Local Light Field Fusion: Practical View Synthesis with Prescriptive Sampling Guidelines
Authors Ben Mildenhall, Pratul P. Srinivasan, Rodrigo Ortiz Cayon, Nima Khademi Kalantari, Ravi Ramamoorthi, Ren Ng, Abhishek Kar
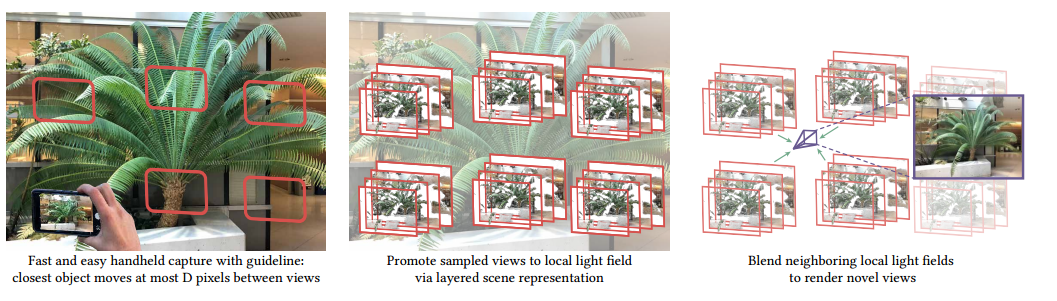
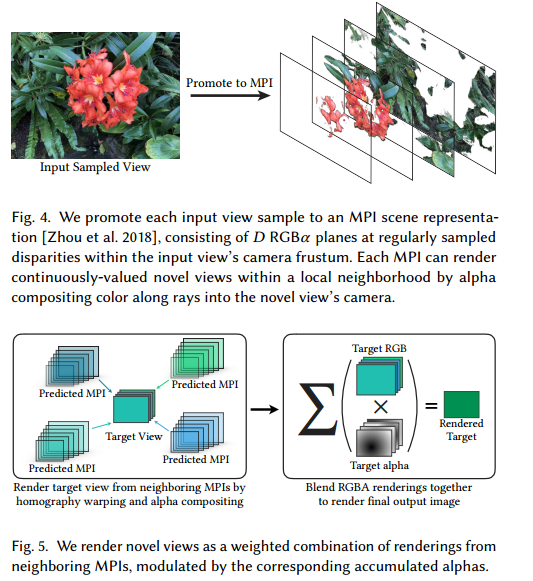
我们提供了一种实用且强大的深度学习解决方案,用于捕获和渲染复杂现实世界场景的新视图以进行虚拟探索以前的方法要么需要难以处理的密集视图采样,要么对用户应如何对场景的视图进行采样以可靠地呈现高质量的新颖视图提供很少或没有指导。相反,我们提出了一种用于从不规则的采样视图网格进行视图合成的算法,该算法首先通过多平面图像MPI场景表示将每个采样视图扩展为局部光场,然后通过混合相邻的局部光场来渲染新颖视图。我们扩展了传统的全光采样理论,以推导出一个边界,该边界精确地指定用户在使用我们的算法时应该如何密集地对给定场景的视图进行采样。在实践中,我们应用此界限来捕获和渲染真实世界场景的视图,这些视图实现了奈奎斯特速率视图采样的感知质量,同时使用的视图减少了多达4000倍。我们通过增强现实智能手机应用程序展示我们的方法的实用性,该应用程序可引导用户捕获场景的输入图像,以及在桌面和移动平台上实现实时虚拟探索的查看器。
|
Self-supervised Learning for Video Correspondence Flow
Authors Zihang Lai, Weidi Xie
本文的目的是对来自视频的特征嵌入进行自我监督学习,适用于对应流,即匹配视频上帧之间的对应关系。我们利用视频中外观的自然空间时间一致性来创建指针模型,该模型学习通过复制参考帧中的颜色来重建目标帧。
|
Lifting Vectorial Variational Problems: A Natural Formulation based on Geometric Measure Theory and Discrete Exterior Calculus
Authors Thomas M llenhoff, Daniel Cremers
成像和视觉方面的许多任务可以被制定为矢量值映射的变分问题。我们通过提升到电流空间来处理这种矢量变分问题的松弛和凸化。为此,我们记得具有多凸拉格朗日的函数可以在函数图上重新参数化为凸一齐函数。这导致在域和密码域的产品空间中的取向表面上的等效形状优化问题。然后通过将搜索空间从定向表面放松到更一般的电流来获得凸形配方。我们提出使用Whitney形式对所得到的无限维优化问题进行离散化,这也推广了最近的子标签精确多标记方法。
|
Clustering Images by Unmasking - A New Baseline
Authors Mariana Iuliana Georgescu, Radu Tudor Ionescu
我们提出了一种基于unmasking的新型凝聚聚类方法,这种技术以前用于文本文档的作者验证和视频中的异常事件检测。为了连接两个聚类,我们在训练二元分类器之间交替,以区分来自一个聚类的样本和来自另一个聚类的样本,以及ii在每个步骤中去除最具判别性的特征。中间获得的分类器的更快降低的准确率表明应该连接两个簇。据我们所知,这是第一个应用取消屏蔽以聚类图像的工作。我们将我们的方法与k均值以及最近的现有聚类方法进行比较。实证结果表明,我们的方法能够提高各种深层和浅层特征表示和不同任务的性能,如手写数字识别,纹理分类和细粒度物体识别。
|
