High-Resolution Daytime Translation Without Domain Labels
[CVPR 2020] [GitHub]

Abstract
Modeling daytime changes in high resolution photographs, e.g., re-rendering the same scene under different illuminations typical for day, night, or dawn, is a challenging image manipulation task. We present the high-resolution daytime translation (HiDT) model for this task. HiDT combines a generative image-to-image model and a new upsampling scheme that allows to apply image translation at high resolution. The model demonstrates competitive results in terms of both commonly used GAN metrics and human evaluation. Importantly, this good performance comes as a result of training on a dataset of still landscape images with no daytime labels available. Our results are available at https://saic-mdal.github.io/HiDT/ .
研究领域:在高分辨率照片中建模白天的变化,例如,在不同的光照下重新渲染相同的场景,典型的白天、夜晚或黎明,是一个具有挑战性的图像处理任务。
研究方法:提出了高分辨率日间翻译 (HiDT) 模型。HiDT 结合了图像到图像生成模型和新的上采样方案,允许在高分辨率下应用图像平移。在没有白天标签的静态景观图像数据集上进行训练的。
实验结果:该模型在常用的 GAN 指标和人类评价方面展示 competitive results。
【摘要分析】看似很简单,但其实很清晰。首先,第一句给出第一个卖点,即高分辨率图像到图像翻译;其次,Importantly 给出第二个卖点,即并没有使用的数据集是没有白天标签的风景图片(不需要域标签)。几句话,非常清晰本文干什么(High-Resolution Daytime Translation ),特点是什么(Without Domain Labels),做了什么((HiDT) model)。
Introduction
In this work, we consider the task of generating daytime timelapse videos and pose it as an image-to-image translation problem. Recent image-to-image translation methods have successfully handled the task of conversion between two predefined paired domains [8, 30, 16, 7] as well as between multiple domains [2, 14, 13, 17]. Given the success of these methods, using image-to-image translation methods to generate daytime changes is a natural idea.
研究领域介绍:
最近的图像到图像转换方法已经成功地处理了两个预定义成对域之间的转换 [8,30,16,7] 以及多个域之间的转换 [2,14,13,17]。
[7] Xun Huang, Ming-Yu Liu, Serge Belongie, and Jan Kautz. Multimodal Unsupervised Image-to-Image Translation. In Vittorio Ferrari, Martial Hebert, Cristian Sminchisescu, and Yair Weiss, editors, Computer Vision – ECCV 2018, pages 179–196, Cham, 2018. Springer International Publishing.
[8] Phillip Isola, Jun-Yan Zhu, Tinghui Zhou, and Alexei A. Efros. Image-to-image translation with conditional adversarial networks. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), July 2017.
[16] Ming-Yu Liu, Thomas Breuel, and Jan Kautz. Unsupervised Image-to-Image Translation Networks. In I. Guyon, U. V. Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, and R. Garnett, editors, Advances in Neural Information Processing Systems 30, pages 700–708. Curran Associates, Inc., 2017.
[30] J. Zhu, T. Park, P. Isola, and A. A. Efros. Unpaired Image-toImage Translation Using Cycle-Consistent Adversarial Networks. In 2017 IEEE International Conference on Computer Vision (ICCV), pages 2242–2251, Oct. 2017.
[2] Y. Choi, M. Choi, M. Kim, J. Ha, S. Kim, and J. Choo. StarGAN: Unified Generative Adversarial Networks for Multidomain Image-to-Image Translation. In 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8789–8797, June 2018.
[13] Hsin-Ying Lee, Hung-Yu Tseng, Qi Mao, Jia-Bin Huang, Yu-Ding Lu, Maneesh Singh, and Ming-Hsuan Yang. DRIT++: diverse image-to-image translation via disentangled representations. CoRR, abs/1905.01270, 2019.
