一. 基础
- 为什么要使用切片: slice出现的原因主要是为了解决数组长度固定的问题
- slice是一种动态数组的实现,它由三个属性组成:array指针数组,len表示slice中元素的个数,cap表示底层数组中元素的个数,len不能大于cap,假设指定cap为10,当添加第11个元素时会报错
- 切片是数组的一个引用,是引用类型,传递时是引用拷贝
- 切片的长度是可变的,但是在初始化时如果直接赋值不能超过初始化的len长度
- 其它问题小总结:
- 每个切片都指向一个底层数组
- 每个切片都保存了当前切片的长度、底层数组可用容量
- 使用len()计算切片长度时间复杂度为O(1),不需要遍历切片
- 使用cap()计算切片容量时间复杂度为O(1),不需要遍历切片
- 通过函数传递切片时,不会拷贝整个切片,因为切片本身只是个结构体而矣
- 使用append()向切片追加元素时有可能触发扩容,扩容后将会生成新的切片
- 切片的两种创建方式
- 第一种: 首先创建数组,让切片去引用数组,创建处理
- 第二种: 通过make创建切片(参数说明: type 数据类型,len: 大小, cap:容量可选值,但要大于len
//1.声明一个数组,指定长度为10
var array [10]int
//array[5:6]引用这个数组,通过数组的方式创建切片,
//数组下标5开始,6结束(不包含6)
var slice = array[5:6]
slice := make([]int, 5, 10)
//原理类似make,也可以看为创建数组不指定长度?
//注意: [ ] 里面不要写数组的容量,因为如果写了个数以后就是数组了,而不是切片了
var ss []string = []string{"tom","aaa"}
- 两种方式的区别:
- 直接引用数组方式: 数组是事先存在的,注意数组和切片操作可能作用于同一块内存
- make方式: 底层也会创建一个数组,由切片底层维护
- cap(切片): 获取当前切片中存放的最多数据的个数(动态可伸缩的,有点像HashMap的扩容,底层的数组长度)
几个小问题
1. 题目一
- 判断输出什么,解释:
- main函数中定义了一个10个长度的整型数组array,然后定义了一个切片slice,切取数组的第6个元素,
- 打印slice的长度和容量,
- 判断切片的第一个元素和数组的第6个元素地址是否相等
func main() {
var array [10]int
var slice = array[5:6]
fmt.Println("lenth of slice: ", len(slice))
fmt.Println("capacity of slice: ", cap(slice))
fmt.Println(&slice[0] == &array[5])
}
- 结果: slice跟据数组array创建,与数组共享存储空间,slice起始位置是array[5],长度为1,容量为5,slice[0]和array[5]地址相同
2. 题目二
- 判断输出什么,解释:
- AddElement(): 接收一个切片和一个元素,把元素append进切片中,并返回
- main()函数中定义一个切片,并向切片中append 3个元素
- 接着调用AddElement()继续向切片append进第4个元素同时定义一个新的切片newSlice
- 最后判断新切片newSlice与旧切片slice是否共用一块存储空间
func AddElement(slice []int, e int) []int {
return append(slice, e)
}
func main() {
var slice []int
slice = append(slice, 1, 2, 3)
newSlice := AddElement(slice, 4)
fmt.Println(&slice[0] == &newSlice[0])
}
- 结果: append函数执行时会判断切片容量是否能够存放新增元素,如果不能则会重新申请存储空间,新存储空间将是原来的2倍或1.25倍(取决于扩展原空间大小)本例中实际执行了两次append操作,第一次空间增长到4,所以第二次append不会再扩容,所以新旧两个切片将共用一块存储空间。程序会输出”true
3. 题目三
- 判断输出什么,解释:
- 该段程序源自select的实现代码,程序中定义一个长度为10的切片order,
- pollorder和lockorder分别是对order切片做了order[low:high:max]操作生成的切片,
- 最后程序分别打印pollorder和lockorder的容量和长度
func main() {
orderLen := 5
order := make([]uint16, 2 * orderLen)
pollorder := order[:orderLen:orderLen]
lockorder := order[orderLen:][:orderLen:orderLen]
fmt.Println("len(pollorder) = ", len(pollorder))
fmt.Println("cap(pollorder) = ", cap(pollorder))
fmt.Println("len(lockorder) = ", len(lockorder))
