前言:
本章内容:
-
学习CUDA内存模型
-
CUDA内存管理
-
全局内存编程
-
探索全局内存访问模式
-
研究全局内存数据布局
-
统一内存编程
-
最大限度地提高全局内存吞吐量
在上一章中,你已经了解了线程是如何在GPU中执行的,以及如何通过操作线程束来优化核函数性能。但是,核函数性能并不是只和线程束的执行有关。回忆一下第3章的内容,在3.3.2节中,把一个线程块最里面一层的维度设为线程束大小的一半,这导致内存负载效率的大幅下降。这种性能损失不能用线程束调度或并行性来解释,造成这种性能损失的真正原因是较差的全局内存访问模式。
在本章,我们将剖析核函数与全局内存的联系及其对性能的影响。本章将介绍CUDA内存模型,并通过分析不同的全局内存访问模式来教你如何通过核函数高效地利用全局内存。
4.1 CUDA内存模型概述:
内存的访问和管理是所有编程语言的重要部分。在现代加速器中,内存管理对高性能计算有着很大的影响。
因为多数工作负载被加载和存储数据的速度所限制,所以有大量低延迟、高带宽的内存对性能是十分有利的。然而,大容量、高性能的内存造价高且不容易生产。因此,在现有的硬件存储子系统下,必须依靠内存模型获得最佳的延迟和带宽。CUDA内存模型结合了主机和设备的内存系统,展现了完整的内存层次结构,使你能显式地控制数据布局以优化性能。
内存层次结构的优点:
这里讲的就是计组 & 操作系统里的存储器体系结构
没啥好说的, 直接当复习计组吧
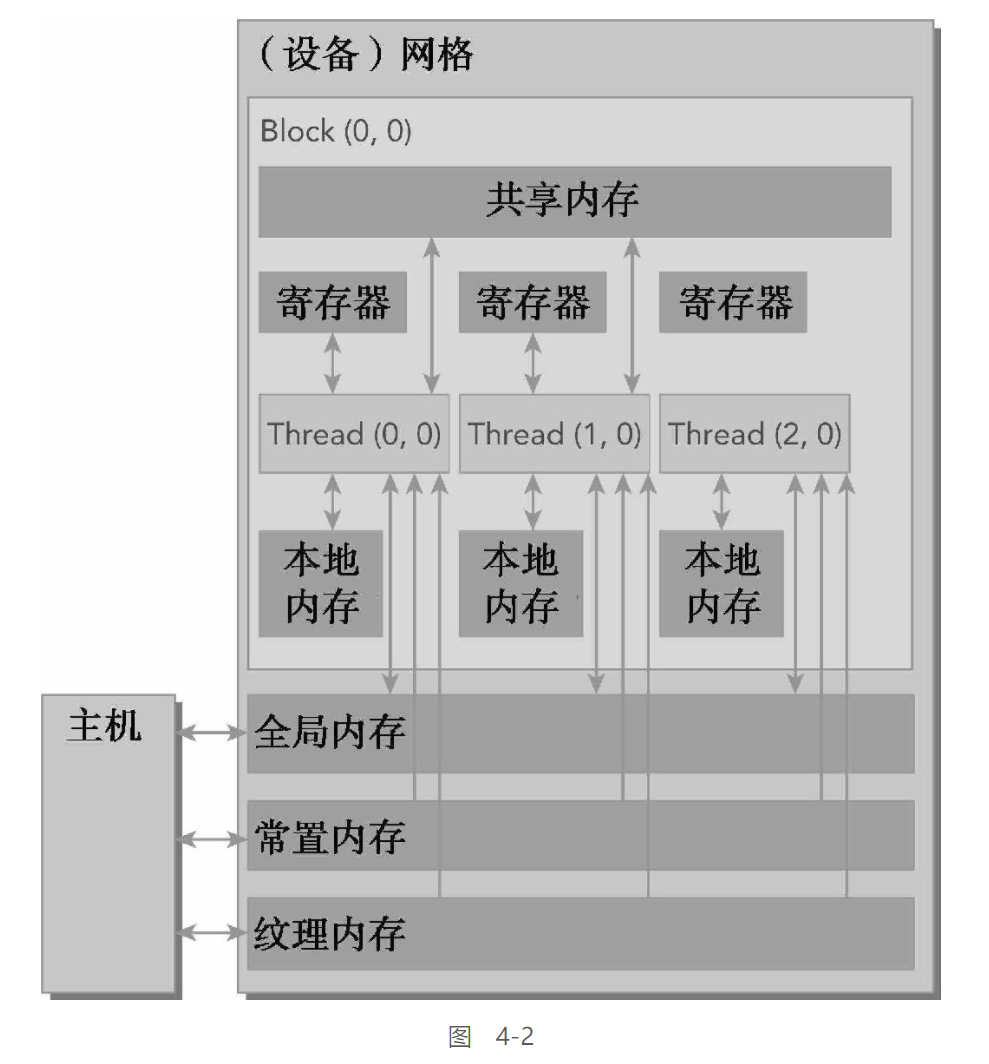
CUDA内存模型:
对于程序员而言, 有两种类型的存储器:
- 可编程的:
你需要显式地控制哪些数据存放在可编程内存中
- 不可编程的:
你不能决定数据的存放位置,程序将自动生成存放位置以获得良好的性能
在内存层次结构中, 一级缓存 & 二级缓存都是不可编程的存储器
对于CUDA内存模型, 则有多种可编程内存的类型:
-
寄存器
-
共享内存
-
本地内存
-
常量内存
-
纹理内存
-
全局内存
每种都有不同的作用域, 生命周期 & 缓存行为
-
一个核函数中的线程都有自己私有的本地内存
-
一个线程块有自己的共享内存,对同一线程块中所有线程都可见,其内容持续线程块的整个生命周期
-
所有线程都可以访问全局内存
-
所有线程都能访问的只读内存空间有:常量内存空间和纹理内存空间
-
全局内存、常量内存和纹理内存空间有不同的用途
-
纹理内存为各种数据布局提供了不同的寻址模式和滤波模式
-
对于一个应用程序来说,全局内存、常量内存和纹理内存中的内容具有相同的生命周期。
寄存器:
与CPU相同, 寄存器是存储体系中速度最快的内存
作为GPU中的稀缺资源, 寄存器同样限制了SM上常驻线程块的数量, 线程占用的寄存器数量越少, SM上的并发线程块就越多
- Fermi架构中, 每个线程最多拥有63个寄存器
- Kepler架构中, 提升至255个
查看核函数使用的寄存器&共享内存资源:
nvcc -arch=sm_61 -Xptxas -v .\cuda_test.cu -o .\cuda_test.exe

帮助编译器优化寄存器使用:
在核函数前添加点东西:
__global__ void
__launch_bounds__(maxThreadsPerBlock, minBlocksPerMultiprocessor)
kernel(args){
...
}
- maxThreadsPerBlock
每个线程块可以包含的最大线程数
- minBlocksPerMultiprocessor
可选参数, 每个SM中预期最小的常驻线程块数量
本地内存:
之前说到SM中寄存器的数量是有限的, 无法装进寄存器的变量会溢出到本地内存中
可能存放到本地内存中的变量有:
- 在编译时使用未知索引引用的本地数组
- 可能会占用大量寄存器空间的较大本地结构体或数组
- 任何不满足核函数寄存器限定条件的变量
注意, 这里的本地内存的物理存储位置实际上和全局内存是在同一块的
共享内存:
共享内存是片上内存(集成在GPU内部), 类似于CPU的一缓, 但他是可编程的, 与全局内存或本地内存相比有更高的带宽&更低的延时
每个SM都有有限的共享内存, 所以其也成为限制SM上活跃线程数量的一大因素
使用__shared__声明要放在共享内存中的变量, 其生命周期伴随整个线程块
这里可以看到三种架构中每个SM共享内存的容量
并且对于Fermi & Kepler 架构, 其共享内存与一级缓存是在一起的:



通常共享内存&一级缓存是静态分配的, 但在运行时可以手动指定:

常量内存:
-
常量内存驻留在设备内存中,并在每个SM专用的常量缓存中缓存
-
常量使用__constant__来修饰
-
常量必须在全局空间内核所有核函数之外声明
即不能声明在核函数之内, 通常声明的位置与C++全局变量相同, 然后使用cudaMemcpyToSymbol(而不是cudaMemcpy)把数据从主机拷贝到设备GPU中