[14] Hsin-Ying Lee, Hung-Yu Tseng, Jia-Bin Huang, Maneesh Singh, and Ming-Hsuan Yang. Diverse Image-to-Image Translation via Disentangled Representations. In Vittorio Ferrari, Martial Hebert, Cristian Sminchisescu, and Yair Weiss, editors, Computer Vision – ECCV 2018, Lecture Notes in Computer Science, pages 36–52. Springer International Publishing, 2018.
[17] Ming-Yu Liu, Xun Huang, Arun Mallya, Tero Karras, Timo Aila, Jaakko Lehtinen, and Jan Kautz. Few-shot unsupervised image-to-image translation. In The IEEE International Conference on Computer Vision (ICCV), October 2019.
Image-to-image translation approaches require domain labels at training as well as at inference time. The recent FUNIT model [17] relaxes this constraint partially. Thus, to extract the style at inference time, it uses several images from the target domain as guidance for translation (known as the few-shot setting). The domain annotations are however still needed during training.
提出核心问题:
本文要解决的的核心问题 -- 图像到图像转换方法在训练和推理时都需要域标签。最近的 FUNIT 模型 [17] 部分地放宽了这一限制。为了在推断时提取风格,FUNIT 使用来自目标域的几张图像作为翻译指导 (few-shot)。然而,在培训期间仍然需要域注释。域标签是很难做的,因此,本文希望提出的模型是不需要域标签的!

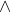 [17] Few-shot unsupervised image-to-image translation. Training: 训练集由各种对象类 (源类) 的图像组成。训练一个模型在这些源对象类之间转换图像。Deployment: 训练模型展示了目标类的很少的图像,这足以将源类的图像转换为目标类的类似图像,即使模型在训练期间从未看到过目标类的单个图像。注意,FUNIT生成器有两个输入:1) 一个内容图像和 2) 一组目标类图像。它的目的是生成与目标类的图像相似的输入图像的翻译。
[17] Few-shot unsupervised image-to-image translation. Training: 训练集由各种对象类 (源类) 的图像组成。训练一个模型在这些源对象类之间转换图像。Deployment: 训练模型展示了目标类的很少的图像,这足以将源类的图像转换为目标类的类似图像,即使模型在训练期间从未看到过目标类的单个图像。注意,FUNIT生成器有两个输入:1) 一个内容图像和 2) 一组目标类图像。它的目的是生成与目标类的图像相似的输入图像的翻译。
In our task, domains correspond to different times of the day and different lighting, and therefore domain labels are hard to define and hard to solicit from users. Furthermore, while timelapse videos might have provided us with weakly supervised data, we have found that collecting highresolution diverse daytime timelapse videos is hard. Therefore, in our work, we aim to develop an image-to-image translation problem suitable for the setting when domain labels are unavailable.
本文任务分析:
在我们的任务中,域对应于一天中不同的时间和不同的光照,因此域标签很难定义,也很难从用户那里获得。此外,虽然延时视频可能为我们提供了弱监督数据,但我们发现,收集高分辨率、多样化的日间延时视频是困难的。因此,本文的目标是发展一个图像到图像的翻译问题,适合于域标签是不可用的情况。
Thus, as our first contribution, we show how to train a multi-domain image-to-image translation model on a large dataset of unaligned images without domain labels. We demonstrate that the internal bias of the collected dataset, the inductive bias caused by the network architecture, and a specially developed training procedure make it possible to learn style transformations even in this setting. The only external (weak) supervision used by our approach are coarse segmentation maps estimated using an off-the-shelf semantic segmentation network.
本文贡献(工作)1:
展示了如何在一个没有域标签的未对齐图像的大数据集上训练一个多域图像到图像的转换模型。所收集数据集的内部偏差、由网络结构引起的归纳偏差以及专门开发的训练程序,即使在这种情况下也可以学习风格转换。本文的方法使用的外部(弱)监督是使用现成的语义分割网络估计的粗分割地图。
As the second contribution, to ensure fine detail preservation, we propose an architecture for image-to-image translation that combines the two well-known ideas: skip connections [22] and adaptive instance normalizations (AdaIN) [6]. We show that such a combination is feasible and leads to an architecture that preserves details much better than currently dominant AdaIN architectures without skip connections. We evaluate our system against several state-of-the-art baselines through objective measures as well as a user study. While our main focus is the task of photorealistic daytime alteration for landscape images, we also show that such architecture system can be used to handle other multi-domain image stylization/recoloring tasks.