Human Action Recognition with Deep Temporal Pyramids
Authors Ahmed Mazari, Hichem Sahbi
深度卷积神经网络CNN现在在包括动作识别在内的不同模式识别任务中实现了重大飞跃。当前的CNN越来越深,数据越来越多,这使得它们成为大量标记训练数据的成功支流。 CNN还依赖于最大平均合并,这降低了输出层的维数,从而削弱了它们对标记数据可用性的敏感性。然而,该过程可能稀释上游卷积层的信息,从而影响训练表示的辨别力,特别是当学习的类别被细粒度化时。
|
Egocentric Hand Track and Object-based Human Action Recognition
Authors Georgios Kapidis, Ronald Poppe, Elsbeth van Dam, Lucas P. J. J. Noldus, Remco C. Veltkamp
以自我为中心的视觉是一个新兴的计算机视觉领域,其特点是从第一人称视角获取图像和视频。在本文中,我们通过明确利用场景中检测到的感兴趣区域的存在和位置来解决自我中心人类行为识别的挑战,而无需进一步使用视觉特征。
|
The 2019 DAVIS Challenge on VOS: Unsupervised Multi-Object Segmentation
Authors Sergi Caelles, Jordi Pont Tuset, Federico Perazzi, Alberto Montes, Kevis Kokitsi Maninis, Luc Van Gool
我们将介绍2019年DAVIS挑战视频对象分割,这是DAVIS挑战系列的第三版,这是一项专为视频对象分割VOS设计的公共竞赛。除了原版半监督音轨和上一版中引入的互动音轨外,今年还将推出一款新的无监督多目标音轨。在新引入的轨道中,要求参与者在每个图像上提供非重叠的对象提议,以及在帧之间链接它们的标识符,即视频对象提议,而没有任何测试时间,人工监督没有在测试视频上提供的涂鸦或掩模。为了做到这一点,我们以简洁的方式重新注释了DAVIS 2017的列车和val集,以促进无人监督的轨道,并为比赛创建了新的测试开发和测试挑战集。本文详细描述了无监督轨道的定义,规则和评估指标。
|
Face Identification using Local Ternary Tree Pattern based Spatial Structural Components
Authors Rinku Datta Rakshit, Dakshina Ranjan Kisku, Massimo Tistarelli, Phalguni Gupta
本文报告了人脸识别系统的突破性结果,该系统利用了一种称为局部三元树模式的新型局部描述符。当系统在存在包括约束,无约束和整形外科图像的多种面部图像的情况下执行时,为面部图像设计灵巧且可行的局部描述符在面部识别任务中起到紧急的前言。已经提出LTTP从面部图像提取鲁棒且有区别的空间特征,因为该描述符可用于最佳地描述面部的各种结构组件。为了提取最有用的特征,为每个像素形成具有八个邻居的三元树。 LTTP模式可以以四种方式生成LTTP左深度,LTTP左宽度,LTTP右深度和LTTP右宽度。这四种模式生成的编码方案在计算复杂性和时间复杂性方面非常简单和有效。所提出的面部识别系统在六个面部数据库上进行测试,即UMIST,JAFFE,扩展的耶鲁面部B,整形外科,LFW和UFI。实验评估表明,考虑到在不同环境下捕获的各种面部,在设计面部识别系统时将产生长期影响的最优秀结果。
|
DS-VIO: Robust and Efficient Stereo Visual Inertial Odometry based on Dual Stage EKF
Authors Xiaogang Xiong, Wenqing Chen, Zhichao Liu, Qiang Shen
