一、项目背景及目的
1.1 项目背景
移动互联网企业从粗放式到精细化运营管理过程中,需要结合市场、渠道、用户行为等数据分析,对用户开展有针对性的运营活动,提供个性化、差异化的运营策略,以实现运营业务指标。本项目利用sql对淘宝用户行为数据进行分析,通过用户行为分析业务问题,提供针对性的运营策略。
1.2 项目目的
本次分析的目的是想通过对淘宝用户行为数据分析,为以下问题提供解释和改进建议:
1.分析用户使用APP过程中的常见电商分析指标,建立用户行为转化漏斗模型,确定各个环节的流失率,找到需要改进的环节
2.研究用户在不同时间尺度下的行为规律,找到用户在不同时间周期下的活跃规律,在用户活跃时间点推出相应营销策略
3.找到用户对不同种类商品的偏好,找到针对不同商品的营销策略
4.找出最具价值的核心付费用户群,对这部分用户的行为进行分析
1.3 数据集来源与介绍
- 数据集来自阿里云天池:数据链接
- 本数据集包含了2017年11月25日至2017年12月3日之间,有行为的约一百万随机用户的所有行为(行为包括点击、购买、加购、喜欢)。数据集的组织形式和MovieLens-20M类似,即数据集的每一行表示一条用户行为,由用户ID、商品ID、商品类目ID、行为类型和时间戳组成,并以逗号分隔。关于数据集中每一列的详细描述如下:
| 列名称 | 说明 |
| 用户ID | 整数类型,序列化后的用户ID |
| 商品ID | 整数类型,序列化后的商品ID |
| 商品类目ID | 整数类型,序列化后的商品所属类目ID |
| 行为类型 | 字符串,枚举类型,包括(‘pv’, ‘buy’, ‘cart’, ‘fav’) |
| 时间戳 | 行为发生的时间戳 |
| 行为类型 | 说明 |
| pv | 商品详情页pv,等价于点击 |
| buy | 商品购买 |
| cart | 将商品加入购物车 |
| fav | 收藏商品 |
二、数据导入
两种导入方式:
- 1、使用图形界面工具导入,例如Navicat(操作简单)
- 2、cmd中以系统命令行导入(速度更快)
2.1 图形界面工具导入
新建数据库

导入数据表

选择导入前1000000行数据
需要注意源数据集中不包含字段名称行,导入时字段名行设置为0,第一个数据行设置为1。

设置字段类型

导入完成,耗时1分21秒

修改字段名

- 注意:源数据集中,时间存储格式是从新纪元开始后的秒数,需要进行进行数据格式转换。
2.2 以系统命令行导入
使用命令行连接MySQL,并进入到taobao数据库

创建新表user
载入源数据
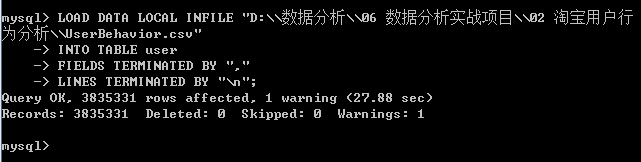
- 速度更快,导入3835331行数据,仅用27.88秒,但是相比于图形界面工具操作更复杂。
三、数据清洗
3.1 删除重复值
# 统计重复值
SELECT *
FROM userbehavior
GROUP BY user_id,item,category,time
HAVING count(user_id)>1;

从查询结果可知,数据中不存在重复记录。
3.2 查看缺失值
# 统计缺失值
SELECT count(user_id),count(item),count(category),count(behavior),count(time)
FROM userbehavior;

从查询结果来看,不存在缺失值,数据质量高。
3.3 时间格式转换
# 新增date、hour时间字段
ALTER TABLE userbehavior
ADD date VARCHAR(20),
ADD hour VARCHAR(20);
# 时间格式转换
UPDATE userbehavior SET date = FROM_UNIXTIME(time,"%Y-%m-%d");
UPDATE userbehavior SET hour = FROM_UNIXTIME(time,"%H");
UPDATE userbehavior SET time = FROM_UNIXTIME(time);