本文贡献(工作)2:
为了确保细节的保留,提出了一个图像到图像转换的架构,结合了两思想:跳过连接 [22] 和自适应实例标准化 AdaIN [6]。本文证明了这样的组合是可行的,它比目前占主导地位的 AdaIN 架构在没有跳过连接的情况下更好地保留细节。虽然主要重点是对景观图像进行逼真的日间更改,但这样的建筑系统可以用于处理其他多领域的图像风格化/重新上色任务。
Finally, as the third contribution, we address the task of image-to-image translation at high resolution. In our case, as well as in many other settings, training a high-capacity image-to-image translation network directly at high resolution is computationally infeasible. We therefore propose a new enhancement scheme that allows to apply the imageto-image translation network trained at medium resolution for high-resolution images.
本文贡献(工作)3:
解决了高分辨率图像-图像转换的任务。直接训练一个高分辨率的高容量图像到图像转换网络在计算上是不可行的。因此提出了一种新的增强方案,允许将在中等分辨率下训练的图像-图像转换网络应用于高分辨率图像。
Related work
- Unpaired image-to-image translation.
。。。。. In this work, we take the next logical step in the evolution of GAN-based style transfer and do not use domain labels at all.
在这项工作中,在基于 GAN 的样式转换的发展中提出了完全不使用域标签的方法。
The generation of timelapses has attracted some attention from researchers, but most previous approaches use a dataset of timelapse videos for training. In particular, the work [24] used a bank of timelapse videos to find the scene most similar to a given image and then exploited the retrieved video as guidance for editing. Following them, the work [12] used a database of labeled images to create a library of transformations and apply them to image regions similar to input segments. Both methods rely on global affine transforms in the color space, which are often insufficient to model daytime appearance changes.
Unlike them, a recent paper [20] has introduced a neural generation approach. The authors leveraged two timelapses datasets: one with timestamp labels and another without them, both of different image quality and resolution. Finally, a very recent and parallel research [3] uses a dataset of diverse videos to solve the daytime appearance change modeling problems. Note that the method [3] also considers the problem of modeling short-term changes and rapid object motion, which we do not tackle in our pipeline. Our approach is different from all previous works for timelapse generation, as it needs neither timestamps nor spatial alignment (such as, e.g. timelapse frames).
以前的大多数方法使用timelapse视频的数据集进行训练。最近的一篇论文 [20] 引入了一种神经生成方法,利用了两个 timelapses 数据集,一个带有时间戳标签,另一个没有时间戳标签,两者的图像质量和分辨率都不同。最近的并行研究[3]使用不同视频的数据集来解决日间外观变化建模问题。本文的方法与之前所有的 timelapse 生成方法不同,因为本文的方法既不需要时间戳,也不需要空间对齐 (例如,timelapse 帧)。
- High-resolution translation.
Modern generative models are often hard to scale to high-resolution input images due to memory constraints; most models are trained on either cropped parts or downscaled versions of images. Therefore, to generate a plausible image in high resolution one needs an additional enhancement step to upscale the translation output and remove artifacts. Such enhancement is closely related to the superresolution problem.
The work [15] compared photorealistic smoothing and image-guided filtering [4], and noted that the latter slightly degraded the performance as compared to the former, but led to a significant performance gain. Another way, proposed in [20], is to apply a different kind of guided upsampling via local color transfer [5]. However, unlike image-guided filtering, this method does not have a closed-form solution and requires an optimization procedure at inference time. In [3], the model predicts the parameters of a pixel-wise affine transformation of the downscaled image and then applies bilinear upsampling with these parameters to the full-resolution image. Unfortunately, both approaches often produce halo-type artifacts near image edges.