fmt.Println("cap(lockorder) = ", cap(lockorder))
}
- 结果: order[low:high:max]操作,意思是对order进行切片,新切片范围是[low, high),新切片容量是max。order长度为2倍的orderLen,pollorder切片指的是order的前半部分切片,lockorder指的是order的后半部分切片,即原order分成了两段。所以,pollorder和lockerorder的长度和容量都是orderLen,即5
4. 数组和切片陷阱
- 参考博客
二. Slice实现原理
切片的创建与底层结构
- Slice底层依托数组实现,查看slice结构体,array指针指向底层数组,len表示切片长度,cap表示底层数组容量,当调用make()函数初始化时
func makeslice(et *_type, len, cap int) unsafe.Pointer {
mem, overflow := math.MulUintptr(et.size, uintptr(cap))
//1.对切片有效数据的个数,与容量等进行验证 make([]切片类型,有效个数,容量(大于等于有效个数))
//当验证不同过时,panic终止程序继续运行
if overflow || mem > maxAlloc || len < 0 || len > cap {
mem, overflow := math.MulUintptr(et.size, uintptr(len))
if overflow || mem > maxAlloc || len < 0 {
panicmakeslicelen()
}
panicmakeslicecap()
}
//2.前面的验证通过后,调用mallocgc函数,该函数中会获取一个int类型值,也就是结构体中array unsafe.Pointer的长度
//最终会创建一个 slice 结构体
return mallocgc(mem, et, true)
}
// src/runtime/slice.go:slice
type slice struct {
array unsafe.Pointer
len int
cap int
}
- 例如: slice := make([]int, 5, 10), 表示:
该Slice长度为5,即可以使用下标slice[0] ~ slice[4]来操作里面的元素,capacity为10,表示后续向slice添加新的元素时可以不必重新分配内存,直接使用预留内存即可

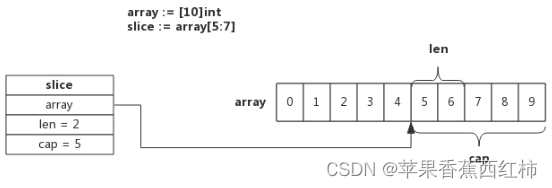
- 使用数组创建切片: 内存中首先开辟一个array空间,然后开辟silce切片空间,引用了array的变量,所以地址值与引用的intArr数组中首个引用元素的值相同
切片从数组array[5]开始,到数组array[7]结束(不含array[7])即切片长度为2,数组后面的内容都作为切片的预留内存,即capacity为5
append() 与切片的扩容
- 当使用append向Slice追加元素时,如果Slice空间不足,会触发Slice扩容, 例如向一个capacity为5,且length也为5的Slice再次追加1个元素时,就会发生扩容
- 扩容时会执行底层的growslice()函数, 在该函数中会经过多个判断
- 如果当前添加元素所需容量 (cap) 大于原先容量的两倍 (doublecap),会已当前所需容量作为扩容容量
- 当前所需容量(cap)不大于原容量的两倍(doublecap),会判断原切片的长度(old.len)是否小于1024
- 如果原切片长度(lod.len)小于1024, 扩容为原容量的两倍
- 如果原切片长度(lod.len)大于1024,会获取原切片长度,以原切片长度的1.25倍进行扩容,直到大于所需容量(cap)为止,然后判断最终申请容量(newcap)是否溢出,如果溢出,最终申请容量等于所需容量(cap)
- 例如: 所需容量 cap = 1024+2 = 1026,doublecap = 2048, 大于1024, 获取原切片长度 old.len = 1024,计算扩容容量newcap = 1024 + 1024/4 = 1280
func growslice(et *_type, old slice, cap int) slice {
if raceenabled {
callerpc := getcallerpc()
racereadrangepc(old.array, uintptr(old.len*int(et.size)), callerpc, abi.FuncPCABIInternal(growslice))
}
if msanenabled {
msanread(old.array, uintptr(old.len*int(et.size)))
}
if asanenabled {
asanread(old.array, uintptr(old.len*int(et.size)))
}
if cap < old.cap {
panic(errorString("growslice: cap out of range"))
}
if et.size == 0 {
// append should not create a slice with nil pointer but non-zero len.