# 调整一下time字段数据的样式
UPDATE userbehavior SET time = SUBSTRING_INDEX(time,'.',1);

3.4 过滤异常值
由于数据集时间范围为2017-11-25至2017-12-3,因此需要对不在该时间范围内的异常数据进行过滤。
# 筛选异常数据
SELECT *
FROM userbehavior
WHERE date < '2017-11-25' or date > '2017-12-03';
# 过滤异常数据
DELETE FROM userbehavior
WHERE date < '2017-11-25' or date > '2017-12-03';
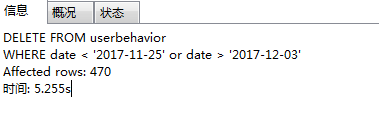
总共过滤掉470条异常记录。
四、数据分析
- 分析框架

4.1 基于用户行为转化漏斗模型分析用户行为
4.1.1 常见电商指标分析
4.1.1.1 UV、PV、UV/PV
# UV、PV、UV/PV指标统计
SELECT count(DISTINCT user_id) as UV,
sum(case when behavior='pv' then 1 else 0 end) as PV,
sum(case when behavior='buy' then 1 else 0 end) as Buy,
sum(case when behavior='cart' then 1 else 0 end) as Cart,
sum(case when behavior='fav' then 1 else 0 end) as Fav,
sum(case when behavior='pv' then 1 else 0 end)/count(DISTINCT user_id) as 'PV/UV'
FROM userbehavior;

访问用户总数(UV):9739
页面总访问量(PV):895636
9天时间内平均每人页面访问量(UV/PV):约为92次
- tips:该段SQL代码的功能类似于pandas中get_dummies()函数,构建独热编码,再利用count()函数进行字段的求和。
4.1.1.2 复购率
- 复购率定义:在某时间窗口内重复消费用户(消费两次及以上的用户)在总消费用户中占比(按天非去重)。复购率与回购率的区别
# 复购率
SELECT
sum(case when buy_amount>1 then 1 else 0 end) as "复购总人数",
count(user_id) as "购买总人数",
sum(case when buy_amount>1 then 1 else 0 end)/count(user_id) as "复购率"
FROM
(SELECT *,count(behavior) as buy_amount
FROM userbehavior
WHERE behavior = 'buy'
GROUP BY user_id) a;
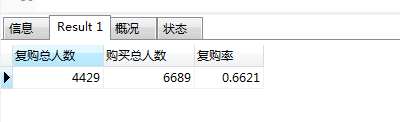
从结果来看,复购率高达66.21%,反映淘宝的用户忠诚度较高。
4.1.1.3 跳失率
- 跳失率定义:仅仅访问了单个页面的用户占全部访问用户的百分比,或者指从首页离开网站的用户占所有访问用户的百分比。
- 跳出率可以反映用户对APP\网站内容的认可程度,或者说网站\APP是否对用户有吸引力。网站\APP的内容是否能够对用户有所帮助留住用户也直接可以在跳出率中看出来,所以跳出率是衡量网站\APP内容质量的重要标准。
# 跳出率
SELECT count(*) as "仅访问一次页面的用户数"
FROM
(SELECT user_id
FROM userbehavior
GROUP BY user_id
HAVING count(behavior)=1) a
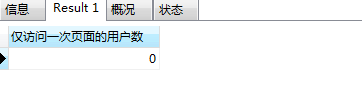
统计结果表明,9天时间内,没有一名用户仅浏览一次页面就离开淘宝,跳失率为0。反映出商品或者商品详情页的内容对于用户具有足够的吸引力,让用户在淘宝驻留。
4.1.2 用户行为转化漏斗模型分析
漏斗分析模型已经广泛应用于各行业的数据分析工作中,用以评估总体转化率、各个环节的转化率,以科学评估促销专题活动效果等,通过与其他数据分析模型结合进行深度用户行为分析,从而找到用户流失的原因,以提升用户量、活跃度、留存率,并提升数据分析与决策的科学性等。
# 电商行业转化率算法
利润=销售额X净利润率
=(购买人数X客单价)X净利润率
=进店人数X购买转化率X客单价X净利润率
=广告展现X广告转化率X购买转化率X客单价X净利润率
=推广展现X推广转化率X购买转化率X客单价X净利润率
=搜索展现X搜索转化率X购买转化率X客单价X净利润率
=*****X*****转化率X购买转化率X客单价X净利润率
- 常用漏斗模型:首页—商品详情页—加入购物车—提交订单—支付订单
- 本数据集只包含商品详情页(pv)、加入购物车(cart)、支付订单(buy)数据,因此将漏斗模型简化为:商品详情页—加入购物车—支付订单。
用户总行为(PV)的转化漏斗
# 用户总行为漏斗
SELECT behavior,COUNT(*)
FROM userbehavior
GROUP BY behavior
order by behavior desc;
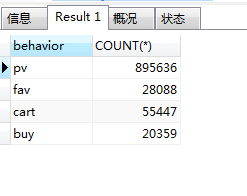
用户总行为转化漏斗图:

独立访客(UV)的转化漏斗
# 独立访客转化漏斗
SELECT behavior,count(DISTINCT user_id)
FROM userbehavior
GROUP BY behavior
ORDER BY behavior DESC;

综合用户总行为转化漏斗图与独立访客转化漏斗图,可以发现:
- (1)从浏览商品详情页PV到有购买意向只有6.19%的转化率,但从浏览商品详情页UV到有购买意向有75.46%的转化率,说明用户在购买商品前会大量的去点击浏览商品详情页(pv/buy=895636/20359=44次)进行对比筛选,这一环节是指标提升的重点环节,尽量做到精准推荐,减少用户寻找信息的成本。
- (2)支付订单用户数占浏览商品详情页用户数的68.92%,反映淘宝APP用户购买转化率较高,即淘宝APP上的商品能满足绝大部分用户的购买需求。
针对上述环节改善转化率的建议:
- (1)优化电商平台的搜索匹配度和推荐策略,主动根据用户喜好推荐相关的商品,优化商品搜索的准确度和聚合能力,对搜索结果排序优先级进行优化。
- (2)在商品详情页的展示上突出用户关注的重点信息,精简信息流的呈现方式,减少用户寻找信息的成本。
题外话:大家在使用淘宝购物时,有没有过被店铺利用优惠券引导收藏加购的经历呢?为什么店铺愿意花一定的代价去做这件事?原因就是淘宝收藏加购的好处意义是直接提升宝贝权重排名,人气权重这个维度在搜索排序维度中权重占比有很大提升。淘宝收藏加购多了,会增加淘宝店铺权重,从而提升宝贝排名,流量自然也就多了。
4.2 从时间维度分析用户行为
4.2.1 每天的用户行为分析
# 每天的用户行为分析
SELECT
date,
count(DISTINCT user_id) as '每日用户数',
sum(case when behavior='pv' then 1 else 0 end) as '浏览数',
sum(case when behavior='cart' then 1 else 0 end) as '加购数',
sum(case when behavior='fav' then 1 else 0 end) as '收藏数',
sum(case when behavior='buy' then 1 else 0 end) as '购买数'
FROM userbehavior
GROUP BY date;

每日用户行为数据变化:

在2017年11月25日-2017年12月3日统计窗口内,11月25-26日与12月2-3日为周末。
通过每日用户行为数据变化曲线可以分析:11月25日至12月1日,数据波动变化范围很小,在12月2-3日(周末),各项数据指标明显上涨,高于前7天的各项数据指标。由于在上一个周末(11月25-26日)的各项数据指标并未存在明显涨幅,因此推测在12月2-3日数据指标上涨可能与淘宝双12预热活动相关。
4.2.2 每时的用户行为分析
# 每时的用户行为分析
SELECT
hour,
count(DISTINCT user_id) as '每时用户数',
sum(case when behavior='pv' then 1 else 0 end) as '浏览数',
sum(case when behavior='cart' then 1 else 0 end) as '加购数',
sum(case when behavior='fav' then 1 else 0 end) as '收藏数',
sum(case when behavior='buy' then 1 else 0 end) as '购买数'
FROM userbehavior
GROUP BY hour;