这个函数将count个字节从src指向的内存复制到symbol指向的内存中,这个变量存放在设备的全局内存或常量内存中。在大多数情况下这个函数是同步的
具体的代码操作在后头的例子中会详细介绍
-
常量内存是静态声明的,并对同一编译单元中的所有核函数可见
-
每从一个常量内存中读取一次数据,都会广播给线程束里的所有线程
所以对于常量(如数学系数), 使用__constant__储存是再好不过的选择
纹理内存:
纹理内存这部分还是挺多的, 这里仅作了解, 详细的直接看这篇博客:
https://blog.csdn.net/zhangfuliang123/article/details/76571498
- 纹理内存驻留在设备内存中,并在每个SM的只读缓存中缓存
- 纹理内存是一种通过指定的只读缓存访问的全局内存
只读缓存包括硬件滤波的支持,它可以将浮点插入作为读过程的一部分来执行
- 纹理内存是对二维空间局部性的优化,所以线程束里使用纹理内存访问二维数据的线程可以达到最优性能
- 对于一些应用程序来说,这是理想的内存,并由于缓存和滤波硬件的支持所以有较好的性能优势
然而对于另一些应用程序来说,与全局内存相比,使用纹理内存更慢。
全局内存:
全局内存即显存 global memory, 是GPU中最大, 延时最高, 最常使用的内存
其作用域与生命周期即global: 能被所有SM访问, 并贯穿整个程序的生命周期
全局内存的访问涉及到一个对齐问题(类似MPI中的内存对齐)
其支持32字节、64字节或128字节的内存访问事务, 也就是说,首地址必须是32字节、64字节或128字节的倍数
当一个线程束执行内存LD/ST时,需要满足的传输数量通常取决于以下两个因素:
接下来的部分将研究如何优化全局内存访问,以及如何最大程度地提高全局内存的数据吞吐率
GPU缓存:
跟CPU缓存一样,GPU缓存是不可编程的内存。在GPU上有4种缓存:
在CPU上,内存的加载和存储都可以被缓存。但是,在GPU上只有内存加载操作可以被缓存,内存存储操作不能被缓存
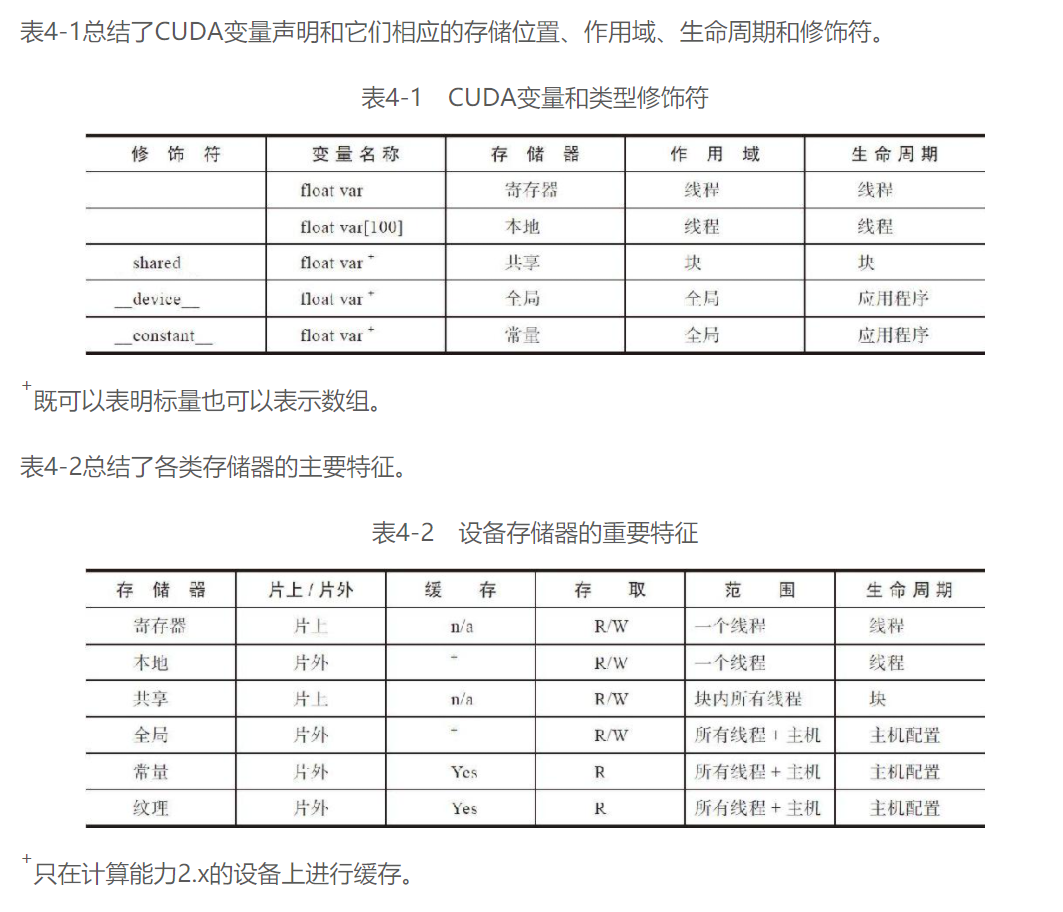
CUDA变量声明总结:
静态全局内存:
下面的代码说明了如何静态声明一个全局变量
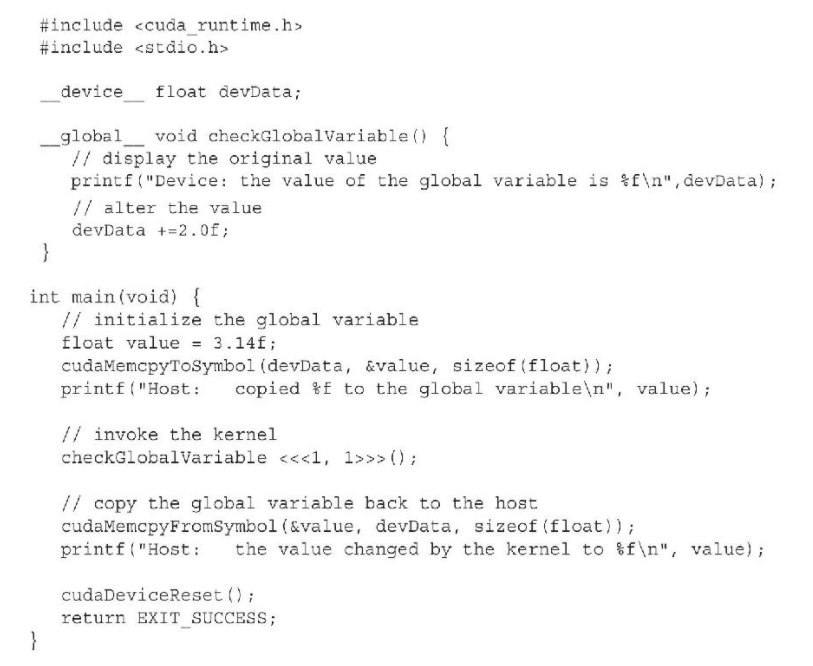
- 首先, 是在文件作用域中用
__device__声明一个全局变量
- 而后在main主机代码中, 使用
cudaMemcpyFromSymbol()初始化到设备中
- 执行完核函数之后, 全局变量被修改, 在使用
cudaMemcpyFromSymbol()传回主机内存中
输出:

主机代码是没法直接访问设备变量的, 即便他们都在同一个文件作用域中被声明,
其有如下几点限制:
-
在主机端中用于声明设备全局变量的符号DevData是无法用在cudaMemcpy设备&主机之间拷贝数据的
想要传递数据需要获取一个实际地址
但是也无法使用&devData来获取地址, 只能使用
由此, 便可以传递数据了:

-
可以使用cudaMemcpyToSymbol()获取设备中的静态全局变量
总之就是记着, 主机和设备想要访问对方的数据, 最好是通过API来执行
4.2 内存管理:
CUDA编程的内存管理与C语言的类似,需要程序员显式地管理主机和设备之间的数据移动。随着CUDA版本的升级,NVIDIA正系统地实现主机和设备内存空间的统一(Pascal架构实现了统一内存的技术),但对于大多数应用程序来说,仍需要手动移动数据。这一领域中的最新进展将在本章的4.2.6节中进行介绍。现在,工作重点在于如何使用CUDA函数来显式地管理内存和数据移动。
为了达到最优性能,CUDA提供了在主机端准备设备内存的函数,并且显式地向设备传输数据和从设备中获取数据
内存分配和释放
在前头的章节中已经讲过了设备上的内存分配&释放
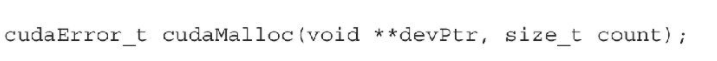

这里在介绍一个内存操作函数:
cudaError_t cudaMemset(void * devPtr, int value, size_t count)
这个函数用存储在变量value中的值来填充从设备内存地址devPtr处开始的count字节
内存传输:
前头的章节也讲到了内存传输函数cudaMemcpy(), 这里也没涉及啥多的内容
固定内存
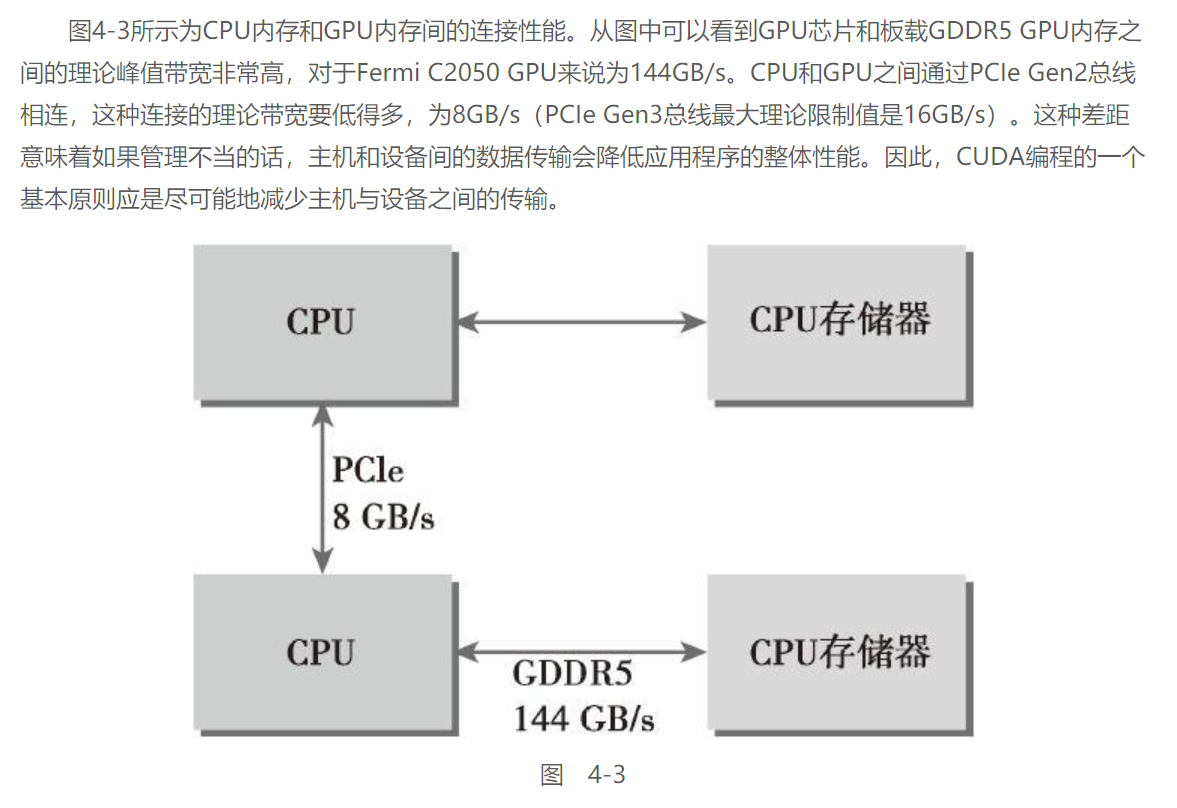
介绍固定内存之前首先要了解一下设备内存 & 主机内存之前的传输:
主机内存通常都是可分页式的, 具有一定的虚拟内存
而GPU不能在可分页的主机内存上安全的访问数据, 因为当主机操作系统在物理位置上移动该数据时, 设备无法控制
所以, 当从可分页内存中传输数据到设备内存时, CUDA首先分配临时的页面锁定或固定的主机内存(这类内存称之为固定内存), 先将数据复制到固定内存中, 在传输到设备内存中, 如下如所示:
分配固定内存:
__host__ cudaError_t CUDARTAPI cudaMallocHost(void ** ptr, size_t size)
这个函数分配了count字节的主机内存,这些内存是页面锁定的并且对设备来说是可访问的
由于固定内存能被设备直接访问,所以它能用比可分页内存高得多的带宽进行读写
但是过多的分配主机内存会导致主机性能下降(就是导致主机内存不足)
同样, 分配的固定内存需要使用特定的函数释放:
__host__ cudaError_t CUDARTAPI cudaFreeHost(void * ptr)
此时如果还使用free()释放, 程序将崩溃
可以使用nvprof检测固定内存的性能提升:

固定内存的分配&释放的代价成本更高, 但其提升了大规模数据传输时的吞吐量
通常, 当传输数据量>=10M时, 使用固定内存是更好的选择
零拷贝内存:
之前说到了设备和主机不能直接访问对方的变量, 但在零拷贝内存中, 主机和设备都可以访问(均可见), 其实现的原理是将host内存直接映射到设备内存空间上, 使得设备能通过DMA方式来访问host的锁定页面内存
CUDA核函数中使用零拷贝内存有以下优势:
-
当设备内存不足时可利用主机内存
-
避免主机和设备间的显式数据传输
-
提高PCIe传输率
同样的, 使用零拷贝内存需要同步主机&设备间的内存访问
分配零拷贝内存:
__inline__ __host__ cudaError_t cudaHostAlloc(T ** ptr, size_t size, unsigned int flags)
这个函数分配了count字节的主机内存,该内存是页面锁定的且设备可访问的
用这个函数分配的内存必须用cudaFreeHost函数释放
flags参数:
-
cudaHostAllocDefault
使cudaHostAlloc函数的行为与cudaMallocHost函数一致
-
cudaHostAllocPortable
设置cudaHostAllocPortable参数可以返回能被所有CUDA上下文使用的固定内存,而不仅是执行内存分配的那一个
-
cudaHostAllocWriteCombined
cudaHostAllocWriteCombined参数返回写聚合内存,该内存可以在某些系统配置上通过PCIe总线上更快地传输,但是它在大多数主机上不能被有效地读取
写聚合内存(write-combine), 这里就是感觉翻译的有问题
其是通过缓存技术将多次写操作合并, 但实际上性能会比普通的write-back更糟糕, 主要是由于其没有使用cache, 而是直接写回内存
-
cudaHostAllocMapped
将申请映射回设备空间(Map allocation into device space)
__host__ cudaError_t cudaHostRegister ( void* ptr, size_t size, unsigned int flags )
cudaHostRegister() 函数用于把已经的存在的可分页内存注册为分页锁定的
flag参数:
-
cudaHostRegisterDefault
Default host memory registration flag
-
cudaHostRegisterIoMemory
Memory-mapped I/O space
-
cudaHostRegisterMapped
Map registered memory into device space
-
cudaHostRegisterPortable
Pinned memory accessible by all CUDA contexts
Mapped Memory:
一块锁页内存可以在调用cudaHostAlloc() 分配时传入cudaHostAllocMapped 标签或者在使用cudaHostRegister() 注册时使用cudaHostRegisterMapped 标签,把锁页内存地址映射到设备地址空间
这样, 这块内存就会存在有两个内存指针(两个内存地址):
第一个通过上头两个函数即可获得, 第二个需要使用额外的函数
这部分可以用后头的 统一虚拟寻址 & 统一内存寻址 来替代
__inline__ __host__ cudaError_t cudaHostGetDevicePointer(T ** pDevice, void * pHost, unsigned int flags)
该函数返回了一个在pDevice中的设备指针,该指针可以在设备上被引用以访问映射得到的固定主机内存
如果设备不支持映射得到的固定内存,该函数将失效
flag参数:
在进行频繁的读写操作时,使用零拷贝内存作为设备内存的补充将**显著降低性能**
因为每次内存读取都将经过PCIe总线, 去访问更慢的主机内存
通过书中的样例测试可以明显看到两者的性能差异:


使用nvprof查看结果:

对于不同的数据量:
-
使用Tesla M2090运行并使能一级缓存。
-
减度比=读取零拷贝内存的运行时间/读取设备内存的运行时间。
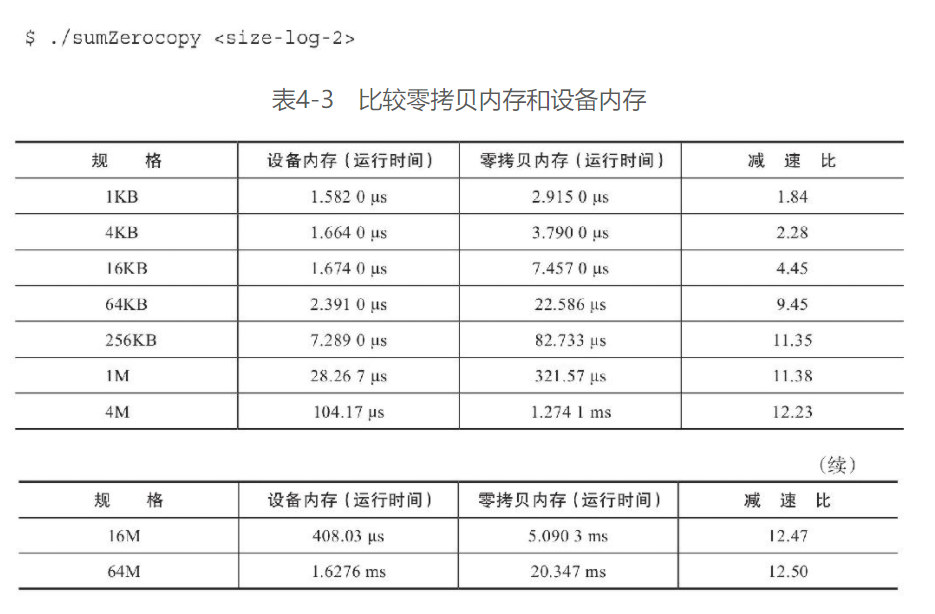
所以, 零拷贝内存推荐用在共享主机端 & 设备端的少量数据
其简化了编程并且能保持较好的性能(上图中小数据量的减速比相对较低), 但对于大数据而言, 将会造成严重的性能下降
统一虚拟寻址:
计算能力为2.0及以上版本的设备支持一种特殊的寻址方式,称为统一虚拟寻址(UVA)。UVA,在CUDA 4.0中被引入,支持64位Linux系统。有了UVA,主机内存和设备内存可以共享同一个虚拟地址空间,如图4-5所示。
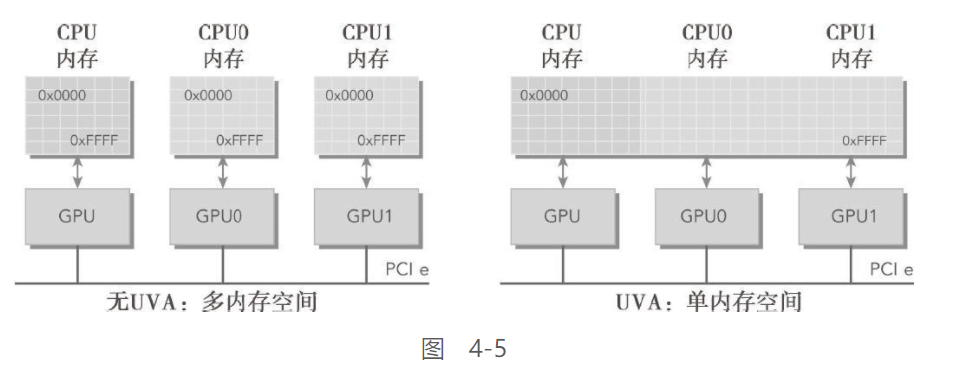
有了UVA,由指针指向的内存空间对应用程序代码来说是透明的。
上头讲的申请固定内存时, 需要:
有了UVA,由cudaHostAlloc分配的固定主机内存具有相同的主机和设备指针。因此,可以将返回的指针直接传递给核函数
这样就可以简化上头的例子了:

能够获得和上头一样的性能
统一内存寻址:
这部分直接看书
书里讲的其实还是很泛, 需要的时候直接百度+Google吧

4.3 内存访问模式:
大多数设备端数据访问都是从全局内存开始的,并且多数GPU应用程序容易受内存带宽的限制。因此,最大限度地利用全局内存带宽是调控核函数性能的基本。如果不能正确地调控全局内存的使用,其他优化方案很可能也收效甚微
为了在读写数据时达到最佳的性能,内存访问操作必须满足一定的条件。CUDA执行模型的显著特征之一就是指令必须以线程束为单位进行发布和执行。存储操作也是同样。在执行内存指令时,线程束中的每个线程都提供了一个正在加载或存储的内存地址。在线程束的32个线程中,每个线程都提出了一个包含请求地址的单一内存访问请求,它并由一个或多个设备内存传输提供服务。根据线程束中内存地址的分布,内存访问可以被分成不同的模式。在本节中,你将学习到不同的内存访问模式,并学习如何实现最佳的全局内存访问
对齐与合并内存:
首先需要了解一下CUDA内存访问的特点:

读取全局内存(DRAM)需要通过缓存层(二缓, 许多访问也会通过一缓,. 这取决于GPU的架构):
- 如果用到了一缓 & 二缓, 则内存访问是有一个128字节的内存事务实现的
- 如果仅适用了二缓, 则内存访问是由一个32字节的内存事务实现的
在编译时可以手动启用/禁用一缓
在Fermi架构的设备上, 默认启用L1缓存
但是在之后的架构上默认都是不启动L1缓存的, 如果要使用,使用编译指令:-Xptxas -dlcm=ca. 禁用. 或使用-Xptxas -dlcm=cg
一行一级缓存是128个字节,它映射到设备内存中一个128字节的对齐段。如果线程束中的每个线程请求一个4字节的值,那么每次请求就会获取128字节的数据,这恰好与缓存行和设备内存段的大小相契合
因此在优化应用程序时,需要注意设备内存访问的两个特性:
-
对齐内存访问
当内存事务的访问地址是缓存粒度的偶数倍时(32字节的二缓 & 128字节的一缓), 此时为对齐内存访问
运行非对齐的加载会导致带宽的浪费
-
合并内存访问
当一个线程束中全部的32个线程访问一个连续的内存块时, 就会出现合并内存访问
最理想的状况是: 线程束从对齐内存地址开始访问一个连续的内存块
图4-7描述了对齐与合并内存的加载操作
在这种情况下,从设备内存中读取数据只需要一个128字节的内存事务

图4-8展示了非对齐和未合并的内存访问
在这种情况下,从设备内存中读取数据可能需要3个128字节的内存事务:
- 一个在偏移量为0的地方开始,读取连续地址之后的数据
- 一个在偏移量为256的地方开始,读取连续地址之前的数据
- 另一个在偏移量为128的地方开始读取大量的数据
这样就造成了带宽浪费
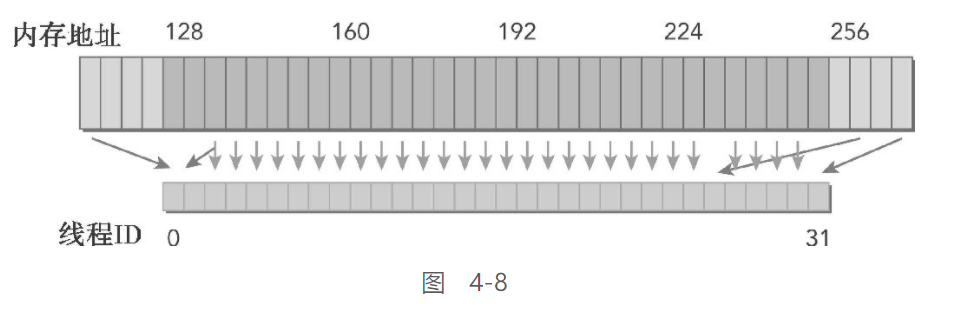
内存优化的目标在于:
通过更少的”内存事务“获得更多的内存请求,因此需要尽量进行对齐合并访问
全局内存读取:
在SM中,数据通过以下3种缓存/缓冲路径进行传输,具体使用何种方式取决于引用了哪种类型的设备内存:
启用 & 禁用一缓:
Fermi架构的设备之后, 就能够启用/禁用一缓
使用编译指令:-Xptxas -dlcm=ca. 禁用. 或使用-Xptxas -dlcm=cg
注意的是:
一缓 & 二缓的加载顺序, 如果启用一缓, 数据首先会尝试装入一缓中, 其次才是二缓, 最后才是DRAM
Fermi之后的架构中禁用一缓是因为, 一缓被专门用作缓存从寄存器中溢出的数据
内存加载访问模式:
内存加载可以分为两类:
-
缓存加载(启用一级缓存)
-
没有缓存的加载(禁用一级缓存)
内存加载的访问模式有如下特点:
-
有缓存与没有缓存:如果启用一级缓存,则内存加载被缓存
-
对齐与非对齐:如果内存访问的第一个地址是32字节的倍数,则对齐加载
-
合并与未合并:如果线程束访问一个连续的数据块,则加载合并
下一节中才会学习这些内存访问模式对核函数性能的影响
缓存加载:
这里是以一缓为例, 对于二缓是同样的道理
缓存的加载分为5种情况:
-
对齐 & 合并
线程束中所有线程请求的地址都在128字节的缓存行范围内。完成内存加载操作只需要一个128字节的事务。总线的使用率为100%,在这个事务中没有未使用的数据。
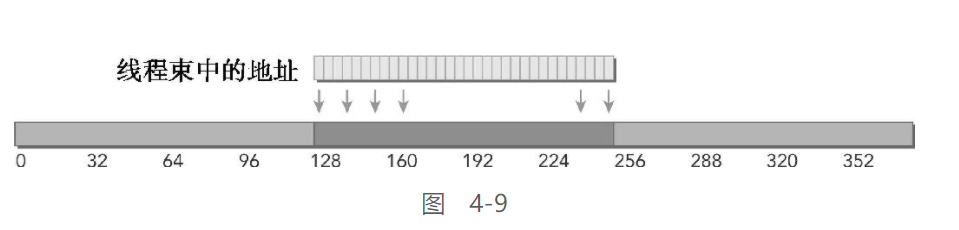
-
对齐 & 非合并:
图4-10所示为另一种情况:访问是对齐的,引用的地址不是连续的线程ID,而是128字节范围内的随机值。由于线程束中线程请求的地址仍然在一个缓存行范围内,所以只需要一个128字节的事务来完成这一内存加载操作。总线利用率仍然是100%,并且只有当每个线程请求在128字节范围内有4个不同的字节时,这个事务中才没有未使用的数据
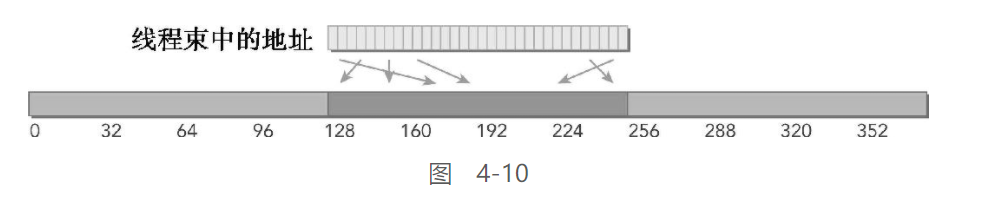
-
合并 & 非对齐:
图4-11也说明了一种情况:线程束请求32个连续4个字节的非对齐数据元素。在全局内存中线程束的线程请求的地址落在两个128字节段范围内。因为当启用一级缓存时,由SM执行的物理加载操作必须在128个字节的界线上对齐,所以要求有两个128字节的事务来执行这段内存加载操作。总线利用率为50%,并且在这两个事务中加载的字节有一半是未使用的