// We assume that append doesn't need to preserve old.array in this case.
return slice{unsafe.Pointer(&zerobase), old.len, cap}
}
newcap := old.cap
doublecap := newcap + newcap
if cap > doublecap {
newcap = cap
} else {
const threshold = 256
if old.cap < threshold {
newcap = doublecap
} else {
// Check 0 < newcap to detect overflow
// and prevent an infinite loop.
for 0 < newcap && newcap < cap {
// Transition from growing 2x for small slices
// to growing 1.25x for large slices. This formula
// gives a smooth-ish transition between the two.
newcap += (newcap + 3*threshold) / 4
}
// Set newcap to the requested cap when
// the newcap calculation overflowed.
if newcap <= 0 {
newcap = cap
}
}
}
var overflow bool
var lenmem, newlenmem, capmem uintptr
// Specialize for common values of et.size.
// For 1 we don't need any division/multiplication.
// For goarch.PtrSize, compiler will optimize division/multiplication into a shift by a constant.
// For powers of 2, use a variable shift.
switch {
case et.size == 1:
lenmem = uintptr(old.len)
newlenmem = uintptr(cap)
capmem = roundupsize(uintptr(newcap))
overflow = uintptr(newcap) > maxAlloc
newcap = int(capmem)
case et.size == goarch.PtrSize:
lenmem = uintptr(old.len) * goarch.PtrSize
newlenmem = uintptr(cap) * goarch.PtrSize
capmem = roundupsize(uintptr(newcap) * goarch.PtrSize)
overflow = uintptr(newcap) > maxAlloc/goarch.PtrSize
newcap = int(capmem / goarch.PtrSize)
case isPowerOfTwo(et.size):
var shift uintptr
if goarch.PtrSize == 8 {
// Mask shift for better code generation.
shift = uintptr(sys.Ctz64(uint64(et.size))) & 63
} else {
shift = uintptr(sys.Ctz32(uint32(et.size))) & 31
}
lenmem = uintptr(old.len) << shift
newlenmem = uintptr(cap) << shift
capmem = roundupsize(uintptr(newcap) << shift)
overflow = uintptr(newcap) > (maxAlloc >> shift)
newcap = int(capmem >> shift)
default:
lenmem = uintptr(old.len) * et.size
newlenmem = uintptr(cap) * et.size
capmem, overflow = math.MulUintptr(et.size, uintptr(newcap))
capmem = roundupsize(capmem)
newcap = int(capmem / et.size)
}
// The check of overflow in addition to capmem > maxAlloc is needed
// to prevent an overflow which can be used to trigger a segfault
// on 32bit architectures with this example program:
//
// type T [1<<27 + 1]int64
//
// var d T
// var s []T
//
// func main() {
// s = append(s, d, d, d, d)
// print(len(s), "\n")
// }
if overflow || capmem > maxAlloc {
panic(errorString("growslice: cap out of range"))
}
var p unsafe.Pointer
if et.ptrdata == 0 {
p = mallocgc(capmem, nil, false)
// The append() that calls growslice is going to overwrite from old.len to cap (which will be the new length).