每时用户行为数据变化:

结果显示:在凌晨2-5点左右,各项数据指标进入低谷期;在9-18点之间,数据呈现一个小高峰,波动变化较小;在20-23点间,各数据指标呈现一个大高峰,并且在21点左右达到每日数据最大峰值,数据的变化趋势比较符合正常用户的作息规律。在制定运营策略时,可以利用这个规律来进行创收,选择在每天用户最活跃的时间段推出各种网店直播、直播带货等互动营销手段。
4.3 从商品维度分析用户行为
关于“受欢迎”的商品,可以从销量与浏览量两个维度(用户行为)去分析。但有的浏览量高的商品可能是因为被页面或广告等吸引而来,或者只是感兴趣,用户并不一定会购买;而销量高的产品有可能是用户真正需要的,搜索和点击购买的目标也比较明确。因此需要同时结合销量与浏览量两个维度去进行分析。
4.3.1 商品排行榜分析
4.3.1.1 商品销量排行榜前10
# 商品销量排行榜前10
SELECT item, count(behavior) as '购买次数'
FROM userbehavior
WHERE behavior='buy'
GROUP BY item
ORDER BY count(behavior) DESC
limit 10;
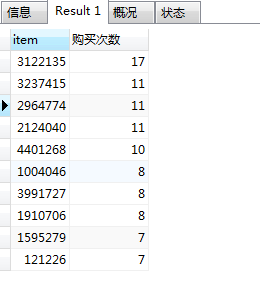
从商品销量排行榜可以发现,在被下单的17565件商品中,单个商品销量最多不超过17次,且仅有5件商品销量超过10次,反映出在分析的数据集中,并没有出现卖的比较火爆的商品。
4.3.1.2 商品浏览量排行榜前10
# 商品浏览量排行榜前10
SELECT item, count(behavior) as '浏览次数'
FROM userbehavior
WHERE behavior='pv'
GROUP BY item
ORDER BY count(behavior) DESC
limit 10;
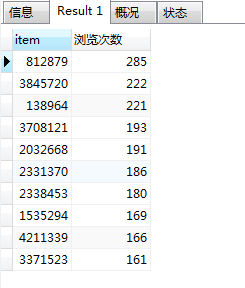
对销量前10与浏览量前10的商品进行表连接:
# 商品销量榜单与浏览量榜单表连接
SELECT a.item,a.`购买次数`,b.`浏览次数`
FROM
(SELECT item, count(behavior) as '购买次数'
FROM userbehavior
WHERE behavior='buy'
GROUP BY item
ORDER BY count(behavior) DESC
LIMIT 10) a
LEFT JOIN
(SELECT item, count(behavior) as '浏览次数'
FROM userbehavior
WHERE behavior='pv'
GROUP BY item
ORDER BY count(behavior) DESC
limit 10) b on a.item=b.item;
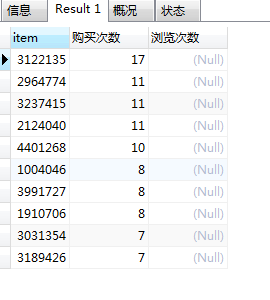
结果显示:商品销量榜单与商品浏览量榜单之间对应性差(仅有2件商品销量与浏览量同时进入前20榜单),反映浏览量高的商品其销量不一定高,销量高的商品其浏览量不一定高,因此需要同时结合销量与浏览量两个维度去进行分析。下面将以商品浏览量和销量两个维度指标来对商品进行四象限划分,分析不同类型商品对应的用户行为,并提出相应的改进措施。
4.3.2 商品四象限划分
商品销量与浏览量两个维度的界限值分别选取3、20(需要根据实际业务场景来确定界限值),将商品按照销量与浏览量划分为四个象限:

第Ⅰ象限: 商品浏览量与销量都高,说明商品购买转化率高,属于受用户欢迎的商品。
- 改进措施:由于该象限内的商品有对应的市场,电商平台应该重点进行推送,并且可以多做活动,吸引更多的潜在用户。
第Ⅱ象限: 商品的销量高,但是浏览量较低。产生这种现象可能有以下两种原因(B端与C端两个角度):一是 该象限内的商品可能属于某类特定群体的刚需产品,这类特定群体搜索和浏览的目标比较明确;二是 该象限内的商品受众广,但是引流入口数量少。
- 改进措施:收集目前购买与浏览该象限内商品的用户信息,分析用户画像,并结合商品的特点,核实产品是否存在某类特征明显的消费群体。如果存在,则电商平台可以集中向该类特征消费用户进行定向推送、精准推送;如果不存在,则可以对该象限内商品的多做推广,提高曝光率,并增加引流入口,流量上来了,销量可能会有提升。
第Ⅲ象限: 商品的浏览量低,销量也低。原因主要需要从B端进行分析:一是 该象限内商品的引流入口数量;二是 该象限内商品是否符合用户的需求?对用户的吸引力如何?
第Ⅳ象限: 商品的浏览量高,但是销量偏低,商品购买转化率低。其原因也可以分为B/C端进行分析:在B端方面,是否是广告的投放人群或者商品的推送目标有问题,并没有获取到对应商品的目标用户;是否是商品的定价与定位的原因,价格太贵且不符合主流消费群体的胃口;是否是商品详情页的图片、描述以及商品的评价较差;是否是客服的服务不到位、APP操作更新流程复杂等因素。在C端方面,用户的消费能力可能会对商品的销量有影响。
4.3.4 “二八定律”or“长尾理论”分析
知识点:
按照商品销量对商品分类统计:
# 按照商品销量对商品进行分类统计
SELECT a.`购买次数`, count(a.item) as '商品量'
FROM
(SELECT item, count(behavior) as '购买次数'
FROM userbehavior
WHERE behavior='buy'
GROUP BY item
ORDER BY count(behavior) DESC) a
GROUP BY a.`购买次数`
ORDER BY count(a.item) DESC;
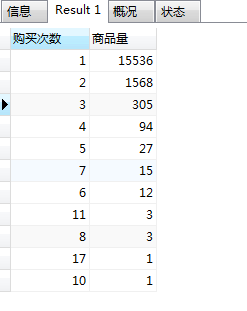
绘制不同销量对应商品量柱状图:

根据不同销量对应商品量数据,在被下单的17565件商品中,只购买一次的商品有15536件,占下单总商品的88.45%,说明在互联网环境下,以淘宝为代表的电商平台,其商品售卖主要是依靠长尾商品的累计效应,并非爆款商品的带动。
4.4 基于RFM用户分层模型分析用户行为
4.4.1 基于RFM模型的用户分层
基于RFM模型进行用户分层分析,由于数据集中不包含订单金额,故本次分析中不考虑M维度,只分析R、F两个维度,对两个维度的指标进行分级打分,最终按照综合得分对用户分层。
4.4.1.1 R维度分析
计算用户的最近消费时间间隔R值(R值越小,说明用户最后消费时间越近),并对R值进行打分。根据R值结果,将其分为三个区间[0:2],[3:5]以及[6:8],分别赋予R_Score值3、2、1分。
# RFM模型——R维度分析
CREATE VIEW r_value as
SELECT user_id, min(时间间隔) as R
FROM
(SELECT user_id, DATEDIFF('2017-12-03',date) as '时间间隔'
FROM userbehavior
WHERE behavior='buy') a
GROUP BY user_id;
# 进行R维度打分
SELECT user_id, R,
case when R BETWEEN 0 and 2 then 3
when R BETWEEN 3 and 5 then 2
else 1 end as R_Score
FROM r_value
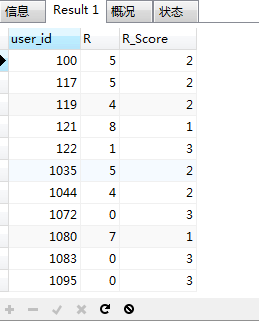
统计不同R_Score占比:

从R_Score占比中可以发现,超过半数用户会在购物当天的后两天内就再次购买,可以看出淘宝已经成为人们的日常购物习惯。
4.4.1.2 F 维度分析
计算用户的消费频率F值,并对F值进行打分。根据F值结果(最大值72次),将其分为6个区间[1:9],[10:19],[20:29],[30:39],[40:49]以及[50:72],分别赋予F_Score值1、2、3、4、5、6分。
# RFM模型——F维度分析
CREATE VIEW f_value as
SELECT user_id, count(behavior) as F
FROM userbehavior
WHERE behavior='buy'
GROUP BY user_id
ORDER BY count(behavior) DESC;
# 进行F维度打分
SELECT user_id, F,
case when F BETWEEN 1 and 9 then 1
when F BETWEEN 10 and 19 then 2
when F BETWEEN 20 and 29 then 3
when F BETWEEN 30 and 39 then 4
when F BETWEEN 40 and 49 then 5
else 6 end as F_Score
FROM f_value
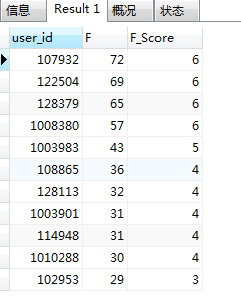
统计不同F_Score占比:

从R_Score占比中可以发现,在统计窗口的9天时间内,96.76%的用户在淘宝平台消费1-9次。
4.4.1.3 用户分层
RF综合打分:
# 进行R维度打分
CREATE VIEW r_score as
SELECT user_id, R,
case when R BETWEEN 0 and 2 then 3
when R BETWEEN 3 and 5 then 2
else 1 end as R_Score
FROM r_value
# 进行F维度打分
CREATE VIEW f_score as
SELECT user_id, F,
case when F BETWEEN 1 and 9 then 1
when F BETWEEN 10 and 19 then 2
when F BETWEEN 20 and 29 then 3
when F BETWEEN 30 and 39 then 4
when F BETWEEN 40 and 49 then 5
else 6 end as F_Score
FROM f_value
# RF综合打分
CREATE VIEW rf_score as
SELECT a.user_id, a.R_Score, b.F_Score, a.R_Score+b.F_Score as RF_Score
FROM r_score a JOIN f_score b on a.user_id=b.user_id

根据RF_Score值,对用户进行分层:划分为2-3分,4-5分,6-7分,8-9分四个等级,分别对应易流失用户、挽留用户、发展用户、忠诚用户。
# 用户分层
SELECT *,
case when RF_Score BETWEEN 2 and 3 then '易流失用户'
when RF_Score BETWEEN 4 and 5 then '挽留用户'
when RF_Score BETWEEN 6 and 7 then '发展用户'
else '忠诚用户' end as '用户分层'
FROM rf_score