-
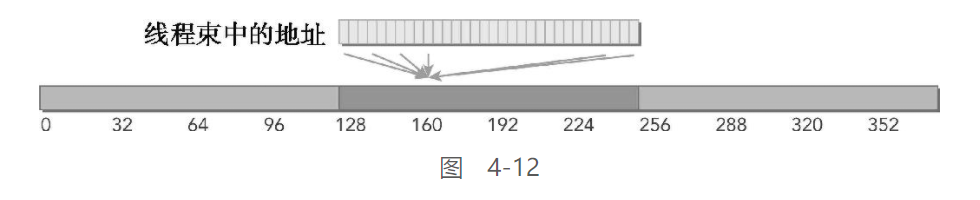
请求相同地址:
图4-12说明了一种情况:线程束中所有线程请求相同的地址。因为被引用的字节落在一个缓存行范围内,所以只需请求一个内存事务,但总线利用率非常低。如果加载的值是4字节的,则总线利用率是4字节请求/128字节加载=3.125%
-
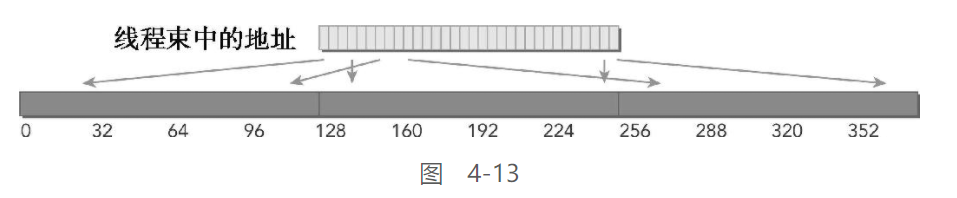
非合并 & 非对齐
这是最坏的情况, 线程束中线程请求分散于全局内存中的32个4字节地址。尽管线程束请求的字节总数仅为128个字节,但地址要占用N个缓存行(0<N≤32)。完成一次内存加载操作需要申请N次内存事务
CPU & GPU的一缓 & 二缓 の 区别:
CPU一级缓存优化了时间和空间局部性
GPU一级缓存是专为空间局部性而不是为时间局部性设计的
频繁访问一个一级缓存的内存位置不会增加数据留在缓存中的概率(并不相当于每次访问都要重新读取)
无缓存的加载:
这里的无缓存指的是不走L1 但是走L2
它在内存段的粒度上(32个字节)而非缓存池的粒度(128个字节)执行。这是更细粒度的加载,可以为非对齐或非合并的内存访问带来更好的总线利用率
还是以5种内存访问情况为例:
-
对齐 & 合并:
128个字节请求的地址占用了4个内存段,总线利用率为100%

-
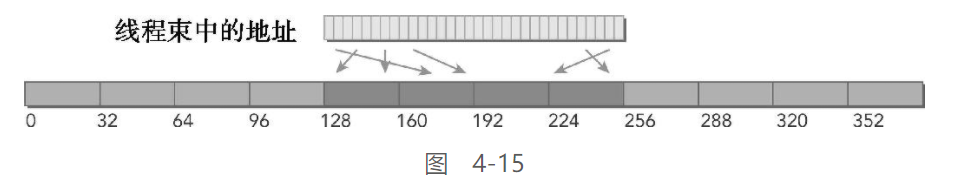
对齐 & 不合并
内存访问是对齐的且线程访问是不连续的,而是在128个字节的范围内随机进行。只要每个线程请求唯一的地址,那么地址将占用4个内存段,并且不会有加载浪费。这样的随机访问不会抑制内核性能
-
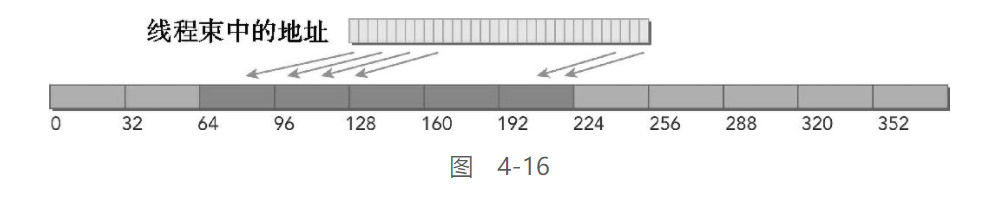
合并 & 不对齐
线程束请求32个连续的4字节元素但加载没有对齐到128个字节的边界。请求的地址最多落在5个内存段内,总线利用率至少为80%
与这些类型的请求缓存加载相比,使用非缓存加载会提升性能,这是因为加载了更少的未请求字节
-
访问统一数据
线程束中所有线程请求相同的数据. 地址落在一个内存段内
总线的利用率是请求的4字节/加载的32字节=12.5%
在这种情况下,非缓存加载性能也是优于缓存加载的性能
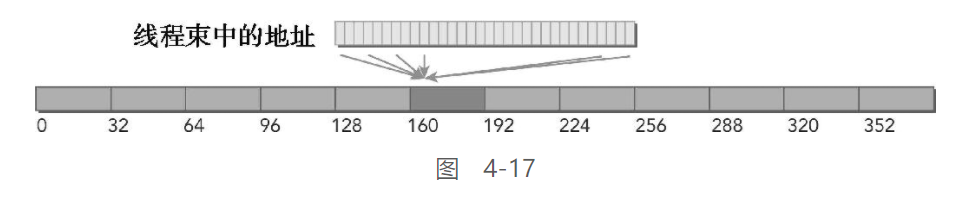
-
不合并 & 不对齐
图4-18说明了最坏的一种情况:线程束请求32个分散在全局内存中的4字节字。由于请求的128个字节最多落在N个32字节的内存分段内而不是N个128个字节的缓存行内,所以相比于缓存加载,即便是最坏的情况也有所改善
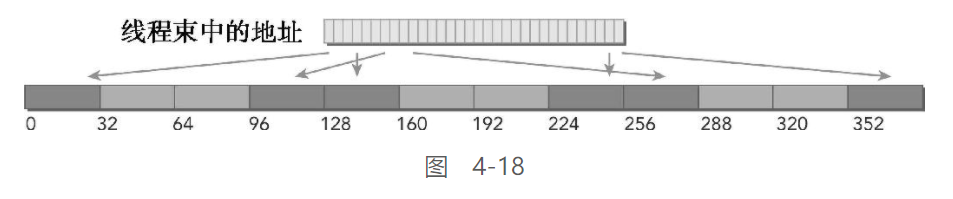
由此可猜测为啥Fermi之后都是默认禁用L1的
非对齐读取の样例:
本部分直接使用书里的代码
对第3章中使用的向量加法代码进行修改:
kernel中多了一个k索引,是用来配置偏移地址的,通过他就可以配置对齐情况,只有在load两个数组A和B时才会使用k。对C的写操作则继续使用原来的代码,从而保证写操作 保持很好的对齐。
__global__ void readOffset(float *A, float *B, float *C, const int n,int offset) {
unsigned int i = blockIdx.x * blockDim.x + threadIdx.x;
unsigned int k = i + offset;
if (k < n) C[i] = A[k] + B[k];
}
主机中用于验证的代码也做出相应修改:

main函数:
int main(int argc, char **argv)
{
// set up device
int dev = 0;
cudaDeviceProp deviceProp;
cudaGetDeviceProperties(&deviceProp, dev);
printf("%s starting reduction at ", argv[0]);
printf("device %d: %s ", dev, deviceProp.name);
cudaSetDevice(dev);
// set up array size
int nElem = 1 << 20; // total number of elements to reduce
printf(" with array size %d\n", nElem);
size_t nBytes = nElem * sizeof(float);
// set up offset for summary
int blocksize = 512;
int offset = 0;
if (argc > 1)
offset = atoi(argv[1]);
if (argc > 2)
blocksize = atoi(argv[2]);
// execution configuration
dim3 block(blocksize, 1);
dim3 grid((nElem + block.x - 1) / block.x, 1);
// allocate host memory
float *h_A = (float *)malloc(nBytes);
float *h_B = (float *)malloc(nBytes);
float *hostRef = (float *)malloc(nBytes);
float *gpuRef = (float *)malloc(nBytes);
// initialize host array
initialData(h_A, nElem);
memcpy(h_B, h_A, nBytes);
// summary at host side
sumArraysOnHost(h_A, h_B, hostRef, nElem, offset);
// allocate device memory
float *d_A, *d_B, *d_C;
cudaMalloc((float **)&d_A, nBytes);
cudaMalloc((float **)&d_B, nBytes);
cudaMalloc((float **)&d_C, nBytes);
// copy data from host to device
cudaMemcpy(d_A, h_A, nBytes, cudaMemcpyHostToDevice);
cudaMemcpy(d_B, h_A, nBytes, cudaMemcpyHostToDevice);
// kernel 1:
double iStart = seconds();
warmup<<<grid, block>>>(d_A, d_B, d_C, nElem, offset);
cudaDeviceSynchronize();
double iElaps = seconds() - iStart;
printf("warmup <<< %4d, %4d >>> offset %4d elapsed %f sec\n",
grid.x, block.x,
offset, iElaps);
iStart = seconds();
readOffset<<<grid, block>>>(d_A, d_B, d_C, nElem, offset);
cudaDeviceSynchronize();
iElaps = seconds() - iStart;
printf("readOffset <<< %4d, %4d >>> offset %4d elapsed %f sec\n",
grid.x, block.x,
offset, iElaps);
// copy kernel result back to host side and check device results
cudaMemcpy(gpuRef, d_C, nBytes, cudaMemcpyDeviceToHost);
checkResult(hostRef, gpuRef, nElem - offset);
// copy kernel result back to host side and check device results
cudaMemcpy(gpuRef, d_C, nBytes, cudaMemcpyDeviceToHost);
checkResult(hostRef, gpuRef, nElem - offset);
// copy kernel result back to host side and check device results
cudaMemcpy(gpuRef, d_C, nBytes, cudaMemcpyDeviceToHost);
checkResult(hostRef, gpuRef, nElem - offset);
// free host and device memory
cudaFree(d_A);
cudaFree(d_B);
cudaFree(d_C);
free(h_A);
free(h_B);
// reset device
cudaDeviceReset();
return EXIT_SUCCESS;
}
结果:

使用nvprof可以查看全局加载效率:



对于没有缓存加载的情况:

结果显示,没有缓存的加载的整体性能略低于缓存访问的性能。缓存缺失对非对齐访问的性能影响更大。如果启用缓存,一个非对齐访问可能将数据存到一级缓存,这个一级缓存用于后续的非对齐内存访问。但是,如果没有一级缓存,那么每一次非对齐请求需要多个内存事务,并且对将来的请求没有作用, 所以为啥整体的时间反而提高了
此时的全局加载效率:

对于非对齐情况,禁用一级缓存使加载效率得到了提高,从49.8%提高到了80%, 由于禁用了一级缓存,每个加载请求是在32个字节的粒度上而不是128个字节的粒度上进行处理,因此加载的字节(但未使用的)数量减少了
但是:
这种结果只针对这种测试示例。随着设备占用率的提高,没有缓存的加载可帮助提高总线的整体利用率。对于没有缓存的非对齐加载模式来说,未使用的数据传输量可能会显著减少。
只读缓存:

全局内存写入:
之前说过, CUDA的L1 L2缓存仅针对了程序的空间局部性, 并没有针对时间局部性
即: L1不用在存储操作上, 存储操作仅通过二级缓存
所以存储的执行粒度为32字节
内存访问可以被分为1段, 2段, 4段进行传输, 所以有以下3中情况:
-
对齐 & 128连续:
图4-19所示为理想情况:内存访问是对齐的,并且线程束里所有的线程访问一个连续的128字节范围。存储请求由1个四段事务实现
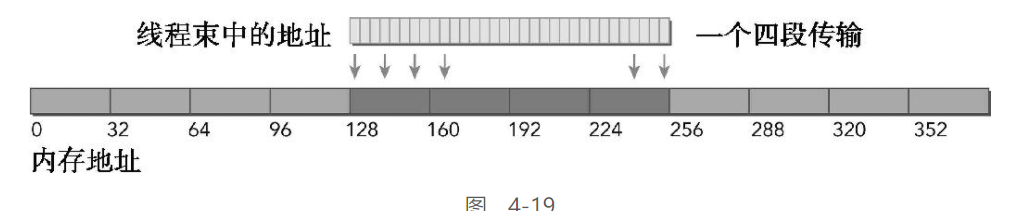
-
对齐 & 分散:
图4-20所示为内存访问是对齐的,但地址分散在一个192个字节范围内的情况。存储请求由3个一段事务来实现
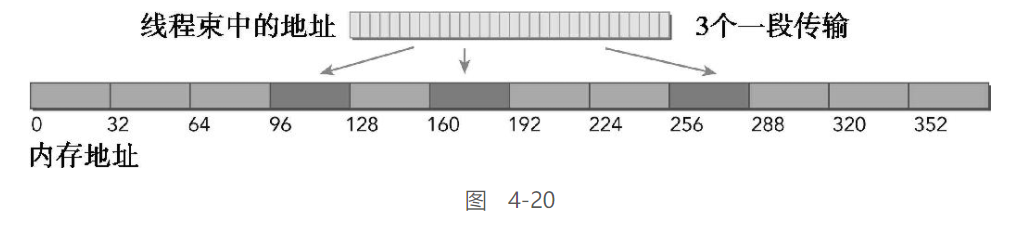
-
对齐 & 64连续:
图4-21所示为内存访问是对齐的,并且地址访问在一个连续的64个字节范围内的情况。这种存储请求由一个两段事务来完成
例程:
仍然在之前例程的基础上进行修改, load变回使用i,而对C的写则使用k:
__global__ void writeOffset(float *A, float *B, float *C,const int n, int offset) {
unsigned int i = blockIdx.x * blockDim.x + threadIdx.x;
unsigned int k = i + offset;
if (k < n) C[k] = A[i] + B[i];
}
主机端同样也修改:
void sumArraysOnHost(float *A, float *B, float *C, const int n,int offset) {
for (int idx = offset, k = 0; idx < n; idx++, k++) {
C[idx] = A[k] + B[k];
}
}
输出:

偏移量为11时性能最差
使用nvprof获取全局加载 & 储存效率指标:

当偏移量为11且从一个线程束产生一个128个字节的写入请求时,该请求将由一个四段事务和一个一段事务来实现。因此,128个字节用来请求,160个字节用来加载,存储效率为80%。
结构体数组 & 数组结构体:
数组结构体(AoS) & 结构体数组(SoA)
这里介绍这俩, 主要用于存储结构化的数据集
-
AoS:
它存储的是空间上相邻的数据(例如,x和y),这在CPU上会有良好的缓存局部性


-
SoA:
这不仅能将相邻数据点紧密存储起来,也能将跨数组的独立数据点存储起来

二者内存布局的区别:
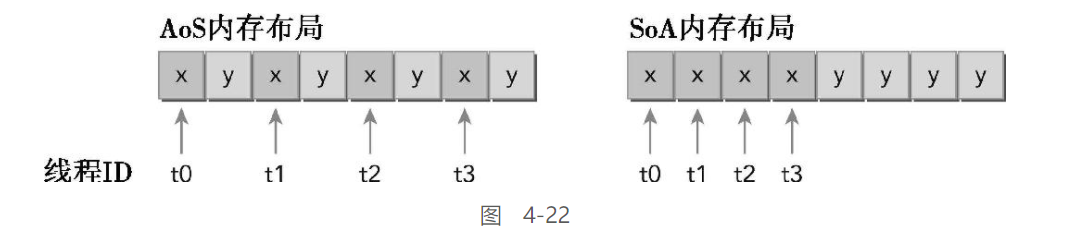
基于之前学习的内存访问模型, 可知
在SIMD模式中, 数据储存更倾向与SoA
例程:
以下给出两种存储模式的对比:
AoS模式

输出:


SoA模式:



性能调整:
优化设备内存带宽利用率有两个目标:
-
对齐及合并内存访问,以减少带宽的浪费
-
足够的并发内存操作,以隐藏内存延迟
加上第三章中学到的优化指令吞吐量的方法:
本节来学习内存性能调优
循环展开:
这里书中讲的莫名其妙, 原理没说清楚, 但是应用环境倒是讲的挺明白的
本部分非常类似于第三章中的循环展开
先说下结论:
对于I/O密集型核函数, 内存访问并行循环展开有着很高的性能提升
例子:
修改之前的readOffset核函数:
初始版本:
__global__ void readOffset(float *A, float *B, float *C, const int n,int offset) {
unsigned int i = blockIdx.x * blockDim.x + threadIdx.x;
unsigned int k = i + offset;
if (k < n) C[i] = A[k] + B[k];
}
修改后, 每个循环中对内存的操作由一次增加到4次

运行结果:
这里启动一级缓存

对比与之前的版本:

能实现3.04~3.17倍的加速, 证明了这一展开技术对性能有非常好的影响,甚至比地址对齐还要好
使用nvprof查看加载&存储效率:

可以看到效率相同
但在偏移量为11的情况下:

增大并行性:
这里主要是对核函数的运行配置进行调优:
(以下均使用偏移量为0的情况)

这里的结果是根据架构而异的
尽管每块有128个线程对GPU来说有了更多的并行性,但其性能比每块有256个线程稍差。要想知道其中的原因,请参考第3章中的表3-2,需要特别注意的是此处有两个硬件限制。因为在这种情况下,测试系统使用Fermi GPU,每个SM最多有8个并发线程块,并且每个SM最多有48个并发线程束。当采用每个线程块有128个线程的方案时,则每个线程块有4个线程束。因为一个Fermi SM只可以同时放置8个线程块,所以该核函数被限制每个SM上最多有32个线程束。这可能会导致不能充分利用SM的计算资源,因为没有达到48个线程束的上限。你也可以使用第3章介绍的CUDA占用率来达到相同的效果
当偏移量为11时:
4.4 核函数可达到的带宽:
在上一节中,你已经尝试使用两种方法来改进核函数的性能:
本节的主要目标:
对于这样一个核函数来说:
- 什么样的性能才是足够好的呢?
- 在次理想的情况下可达到的最理想性能又是什么呢
我们将利用一个矩阵转置的例子学习如何通过使用各种优化手段来调整核函数的带宽。你会看到,即使一个原本不好的访问模式,仍然可以通过重新设计核函数中的几个部分以实现良好的性能。
内存带宽:
大多数核函数对内存带宽非常敏感,也就是说它们有内存带宽的限制。
一般有如下两种类型的带宽:
-
理论带宽
理论带宽是当前硬件可以实现的绝对最大带宽, 通常在设备性能说明上都会写明
-
有效带宽
有效带宽是核函数实际达到的带宽,它是测量带宽, 使用公式计算:


矩阵转置问题:
以下是基于主机实现的使用单精度浮点值的错位转置算法。假设矩阵存储在一个一维数组中。通过改变数组索引值来交换行和列的坐标,可以很容易得到转置矩阵
就是简单的将原始矩阵中的横纵坐标交换并拷贝到新的矩阵

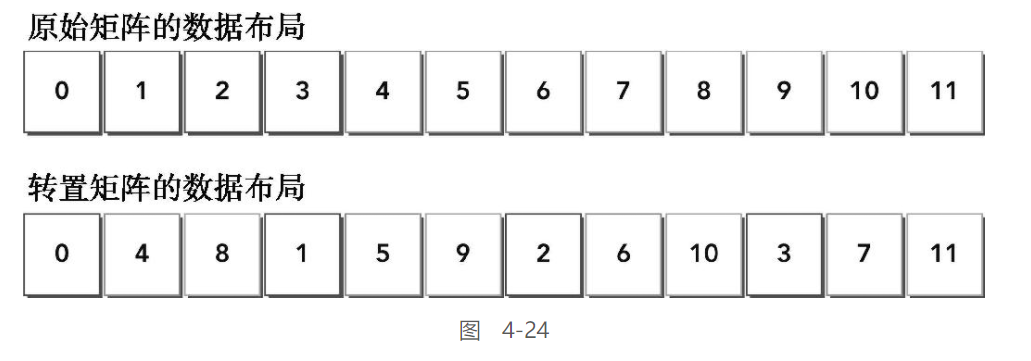
观察输入和输出布局,你会注意到:
-
读:通过原矩阵的行进行访问,结果为合并访问
-
写:通过转置矩阵的列进行访问,结果为交叉访问
交叉访问是使GPU性能变得最差的内存访问模式。但是,在矩阵转置操作中这是不可避免的。本节的剩余部分将侧重于使用两种转置核函数来提高带宽的利用率:一种是按行读取按列存储,另一种则是按列读取按行存储
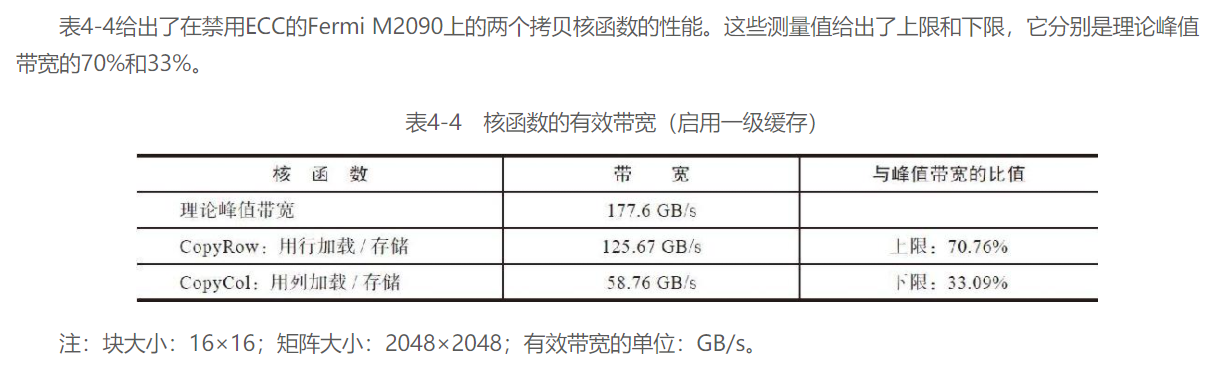
确认带宽上下限:
实验之前可以先测试一下带宽上下限, 以对比性能调优的结果:

最简单的办法: 行读取 & 列读取:

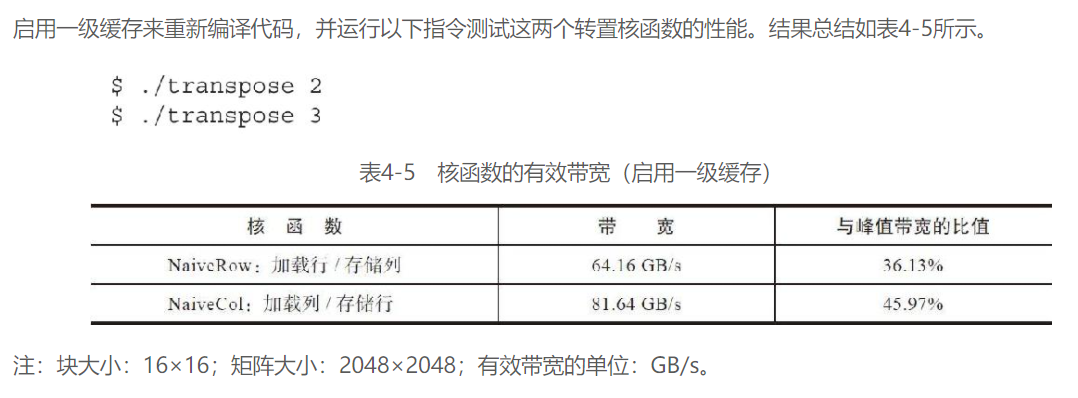
可以看到第二种方法明显要好
这里就很迷了, 书里是这么说的:
如前面所述,导致这种性能提升的一个可能原因是在缓存中执行了交叉读取。即使通过某一方式读入一级缓存中的数据没有都被这次访问使用到,这些数据仍留在缓存中,在以后的访问过程中可能发生缓存命中
按道理来说, 内存写入是没有缓存的, 所以交叉写入&合并写入基本没有性能差别, 但是读取上, 之前说到合并读取理论上会比交叉读取有更好的性能, 但是这里却是相反
这里也只能用L1缓存命中率来解释了
在缓存读取的情况下,每个内存请求由一个128字节的缓存行来完成。按列读取数据,使得线程束里的每个内存请求都会重复执行32次(因为交叉读取2048个数据元素),一旦数据预先存储到了一级缓存中,那么许多当前全局内存读取就会有良好的隐藏延迟并取得较高的一级缓存命中率
在禁用L1的情况下:
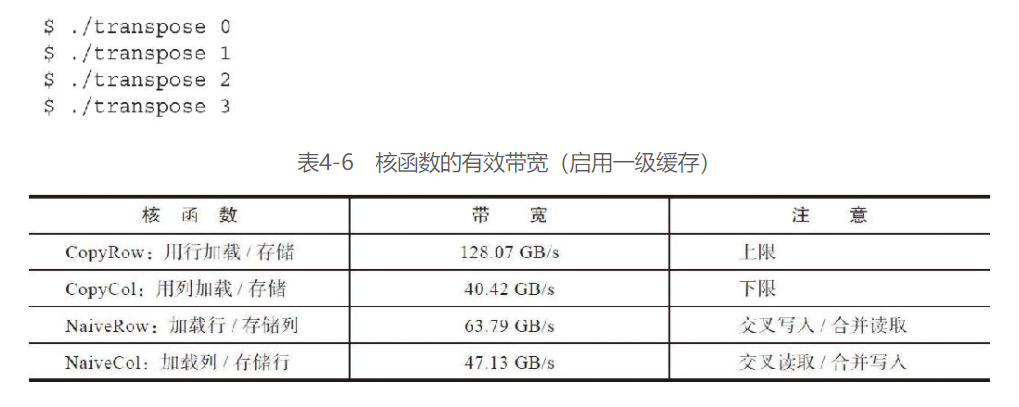
相应的缓存加载情况:
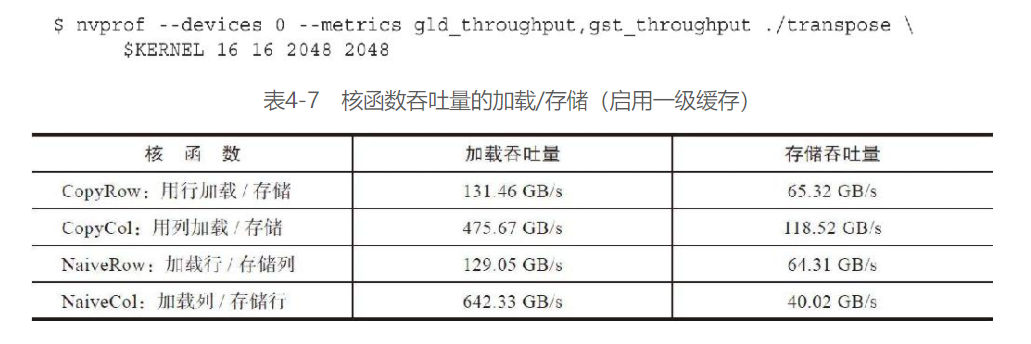
LD/ST效率:
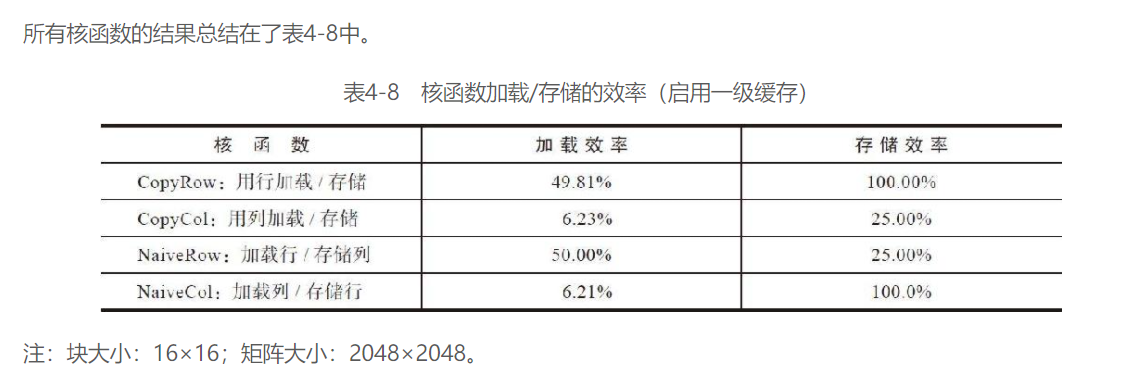
循环展开的转置:
修改核函数如下:

输出(禁用L1)
并且在启用L1的情况下, 第二种能获得更好的性能
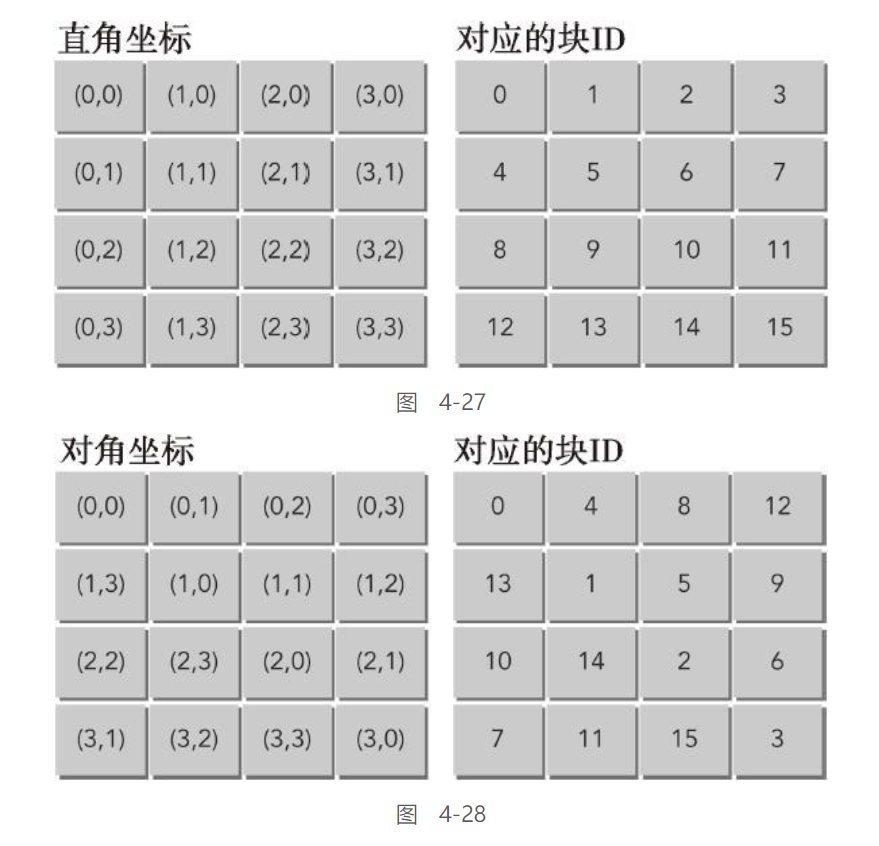
对角转置:
这里换了一种思路, 使用对角坐标系对矩阵的转置进行顺序上的调整:
对角坐标系如下, 有点类似于行列式乘法计算顺序的样子
核函数修改如下:
这里,blockIdx.x和blockIdx.y为对角坐标。block_x和block_y是它们对应的笛卡尔坐标。基于行的矩阵转置核函数使用如下所示的对角坐标。在核函数的起始部分包含了从对角坐标到笛卡尔坐标的映射计算,然后使用映射的笛卡尔坐标(block_x,block_y)来计算线程索引(ix,iy)。这个对角转置核函数会影响线程块分配数据块的方式。

输出:

可以看到第一种方法的性能提升很明显, 但第二种性能甚至下降
原先的性能对比:

性能提升的原因:
反正
首先这里需要了解一下DRAM分区(区块)的概念:
这本书翻译的就是很奇怪, 感觉不应该叫分区, 所以在原书的基础上进行个人的理解
全局内存的访问请求实际上有DRAM分区完成, 可以想象成每个分区256字节大小, 不同分区的访问可以并行, 但对同一个分区的访问是串行的
- 当使用笛卡尔坐标将线程块映射到数据上时, 全局内存的访问可能导致访问了同一个分区而被迫串行, 而另一些分区则没有调用
- 当使用对角坐标系映射时, 线程块书里的数据块非线性映射, 所以降低了访问同一个分区的概率, 使得内存串行性下降, 带来性能上的提升
小样例:
对最佳性能来说,被所有活跃的线程束并发访问的全局内存应该在分区中被均匀地划分。图4-29所示为一个简化的可视化模型,它表示了使用笛卡尔坐标表示块ID时的分区冲突。在这个图中,假设通过两个分区访问全局内存,每个分区的宽度为256个字节,并且使用一个大小为32×32的线程块启动核函数。如果每个数据块的宽度是128个字节,那么需要使用两个分区为第0、1.2.3个线程块加载数据。但现实是,只能使用一个分区为第0、1.2.3个线程块存储数据,因此造成了分区冲突。
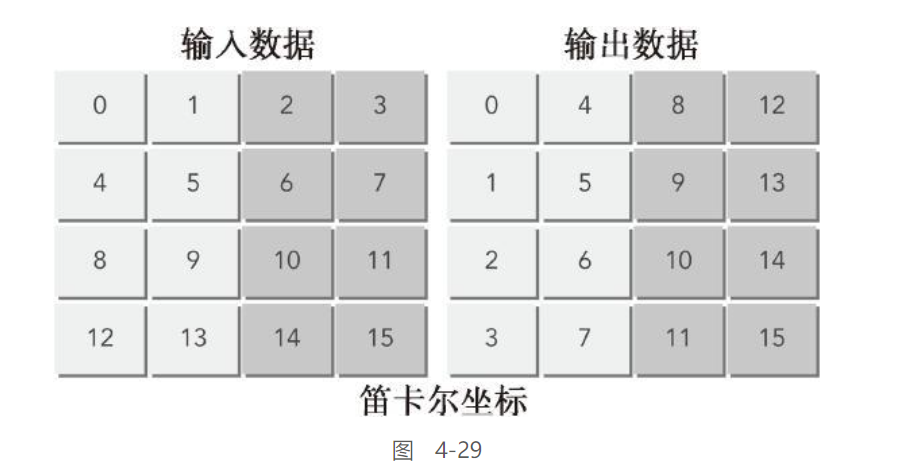
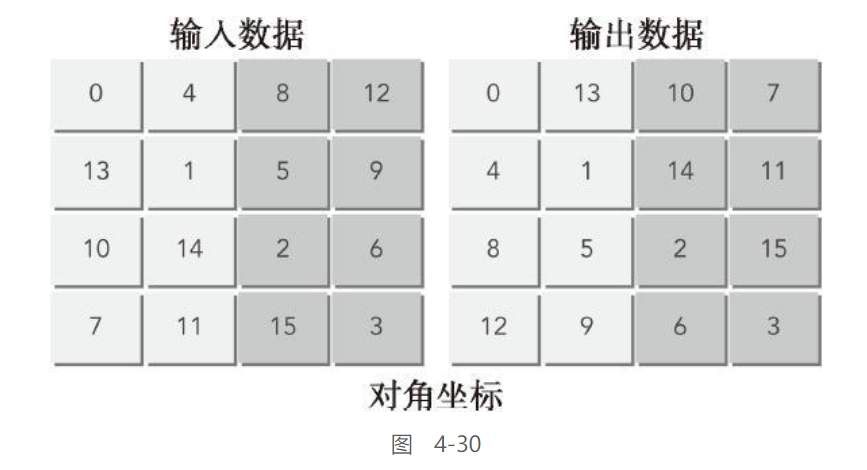
图4-30借用了图4-29中的简化模型,但这次使用对角坐标来表示块ID。在这种情况下,需要使用两个分区为第0、1.2.3个线程块加载和存储数据。加载和存储请求在两个分区之间被均匀分配。这个例子说明了为什么对角核函数能够获得更好的性能
使用瘦块来增加并行性:
神奇的翻译, 瘦块是什么…根本搜不到好吧
总之这里就是调整block的大小进行性能的对比
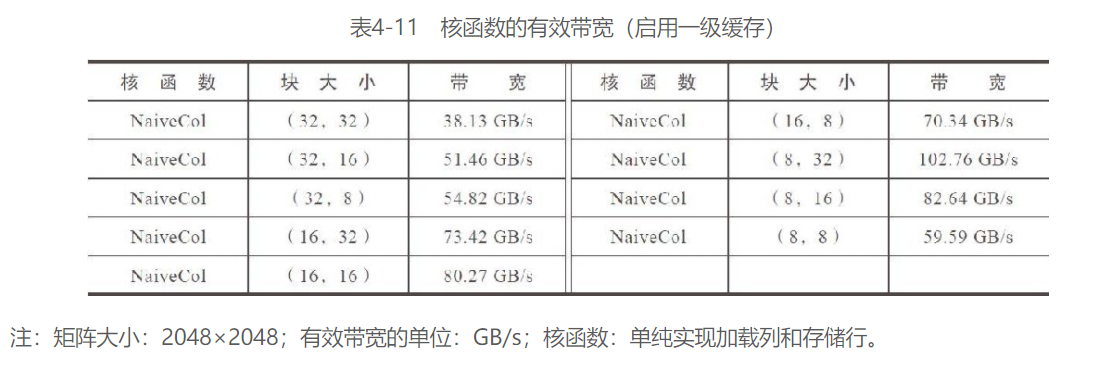
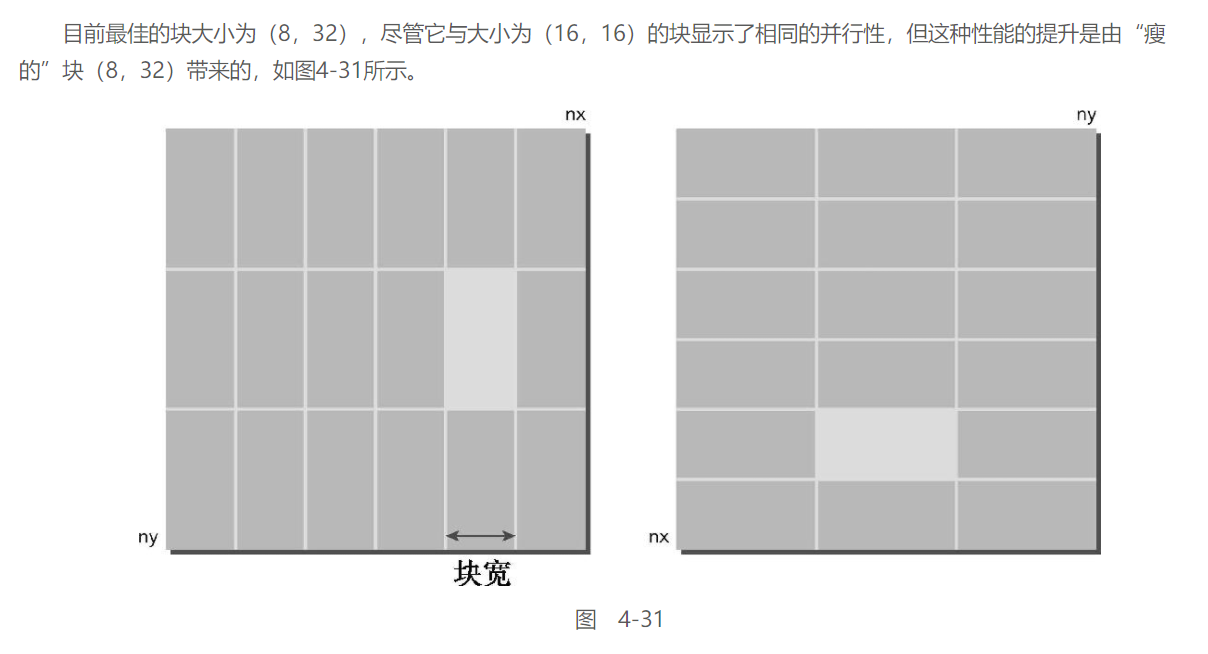
通过增加存储在线程块中连续元素的数量,“瘦”块可以提高存储操作的效率(如表4-12所示)
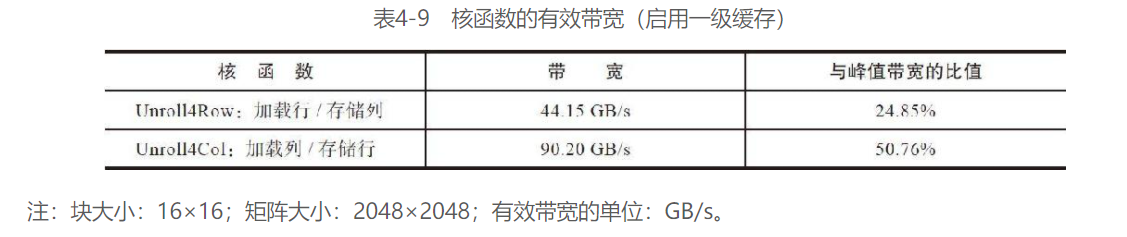
nvprof中也表明了这一点:

使用瘦块执行之前几种核函数进行性能测试:
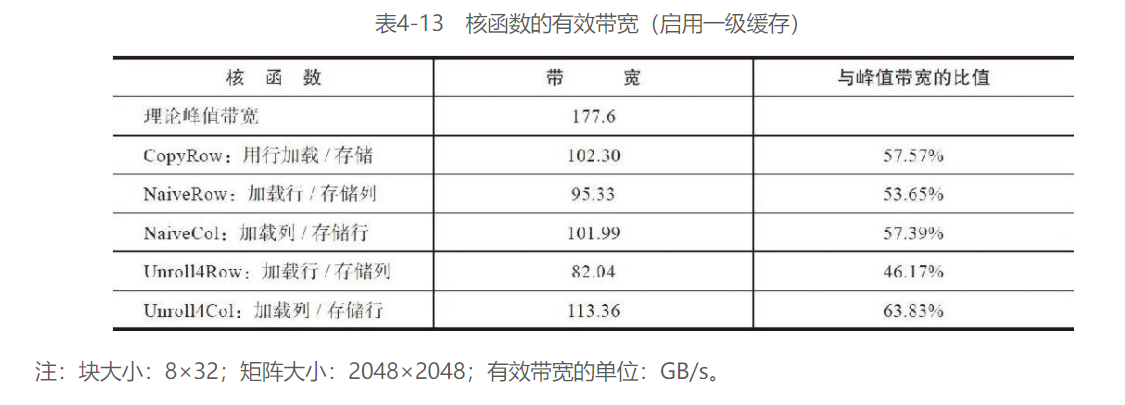
到目前为止,核函数Unroll4Col性能表现得最好,甚至优于上限拷贝核函数。有效带宽达到了峰值带宽的60%~80%,这一结果是很令人满意的
4.5 使用统一内存的矩阵加法:
本部分尝试用之前讲到的统一内存来解决矩阵加法问题:
所以本部分按道理应该使用Pascal架构以上的显卡 ?
但是为啥书里使用的是K40 ???
并且用的还是-arch=sm_30 , 统一内存TM不是CUDA6.0 之后才有的么
这么说之后的编程都可以使用统一内存???

