这里主要再简单看一下框架图:
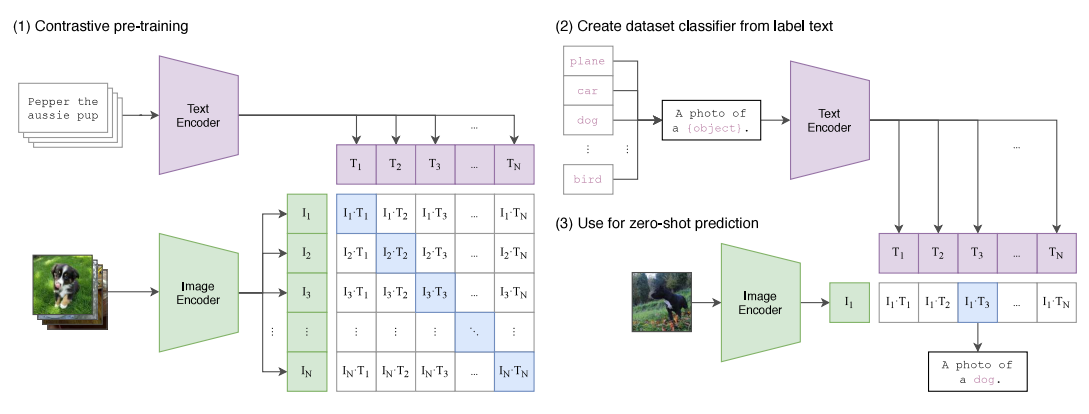
- 训练比较简单,使用的是对比学习的方法,做图文匹配的任务,计算相似度。给定batch =
N
N
N的image-text pairs,CLIP预测
N
×
N
N \times N
N×N的概率(利用线性变换得到multi-modal embedding space的向量,点乘计算得到相似度),对角线即为正样本,其它都是负样本。
- 预测分类的使用,将label构建成文本,再分别计算相似度即可得到答案。
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)