统计不同类型用户占比:
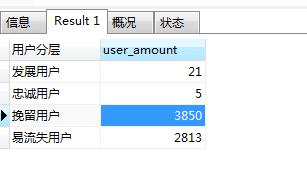

用户分层结果:
- 重点挽留用户的比例最高,而且这部分客户给平台带来的潜在价值也很大,应该对这部分用户进行定期上新提醒、价格激励、订单搭配推荐等措施,留住用户并提高其消费频次;
- 易流失用户占比也相对较高,这部分客户可能已经找到替代品或对该公司产品不感兴趣了,可采取价格激励、发放优惠券等方式进行流失召回;
- 忠诚用户占比最少,这部分用户属于平台的 高价值用户,需要制定相应的运营策略来保持用户粘性;
- 重点发展用户占比也较低,对这部分用户发送提醒或促销活动邮件、促进其消费频次。
用户分层效果分析: 从不同用户占比上来看,本次用户分层的效果不佳,可能有以下两个方面原因:1、两个维度的打分区间划分的不合理,并没有用户很好的分开,应该在做区间划分时提前看一下各维度的用户分布情况,结合实际业务场景需求,去确定区间界限值;2、两个维度划分的区间数不一致,且赋予的分值区间差异较大,这种操作其实相当于给两个维度赋予了不同的比重。
在本次用户分层中,可能采取RF两个维度的四象限划分更简单明了,且效果会更好。
4.4.2 高价值用户行为分析
以user_id为107932的用户为例,对其进行深入分析:
# user_id为107932用户行为分析
SELECT
date,
sum(case when behavior='pv' then 1 else 0 end) as '浏览数',
sum(case when behavior='cart' then 1 else 0 end) as '加购数',
sum(case when behavior='fav' then 1 else 0 end) as '收藏数',
sum(case when behavior='buy' then 1 else 0 end) as '购买数',
sum(case when behavior='buy' then 1 else 0 end)/sum(case when behavior='pv' then 1 else 0 end) as '购买转化率'
FROM userbehavior
WHERE user_id = 107932
GROUP BY date;


结果表明:该用户几乎每天都有消费,购买转化率也很高,但从未使用过收藏功能,购物车的使用频率也极低。对于高价值用户,可以分析其常购买的商品类型,再进行相关的商品推荐。由于商品种类数据为脱敏数据,本文无法分析该用户购买的商品类型。
五、结论与建议
本文从4个维度分析了淘宝用户行为数据共100万条,结论和建议如下:
- 1、淘宝平台的商品对用户具有足够的吸引力(跳失率),且能够满足绝大部分用户的需求(购买转化率)。淘宝用户的忠诚度较高,复购率高达66.21%。从浏览商品详情页PV到有购买意向仅有6.19%的转化率,这一环节是指标提升的重点环节,尽量做到精准推荐,减少用户寻找信息的成本。
针对上述环节改善转化率的建议:
(1)优化电商平台的搜索匹配度和推荐策略,主动根据用户喜好推荐相关的商品,优化商品搜索的准确度和聚合能力,对搜索结果排序优先级进行优化。
(2)在商品详情页的展示上突出用户关注的重点信息,精简信息流的呈现方式,减少用户寻找信息的成本。
- 2、用户的各种行为数据指标在周末和工作日的差别不大,但是受双12等大型平台活动影响较大。每天晚上的20-23点间是用户活跃度最高的时间段,各数据指标呈现一个大高峰,并且在21点左右达到每日数据最大峰值。在制定运营策略时,可以利用这个规律来进行创收,选择在每天用户最活跃的时间段推出各种网店直播、直播带货等互动营销手段。
- 3、商品销量与商品浏览量之间相关性较差,浏览量高的商品其销量不一定高,销量高的商品其浏览量不一定高,结合商品四象限划分结果,各象限商品都可从B端与C端两个角度去分析原因,并针对性的进行改善。
- 4、淘宝平台商品售卖主要是依靠长尾商品的累计效应,并非爆款商品的带动。
建议:长尾效应的确能带来一部分收益,但是,繁多的种类对于商家来说其实是一种经营负担,成本也较高。二八定律告诉我们,商家其实可以通过打造爆款商品来获利。打造爆款商品具体的建议是:品控上提高产品质量,宣传上增大力度(直播、微淘、引流到其他平台),展现上突出产品优势等(主图、详情页、评论)。
- 5、通过RFM模型对用户进行分层,找出RF评分高的作为高价值用户,并对不同类型的用户采取不用的运行策略。