// Only clear the part that will not be overwritten.
memclrNoHeapPointers(add(p, newlenmem), capmem-newlenmem)
} else {
// Note: can't use rawmem (which avoids zeroing of memory), because then GC can scan uninitialized memory.
p = mallocgc(capmem, et, true)
if lenmem > 0 && writeBarrier.enabled {
// Only shade the pointers in old.array since we know the destination slice p
// only contains nil pointers because it has been cleared during alloc.
bulkBarrierPreWriteSrcOnly(uintptr(p), uintptr(old.array), lenmem-et.size+et.ptrdata)
}
}
memmove(p, old.array, lenmem)
return slice{p, old.len, newcap}
}
- 注意如果继续扩容当append,1280->1696,似乎不是1.25倍,而是1.325倍,查看growslice()中执行的roundupsize()用来内存对齐函数,golang中是根据对象大小来配不同的mspan内存的,为了避免造成过多的内存碎片,slice在扩容中需要对扩容后的cap容量进行内存对齐的操作,如果所需容量cap在变成1600后又进入了内存对齐的过程,最终cap变为了1696, 也就是1.325倍
func roundupsize(size uintptr) uintptr {
if size < _MaxSmallSize {
if size <= smallSizeMax-8 {
return uintptr(class_to_size[size_to_class8[divRoundUp(size, smallSizeDiv)]])
} else {
return uintptr(class_to_size[size_to_class128[divRoundUp(size-smallSizeMax, largeSizeDiv)]])
}
}
if size+_PageSize < size {
return size
}
return alignUp(size, _PageSize)
}
切片的值传递引用传递
- 首先切片是值传递
- 在上面我们了解到slice底层是一个结构体,len、cap、array分别表示长度、容量、底层数组的地址,
- 当slice作为函数的参数传递的时候,跟普通结构体的传递是没有区别的;
- 如果直接传slice,实参slice是不会被函数中的操作改变的,
- 如果传递的是slice的指针,是会改变原来的slice的;
-
注意: 无论是传递slice还是slice的指针,如果改变了slice的底层数组,都是会影响slice的
切片再切片(特殊切片)
- 先看一下截取切片,在截取时,通过截取创建出的多个slice实际作用在同一个底层数组上,这里我们可以变向的看成浅拷贝
slice := []int{0, 1, 2, 3, 4, 5, 6, 7, 8, 9}
s1 := slice[2:5]
s2 := s1[2:7]
- 截取出的新切片追加元素时,还要考虑一个扩容问题, 在扩容时,会创建一个新的底层数组的问题
切片的 Copy
- 先看一下截取切片,在截取时,通过截取创建出的多个slice实际作用在同一个底层数组上,这里我们可以变向的看成浅拷贝
slice := []int{0, 1, 2, 3, 4, 5, 6, 7, 8, 9}
s1 := slice[2:5]
s2 := s1[2:7]
- golang提供了copy函数
slice1 := []int{0, 1, 2, 3, 4, 5, 6, 7, 8, 9}
var slice2 []int
slice3 := make([]int, 5)
//执行发现slice1的内容并未copy到slice2
copy_1 := copy(slice2, slice1)
//执行发现slice1的内容成功copy到了slice3中(与slice2不同的是cap长度)
copy_2 := copy(slice3, slice1)
//修改slice3中数据并不会影响copy_2
slice3[0] = 100
- 总结:
- 通过截取方式创建的多个新slice,底层实际都作用在同一个数组上,可以看为浅拷贝,修改其中一个,其它的也会变
- golang提供了copy函数, 在通过该函数对slice进行copy时要注意目标切片大小,不能为0, 也就是需要在拷贝前申请内存空间
- 通过copy函数操作切片时,可以看为深拷贝,修改其中一个,不会影响到复制出的新切片
- 查看copy()源码,在对slice进行coyp()动作时,底层会执行runtime/slice.go文件中slicecopy函数
func slicecopy(to, fm slice, width uintptr) int {
// 如果源切片或者目标切片有一个长度为0,那么就不需要拷贝,直接 return
if fm.len == 0 || to.len == 0 {
return 0
}
// n 记录下源切片或者目标切片较短的那一个的长度
n := fm.len
if to.len < n {
n = to.len
}
// 如果入参 width = 0,也不需要拷贝了,返回较短的切片的长度
if width == 0 {
return n
}
//如果开启竞争检测
if raceenabled {
callerpc := getcallerpc()
pc := funcPC(slicecopy)
racewriterangepc(to.array, uintptr(n*int(width)), callerpc, pc)
racereadrangepc(fm.array, uintptr(n*int(width)), callerpc, pc)
}
if msanenabled {
msanwrite(to.array, uintptr(n*int(width)))
msanread(fm.array, uintptr(n*int(width)))
}
size := uintptr(n) * width
if size == 1 { // common case worth about 2x to do here
// TODO: is this still worth it with new memmove impl?