本文提出了一种基于EKF扩展卡尔曼滤波器的双阶段算法,用于实时和稳健的立体声VIO视觉惯性测距。这种基于EKF的算法的第一阶段执行加速度计和陀螺仪的融合,而第二阶段执行立体相机和IMU的融合。由于加速度计和陀螺仪以及立体相机和IMU之间具有足够的互补特性,基于双级EKF的算法可以实现高精度的测距估计。同时,由于该算法中状态向量的维数较低,其计算效率可与之前基于滤波器的方法相媲美。我们称之为DS VIO双级基于EKF的立体视觉惯性测量法,并通过将其与EuRoC数据集上的OKVIS,ROVIO,VINS MONO和S MSCKF等现有技术方法进行比较来评估我们的DSVIO算法。结果表明,我们的算法在RMS误差方面可以达到相当甚至更好的性能
|
RetinaFace: Single-stage Dense Face Localisation in the Wild
Authors Jiankang Deng, Jia Guo, Yuxiang Zhou, Jinke Yu, Irene Kotsia, Stefanos Zafeiriou
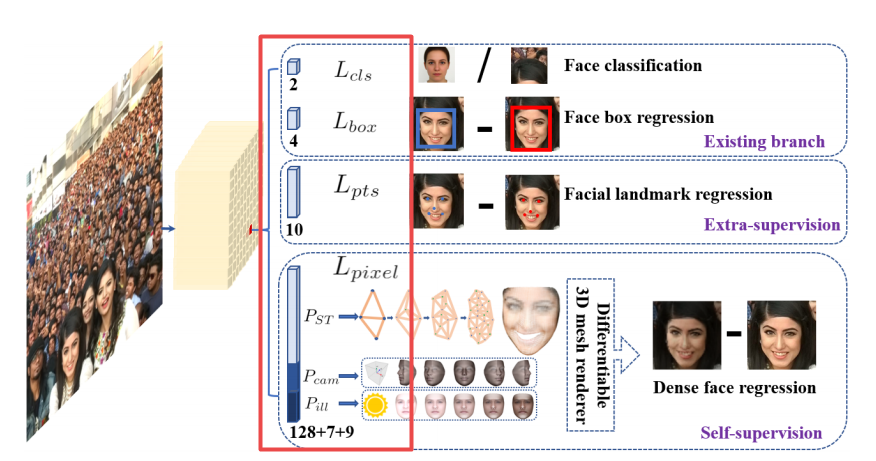
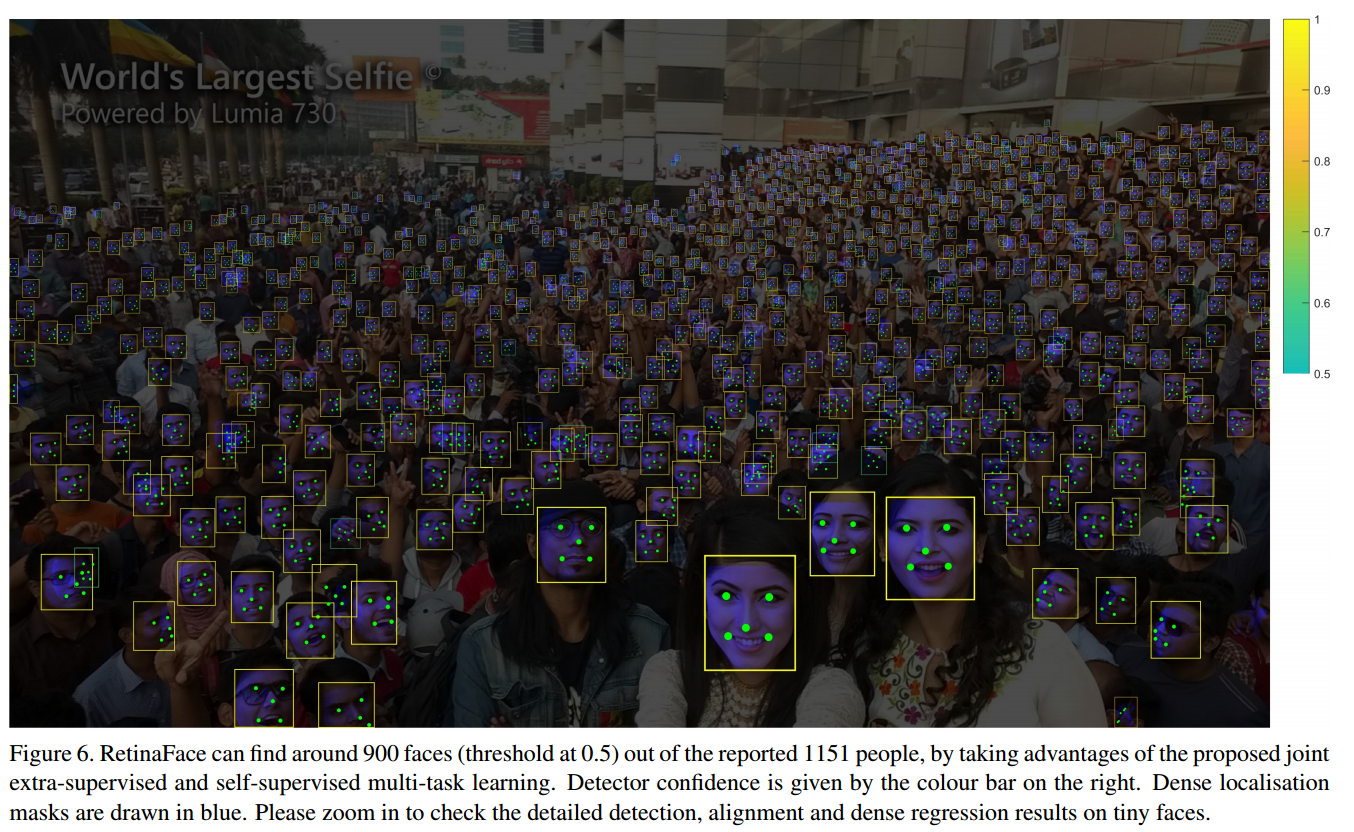
尽管在不受控制的人脸检测方面取得了巨大进步,但野外准确有效的面部定位仍然是一个开放的挑战。本文提出了一种强大的单阶段人脸检测器,名为RetinaFace,它利用联合额外监督和自我监督的多任务学习,在各种人脸尺度上进行像素智能人脸定位。具体来说,我们在以下五个方面做出贡献1我们在WIDER FACE数据集上手动注释五个面部标志,并在这个额外监督信号的帮助下观察硬面检测的显着改进。 2我们进一步添加了一个自监督网格解码器分支,用于与现有的监督分支并行地预测像素方面的3D形状面部信息。 3在WIDER FACE硬测试装置上,RetinaFace的性能优于现有技术平均精度AP 1.1,达到AP等于bf 91.4。 4在IJB C测试装置上,RetinaFace使最先进的方法ArcFace能够在FAR 1e 6的面部验证TAR 89.59中改进其结果。 5通过采用轻量级骨干网络,RetinaFace可以在单个CPU核心上实时运行以获得VGA分辨率图像。将发布额外的注释和代码以方便将来的研究。
|
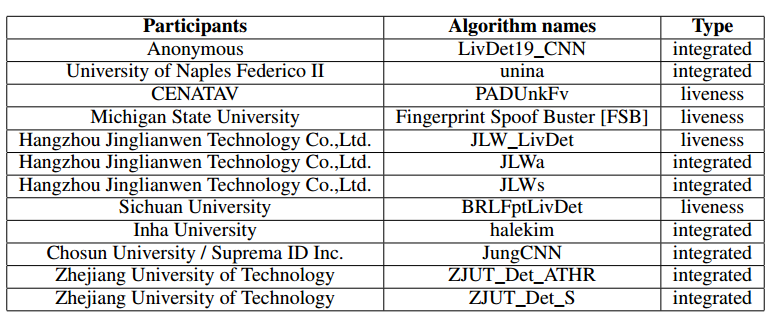
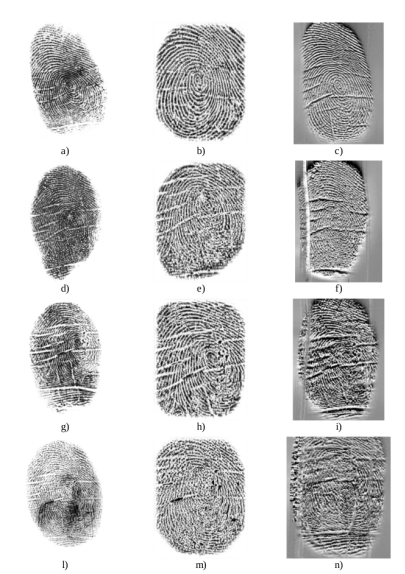
LivDet in Action - Fingerprint Liveness Detection Competition 2019
Authors Giulia Orr , Roberto Casula, Pierluigi Tuveri, Carlotta Bazzoni, Giovanna Dessalvi, Marco Micheletto, Luca Ghiani, Gian Luca Marcialis
国际指纹活体检测竞赛LivDet是一个公开的,公认的学术界和私营公司的会议点,处理区分来自人造材料和图像相对于真实指纹的指纹复制的图像的问题。在本期LivDet中,我们邀请竞争对手提出具有匹配系统的集成算法。目标是调查这种整合在多大程度上影响整个绩效。提交了12个算法,其中8个算法用于集成系统。
|
Directing DNNs Attention for Facial Attribution Classification using Gradient-weighted Class Activation Mapping
Authors Xi Yang, Bojian Wu, Issei Sato, Takeo Igarashi