The work most similar to ours in this regard, the pix2pixHD model [8], developed a separate refinement network. Our enhancement model is similar to their approach, as we also use the refinement procedure as a postprocessing step. But instead of training on the features, we use the output of low-resolution translation directly in a way inspired by classical multi-frame superresolution approaches [27].
在这方面与我们的工作最为相似的是,pix2pixHD 模型[8],开发了一个单独的细化网络。我们的增强模型与他们的方法类似,因为我们也使用细化过程作为后处理步骤。但是,我们没有对特征进行训练,而是直接使用低分辨率翻译的输出,其方式受到了经典的多帧超分辨率方法[27]的启发。
Methods
Architecture
The main part of HiDT is an encoder-decoder architecture. The encoder performs decomposition into style (vector) and content (tensor). The decoder is then able to generate a new image xˆ by taking content from the content input image x and style from the style input image x ′ .
The two components (the content and the style) are combined together using the AdaIN connection [6, 17]. The overall architecture has the following structure: the content encoder Ec maps the initial image to a 3D tensor c using several convolutional down-sampling layers and residual blocks. The style encoder Es is a fully convolutional network that ends with global pooling and a compressing 1×1 convolutional layer. The generator G processes c with several residual blocks with AdaIN modules inside and then up-samples it.
To create a plausible daytime landscape image, the model should preserve fine details from the original image. To satisfy this requirement, we enhance the encoder-decoder architecture with skip connections between the down-sampling part of tje (the, 拼写错误) encoder Ec and the up-sampling part of the generator G. Regular skip connections would also “leak” the style of the initial input into the output. Therefore, we introduce an additional convolutional block with AdaIN [6] and apply it to the skip connections (see Fig. 2).
 Figure 2
Figure 2
自适应 U-Net 架构图:具有密集的跳跃连接和内容风格分解的编码器-解码器网络 (c, s)。
 Figure 3
Figure 3
网络结构总结为几点(结合图2 图3):
1. 分解:解码器将图像分解为 content 张量 和 style 向量;content 张量通过 下采样卷积层 和 residual blocks 获得 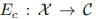 ;style 向量通过 全局池化 和 1×1 压缩卷积层 获得
;style 向量通过 全局池化 和 1×1 压缩卷积层 获得 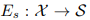 。
。
2. U-Net + AdaIN:AdaIN 将 style 向量与 content 张量进行融合;AdaIN [ 2017 ICCV Arbitrary Style Transfer in Real-time with Adaptive Instance Normalization];这里采用 U-Net 的目的是保持细节信息;但这样对 style 迁移不利,因此用 AdaIN 对跳接的特征进行调整;
3. 语义分割引导:生成器(decoder)的输出除了生成的翻译图像(translated image),还有语义分割图(translated mask),即 
Learning
Overall, the architecture is trained using a reconstruction loss as well as a number of additional losses (Fig. 3). During training, the decoder predicts not only the input image x but also its semantic segmentation mask m (produced by a pretrained network [26]). While we do not aim to achieve state-of-the-art segmentation as a by-product, having the segmentation loss helps to control the style transfer and to preserve the semantic layout. Importantly, segmentation masks are not given as input to the networks, and are thus not needed at inference time.
总的来说,该体系结构是使用重构损失和一些附加损失进行训练的 (图3)。在训练期间,解码器不仅预测输入图像 x,还预测其语义分割面具 m (由预先训练的网络 [26] 产生)。虽然目标不是语义分割,但语义分割损失有助于控制风格转移和保留语义布局。重要的是,分割 mask 图不作为网络的输入给出,因此在测试时不需要。
[26] Deep high-resolution representation learning for human pose estimation. (CVPR), 2019.
