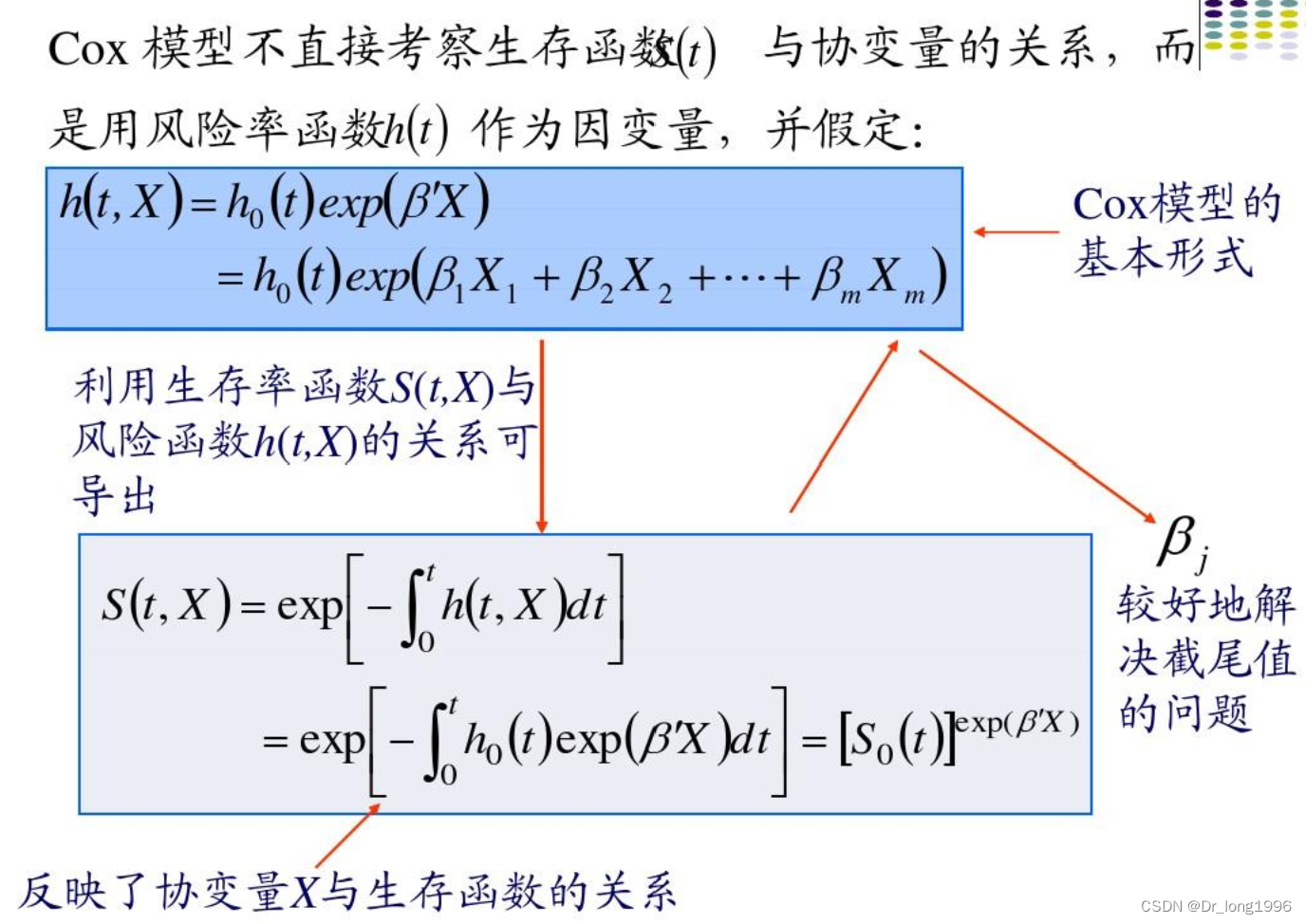
风险率(hazard rate)或风险函数表示t时刻存活的个体在t时刻的瞬时死亡风险。风险函数h(t)用于度量在某个时刻t还存活的个体在极短时间内死亡的风险。h(t)=寿命分布函数f(t)/S(t)
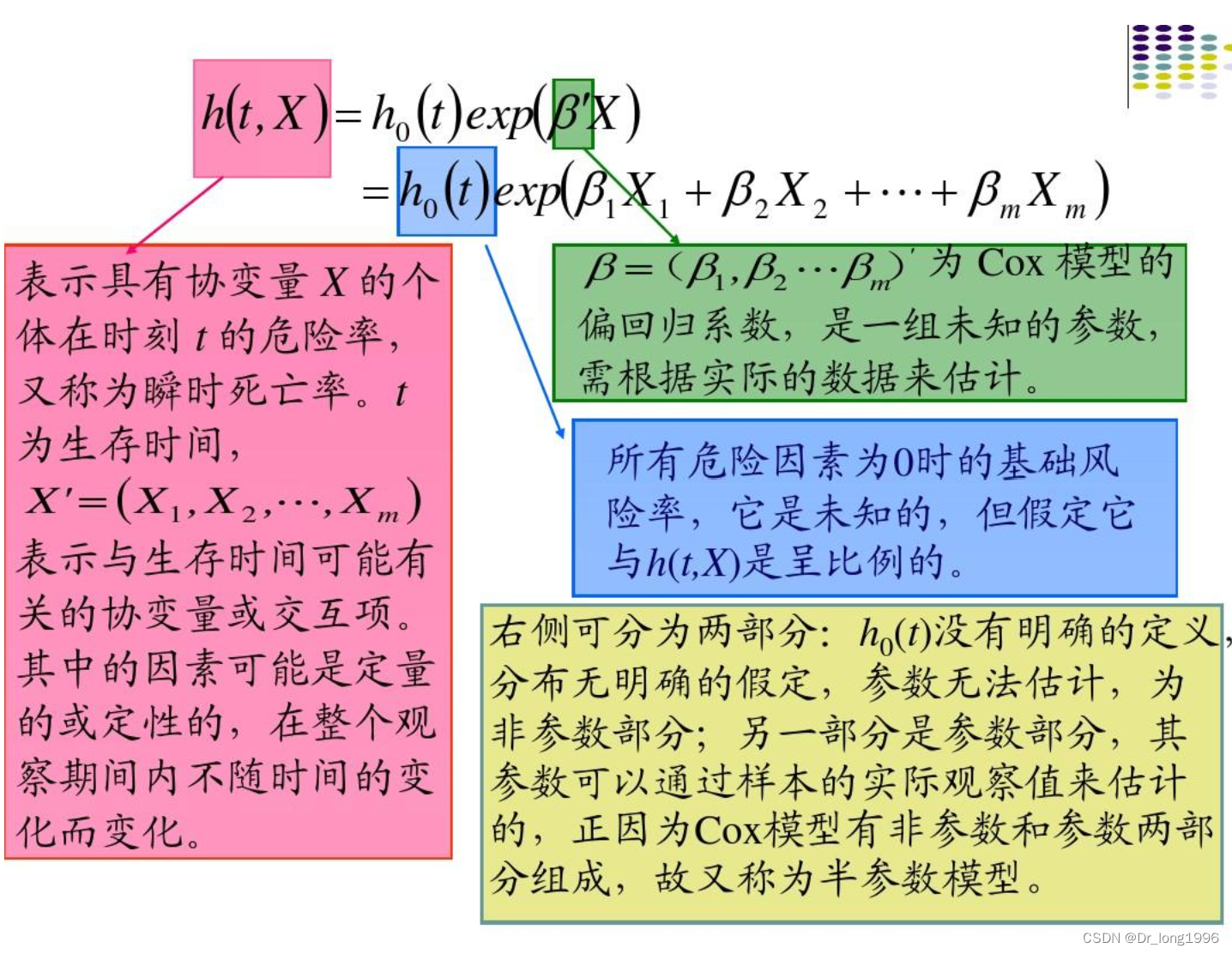

COX回归模型的两个前提假设:
- 各个危险因素的作用不随时间的变化而变化,即
 不会随着时间的变化而变化;
不会随着时间的变化而变化;
- 对数线性假定:模型中协变量应该与对数风险比成线性关系。
COX回归分析的一般步骤:
1. 分析前的准备——数据整理
2. 参数估计,建立最佳模型
3. 假设检验
4. Cox模型的解释及应用
5. Cox模型拟合优度的考察
1. 建立COX回归模型
案例分析:
将所有协变量都包含进来建立cox回归模型:
cox1 <- coxph(surv.obj~rx+resid.ds+agegr+ecog.ps,data=ovarian)
summary(cox1)

调整协变量后,rx组p值0.0322有统计学差异,因此两种治疗方法下死亡风险有统计学差异。
与多重线性回归类似,多重cox回归也存在变量选择问题,对包含所有自变量的模型cox1使用函数drop1()可以得到各个自变量的似然比检验结果。
drop1(cox1,test = "Chisq")
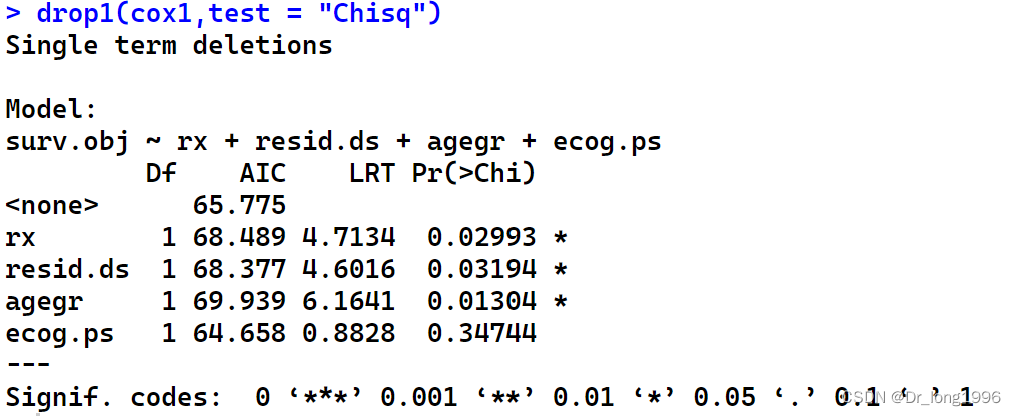
计算各个自变量似然比检验,ecog.ps对于的p值最大,从模型中剔除。也可以使用step()函数基于AIC进行变量选择。
cox2 <- coxph(surv.obj~rx+resid.ds+agegr,data=ovarian)
step.cox <- step(cox1)
step的结果也表明cox2是最优模型
2. 比例风险假定的检验