深度神经网络DNN在图像分类任务中具有高精度。然而,由此类数据集训练的具有共发生偏差的DNN可能在制定分类决策时依赖于错误的特征。它将极大地影响训练有素的DNN的可转移性。在本文中,我们提出了一种交互方法,以指导分类器关注用户手动指定的区域,以减轻共现偏差的影响。我们在CelebA数据集上进行测试,经过预先训练的AlexNet经过精心调整,专注于基于Grad CAM结果的特定面部属性。
|
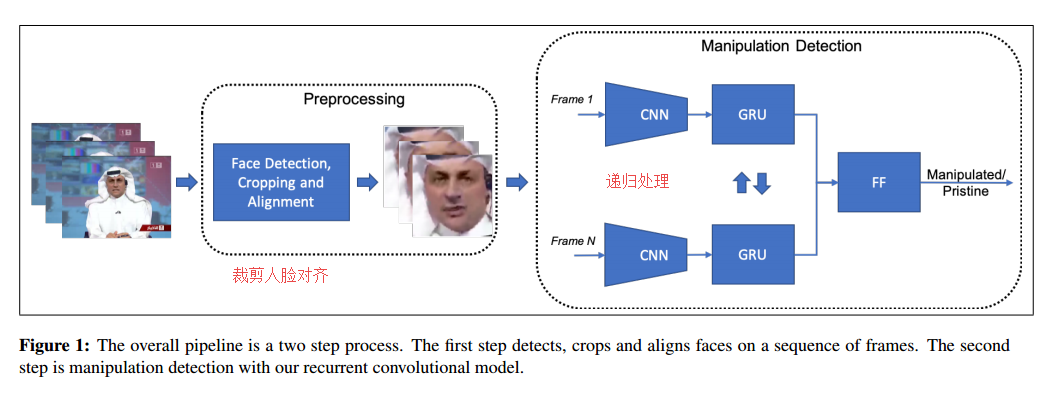
Recurrent-Convolution Approach to DeepFake Detection - State-Of-Art Results on FaceForensics++
Authors Ekraam Sabir, Jiaxin Cheng, Ayush Jaiswal, Wael AbdAlmageed, Iacopo Masi, Prem Natarajan
错误信息的传播已成为一个重要问题,提高了相关检测方法的重要性。虽然存在不同的错误信息表现,但在这项工作中,我们专注于检测视频中的面部操作。具体来说,我们尝试在视频中检测Deepfake,Face2Face和FaceSwap操作。我们利用循环方法利用视频的时间动态。在FaceForensics数据集上进行评估,并且我们的方法改进了先前的技术水平4.55。
|
Large-scale weakly-supervised pre-training for video action recognition
Authors Deepti Ghadiyaram, Matt Feiszli, Du Tran, Xueting Yan, Heng Wang, Dhruv Mahajan
当前完全监督的视频数据集仅包含几十万个视频和少于一千个域特定标签。这阻碍了高级视频架构的发展。本文对使用大量网络视频进行预训练视频模型以进行动作识别任务进行了深入研究。我们的主要实证研究结果是,尽管有嘈杂的社交媒体视频和标签,但是大规模预训练超过6500万个视频,大大改善了三个具有挑战性的公共行动识别数据集的最新技术水平。此外,我们研究了弱监督视频动作数据集构建中的三个问题。首先,假设动作涉及与对象的交互,那么如何构建动词对象预训练标签空间以最有利于转移学习第二,基于框架的模型在动作识别上表现良好是对良好图像特征的预训练足够或者是训练前对于最佳转移学习有价值的时空特征最后,由于动作标签是在视频级别提供的,因此在长视频与短视频中的动作通常不太好,因为如果有一些固定的数字预算,应如何选择视频片段以获得最佳性能或几分钟的视频
|
Billion-scale semi-supervised learning for image classification
Authors I. Zeki Yalniz, Herv J gou, Kan Chen, Manohar Paluri, Dhruv Mahajan
本文提出了一种大型卷积网络半监督学习的研究。我们提出了一个基于教师学生范式的管道,它利用了大量未标记图像,最多可达10亿。我们的主要目标是改善给定目标体系结构的性能,如ResNet 50或ResNext。我们对我们的方法的成功因素进行了广泛的分析,这使我们能够制定一些建议来生成用于半监督学习的图像分类的高精度模型。因此,我们的方法为图像,视频和细粒度分类的标准体系结构带来了重要的收益。例如,通过利用10亿个未标记的图像,我们学到的香草ResNet 50在ImageNet基准测试中达到了81.2的前1精度。
|
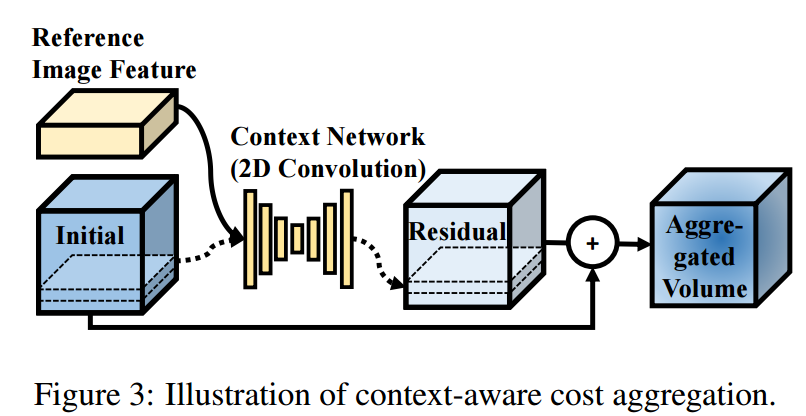
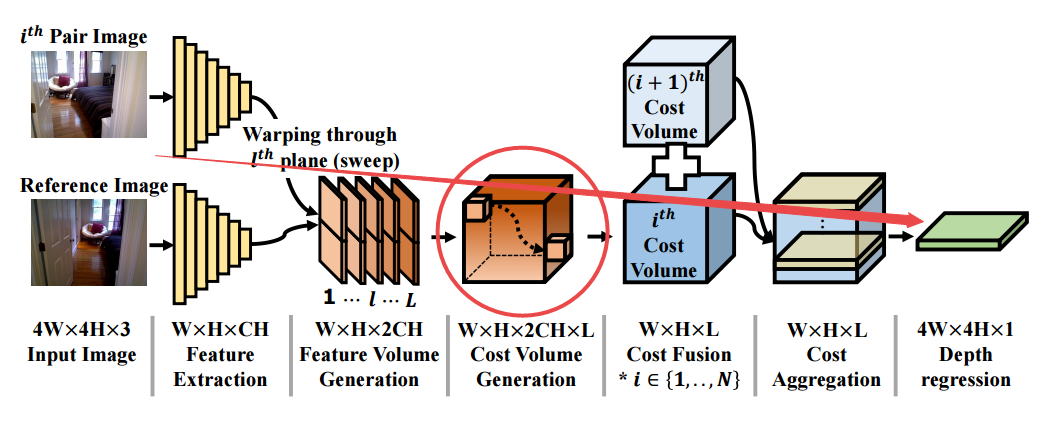
DPSNet: End-to-end Deep Plane Sweep Stereo
Authors Sunghoon Im, Hae Gon Jeon, Stephen Lin, In So Kweon