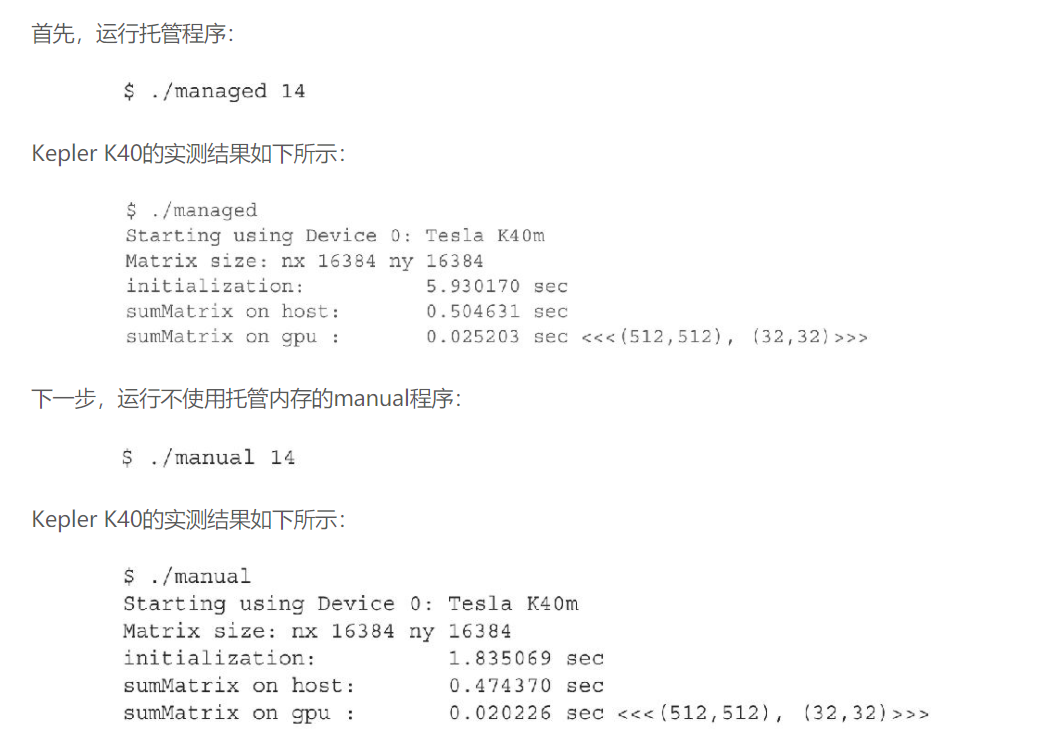
这些结果表明,使用托管内存的核函数速度与显式地在主机和设备之间复制数据几乎一样快,并且很明显它需要更少的编程工作
nvprof的结果:
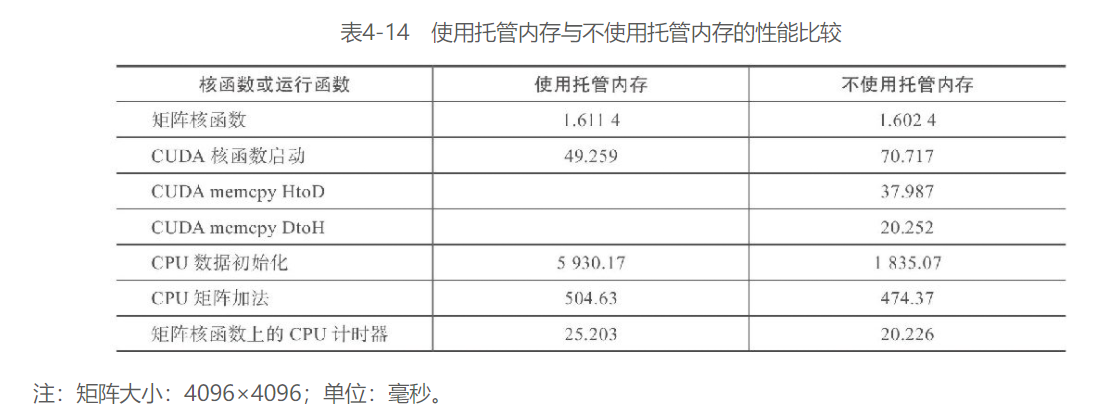
Kepler K40的运行结果总结在了表4-14中。影响性能差异的最大因素在于CPU数据的初始化时间——使用托管内存耗费的时间更长。矩阵最初是在GPU上被分配的,由于矩阵是用初始值填充的,所以首先会在CPU上引用。这就要求底层系统在初始化之前,将矩阵中的数据从设备传输到主机中,这是manual版的核函数中不执行的传输。
当执行主机端矩阵求和函数时,整个矩阵都在CPU上了,因此执行时间比非托管内存要短。接下来,warm-up核函数将整个矩阵迁回设备中,这样当实际的矩阵加法核函数被启动时,数据已经在GPU上了。如果没有执行warm-up核函数,使用托管内存的核函数明显运行得更慢。
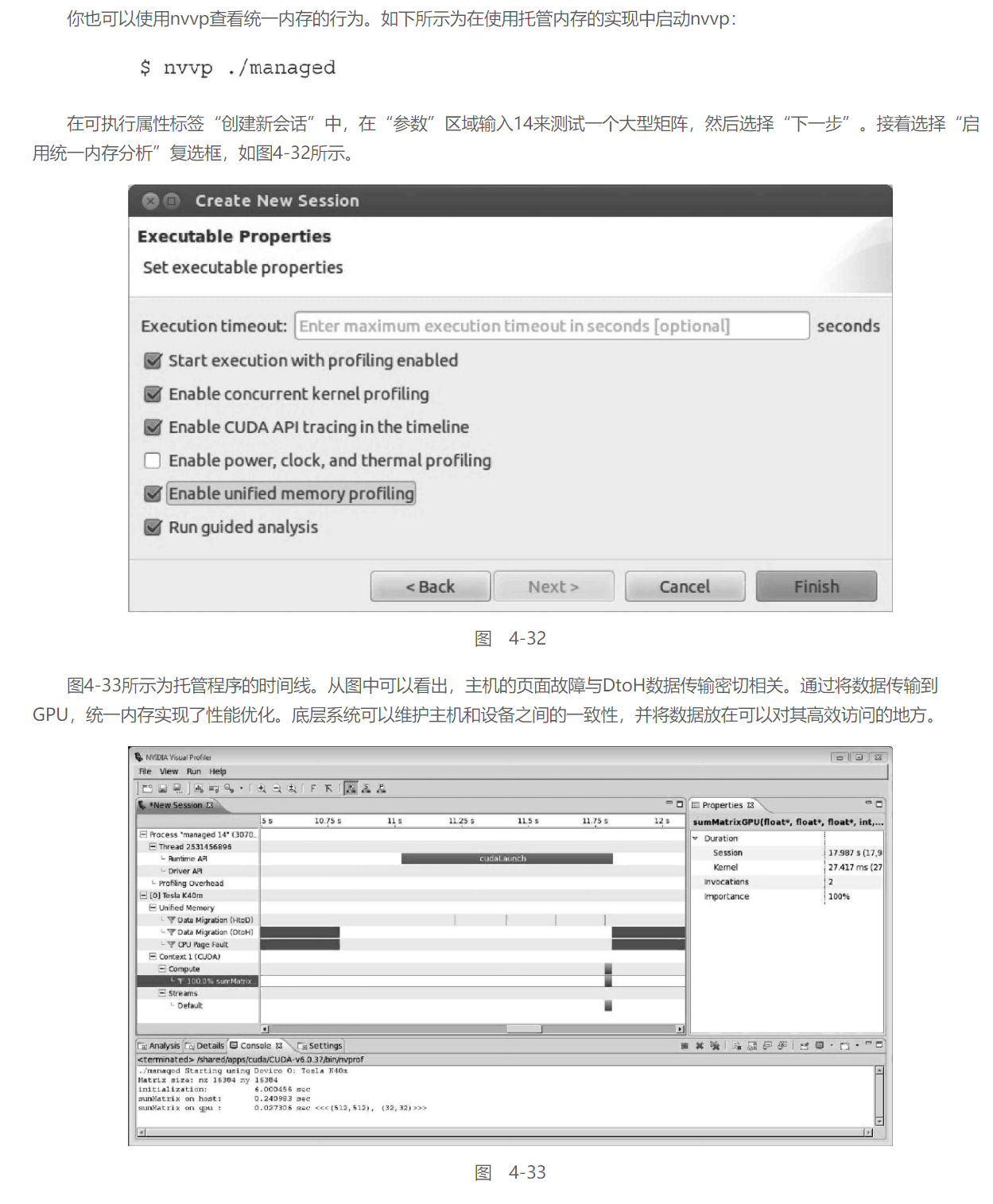
nvvp和nvprof支持检验统一内存的性能。这两种分析器都可以测量系统中每个GPU统一内存的通信量

中间的Count指的是页故障数量
在进行设备到主机传输数据时,将CPU的页故障报告给设备。当主机应用程序引用一个CPU虚拟内存地址而不是物理内存地址时,就会出现页面故障。当CPU需要访问当前驻留在GPU中的托管内存时,统一内存使用CPU页面故障来触发设备到主机的数据传输。测试出的页面故障的数量与数据大小密切相关。
当换用256×256个元素的矩阵重新运行程序, 页面故障的数量大大减少


使用nvvp进行分析
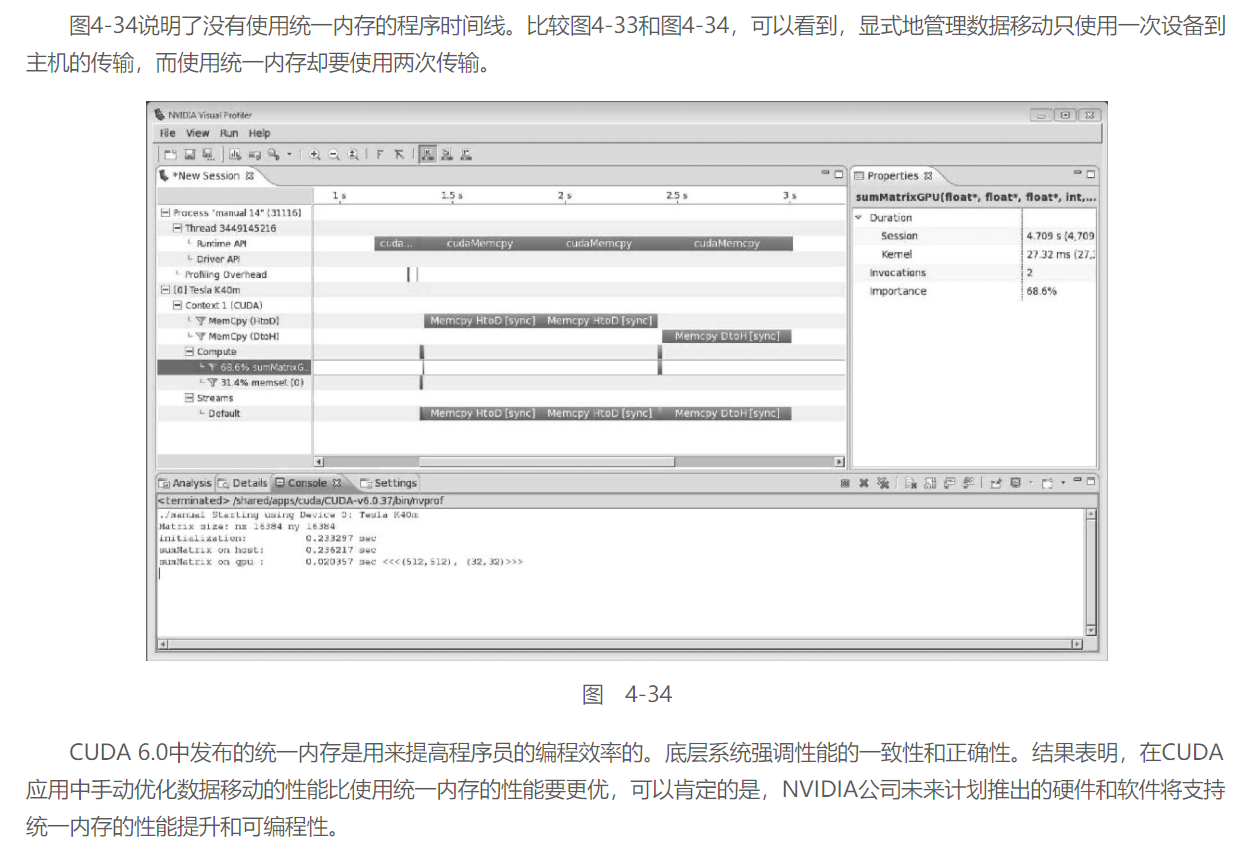
4.6 总结:
CUDA编程模型的一个显著特点是有对程序员直接可用的GPU内存层次结构。这对数据移动和布局提供了更多的控制,优化了性能并得到了更高的峰值性能。
全局内存是最大的、延迟最高的、最常用的内存。对全局内存的请求可以由32个字节或128个字节的事务来完成。记住这些特点和粒度对于调控应用程序中全局内存的使用是很重要的。
通过本章的示例,我们学习了以下两种提高带宽利用率的方法:
为保持有足够多的正在执行的内存操作,可以使用展开技术在每个线程中创建更多的独立内存请求,或调整网格和线程块的执行配置来体现充分的SM并行性。
为了避免在设备内存和片上内存之间有未使用数据的移动,应该努力实现理想的访问模式:对齐和合并内存访问。
对齐内存访问相对容易,但有时合并访问比较有挑战性。一些算法本身就无法合并访问,或实现起来有一定的困难。
改进合并访问的重点在于线程束中的内存访问模式。另一方面,消除分区冲突的重点则在于所有活跃线程束的访问模式。对角坐标映射是一种通过调整块执行顺序来避免分区冲突的方法。
通过消除重复指针以及在主机和设备之间显式传输数据的需要,统一内存大大简化了CUDA编程。CUDA 6.0中统一内存的实现明显地保持了性能的一致性和优越性。未来硬件和软件的提升将会提高统一内存的性能。
下一章将详细介绍在本章简要提到的两个话题:常量内存和共享内存。