验证cox回归的比例风险假定,使用函数cox.zph()
cox.zph(cox2)
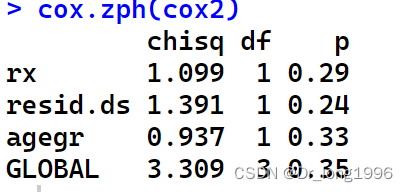
结果表明各个自变量检验和全局检验p值都大于0.05,没有违背比例风险的假定
summary(cox2)

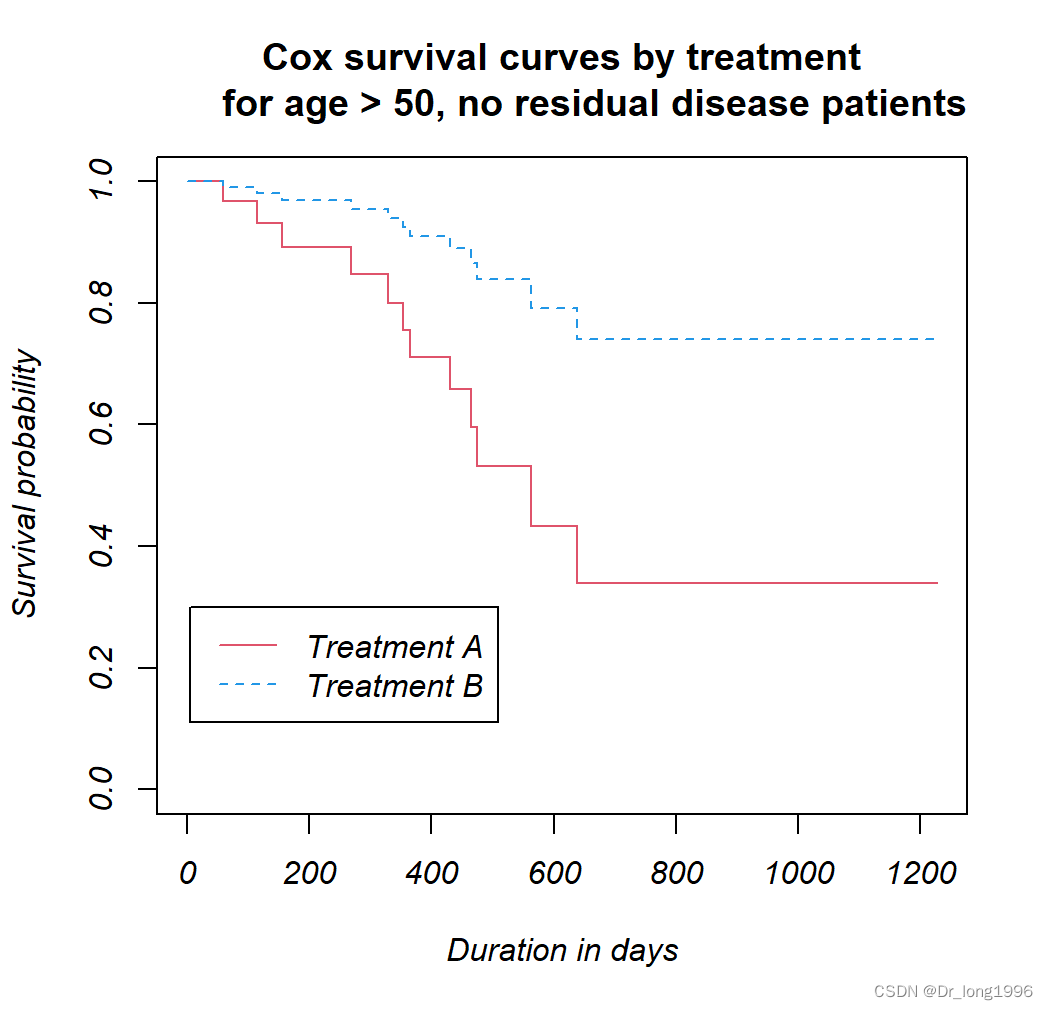
接受方法B治疗的死亡风险是方法A的27.78%,反过来,治疗A方法的死亡风险是B方法的3.599倍,同时不同残留情况以及不同年龄组之间的死亡风险差异均无统计学差异
3. 生存预测
newdata <- data.frame(rx = c("A" , "B"),
resid.ds = c("no", "no"),
agegr = c(">50", ">50"))
newdata
hr <- predict(cox2, newdata = newdata, type = "risk")
hr
hr[1]/hr[2]
A治疗比B治疗的风险
#大于50岁,都没有风险残留的病A治疗的死亡风险是B治疗的3.599倍
#使用KM拟合生存曲线更直观展示两种治疗方式下的生存率变化
绘制生存曲线:
cox.fit <- survfit(cox2, newdata = newdata, type = "kaplan-meier")
plot(cox.fit, lty = c(1, 2), col = c(2, 4))
title(main="Cox survival curves by treatment
for age > 50, no residual disease patients",
xlab="Duration in days",
ylab="Survival probability",
las = 1)
legend(5, 0.3, c("Treatment A", "Treatment B"),
lty = c(1, 2), col = c(2, 4))