多视图立体声旨在从在任意运动下由相机获取的图像重建场景深度。最近的方法通过深度学习解决了这个问题,深度学习可以利用语义线索来处理诸如无纹理和反射区域之类的挑战。在本文中,我们提出了一个称为DPSNet深平面扫描网络的卷积神经网络,其设计灵感来自基于传统几何的密集深度重建方法的最佳实践。 DPSNet采用平面扫描方法,而不是直接估计图像对中的深度和/或光流对应,而不是使用平面扫描算法从深度特征构建成本量,通过上下文调整成本量。了解成本汇总,并从成本量中回归密集深度图。成本量使用可区分的变形过程构建,该过程允许对网络进行端到端的训练。通过在深度学习框架内有效地结合传统的多视图立体概念,DPSNet在各种具有挑战性的数据集上实现了最先进的重建结果。
|
RRPN: Radar Region Proposal Network for Object Detection in Autonomous Vehicles
Authors Ramin Nabati, Hairong Qi
区域提议算法通过假设每个图像中的对象位置在大多数现有技术的两阶段对象检测网络中起重要作用。尽管如此,已知区域提议生成器是这两个阶段对象检测网络中的瓶颈,使得它们变慢并且不适合于诸如自动驾驶车辆的实时应用。在本文中,我们介绍了一种基于雷达的实时区域提议算法,用于自动驾驶车辆中的目标检测。通过将雷达检测映射到图像坐标系并且在每个映射的雷达点处生成预定义的锚框作为对象提议来生成所提出的感兴趣区域RoI。然后,我们基于对象距离对生成的锚执行变换和缩放操作,以更好地适合检测到的对象。我们使用Fast R CNN对象检测网络在新发布的NuScenes数据集上评估我们的方法。与选择性搜索对象提议算法相比,我们的模型运行速度提高了100倍以上,同时实现了更高的检测精度和召回率。代码已公开发布于
|
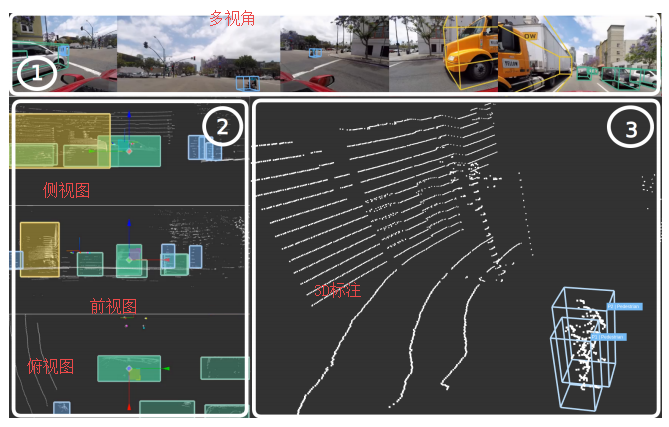
3D BAT: A Semi-Automatic, Web-based 3D Annotation Toolbox for Full-Surround, Multi-Modal Data Streams
Authors Walter Zimmer, Akshay Rangesh, Mohan Trivedi
在本文中,我们专注于获取2D和3D标签,以及借助新颖的3D Bounding Box Annotation Toolbox 3D BAT跟踪道路上物体的ID。我们的开源,基于Web的3D BAT集成了多项智能功能,可提高可用性和效率。例如,此注释工具箱支持使用插值对轨道进行半自动标记,这对下游任务(如跟踪,运动规划和运动预测)至关重要。此外,通过将来自3D空间的注释投影到图像域中,自动获得所有相机图像的注释。除了原始图像和点云馈送之外,还可以使用由顶视图鸟瞰图,侧视图和正视图组成的主视图,以从不同视角观察感兴趣的对象。我们的方法与其他公开可用的注释工具的比较表明,使用我们的工具箱可以更快,更有效地获得3D注释。
|
Optimal Multi-view Correction of Local Affine Frames
Authors Ivan Eichhardt, Daniel Barath
该技术要求在每个图像对之间预先估计对极几何。它利用了摄像机运动所暗示的约束,以便将闭合形式校正应用于输入亲和度的参数。而且,示出了通过部分仿射协变检测器(例如,AKAZE或SIFT)获得的旋转和标度可以通过所提出的算法完成为全仿射帧。它在合成实验和公开可用的现实世界数据集中得到验证,该方法总是改进评估的仿射协变特征检测器的输出。作为副产品,比较这些检测器并报告获得最准确的仿射帧的检测器。为了证明其适用性,我们表明所提出的技术作为预处理步骤提高了相机装备,表面法线和单应性估计的姿态估计的准确性。