- Image reconstruction loss
看图吧,都是 L1-norm

其中,m 是用于已有的语义分割网络,生成 语义风格 图 m。


- Latent reconstruction losses

这块没看懂,具体是引用了文献 CORAL [25] 的思想和方法。
[25] Correlation alignment for unsupervised domain adaptation. Domain Adaptation in Computer Vision Applications

Enhancement postprocessing
Training image-to-image translation on high resolution images is infeasible due to both memory and computation time constraints. In principle, our architecture can be trained at medium resolution and applied to high resolution images in a fully convolutional way. Alternatively, guided filtering [4] can be used to upsample results of processing at medium resolution. Although both of these techniques show good results in most cases, they have limitations. A fully convolutional application might yield scene corruption due to limited receptive field, which is the case with sunsets where multiple suns might be drawn, or water reflections where the border between sky and water surface might be confused. Guided filtering, on the other hand, works great with water or sun but fails if small details like twigs were changed by the style transfer procedure. It also often generates halo artefacts near the horizon and other high-contrast borders. Finally, we have found that a superresolution architecture [29] does not generalize well even to well-looking translated images, effectively amplifying translation artefacts.
由于内存和计算时间的限制,在高分辨率图像上训练图像到图像的翻译是不可行的。原则上,本文的架构可以在中等分辨率下进行训练,并以全卷积的方式应用于高分辨率图像。另外,引导滤波[4]可以用于在中等分辨率的处理结果上采样。尽管这两种技术在大多数情况下都显示出良好的结果,但它们都有局限性。一个完全卷积的应用程序可能会由于有限的接收域而产生场景破坏,例如日落时可能会绘制多个太阳,或者水面反射时可能会混淆天空和水面的边界。关于引导过滤的另一方面,在水或阳光下工作很好,但如果小细节,如树枝改变了风格转换程序就失败了。它也经常在地平线和其他高对比度边界附近产生光晕。最后,对于超分辨率架构 [29] 不能生成很好的图像,会放大 artefacts。
Inspired by existing multiframe image restoration methods [27], we propose to apply translation multiple times at medium resolution and then use a separate merging network  to combine the results into a high-resolution translated image. More specifically, we consider a high resolution image
to combine the results into a high-resolution translated image. More specifically, we consider a high resolution image  (in our experiments, 1024 1024). We then consider sixteen shifted versions of denoted as
(in our experiments, 1024 1024). We then consider sixteen shifted versions of denoted as  , each having the same size as and obtained with integer displacement spanning the range [0; 4] in
, each having the same size as and obtained with integer displacement spanning the range [0; 4] in  and
and 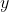 (missing pixels are filled with zeros). The shifted images are then downsampled bilinearly resulting in sixteen medium-resolution images
(missing pixels are filled with zeros). The shifted images are then downsampled bilinearly resulting in sixteen medium-resolution images  , from which the original image can be easily recovered.
, from which the original image can be easily recovered.
受现有多帧图像恢复方法 [27] 的启发,建议在中等分辨率下应用多次翻译,然后使用单独的合并网络 将结果合并成高分辨率的翻译图像。具体地说,考虑一个高分辨率的图像 (1024x1024),然后把 翻译为 16 个版本,表示为 ,每一个都与 的大小相同,并通过跨越范围 [0;4] 在 x 和 y (丢失的像素用零填充)。然后对移位的图像进行双线性下采样,得到16幅中等分辨率的图像 ,从这些图像中可以很容易地恢复到原始图像 。
We then apply HiDT to each of the medium-resolution images separately, getting translated medium-resolution images  .These frames are stacked into a single tensor in a fixed order and are fed to the merging network Genh that outputs the translated high-resolution image.
.These frames are stacked into a single tensor in a fixed order and are fed to the merging network Genh that outputs the translated high-resolution image.
然后我们分别对每一个中等分辨率的图像应用HiDT,得到翻译后的中等分辨率图像,帧以固定顺序堆叠到单个张量中,并馈给合并网络Genh,后者输出转换后的高分辨率图像。