//如果只有一个元素,那么直接进行地址转换
*(*byte)(to.array) = *(*byte)(fm.array) // known to be a byte pointer
} else {
//如果不止一个元素,那么就从 fm.array 地址开始,拷贝到 to.array 地址之后,拷贝个数为size
memmove(to.array, fm.array, size)
}
return n
}
总结
- 自己对切片的理解,在我们使用slice时需要调用make()函数进行初始化,底层会执行makeslice(),调用mallocgc(),最终会创建一个slice结构体变量
- 该结构体中有三个属性:array unsafe.Pointer 指向底层存储数据的数组指针, len表示切片长度,cap表示底层数组容量(也可以理解为当前切片触发扩容的值与当前切片保存数据的最大个数)
- 假设 cap 未超过1024,当cap==len时,切片会自动扩容,扩容为当前cap的2倍,当cap超过1024时,则扩容加上1/4倍
- 扩容规则总结,当使用append向Slice追加元素时,如果Slice空间不足,会触发Slice扩容,执行底层的growslice()函数:
- 当执行append()对切片进行追加时,底层会通过growslice()进行扩容, 在该方法中 首先判断当前Slice中是否还有空闲容量,
- 如果当前数组有空余位置不需要扩容,直接将元素追加到当前数组上,并且设置Slice.len++
- 如果没有空余位置,会重新分配一块新的内存地址,在分配时,会判断,当前切片元素个数是否小于1024,
- 小于则新Slice容量将扩大为原来的2倍
- 大于等于1024时,则新Slice容量将扩大为原来的1.25倍
- 扩容后,将新元素追加进新Slice,Slice.len++,返回新的Slice
- slice和数组有什么区别
- 长度和容量:数组的长度是固定的,一旦定义就不能改变;而切片的长度和容量都可以动态改变,可以根据需要动态扩容
- 内存布局:数组是一个连续的内存块,所有元素的类型都相同;而切片是一个引用类型,它包含一个指向底层数组的指针、长度和容量
- 传递方式:数组在函数调用时会被复制一份,因此对数组的修改不会影响原始数组;而切片在函数调用时只会传递指针和长度,不会复制整个切片,因此对切片的修改会影响原始切片。
- 初始化方式:数组可以使用[n]T{…}的方式进行初始化,其中n表示数组的长度,T表示数组元素的类型;而切片可以使用make([]T, len, cap)的方式进行初始化,其中len表示切片的长度,cap表示切片的容量。
- slice是有序的吗
是有序的,查看slice底层,实际使用一个数组用来存储数据,通过array unsafe.Pointer指针属性指向该数组
- 传参数组和传参slice有什么区别?传参slice会有什么问题吗?
- 在函数中以数组作为入参时,函数会接收到该数组的副本,在函数内部对该数组元素的修改不会影响原始数组。由于是复制的副本进行传递如果一个非常大的数组作为参数,对性能可能会有影响
- 传递一个 slice 作为参数时,会传递这个slice 的引用,如果在函数内部修改了slice中的元素,会影响到原始值,但是在处理大量数据时,使用 slice 作为函数参数可以减少复制和开
- 参考博客
- GO专家编程
- 参考博客
- 参考博客