|
Detection of Single Grapevine Berries in Images Using Fully Convolutional Neural Networks
Authors Laura Zabawa, Anna Kicherer, Lasse Klingbeil, Andres Milioto, Reinhard T pfer, Heiner Kuhlmann, Ribana Roscher
产量估算和预测在葡萄育种和葡萄栽培领域特别受关注。每株植物收获的浆果数量与产生的质量密切相关。因此,早期产量预测可以使浆果集中稀疏,以确保高质量的最终产品。传统上,产量估算是通过从小样本量推断和利用历史数据来完成的。此外,它需要由在该领域具有丰富经验的熟练专家来执行。图像中的浆果检测为专家提供了一种廉价,快速且无创的替代方案,可用于其他耗时且主观的现场分析。我们对用Phenoliner(一种野外表型分析平台)获得的图像应用完全卷积神经网络。我们计算图像中的单个浆果,以避免错误检测葡萄串。群集通常是重叠的,并且可以在大小上变化很大,这使得难以可靠地检测它们。我们特别致力于直接在葡萄园中检测白葡萄。单个浆果的检测被制定为具有三个类别的分类任务,即浆果,边缘和背景。应用连通分量算法来确定一个图像中的浆果数量。我们比较自动计数的浆果数量与手动检测到的浆果在60个图像中显示雷司令植物在垂直拍摄定位格子VSP和半最小修剪树篱SMPH。我们能够在VSP系统内正确检测浆果,准确度为94.0,SMPH系统的准确度为85.6。
|
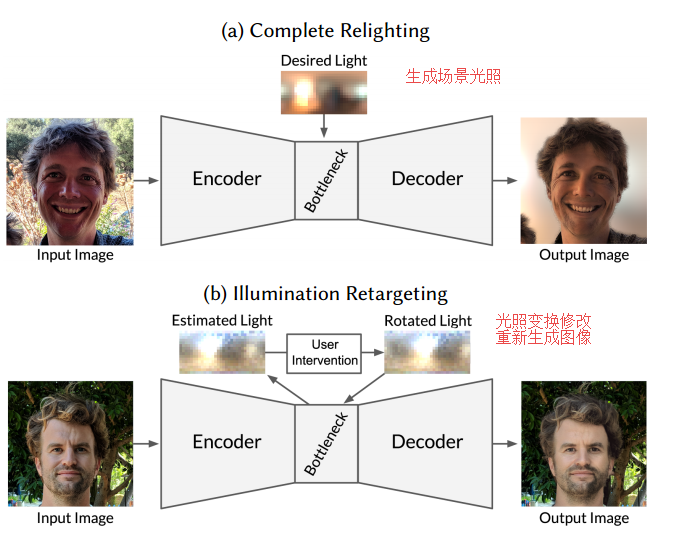
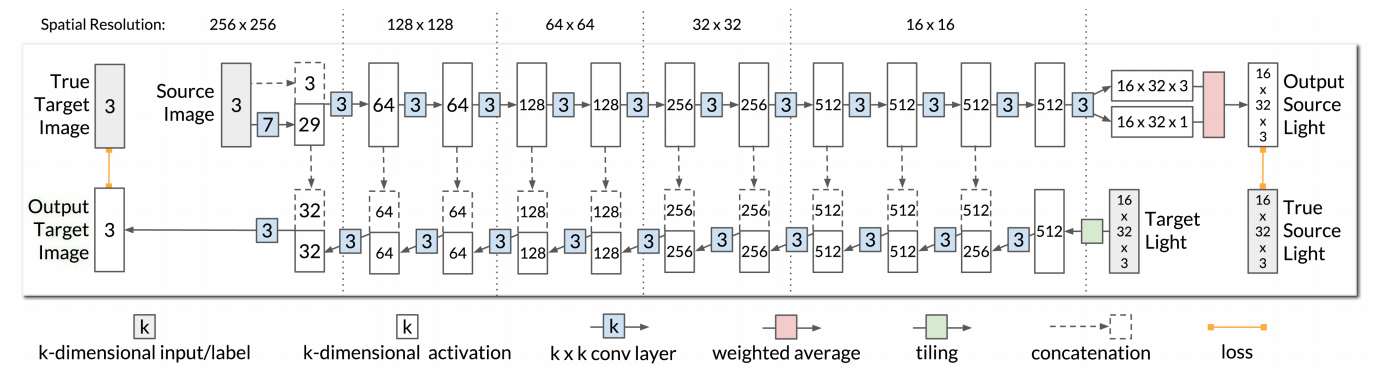
Single Image Portrait Relighting
Authors Tiancheng Sun, Jonathan T. Barron, Yun Ta Tsai, Zexiang Xu, Xueming Yu, Graham Fyffe, Christoph Rhemann, Jay Busch, Paul Debevec, Ravi Ramamoorthi
照明在肖像照片中传达主体的本质和深度方面起着核心作用。专业摄影师将仔细控制他们工作室的灯光以操纵他们的主题的外观,而消费者摄影师通常被限制在他们的环境照明。尽管先前的工作已经探索了重新照亮图像的技术,但是由于专用硬件的要求,受控或已知照明下的受试者的多个图像,或几何和反射的精确模型,它们的效用通常是有限的。为此,我们提出了一个纵向重新点亮神经网络的系统,该系统将在无约束环境中用标准手机相机拍摄的肖像的单个RGB图像作为输入,并从该图像产生该主体的重新图像,就好像它一样。根据任何提供的环境地图照亮。我们的方法是在一个由18个人组成的小型数据库上进行训练,这个数据库是在一个由密集采样光球组成的受控光阶段设置下在不同方向光源下捕获的。与先前的工作相比,我们提出的技术在我们的数据集验证集上产生了定量优越的结果,并在数百个真实世界手机肖像的数据集上产生了令人信服的定性重新照明结果。因为我们的技术可以在160毫秒内产生640倍640的图像,所以它可以在未来实现面向摄影应用的交互式用户。
|
Toward Extremely Low Bit and Lossless Accuracy in DNNs with Progressive ADMM
Authors Sheng Lin, Xiaolong Ma, Shaokai Ye, Geng Yuan, Kaisheng Ma, Yanzhi Wang
权重量化是深度神经网络DNNs模型压缩方法中最重要的技术之一。最近使用先进的优化算法ADMM交替方向乘法方法使用DNN权重量化的系统框架的工作实现了权重量化的一种现有技术结果。在这项工作中,我们首先扩展这种基于ADMM的框架以保证解决方案的可行性,并且我们进一步开发了一个多步骤,渐进式DNN权重量化框架,由于ADMM正规化的特殊性,我实现了进一步的权重量化的双重好处,以及ii减少每个步骤中的搜索空间。广泛的实验结果证明了与先前工作相比的卓越性能。我们为MNIST的所有层LeNet 5推出了第一个无损和完全二值化的亮点。我们为CIFAR 10的所有层VGG 16和ImageNet的ResNet推出了第一个完全二值化,并且具有合理的精度损失。
|
Full-Jacobian Representation of Neural Networks
Authors Suraj Srinivas, Francois Fleuret
诸如神经网络的非线性函数可以通过仿射平面局部地近似。最近的作品使用了输入雅可比行列式,它描述了这些平面的法线。在本文中,我们介绍了完整的雅可比行列式,其中包括这个法线以及一个称为偏差雅可比行星的附加截距项,它们共同描述了局部平面。对于ReLU神经网络,偏置雅可比行列式对应于输出w.r.t的梯度之和。中间层激活。
|
Inverse Halftoning Through Structure-Aware Deep Convolutional Neural Networks
Authors Chang Hwan Son
逆半色调中的主要问题是去除平坦区域上的噪声点并恢复图像结构,例如纹理区域上的线条,图案。因此,本文提出了一种结构为两个子网的新结构感知深度卷积神经网络。一个子网用于图像结构预测,而另一个用于连续色调图像重建。首先,为了预测图像结构,训练包括连续色调片的片对和通过数字半色调产生的相应半色调片。随后,通过将梯度滤波器与连续色调片进行卷积来生成梯度片。在给定半色调片和梯度片的情况下,使用微批量梯度下降算法训练图像结构预测的子网,其分别被馈送到子网的输入和丢失层。接下来,包括图像结构的预测地图通过融合层堆叠在输入半色调图像的顶部,并且被馈送到图像重建子网中,使得整个网络被自适应地训练到图像结构。实验结果证实,所提出的结构感知网络可以在平坦区域上很好地去除噪声点图案并在纹理区域上清楚地恢复细节。此外,证明了所提出的方法超过了基于深度卷积神经网络和本地学习词典的传统现有技术方法。
|
26ms Inference Time for ResNet-50: Towards Real-Time Execution of all DNNs on Smartphone
Authors Wei Niu, Xiaolong Ma, Yanzhi Wang, Bin Ren
随着一系列高端移动设备的迅速出现,许多以前需要桌面级计算能力的应用程序现在可以在这些设备上运行而没有任何问题。然而,如果不进行仔细优化,执行深度神经网络是实时视频流处理的关键构建块,这是许多常用应用程序的基础,但仍然具有挑战性,特别是如果需要极低延迟或高精度推断。这项工作介绍了CADNN,这是一个编程框架,借助先进的模型压缩稀疏性和一套全面的体系结构感知优化,在移动设备上高效地执行DNN。评估结果表明,CADNN优于所有最先进的密集DNN执行框架,如TensorFlow Lite和TVM。
|
Land Use and Land Cover Classification Using Deep Learning Techniques
Authors Nagesh Kumar Uba
目前广泛使用表示为正射影像马赛克的亚米级航空影像的大型数据集,这些数据集可能包含大量尚未开发的信息。此图像有可能找到几种类型的功能,例如森林,停车场,机场,住宅区或图像中的高速公路。然而,这些东西的出现基于许多因素而变化,包括捕获图像的时间,传感器设置,用于矫正图像的处理以及由图像捕获的区域的地理和文化背景。本文探讨了使用深度卷积神经网络从非常高的空间分辨率VHR,正射校正,可见带多光谱图像中分类土地利用。最近的技术和商业应用已经在可见的红色,绿色,蓝色RGB光谱带中驱动了大量的VHR图像,这项工作探索了深度学习算法利用该图像进行自动土地利用土地覆盖LULC分类的潜力。
|
Fully Automatic Brain Tumor Segmentation using a Normalized Gaussian Bayesian Classifier and 3D Fluid Vector Flow
Authors Tao Wang, Irene Cheng, Anup Basu
来自磁共振图像的脑肿瘤分割MRI是测量肿瘤对治疗的反应的重要任务。但是,自动分割非常具有挑战性。本文提出了一种基于归一化高斯贝叶斯分类的自动脑肿瘤分割方法和一种新的三维流体矢量流FVF算法。在我们的方法中,提出了归一化高斯混合模型NGMM并用于模拟健康的脑组织。利用高斯贝叶斯分类器从测试脑MR图像中获取高斯贝叶斯脑图GBBM。进一步处理GBBM以初始化3D FVF算法,该算法对脑肿瘤进行分割。该算法有两个主要贡献。首先,我们提出一个NGMM来模拟健康的大脑。其次,我们将2D FVF算法扩展到3D空间并将其用于脑肿瘤分割。所提出的方法在公开可用的数据集上得到验证。
|
NATTACK: Learning the Distributions of Adversarial Examples for an Improved Black-Box Attack on Deep Neural Networks
Authors Yandong Li, Lijun Li, Liqiang Wang, Tong Zhang, Boqing Gong
强大的对抗性攻击方法对于理解如何构建强大的深度神经网络DNN以及彻底测试防御技术至关重要。在本文中,我们提出了一种黑盒子对抗攻击算法,它可以击败香草DNN和最近开发的各种防御技术产生的DNN。我们的算法不是为目标DNN的良性输入搜索最佳对抗性示例,而是在以输入为中心的小区域上找到概率密度分布,这样从这个分布中抽取的样本很可能是一个对抗性的例子,而不需要访问DNN的内部层或权重。我们的方法是通用的,因为它可以通过单一算法成功攻击不同的神经网络。根据针对2个香草DNN和13个防御DNN的测试,它也很强大,它在大多数测试案例中都优于最先进的黑盒子或白盒攻击方法。此外,我们的结果显示,对抗性训练仍然是最好的防御技术之一,而对抗性的例子并不像防御DNN那样可以在防御性DNN中转移。
|
ResNet Can Be Pruned 60x: Introducing Network Purification and Unused Path Removal (P-RM) after Weight Pruning
Authors Xiaolong Ma, Geng Yuan, Sheng Lin, Zhengang Li, Hao Sun, Yanzhi Wang
现有的DNN结构涉及高计算量和对存储器存储的巨大需求,这对DNN框架资源构成了严峻的挑战。为了缓解这些挑战,已经研究了重量修剪技术。然而,极端结构化修剪的高精度解决方案结合了不同类型的结构化稀疏性,由于DNN网络中的重量极度减少,仍然在等待解开。在本文中,我们提出了一种DNN框架,它结合了两种不同类型的结构权重修剪滤波器和柱修剪,通过结合交替方向的乘法器ADMM算法,以获得更好的修剪性能。我们是第一个在结构化修剪模型中找到ADMM过程和未使用权重的非最优性,并进一步设计一个优化框架,其中包含第一个提出的网络净化和未使用路径去除算法,这些算法专用于在ADMM之后对结构化修剪模型进行后处理脚步。一些高亮显示我们在LeNet 5上实现232x压缩,在ResNet 18 CIFAR 10上实现60x压缩,在AlexNet上实现超过5倍压缩。我们以匿名链接分享我们的模型
|
|
Chinese Abs From Machine Translation |








{kind=link}